Open-TQ-Metal: Fused Compressed-Domain Attention for Long-Context LLM Inference on Apple Silicon
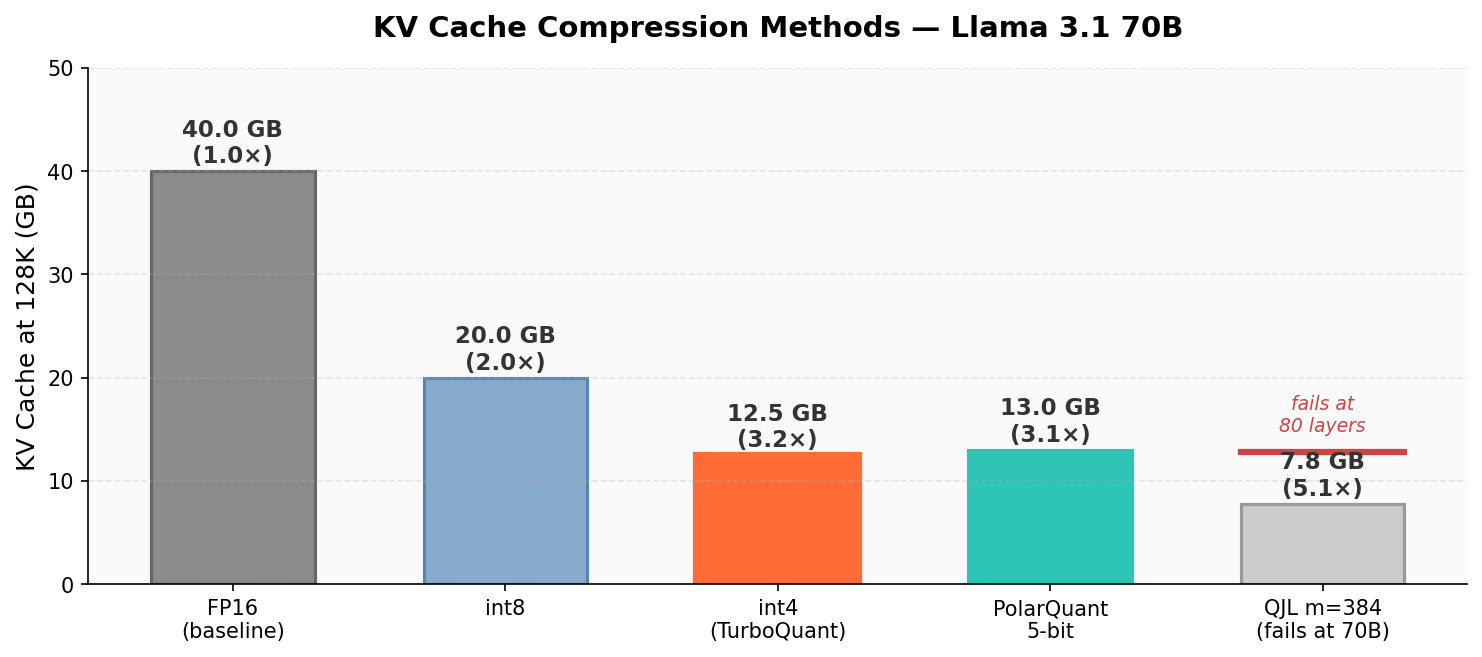
Abstract: We present Open-TQ-Metal, the first implementation of fused compressed-domain attention on Apple Silicon, enabling 128K-context inference for Llama 3.1 70B on a single 64GB consumer Mac -- a configuration impossible with all existing inference frameworks. Open-TQ-Metal quantizes the KV cache to int4 on the fly and computes attention directly on the compressed representation via custom Metal compute shaders, eliminating all intermediate dequantization matrices. Across 330 experiments spanning two model families (Gemma 4 31B and Llama 3.1 70B), the fused sdpa_int4 kernel achieves 48x attention speedup at 128K context over the dequantize-then-attend baseline, reduces KV cache memory from 40 GB to 12.5 GB (3.2x compression), and maintains identical top-1 token predictions to FP16 inference. We further provide the first cross-architecture analysis of KV cache quantization methods, revealing that the attention scale factor -- not model size -- determines whether angular quantization schemes like PolarQuant succeed or fail, with Gemma 4's attn_scale=1.0 amplifying directional error 25-100x more than Llama's standard 1/sqrt(d) scaling.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper shows a new way to run very large AI LLMs with super-long memories (up to 128,000 tokens of text) on regular Apple laptops and desktops with 64 GB of memory. Normally, that would be impossible because the model’s “memory” during reading (called the KV cache) gets too big. The authors created Open-TQ-Metal, a set of custom GPU kernels for Apple’s Metal graphics system that compress this memory and do the attention math directly on the compressed data. That makes it fast and small enough to fit—and it still gives the same answers as before.
What questions the researchers wanted to answer
- Can we run a huge model like Llama 3.1 70B using its full long context (128K tokens) on a 64 GB Mac, even though normal methods run out of memory?
- Can we make attention (the model’s way of focusing on the right parts of the text) fast even when everything is compressed?
- Which compression methods work best on different model designs, and why do some fail for certain models?
How they did it (with simple explanations)
To follow this, think of three ideas:
- KV cache as a backpack: As the model reads more text, it stores “keys” and “values” (summaries of what was read) in a backpack. Longer text = heavier backpack. Normally, this gets too heavy (too big) to carry on a 64 GB machine.
- Compression like zipping files: The authors shrink KV data from 16-bit numbers down to 4-bit numbers (int4), cutting size by about 3.2×. But instead of unzipping before using it, they do calculations directly on the zipped data.
