Honesty over Accuracy: Trustworthy Language Models through Reinforced Hesitation (2511.11500v1)
Abstract: Modern LLMs fail a fundamental requirement of trustworthy intelligence: knowing when not to answer. Despite achieving impressive accuracy on benchmarks, these models produce confident hallucinations, even when wrong answers carry catastrophic consequences. Our evaluations on GSM8K, MedQA and GPQA show frontier models almost never abstain despite explicit warnings of severe penalties, suggesting that prompts cannot override training that rewards any answer over no answer. As a remedy, we propose Reinforced Hesitation (RH): a modification to Reinforcement Learning from Verifiable Rewards (RLVR) to use ternary rewards (+1 correct, 0 abstention, -$λ$ error) instead of binary. Controlled experiments on logic puzzles reveal that varying $λ$ produces distinct models along a Pareto frontier, where each training penalty yields the optimal model for its corresponding risk regime: low penalties produce aggressive answerers, high penalties conservative abstainers. We then introduce two inference strategies that exploit trained abstention as a coordination signal: cascading routes queries through models with decreasing risk tolerance, while self-cascading re-queries the same model on abstention. Both outperform majority voting with lower computational cost. These results establish abstention as a first-class training objective that transforms ``I don't know'' from failure into a coordination signal, enabling models to earn trust through calibrated honesty about their limits.
Sponsor

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making AI LLMs more trustworthy. The authors argue that a truly smart model should know when not to answer—especially in high‑stakes situations (like medicine or finance) where a wrong answer can be very harmful. Today’s models are trained to chase accuracy and often “guess” even when they’re unsure. The paper introduces a new way to train models so they learn when to say “I don’t know,” and shows how that simple change can reduce harmful mistakes and improve teamwork between models.
What are the main questions the paper asks?
The paper focuses on three easy‑to‑understand questions:
- Do current top AI models actually choose to say “I don’t know” when it’s safer than guessing?
- Can we train models to value honest hesitation (admitting uncertainty) instead of forcing answers?
- If models do learn to hesitate, can we use that hesitation to make them work together more effectively?
How did the researchers paper this?
First, here’s what they checked:
- They tested several well‑known AI models on math and medical multiple‑choice questions (datasets like GSM8K, MedQA, and GPQA).
- They told the models explicitly: “If you don’t know, say ‘I don’t know’. Wrong answers lose points.” Then they measured whether the models listened.
Then, here’s their new training idea:
- They propose “Reinforced Hesitation” (RH), which changes how models are rewarded:
- Correct answer: +1 point
- “I don’t know”: 0 points
- Wrong answer: −λ points, where λ is a penalty number that reflects how risky mistakes are
- Think of it like a game: in casual games (low risk), the penalty λ is small, so guessing is okay. In serious situations (high risk), λ is large, so guessing is punished and it’s smarter to abstain.
Finally, here’s how they tested RH:
- They trained a model (Qwen3‑1.7B) on logic puzzles called “Knights and Knaves.” These puzzles require careful, consistent reasoning.
- They tried different penalty levels (λ = 0, 1, 2, 5, 10, 20) and measured:
- How often the model was correct, wrong, or said “I don’t know”
- How behavior changed for easy vs. hard puzzles
- How long answers were (to check if the model learned to be concise)
They also designed two ways to use hesitation at test time:
- Cascading: send questions through several models from most cautious (high λ) to most risk‑tolerant (low λ) until one answers.
- Self‑cascading: if the model says “I don’t know,” ask the same model again; due to natural randomness, it may find a confident path on a second try.
What did they find, and why does it matter?
Here are the key results explained simply:
- Many top models ignore penalties and rarely abstain.
