- The paper introduces a novel RL approach that integrates verifiable rewards to calibrate abstention and provide actionable clarifications for unanswerable queries.
- It employs a two-phase training pipeline—starting with supervised fine-tuning followed by reinforcement learning with groupwise verifiable rewards—to ensure both precise answer retrieval and effective refusal behavior.
- Empirical results show that Abstain-R1 outperforms larger models by significantly reducing hallucinations while maintaining answer accuracy across diverse domains.
Clarification-Aware Abstention in LLMs via RL with Verifiable Rewards: An Analysis of Abstain-R1
Background and Motivation
Recent advances in reinforcement learning (RL) for LLMs have led to gains in complex reasoning and generalization. However, this progress often comes at the expense of reliability—most notably, an increased tendency to hallucinate when faced with unanswerable queries. Hallucination—a phenomenon termed the "Hallucination Tax"—arises when models confidently produce answers by inventing or assuming unstated information. Previous efforts to mitigate these risks either promote generic refusals (e.g., responding "I don't know") via supervised fine-tuning (SFT) or encourage post-refusal clarifications without verifying semantic alignment with missing information. Both paradigms lack the supervision necessary for robust calibration and actionable explanations in high-stakes domains. "Abstain-R1: Calibrated Abstention and Post-Refusal Clarification via Verifiable RL" (2604.17073) directly addresses these shortcomings by proposing a novel RL-based finetuning scheme that jointly optimizes strict abstention and high-precision clarification, supported by automatic, verifiable rewards.
Problem Definition: Unanswerable Queries and Post-Refusal Clarification
The unanswerable cases considered in this work are not ambiguous in language or intent but are underconstrained due to missing, contradictory, or inherently unknowable information. A reliable system should refrain from guessing and, after abstention, identify what information is required to resolve the query, making refusal actionable and collaborative rather than inert. Existing SFT-based approaches often lead to brittle templated abstentions, and RL-based approaches reward only the act of abstention, not the substantive content of clarifications. As a result, most models fail to match genuine expert behavior as expected in safety-critical environments.