- Fused attention = calculating without unpacking: They built a special “fused” attention kernel that reads the compressed KV cache and does the attention math on-the-fly inside the GPU registers (the fastest on-chip memory), so it never creates big temporary “unpacked” copies.
What they actually built:
- A custom “fused int4 SDPA” kernel for Apple Metal that:
- Keeps KV cache in 4-bit form.
- Pulls out tiny 4-bit chunks with bit tricks inside the GPU.
- Runs the attention math (including the softmax) in small steps without intermediate giant matrices.
- Split-K parallelism: For very long texts, they split the KV cache into chunks, process them in parallel, and then combine the results with the right math so it’s as if it were done all at once.
- Smart prefill vs. decode: During the “reading in” stage (prefill), they use standard fast methods and then store compressed KV. During “generate next word” steps (decode), they use the fused int4 kernel for best performance.
- Wired memory: They pin model weights in memory so macOS doesn’t move them to the SSD, avoiding huge slowdowns.
They also tested different compression methods across two model families (Llama and Gemma) and discovered a key design detail that decides whether a method will work.
What they found and why it matters
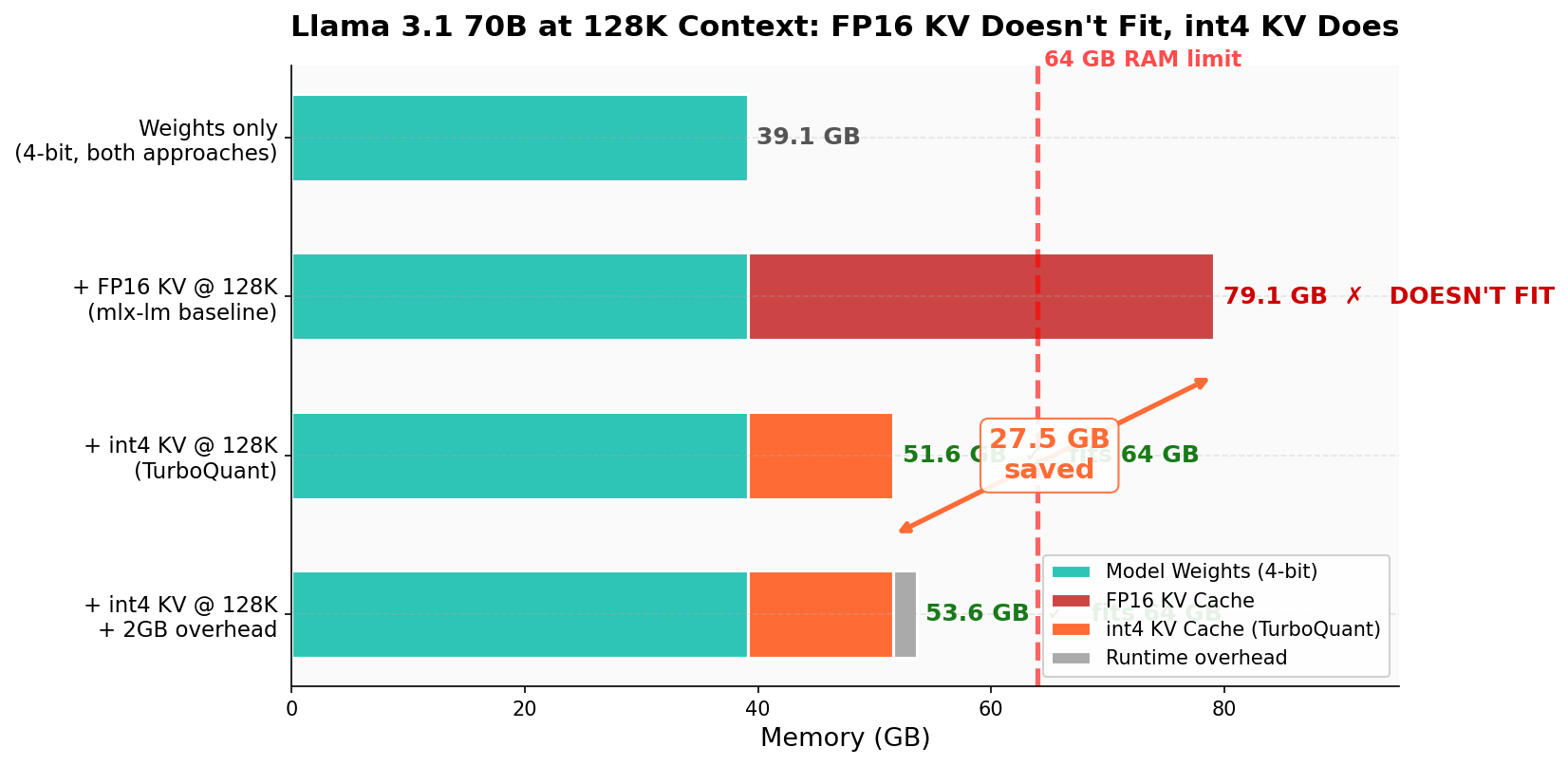
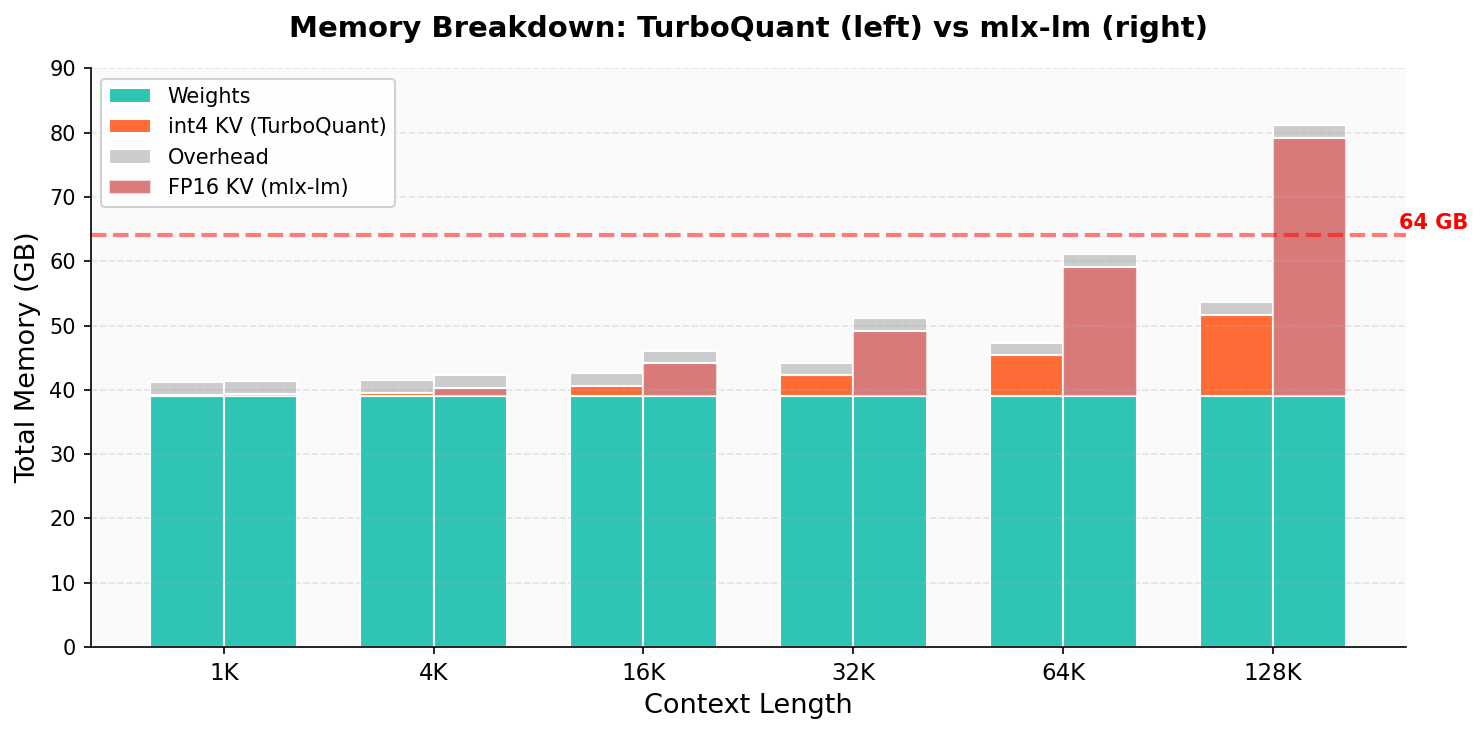
- Fits where it didn’t before:
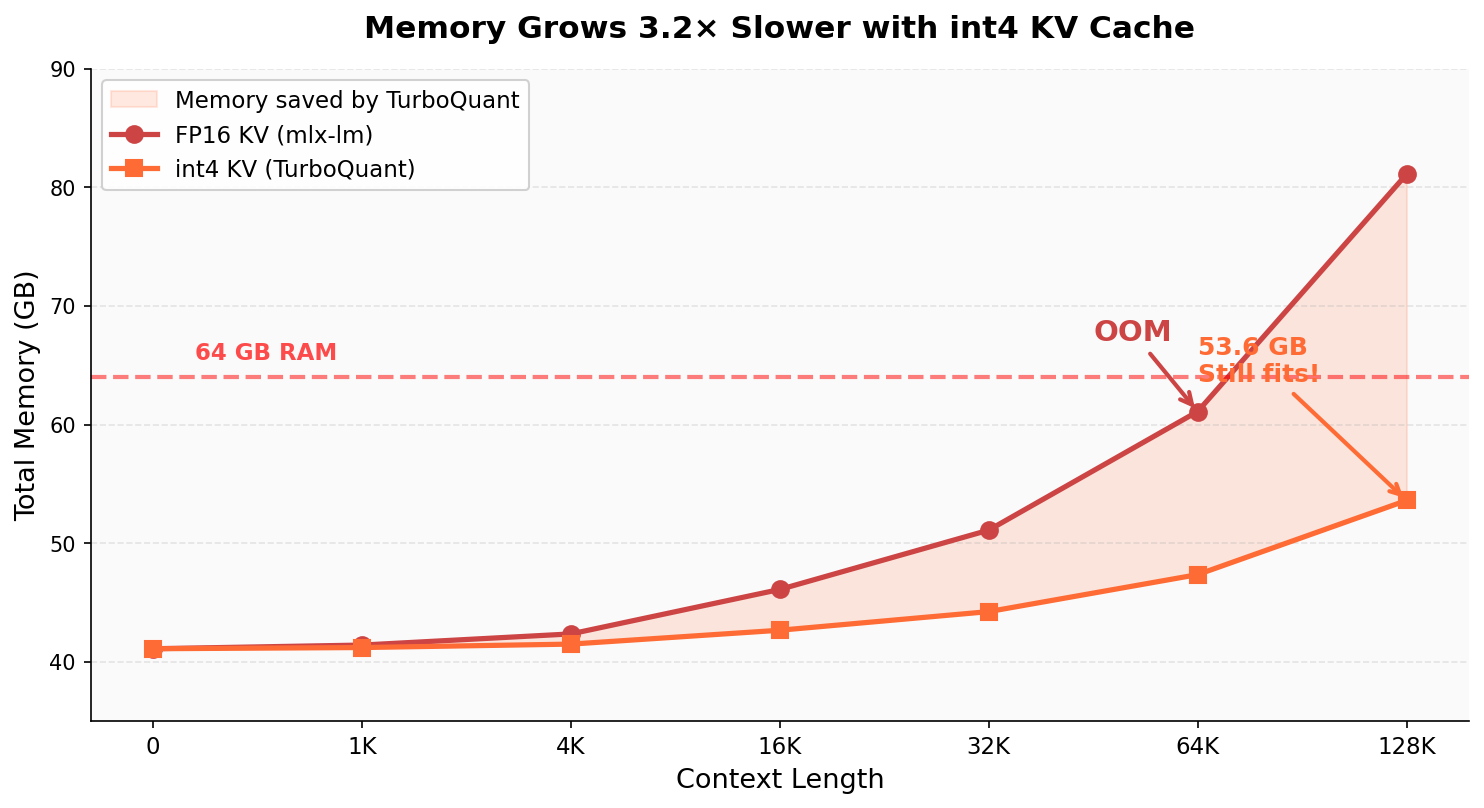
- Llama 3.1 70B at 128K tokens normally needs about 79 GB just for weights + KV cache in FP16—too big for 64 GB.