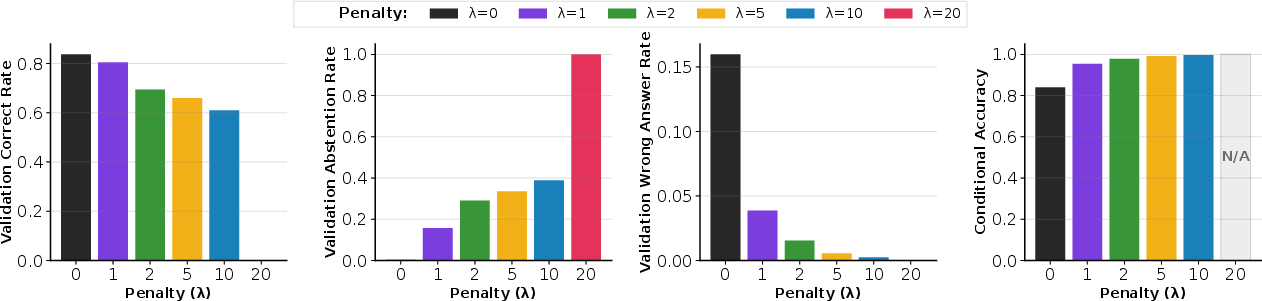
- Even when told they’d lose points for wrong answers, they almost never said “I don’t know” (abstention rates often under 1%), while still making many mistakes (over 10%). This means current training makes them prefer “any answer” over “no answer.”
- RH (the new training method) teaches models to be honest and careful.
- With small penalties (like λ = 1–2), models answered most easy problems but wisely declined many hard ones. Wrong answers fell from about 15% to under 2%.
- With larger penalties (λ ≥ 10), models became very cautious, almost never wrong, and abstained often on hard problems. This is great for high‑risk domains.
- “I don’t know” becomes a helpful signal, not a failure.
- When a model says “I don’t know,” it’s flagging a hard or risky problem. The authors use this to route questions to the right model.
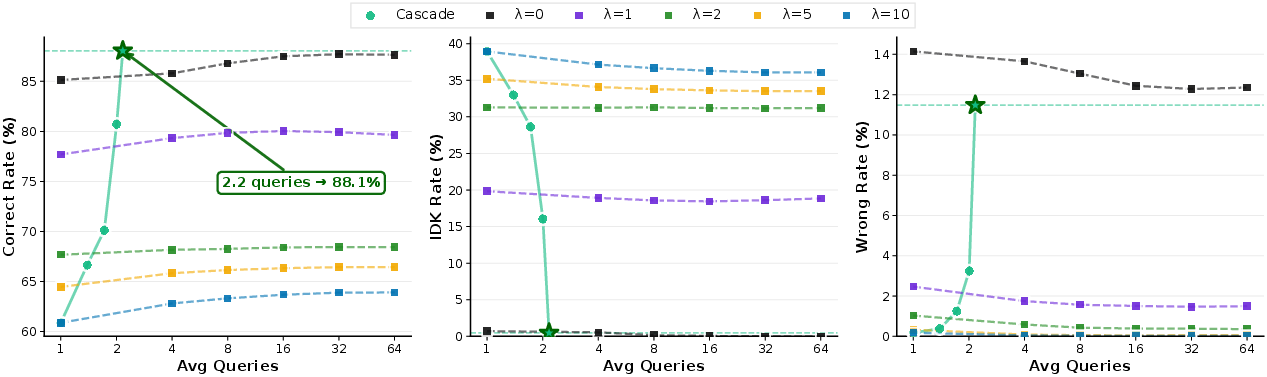
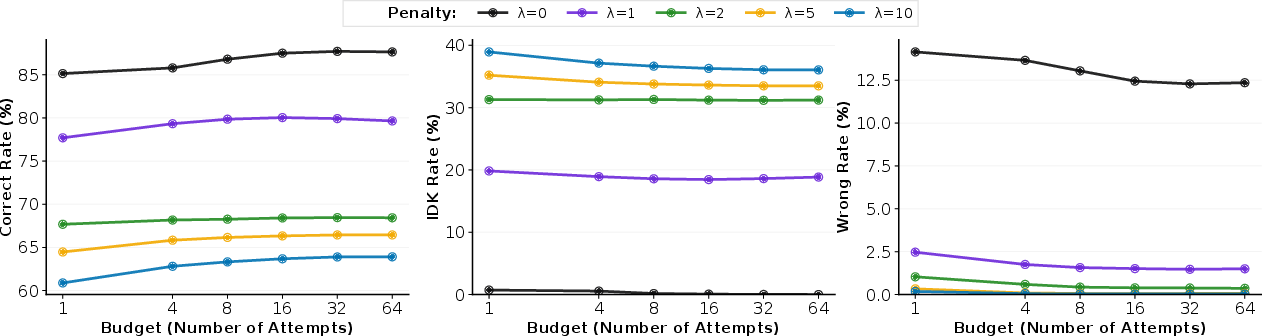
- Cascading (from cautious to bold) achieved about 88% accuracy while only needing 2.2 tries on average—better than majority voting and cheaper to run.