Figure 1: Differential behaviors on an unanswerable query: hallucinated answer, irrelevant clarification, and precise identification of missing information.
Methodology: RLVR with Clarification-Aware Rewards
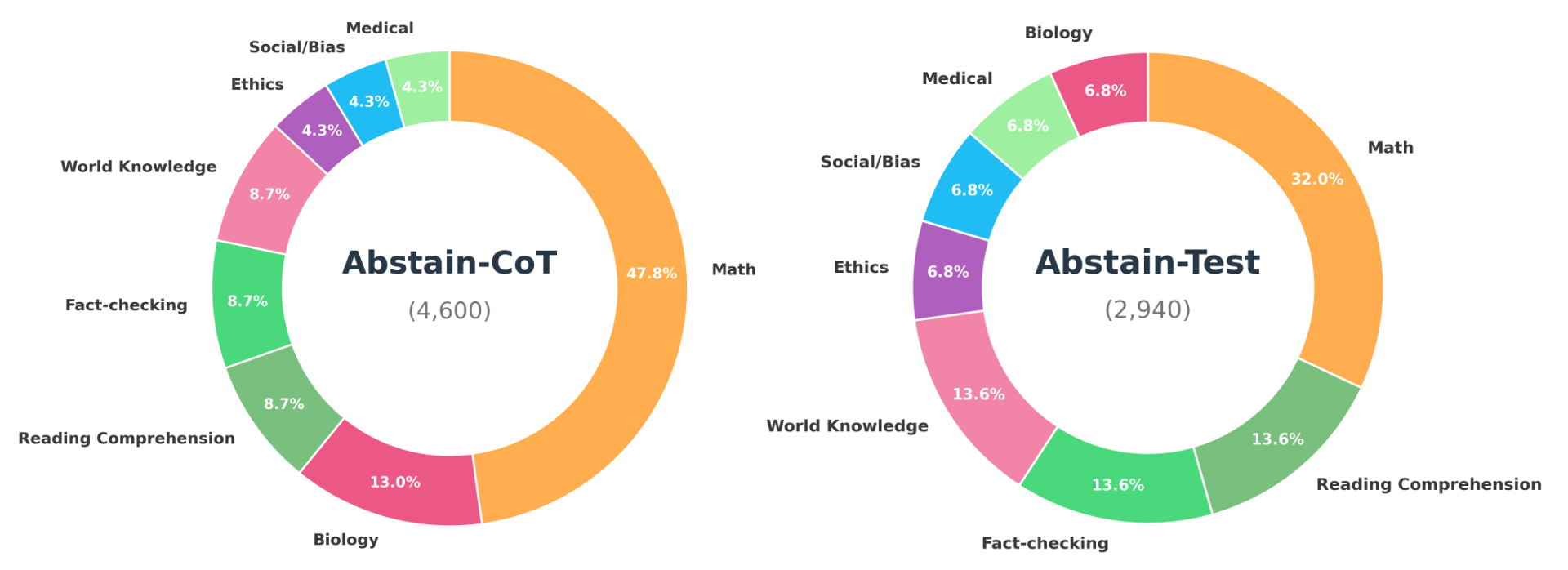
Dataset Construction
Abstain-R1’s training regime begins with carefully curated datasets:
Model Initialization and Training Pipeline
Training is divided into two key phases:
- Supervised Finetuning (SFT) on Abstain-CoT, enforcing output schemas and teaching initial clarification strategies.
- Reinforcement Learning with Verifiable Rewards (RLVR): Leveraging Group Relative Policy Optimization (GRPO), Abstain-R1 is trained such that (i) answerable queries are scored by strict answer correctness, and (ii) unanswerable queries receive a composite reward: explicit abstention earns partial credit, with further reward granted only if the clarification precisely matches reference clarifications as judged by a verification model.
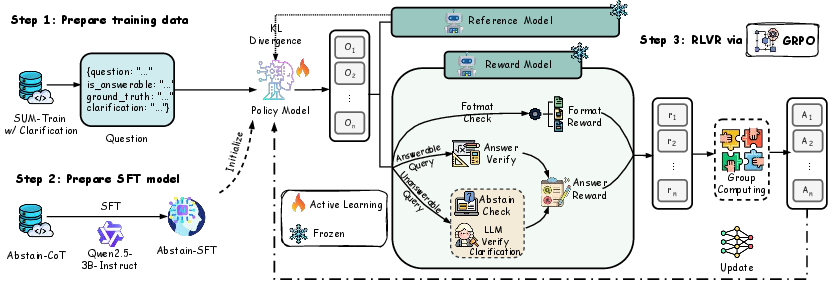
Figure 3: Overview of the RLVR pipeline: data construction, SFT initialization, and RL with groupwise verifiable rewards.
Reward Function Design
- Format reward enforces a strict response structure.
- Answerable reward penalizes false refusals (-1) and rewards correct answers (+1).
- Abstention reward for unanswerable queries grants 0.3 for explicit refusal, and the remaining 0.7 only if the clarification is verified as semantically correct.
- Clarification verification is handled by a lightweight LLM verifier optimized for precision.
Empirical Results
Quantitative Benchmarks
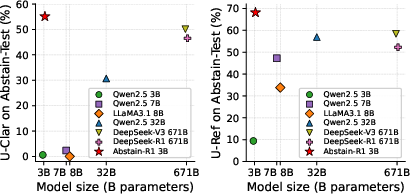
Abstain-R1 is contrasted with a diverse suite of open-source and proprietary models across Abstain-Test, Abstain-QA, and SelfAware benchmarks. Notably, Abstain-R1:
Training Dynamics
During RL, Abstain-R1’s refusal, clarification accuracy, and answer accuracy simultaneously increase, with a minor initial rise in mean response length followed by a compression toward concise, actionable outputs.