- With their int4 KV cache and fused attention, the total fits in ~53.6 GB on a 64 GB Mac, with room to spare.
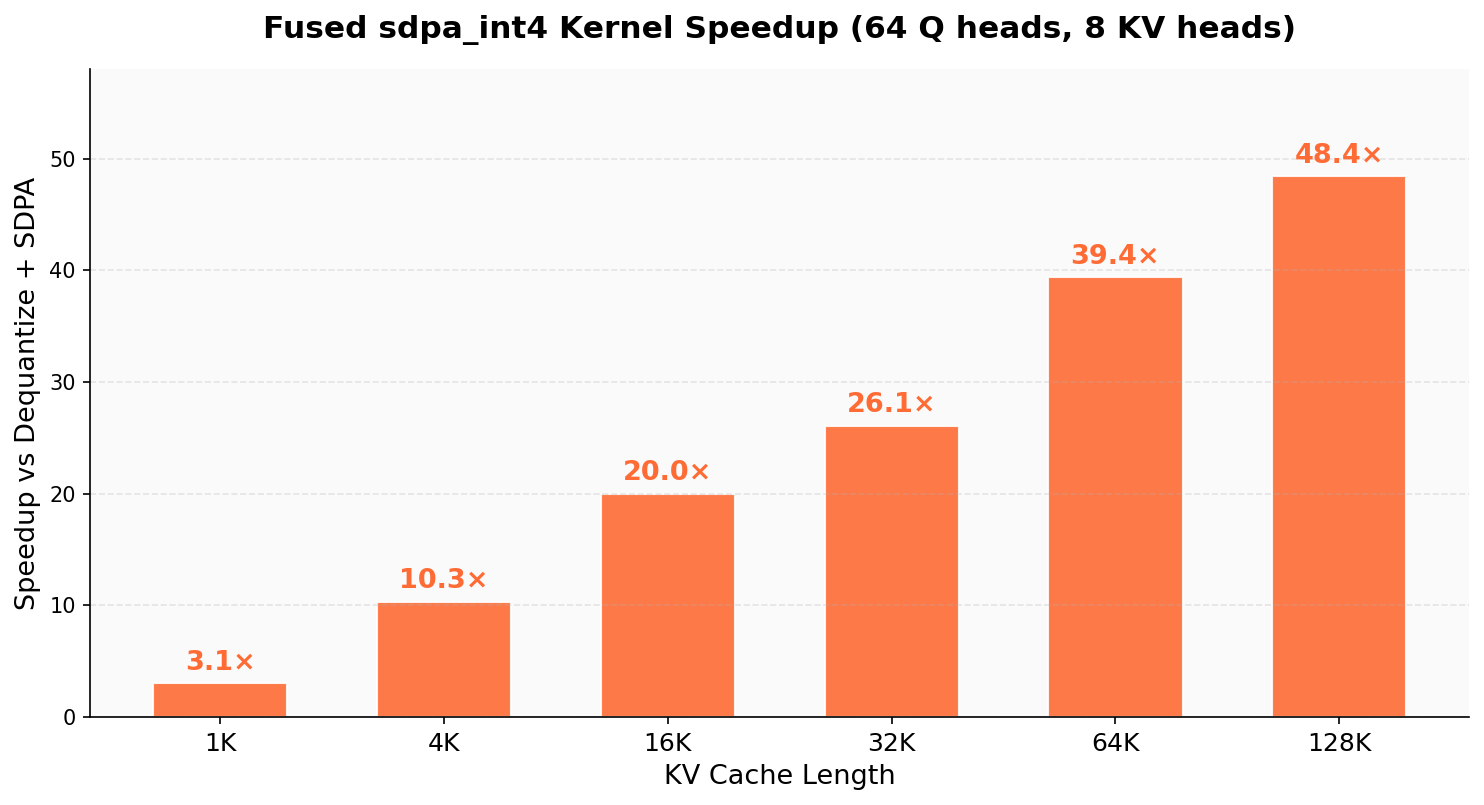
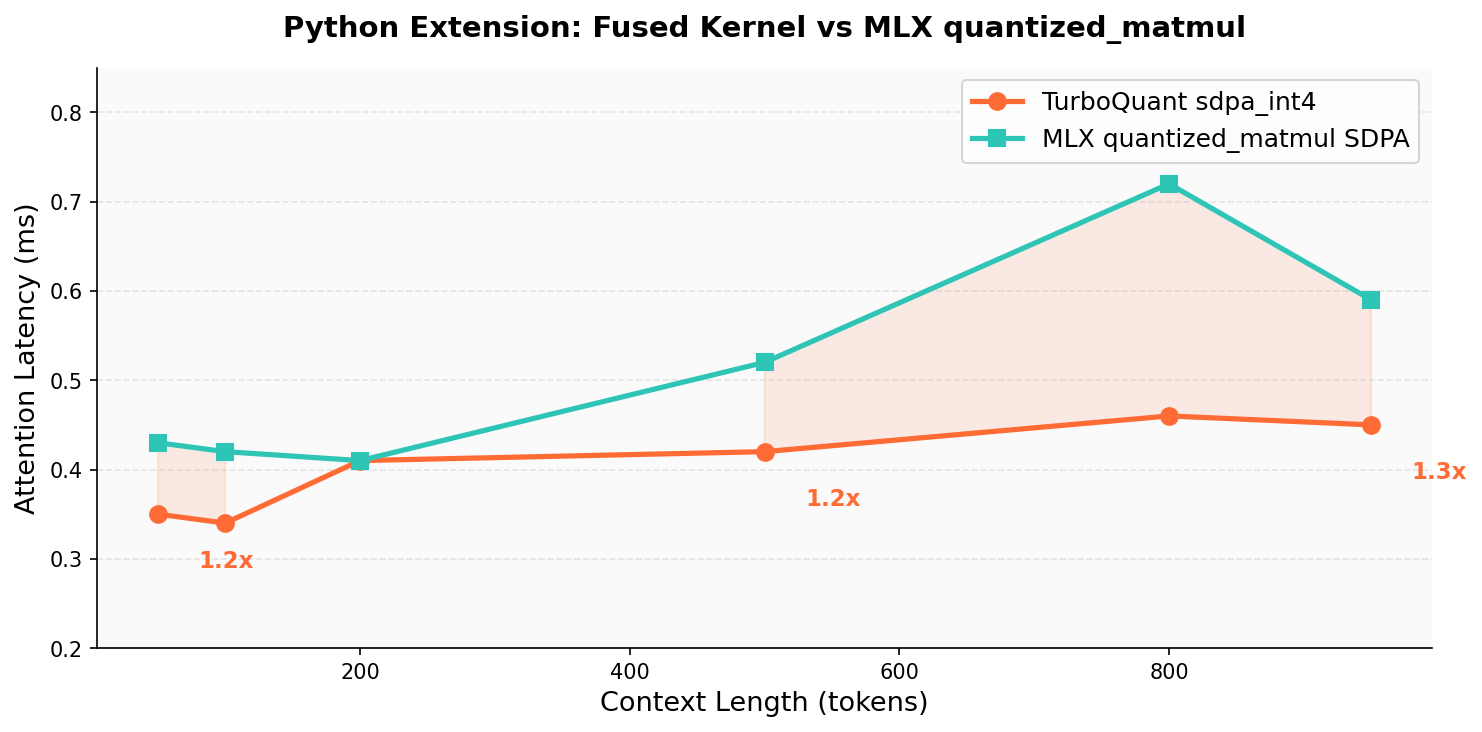
- Big speedups for attention:
- Their fused attention kernel is up to 48× faster at 128K context than the “decompress first, then compute” approach.
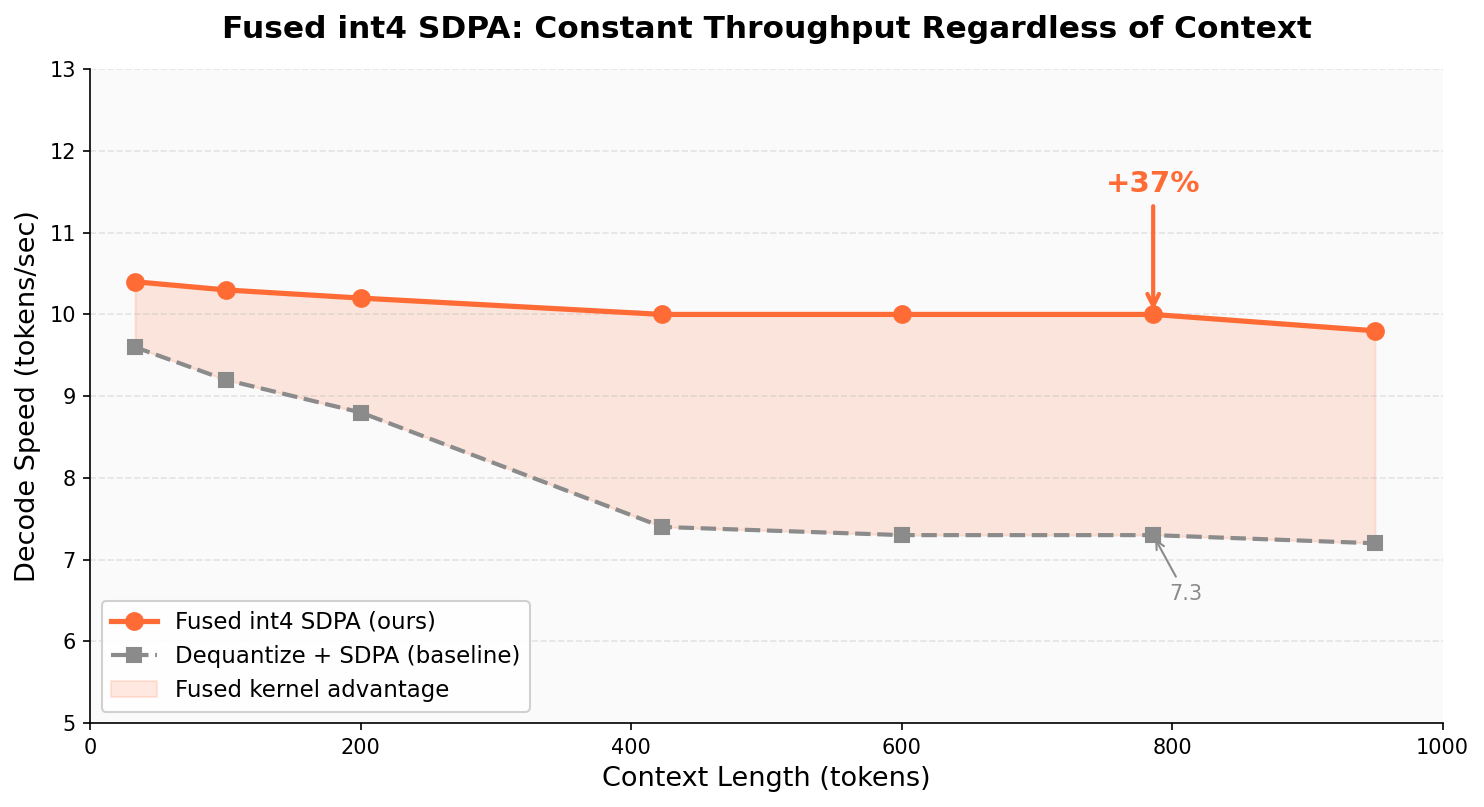
- End-to-end throughput on Llama 70B at 128K is around 6 tokens/second on a 64 GB M1 Max—slow but previously impossible.
- Same top-1 outputs:
- The model’s next-token choices (greedy decoding) match the original FP16 version, so quality stays intact in their tests.
- The secret deciding factor: attention scale
- Different models scale attention scores differently (think of it like how loud the volume knob is).
- Llama uses a small scale ( ≈ 0.0884), which dampens small errors from angular/“direction-based” compression methods like PolarQuant.
- Gemma 4 uses a large scale (1.0), which amplifies those small errors into big problems. So PolarQuant works on Llama but fails on Gemma 4.
- What didn’t work for very deep models:
- A binary-sketch method called QJL (storing only signs) looks okay layer-by-layer, but the small errors stack up across many layers in big models (like 70B), eventually ruining the signal.
Why this is important:
- It brings long-context AI to consumer Macs without special hardware.
- It shows that doing math directly on compressed data isn’t just possible—it’s much faster and saves lots of memory.