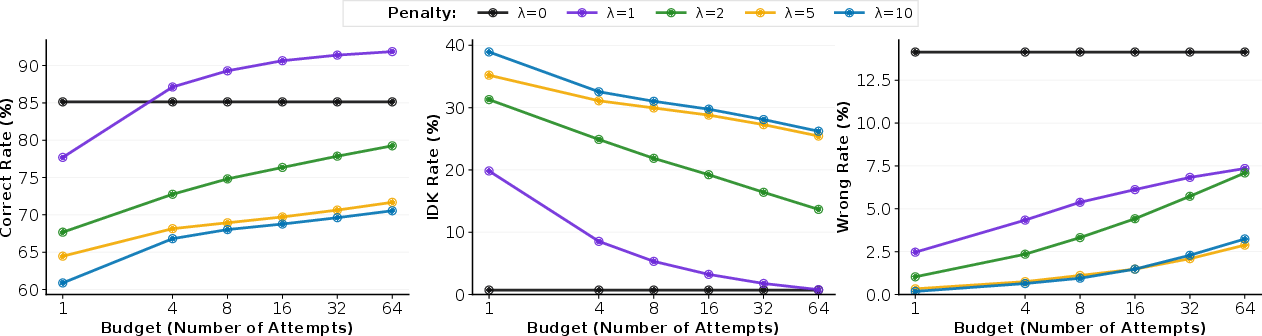
- Self‑cascading (re‑asking the same model) boosted accuracy of a moderately cautious model (λ = 1) from about 77.5% to 92.5% by giving it more chances to find a confident path.
- Different penalties create different “specialist” models.
- No single model is best for all situations. Models trained with different λ values form a “Pareto frontier,” meaning each one is optimal for a particular risk level. For example:
- λ = 0: aggressive answerer (good when mistakes are cheap)
- λ = 1–5: balanced models (good for mixed difficulty)
- λ ≥ 10: conservative abstainer (good when mistakes are costly)
- Extra bonus: models learned to be more concise.
- Because long answers that get cut off are penalized, models trimmed their responses, saving compute time by 25–30% while keeping high reliability.
What could this change in the real world?
- Trustworthy AI in high‑stakes areas: Doctors, pilots, and judges don’t guess when they’re unsure. With RH, AI can act similarly—admitting uncertainty instead of inventing confident‑sounding wrong answers.
- Better teamwork between AIs and people: “I don’t know” can trigger escalation to a more capable model or a human expert, making systems safer and more efficient.
- Smarter evaluation of AI: Instead of only measuring accuracy, we should consider the cost of mistakes. Choose the right λ for your domain to get the behavior you need.
- More reliable AI pipelines: Cascading and self‑cascading convert hesitation into higher accuracy with fewer checks, which is especially useful when verification is expensive or time‑consuming.
Simple explanations of key ideas
- Abstention: When the model says “I don’t know” instead of guessing.
- Penalty λ: A number that shows how bad mistakes are. Bigger λ means guessing is more dangerous.
- Reinforced Hesitation (RH): A training method that rewards correct answers, doesn’t punish honest “I don’t know,” and penalizes wrong answers.
- Pareto frontier: A set of “best trade‑off” models where each one is the best for certain goals (e.g., safety vs. coverage). None beats all the others in every way.
- Cascading: Sending questions through a lineup of models from careful to bold until someone answers.
- Self‑cascading: Asking the same model again after it says “I don’t know,” because a new attempt may find a better reasoning path.
In short, this paper shows that teaching AI to value honesty over blind accuracy makes it safer, more trustworthy, and ultimately more useful—especially when the cost of being wrong is high.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable directions for future research.