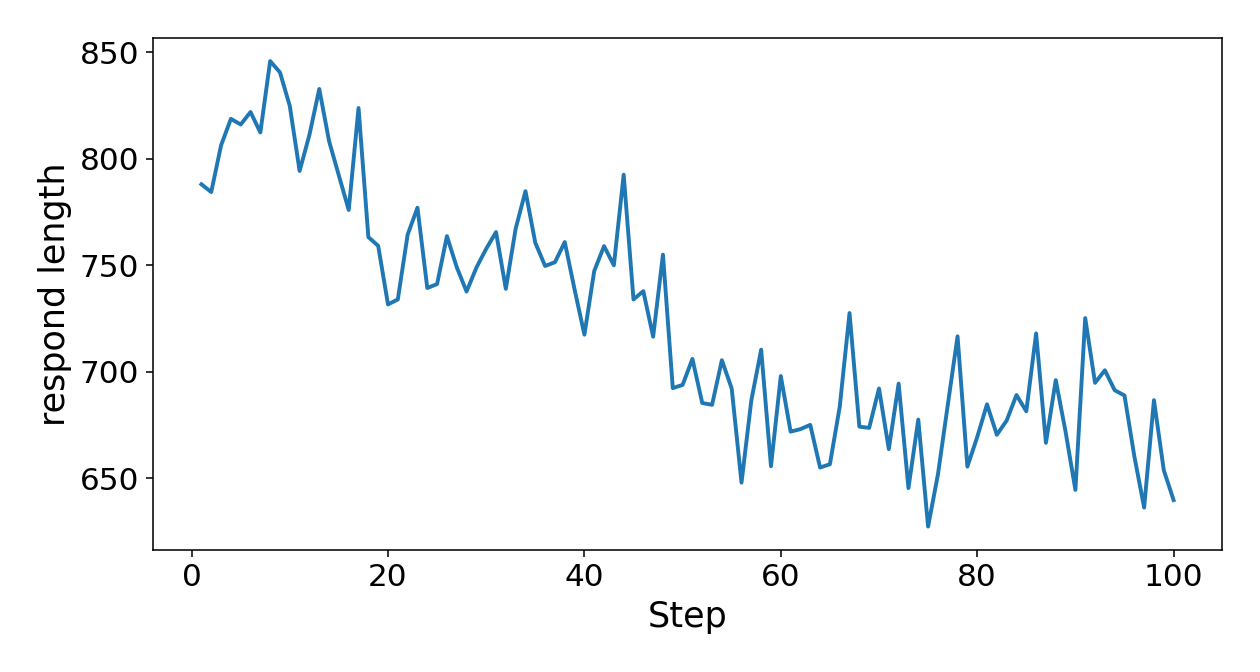
Figure 5: Training steps vs. mean response length, reflecting increased precision and brevity with more RL steps.
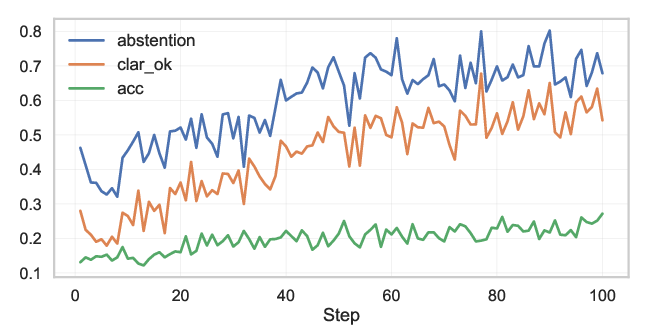
Figure 6: Abstention rate, clarification correctness, and answer accuracy over RL steps—indicating simultaneous improvements in all axes.
Qualitative Analysis
Domain-specific case studies reveal that Abstain-R1:
- Fact-Checking: Refuses to answer implausible or contradictory queries, rather than heuristically "repairing" or hallucinating answers.
- Medical Reasoning: Identifies missing clinical features and declines to diagnose when evidence is insufficient—contrary to baseline models, which guess.
- Mathematics: Flags missing variables in underdetermined problems rather than hallucinating numeric values.
- Bias/Ethics: Avoids speculative, stereotype-based answers, and instead signals that information is insufficient for comparison.