- It reveals that a single architectural detail (attention scale) can make or break certain compression methods, guiding future model and kernel design.
What this could mean going forward
- More capable AI on everyday devices: Long-context models can read and reason over much bigger documents, codebases, or transcripts on a regular Mac.
- Better design choices for future models: Model builders might choose attention scales that are more friendly to compression methods (or pick compression methods that fit the model’s scale).
- Wider hardware support: The ideas (fused compressed attention, split-K) can be adapted to other platforms like CUDA GPUs, helping more users.
- Limits to keep in mind:
- There’s still a “bandwidth wall” (how fast memory can be read) that caps speed for giant models.
- Very long contexts and certain model designs (like Gemma’s scaling) may still see quality drop-offs; more testing is needed on long-context benchmarks.
- Some speed gaps vs. other frameworks come from engineering details (like buffer management) that can likely be improved.
In short, this work shows a practical, open-source way to run huge, long-context LLMs on Apple Silicon by compressing their memory and computing directly on that compressed form—fast, small, and accurate—while also teaching us which model designs play nicely with which compression tricks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following gaps and open questions that warrant further investigation:
- Long-context quality evaluation is incomplete: no results on standard long-context benchmarks (e.g., RULER, Needle-in-a-Haystack, LongBench) at 128K–236K; only top-1 token agreement under greedy decode is reported.
- Sensitivity to decoding strategies is untested: impact of KV int4 on sampling (temperature/top-p), beam search, and nucleus/randomized decoding is unknown.
- Asymmetric K/V bit-allocation is not explored: the paper notes V errors dominate but does not evaluate mixed-precision KV schemes (e.g., K:3–4-bit, V:5–8-bit) or per-layer/per-head bitwidth schedules.
- Group size and quantization hyperparameters are fixed: no ablations on group size g, scale/zero-point precision, per-channel vs per-group quantization, or adaptive schemes to trade latency/accuracy.
- Prefill path remains unfused: there is no fused compressed-domain prefill kernel for S_q > 1; memory and bandwidth spikes during prefill (due to FP16 K,V) at high batch/context are not characterized.
- Batch size >1 and multi-client scenarios are not evaluated: decode kernel targets S_q=1; throughput/latency scaling with batch size, beams, or concurrent requests is unknown.
- Extreme-context numerical stability is unverified: the online softmax + split-K scheme is not stress-tested for S ≫ 128K (e.g., 256K–1M) for overflow/underflow, accumulation error, or accuracy drift.
- RoPE/NTK scaling interactions are unexamined: how int4 KV quantization interacts with rotary embeddings and positional extrapolation at very long contexts is not measured.