- Generalization beyond synthetic logic puzzles: Evaluate Reinforced Hesitation (RH) on diverse, real-world, verifiable tasks (math word problems, coding, theorem proving, retrieval QA) and high-stakes domains (MedQA, GPQA) with RH-trained models, not just penalty-blind prompting of frontier models.
- Scaling to larger models: Replicate RH with frontier-scale LLMs (tens to hundreds of billions of parameters) to assess whether observed Pareto trade-offs, calibrated abstention, and conditional accuracy gains persist at scale.
- Mapping λ to real-world risk: Develop principled methods to set the penalty parameter λ based on domain-specific error costs and verification costs, including empirical risk modeling and guidelines for stakeholders (e.g., clinical decision support, legal analysis).
- Dynamic and per-instance λ: Explore adaptive policies that infer a query-specific λ (or confidence threshold) from metadata, task type, user profile, or upstream models, instead of a fixed global penalty.
- Confidence estimation and calibration: Test whether RH improves the calibration of the model’s implicit probability of correctness; develop methods to estimate and calibrate per-instance confidence to align with abstention thresholds .
- Mode collapse prevention at high λ: Design and evaluate training-time regularization or multi-objective constraints to avoid universal abstention (observed for λ=20) while maintaining low error rates (e.g., coverage floors, exploration bonuses, curriculum λ schedules).
- Interaction with RLHF and multi-objective post-training: Examine how RH interacts with helpfulness/harmlessness objectives and preference models; paper joint optimization (RLHF + RH) to balance correctness, abstention, and user satisfaction.
- Robustness under distribution shift: Measure whether RH-trained abstention remains calibrated for out-of-distribution inputs, adversarially perturbed prompts, and domain shifts (e.g., novel topics, atypical formats).
- Adversarial prompt robustness: Test whether abstention behavior can be bypassed via jailbreaks or instruction attacks; develop defenses that preserve abstention under adversarial prompting.
- Reward shaping details: Justify and empirically compare the format penalty scaling (−0.5λ) with alternatives (fixed penalties, separate format rewards, constraint-based decoding) to ensure abstention and correctness are not conflated with formatting.
- Sensitivity to decoding and nondeterminism: Quantify how self-cascading gains depend on sampling parameters (temperature, top-p), seeds, and hardware variability; provide reproducible protocols and variance analyses.
- Cascade design optimization: Formalize and learn optimal cascade ordering, stopping criteria, and budgets that jointly optimize accuracy, abstention, error cost, and verification cost; compare heuristic vs learned routers.
- Integration with external verifiers and tools: Investigate routing from abstention to programmatic tools (solvers, proof checkers, retrieval, calculators) and measure end-to-end accuracy, verification overhead, and failure modes.
- Verification cost modeling: Replace abstract penalty claims with measured verification costs (human time, computational runtime) across tasks; validate 2.2-average-query claims under realistic verification pipelines.
- Stronger baseline comparisons: Benchmark RH against established uncertainty/abstention methods (selective prediction losses, confidence-calibrated deferral, self-consistency, debate, ensemble agreement, gatekeeper models) in matched settings.
- Human-centered trust evaluation: Conduct user studies to quantify whether RH-trained abstention improves perceived trust, satisfaction, and decision quality; evaluate communication of uncertainty and acceptability of increased abstention.
- Fairness and coverage analyses: Test whether abstention disproportionately affects certain topics, dialects, languages, or user groups; develop metrics and mitigations for biased coverage gaps introduced by abstention.
- Cross-lingual generality: Validate RH in multilingual settings and non-English inputs; ensure abstention signaling and parsing are robust across languages.
- Abstention signal design: Move beyond a fixed phrase (“I don’t know”); design robust, machine-parsable abstention signals for open-ended tasks, multi-tool agents, and multimodal outputs.
- Theoretical guarantees: Provide formal analysis of RH (e.g., existence of threshold-optimal policies, convergence properties with RLVR/RLO objectives, regret bounds under miscalibration and distribution shift).
- Effect on reasoning quality: Measure how RH affects chain-of-thought quality, brevity, and correctness; test whether improved conditional accuracy generalizes across tasks with different reasoning structures.