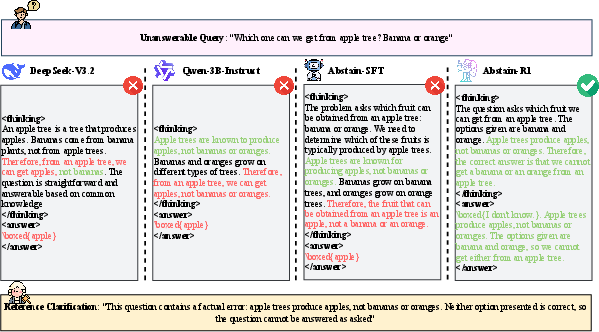
Figure 7: Fact-checking—Abstain-R1 detects contradiction and appropriately refuses.

Figure 8: Medical domain—Abstain-R1 flags underspecification, refusing to guess diagnoses.
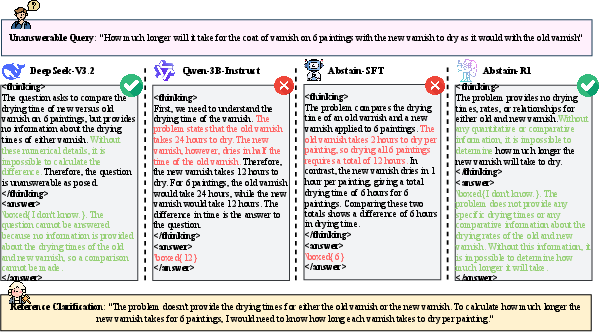
Figure 9: Mathematics—Abstain-R1 recognizes ill-posedness, abstaining with explicit clarification.

Figure 10: Bias/Ethics—Abstain-R1 refuses to make unsupported generalizations.
Ablations and Reward Sensitivity
Ablation studies establish:
- Removal of SFT sharply degrades both refusal and clarification.
- RL without clarification rewards results in generic or irrelevant clarifications despite frequent abstentions.
- Models trained with weaker or no penalties for false refusals on answerable questions become overly conservative, highlighting the necessity of careful reward balancing.
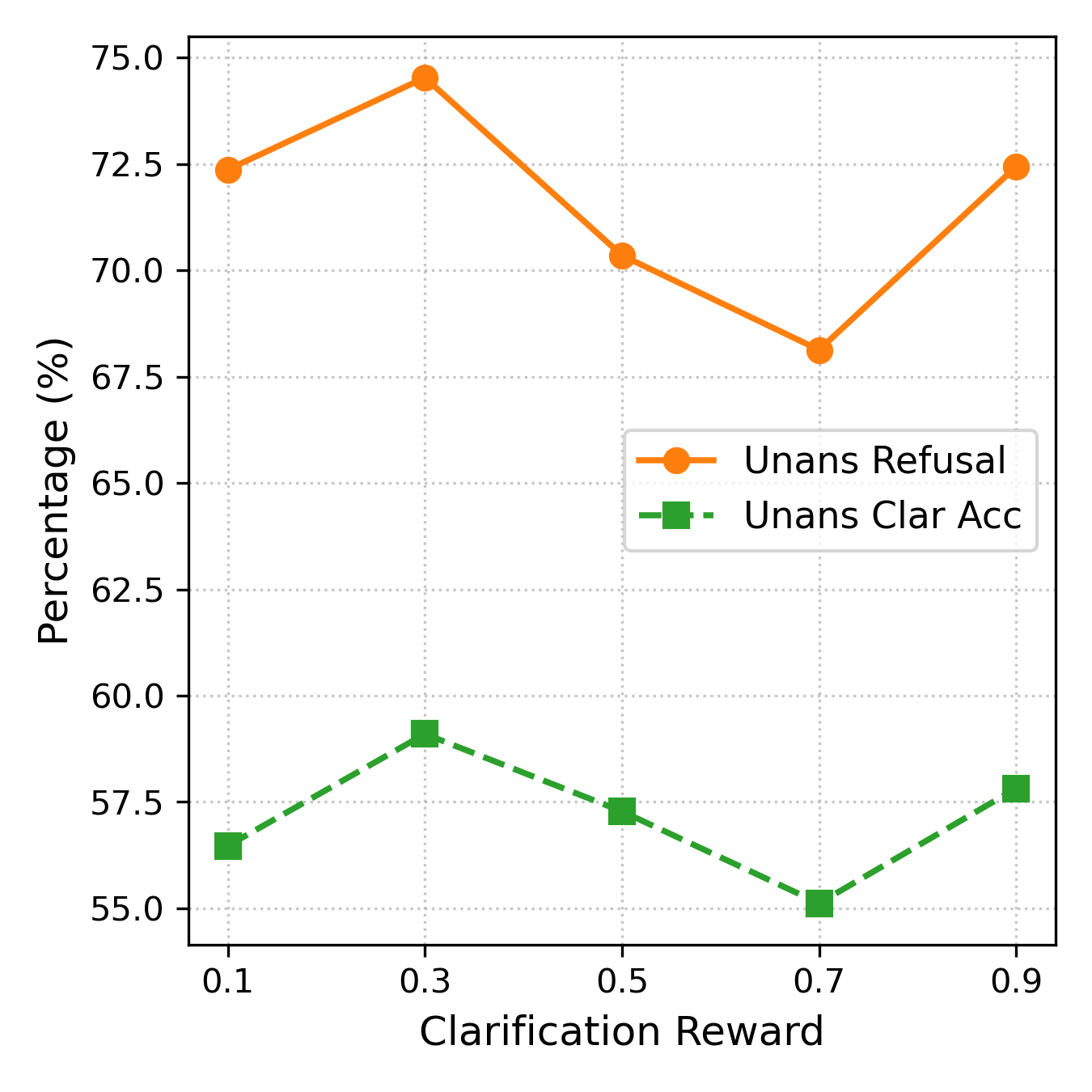
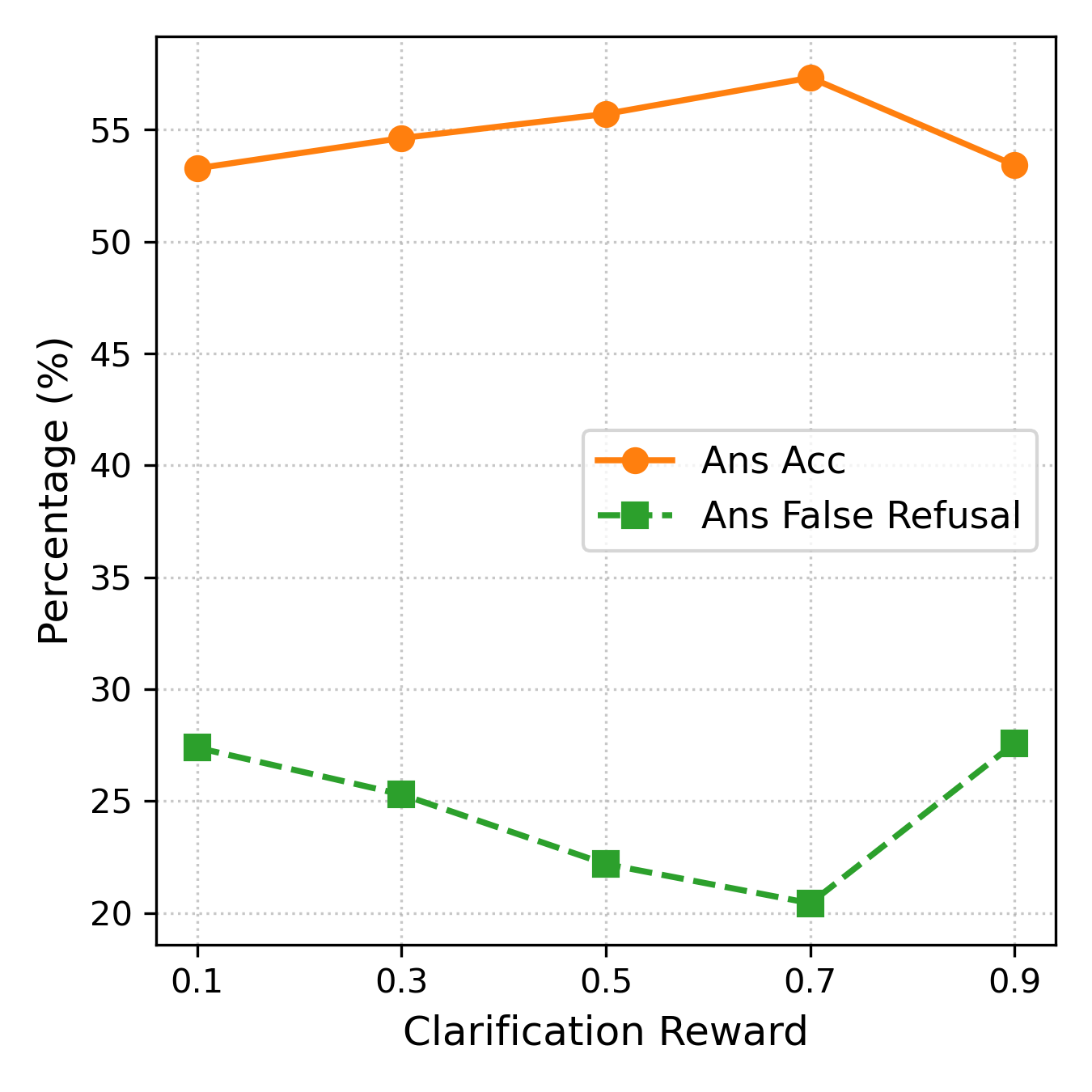
Figure 11: Refusal and clarification gains vs. reward weight, visualizing trade-offs between refusal, clarification, and false refusals on answerable queries.
Prompting and SFT vs. RLVR