- Sliding/windowed/global attention variants are only lightly handled: beyond a conditional skip for Gemma’s sliding layers, broader support (e.g., block-sparse, dilated, recurrent attention) and accuracy impacts are not studied.
- Cross-architecture generality of the “attention scale factor” finding is limited: only Llama (α=1/√d) and Gemma (α=1.0) are tested; models with other normalizations/scales (e.g., Normformer variants, Mistral-family, Qwen, Phi, DeepSeek) are not evaluated.
- Formal analysis of angular-error amplification is missing: the claim that α governs PolarQuant viability is empirically supported but lacks a full theoretical treatment (e.g., bound on layerwise error propagation through softmax).
- Depth-scaling failure of QJL lacks mitigation attempts: no exploration of per-layer re-centering, re-sketching, hybrid schedules, or learned projections to preserve correlation at 70B/80 layers.
- Portability is unaddressed: kernels are Metal-specific; there is no CUDA/ROCm implementation or performance/accuracy comparison on NVIDIA/AMD GPUs.
- Energy efficiency and thermals on Apple Silicon are not reported: power draw, performance-per-watt, and thermal throttling behavior under long-context workloads are unknown.
- Memory management overhead remains unresolved: the 18% end-to-end gap vs mlx-lm due to KV concatenation (lack of pre-allocated slices/slice_update) is not fixed; fragmentation and allocator behavior at 128K–236K are unprofiled.
- Wired memory pinning trade-offs are not analyzed: side effects on system stability, contention with other processes, and macOS version dependencies are not documented.
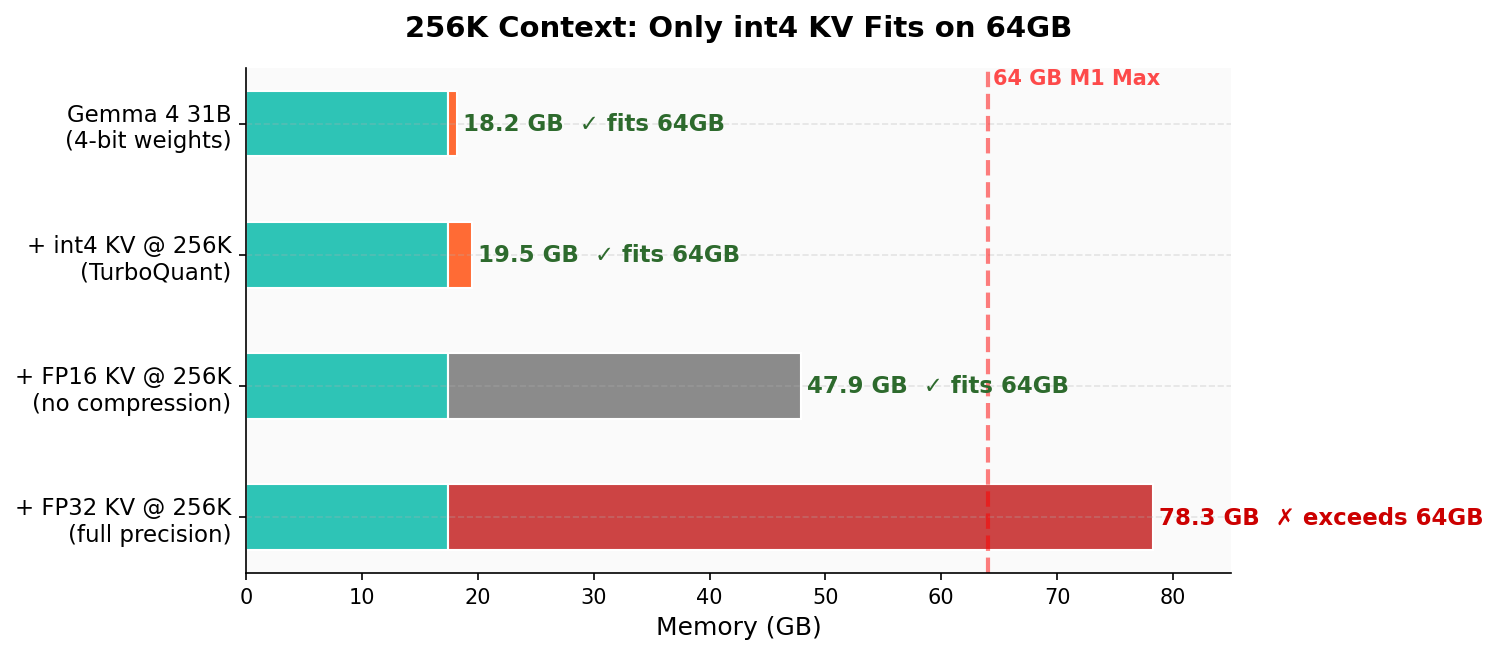
- Maximum feasible context is only memory-checked: while 236K fits in 64 GB, latency, throughput, and quality at that length are not measured.
- GQA/MQA scaling limits are unclear: performance/accuracy across extreme GQA factors, heterogeneous head dimensions, and many-head regimes are not characterized.
- Value quantization effects are only briefly noted: no systematic study on per-layer sensitivity, mitigation (e.g., residual mixing, K-only quantization), or selective higher-precision V for critical layers.
- Scale/zero-point representation is unspecified: precision/format of per-group scales/zero-points and their impact on reconstruction error and bandwidth is not ablated.
- Nibble-extraction robustness/portability is untested: endianness, alignment, and compiler/driver variations that could affect the reinterpret-cast approach are not validated across macOS versions/devices.