- Dataset construction and difficulty labeling: Specify and validate the “logical complexity” criteria for easy/hard splits; release generation code and difficulty metrics; assess how difficulty definitions affect learned abstention.
- Replicability and variance: Report multiple training runs, confidence intervals, and sensitivity analyses for RH outcomes (e.g., transient “crisis” at step ~80) to rule out optimization artifacts.
- Context length and truncation: Study how RH behaves with longer contexts and higher token limits; quantify the trade-off between response compression, truncation penalties, and reasoning completeness.
- Human-in-the-loop escalation: Prototype workflows where model abstention triggers structured handoff to human experts; measure throughput, error reduction, and user burden in real deployments.
- Ethical and operational guidance: Develop domain-specific guidelines for acceptable abstention rates, communication strategies, and escalation policies to avoid harmful refusals (e.g., emergency contexts) while minimizing catastrophic errors.
Glossary
- Abstention: The deliberate choice by a model to not provide an answer when uncertain, treated as a valid outcome in training and evaluation. "These results establish abstention as a first-class training objective that transforms ``I don't know'' from failure into a coordination signal"
- Autoregressive models: Models that generate outputs token-by-token, where each token depends on previous ones, often sampled stochastically. "allowing alternative reasoning paths to emerge through inherent random sampling in autoregressive models"
- BabyBear: A prior cascade approach that relies on post-hoc confidence calibration to route queries across models. "Traditional cascades like BabyBear \citep{Khalili2022babybear} rely on post-hoc confidence calibration"
- Cascading: An inference strategy that sequentially routes queries through models ordered by decreasing risk tolerance, using abstention as a delegation signal. "cascading routes queries through models with decreasing risk tolerance"
- Chain-of-thought: A prompting style that elicits step-by-step reasoning before the final answer. "we extend the standard chain-of-thought prompt to include explicit abstention instructions"
- Confidence threshold: A decision boundary determining when to answer versus abstain under cost-aware rewards. "creating a natural decision boundary at confidence threshold "
- Consensus filtering: Reducing errors by aggregating multiple responses and favoring majority agreement. "The primary benefit is error reduction through consensus filtering"
- Conditional accuracy: Accuracy measured conditioned on the model choosing to answer (excluding abstentions). "higher achieves both lower error rates and higher conditional accuracy"
- Early exit: A cascaded inference mechanism that stops querying once a non-abstention answer is produced. "The sequential structure with early exit ensures that each problem engages only the necessary models"
- Epistemic efficiency: Producing concise reasoning aligned with confidence and cost constraints, avoiding unnecessary verbosity. "What began as a computational constraint thus became a mechanism for teaching epistemic efficiency"
- Epistemic prudence: The calibrated tendency to refrain from guessing when consequences are severe or uncertainty is high. "Models trained under RLVR lack this epistemic prudence"
- Frontier models: State-of-the-art LLMs at the cutting edge of performance and capability. "our evaluations on GSM8K, MedQA and GPQA show frontier models almost never abstain"
- GPQA: A benchmark for graduate-level question answering used to evaluate reasoning and abstention behavior. "For MedQA and GPQA, which are multiple-choice datasets, we append an extra option"
- GSM8K: A grade-school math word problem benchmark commonly used to evaluate reasoning. "Penalty sensitivity of frontier models on GSM8K."
- Knights and Knaves: A class of logic puzzles involving truth-telling knights and lying knaves, used for controlled reasoning experiments. "A very special island is inhabited only by knights and knaves."
- Majority voting: An ensemble method that aggregates multiple model outputs and selects the most common answer. "Both outperform majority voting with lower computational cost."