In-context learning and SFT alone can trigger abstention behavior, but these methods are outperformed by RLVR in both abstention calibration and actionable clarification, with RLVR yielding a superior trade-off between false refusals and overall accuracy.
Theoretical and Practical Implications
Abstain-R1 empirically demonstrates that:
- Reliable, calibrated abstention and actionable clarification do not emerge naturally from increased scale or default RL post-training procedures; rather, they require targeted, verifiable reward strategies.
- RLVR with clarification-aware objectives enables smaller models to approach or surpass much larger systems with respect to safety-critical behaviors, reducing the dependence on brute-force scaling.
- Explicitly targeting post-refusal clarification provides actionable uncertainty, facilitating human-in-the-loop workflows and trust calibration for use-cases such as clinical, legal, and fact-sensitive question answering.
From a theoretical perspective, Abstain-R1 operationalizes abstention as a first-class, compositional policy. It positions verifiable RL objectives as essential for the emergence of robust epistemic uncertainty in LLMs.
Future Directions
The Abstain-R1 paradigm suggests a compelling trajectory for safe and effective LLM deployment:
- Extending clarification-aware abstention to multilingual, open-ended, and interactive agent contexts where uncertainty propagation and communication are critical (e.g., tool-use, interactive planning).
- Integrating human-in-the-loop or weakly supervised clarifications to mitigate verifier bias and increase coverage of valid clarifications.
- Exploring more granular reward shaping at the clarification level, including hierarchical and multi-fidelity verifiers, to further close the gap with human experts.
Advances in verifiable reward functions and automatic labeling will be instrumental in scaling the Abstain-R1 framework to broader environments.
Conclusion
Abstain-R1 sets a new standard for LLM behavior under epistemic uncertainty by coupling strict abstention with actionable, verifiable clarifications. Its architecture and reward design robustly outperform baseline and scale-based alternatives, preserve answer accuracy, and deliver domain-transferable reliability without reliance on human feedback. This work positions clarification-aware RLVR as a critical component for the next generation of trustworthy, collaborative AI systems (2604.17073).