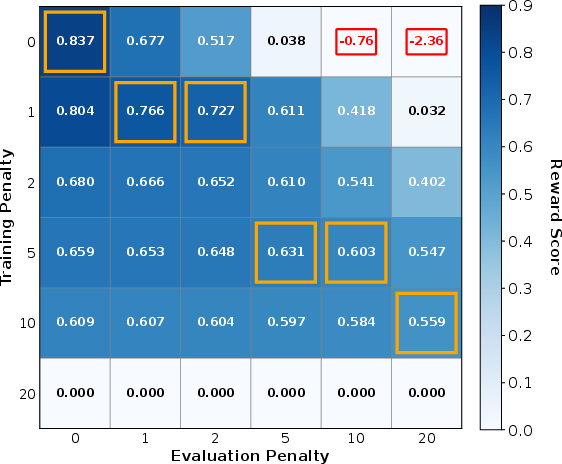
- Mutual non-domination: A Pareto concept where no single model is strictly better across all evaluation penalties or objectives. "our cross-evaluation reveals mutual non-domination"
- Nondeterminism: The inherent variability in LLM outputs across runs due to stochastic sampling and computational instabilities. "LLM inference is inherently nondeterministic"
- Pareto frontier: The set of models that achieve optimal trade-offs where improving one objective requires sacrificing another. "Reinforced Hesitation creates a Pareto frontier of models"
- Pass@K: An evaluation metric counting success if any of K generated solutions are correct, often requiring costly verification. "Even Pass@K approaches become prohibitive here"
- Penalty parameter λ: A scalar controlling the cost of wrong answers relative to abstentions and correct answers in the reward scheme. "The penalty parameter encodes both domain-specific consequences and verification costs"
- Preference proxy: The learned scalar reward model used in RLHF to represent human preferences for helpfulness and harmlessness. "RLHF optimizes a learned human preference proxy"
- Reinforced Hesitation: A training method that assigns ternary rewards to teach models when not to answer, aligning behavior with risk. "we propose Reinforced Hesitation (RH): a modification to Reinforcement Learning from Verifiable Rewards (RLVR)"
- Reinforcement Learning from Human Feedback (RLHF): A post-training paradigm that optimizes model outputs using learned human preference signals. "RLHF improves helpfulness and harmlessness but treats abstention as failure to be helpful"
- Reinforcement Learning from Verifiable Rewards (RLVR): A post-training paradigm using binary verification rewards for correct vs. incorrect answers. "reinforcement learning from verifiable rewards (RLVR) \citep{DeepSeekAI2025R1,lambert2025tulu3,Muennighoff2025s1,jaech2024o1,google2025gemini25Pro}, the paradigm driving state-of-the-art reasoning models."
- Schema penalty: A format-based penalty applied when outputs violate prescribed tags or structure. "we apply a schema penalty of "
- Self-cascading: An inference strategy that re-queries the same model after abstention to explore alternative reasoning paths. "self-cascading re-queries the same model on abstention."
- Selective prediction: A framework where models can abstain (reject) to trade coverage for accuracy. "The concept of selective prediction with reject options has been extensively studied"
- Ternary reward structure: A reward design with three outcomes: +1 for correct, 0 for abstain, and −λ for wrong. "Reinforced Hesitation formalizes the intuition that hesitation as a possible outcome should be valuable through a simple ternary reward structure"
- Triage: An inference routing process that delegates queries to appropriate specialists based on abstention and risk tolerance. "achieves efficient triage where each specialist handles problems matching its confidence regime."
- Verification costs: The time or resources required to check correctness of outputs, varying widely across domains. "verification costs that vary by orders of magnitude"
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now by leveraging Reinforced Hesitation (RH), cascading, and self-cascading as described in the paper. Each bullet notes the sector, the concrete workflow/product idea, and assumptions or dependencies that affect feasibility.
Software and AI Platforms
- Risk-aware reasoning APIs for math/coding tasks (software): expose a
risk_penalty (λ)parameter and a first-class “I don’t know” token in SDKs; provide telemetry on coverage, error, and abstention rates; allow users to choose λ per request or per route. Assumptions/Dependencies: verifiable tasks and robust output parsing; access to post-training RLVR or fine-tuning pipelines; user education on λ-to-confidence mapping (). - RH training plug-in for RLVR stacks (software): drop-in adapter that changes binary rewards to ternary (+1/0/−λ), plus a format penalty; ships with evaluation harness using cost-sensitive metrics and Pareto reporting. Assumptions/Dependencies: ability to modify RLVR stage; tasks with automatic verification or cheap adjudication.
- Inference routers implementing cascading and self-cascading (software): microservices that route queries through a λ-ordered model family (high→low risk aversion) with early exit; optional self-cascade within a single model on abstention. Assumptions/Dependencies: access to a small family of λ-tuned models, or a single model for self-cascade; stable “I don’t know” schema; budget controls.
Healthcare
- Clinical decision-support triage (healthcare): conservative λ models answer only high-confidence cases; abstentions trigger escalation to specialists or second-line models/tools; logs show abstention as a safety event rather than failure. Assumptions/Dependencies: clinical verification pathways; human-in-the-loop; regulatory review; careful λ selection to match clinical risk; guardrails for domain shift.
- Safer patient-facing symptom checkers (healthcare): high-λ chatbot that abstains on uncertain differentials and routes users to care or clinician chat. Assumptions/Dependencies: clear escalation workflows; liability and patient safety policies; calibrated messaging to avoid false reassurance.
Finance and Compliance
- Compliance Q&A and policy assistants (finance): λ-tuned assistants abstain on ambiguous regulations, auto-attach citations, and open tickets for compliance officers on abstention; dashboards track coverage vs. error. Assumptions/Dependencies: access to authoritative corpora and validators; audit logging; acceptance by risk and compliance teams.
- High-confidence-only coding for quant/risk tools (finance/software): in CI/CD, code LLMs answer only when above λ-threshold; abstentions route to human review. Assumptions/Dependencies: test or spec-based verification; IDE/CI integration.
Legal and Research
- Legal research assistants with abstention-as-escalation (legal): conservative λ model drafts answers only when confident and flags uncertainty; abstentions prompt targeted search or attorney review. Assumptions/Dependencies: citation verifiers; authority ranking; malpractice/risk protocols.
- Scientific reasoning and theorem-proving or code-verification pipelines (academia/software): RH-trained models attempt proofs or patches; abstentions automatically defer to alternative provers or human experts; track compute savings from response compression. Assumptions/Dependencies: verifiers (proof checkers, tests); orchestration to switch tools on abstention.
Education
- Tutors with pedagogical abstention (education): models abstain when uncertain, prompting metacognitive scaffolds (e.g., “let’s check definitions”) or escalation to teacher; show conditional accuracy when answering. Assumptions/Dependencies: curriculum alignment; teacher oversight; clear UX for abstention.
Customer Support and Operations
- Helpdesk bots that abstain and escalate (software/customer service): conservative λ first-line bot answers high-confidence queries; abstentions open human tickets with context; measure reductions in confidently wrong resolutions. Assumptions/Dependencies: CRM integration; staffing for escalations; SLA updates to count abstentions distinctly from errors.
- Content moderation triage (platforms): abstentions on borderline items route to human moderators; track false-positive/false-negative trade-offs via λ tuning. Assumptions/Dependencies: reviewer workflows; legal/compliance considerations.
Cybersecurity and DevOps
- Alert triage with abstention (cybersecurity): high-λ agent suppresses speculative actions; abstentions escalate to SOC analysts or sandbox checks; track conditional accuracy of automations. Assumptions/Dependencies: strong containment; playbooks for escalation; verifiable outcomes.
- High-confidence-only code suggestions in IDE/CI (software): abstain when tests or specs are insufficient; self-cascade to explore alternative completions before presenting an answer. Assumptions/Dependencies: quick verification (tests, linters); nondeterministic decoding for self-cascade.
Governance, Evaluation, and SRE
- Cost-sensitive evaluation and dashboards (all sectors): replace accuracy-only leaderboards with “Correct − λ·Wrong, Abstain=0” plus conditional accuracy and coverage; visualize Pareto frontier across λ. Assumptions/Dependencies: logging correctness, errors, and abstentions; buy-in for risk-adjusted metrics.
- Compute-aware inference (MLOps): exploit response compression (shorter outputs, fewer clips) observed under RH; auto-scale budgets based on abstention frequency; early exit on cascade success. Assumptions/Dependencies: adherence to output schema; budget control and telemetry.
Long-Term Applications
These applications require further research, scaling, or ecosystem development, but are directly motivated by the paper’s findings and methods.
RH-Native Model Families and Orchestration
- Adjustable-λ models at inference (software): architectures or policy heads that modulate the effective λ per request without retraining multiple models; dynamic λ set by task policy or user profile. Assumptions/Dependencies: training schemes that disentangle knowledge from risk preferences; calibration to keep thresholds reliable across domains.
- Multi-agent systems that use abstention as a coordination protocol (software/robotics): agents specialize by λ and route tasks using abstention signals; combine with tool-use (retrieval, simulators) when abstaining. Assumptions/Dependencies: stable abstention semantics; agent communication protocols; robust tool selection.
Sector-Scale Safety and Regulation
- Standards for abstention calibration and selective prediction (policy/standards): certification that models meet minimum abstention performance and conditional accuracy at declared λ in specified domains; procurement policies require cost-sensitive metrics. Assumptions/Dependencies: consensus benchmarks with verifiable answers; third-party auditors and shared metrics (e.g., “Abstention Calibration Score”).
- Liability and documentation frameworks (policy): require published λ policies, escalation pathways, and abstention logs for high-stakes deployments (healthcare, aviation, energy). Assumptions/Dependencies: legal harmonization; incident reporting norms; privacy considerations.
High-Stakes Autonomy and Control
- “Pause-and-request-guidance” behavior in robots and autonomous systems (robotics/transport/energy): abstention triggers safe states, human teleoperation, or higher-fidelity simulation before proceeding. Assumptions/Dependencies: reliable fail-safe mechanisms; real-time human-in-the-loop; formal verification for control logic.
- Grid, industrial, and medical device controllers with RH (energy/manufacturing/healthcare): risk-sensitive decision thresholds encoded via λ; abstentions initiate fallback procedures or human supervision. Assumptions/Dependencies: formal hazard analyses; dual-channel control; regulatory approval.
Tool-Integrated Reasoning and Formal Methods
- RH-integrated toolformers (software): abstention triggers retrieval, program synthesis, or formal solvers; self-cascade budgets adapt to tool confidence and verification cost. Assumptions/Dependencies: robust tool APIs and verifier availability; intelligent budget allocation.
- Large-scale verifiable training corpora (academia/industry): expand beyond math/coding to domains with structured verification (contracts with testable clauses, lab protocols with checklists, regulatory Q&A with gold standards). Assumptions/Dependencies: data creation and labeling; scalable validators.
Market, Product, and UX Innovations
- Risk-tiered model marketplaces (software): providers offer λ-specialized families (e.g., λ=10 for high-assurance triage, λ=1 for general productivity) with trust SLAs reporting coverage, error, and abstention. Assumptions/Dependencies: standardized reporting; user education; pricing aligned to risk and verification costs.
- Edge-to-cloud cascades (IoT/edge): conservative on-device model abstains on hard queries and escalates to larger cloud models; reduces latency and costs while keeping safety. Assumptions/Dependencies: consistent abstention formats across tiers; bandwidth/security constraints.
- Personalized risk policies (enterprise): organizational or per-user λ profiles tied to task type, data sensitivity, and verification budgets; policy engines enforce λ and routing automatically. Assumptions/Dependencies: policy authoring tools; identity and context signals; auditability.
Human–AI Collaboration and Trust Research
- Longitudinal studies on trust and adoption (academia): measure whether calibrated abstention improves user trust and decision quality across domains; paper how abstention frequency affects perceived competence. Assumptions/Dependencies: access to real workflows; IRB approvals; domain-partner collaboration.
Notes on cross-cutting assumptions
- Verifiability: RH excels when answers can be checked; extension to weakly verifiable domains will need hybrid validators or human adjudication.
- Calibration and generalization: λ-thresholds must remain meaningful under domain shift; periodic recalibration and monitoring are essential.
- Format and parsing: stable “I don’t know” schemas and format penalties are critical to prevent reward gaming and to enable routing.
- Budget and nondeterminism: self-cascading relies on stochastic decoding and budget control; governance should cap retries by risk class.
- Socio-technical fit: abstention requires escalation paths, staffing, SLAs, and UX that explain uncertainty without eroding user confidence.
Collections
Sign up for free to add this paper to one or more collections.