- End-to-end pipeline integration is partial: compatibility with streaming, kv cache eviction/paging, dynamic attention masks, and advanced scheduler features (e.g., continuous batching, vLLM-style paged KV) is not demonstrated.
- Interaction with weight compression or MoE is not integrated: while MoE shows bandwidth wins, there is no combined evaluation of fused int4 KV with weight quantization/activation compression or production MoE routing at scale.
- Training/finetuning use-cases are not considered: feasibility of quantized KV in training (memory/time savings, optimizer stability) or during LoRA/PEFT finetuning is unknown.
- Error accumulation across very deep stacks is only qualitatively discussed: quantitative per-layer error tracking, layer-wise sensitivity maps, and placement of “high-precision checkpoints” (e.g., periodic FP16 KV layers) are not explored.
- Robustness and safety are not evaluated: effects on factuality, toxicity, or repetition under quantized KV; resilience under adversarial or adversarially-long prompts; and failure modes are unreported.
- Open-source artifacts lack reproducibility metadata: seed control, exact prompts, decoding parameters, and environment hashes for the 330-experiment sweep are not enumerated for full reproducibility.
- Applicability to encoder-decoder or multi-modal models is untested: cross-attention KV quantization, image/text-fused attention, and audio/vision modalities are not evaluated.
- Multi-device and distributed settings are not covered: behavior with unified memory oversubscription, NUMA characteristics on multi-die Apple chips, or sharded KV caches is unknown.
Practical Applications
Immediate Applications
Below are actionable, deployable-now uses that follow directly from the paper’s fused int4 compressed-domain attention, split-K parallelism, and memory pinning on Apple Silicon.
- On-device long-context LLMs on consumer Macs
- What: Run 70B-class models at 128K–236K tokens on 64 GB Apple Silicon with 3.2× KV compression and up to 48× faster attention vs. dequantize-then-attend baselines.
- Sectors: software/dev tools, enterprise IT, privacy-first apps.
- Tools/workflows: integrate Open-TQ-Metal kernels into MLX-based apps; ship offline chat/assistant apps that support 100K+ token prompts; adopt automatic prefill/decode routing and split-K attention for consistent latency.
- Assumptions/dependencies: Apple Silicon with sufficient memory (≥64 GB); Metal + MLX stack; models with standard attention scaling (e.g., Llama-style α = 1/√d) for best robustness; int4 KV cache quantization; greedy decoding quality verified, but exhaustive long-context evaluation may still be pending.
- Private/offline analysis of long documents
- What: Summarize and analyze very large files locally (e.g., 100K+ token PDFs, logs, reports) without cloud data transfer.
- Sectors: legal (contract review, e‑discovery), healthcare (EHR summarization), finance (regulatory filings), government (classification and audits).
- Tools/workflows: macOS apps embedding Open-TQ-Metal to process lengthy documents in a single pass; “RAG-optional” workflows that lean on long context instead of retrieval when appropriate; wired memory pinning to eliminate paging slowdowns.
- Assumptions/dependencies: Data must fit within 64 GB unified memory after compression; regulatory environments may require additional validation; value quantization affects output more than key quantization—consider FP16/FP32 values if needed.
- Local developer assistants over large codebases
- What: Interactive code comprehension, refactoring, and multi-file reasoning with contexts up to 128K+ tokens at ~6 tok/s on a Mac.
- Sectors: software engineering, DevOps.
- Tools/workflows: VS Code/Xcode extensions using fused int4 attention for decode; prefill with batched FP16 SDPA then store int4 KV cache; split-K for flat latency across long history windows.
- Assumptions/dependencies: Model weights must be available in 4-bit (GPTQ or similar) and paired with int4 KV; careful cache management (pre-allocated slices) can close throughput gaps.
- Cost- and privacy-sensitive prototyping for research labs
- What: Run 70B long-context experiments without cloud GPUs to prototype evaluation tasks (RULER-like, Needle-in-a-Haystack) and ablations.
- Sectors: academia, corporate research.
- Tools/workflows: MLX + Open-TQ-Metal kernels for attention; cross-architecture quantization tests to select methods based on model attention scaling; reproducible benchmarks using released code and shaders.
- Assumptions/dependencies: Apple Silicon availability in labs; evaluate non-greedy decode and long-context perplexity when needed.
- Framework and systems engineering upgrades
- What: Adopt fused compressed-domain attention, split-K via graph-chained primitives, and wired memory pinning in MLX-based tooling.
- Sectors: open-source LLM frameworks (MLX-lm, app-specific engines).
- Tools/workflows: contribute kernels and KV int4 cache paths; restructure KV cache to pre-allocated slices instead of per-step concatenation; apply vectorized nibble extraction and online softmax in kernels.
- Assumptions/dependencies: MLX C++ primitive APIs; Metal knowledge; careful graph dependency management to avoid dispatch reordering issues.
- Air-gapped and high-compliance deployments
- What: Keep sensitive text in secure environments while performing long-context inference on-device.
- Sectors: defense, critical infrastructure, regulated industries.
- Tools/workflows: hardened macOS apps that disable paging via wired memory; local-only policy configurations for auditing and compliance.
- Assumptions/dependencies: Security posture of the host device; operational policies allowing on-prem Macs.
Long-Term Applications
These require additional research, engineering, or ecosystem adoption (e.g., porting to other accelerators, refining quantization across architectures, overcoming bandwidth limits).
- Cross-platform fused compressed-domain attention (CUDA/ROCm/Vulkan/DirectML)
- What: Port the fused int4 SDPA and split-K approach to NVIDIA/AMD GPUs and other APIs to make 128K+ contexts widely available.
- Sectors: cloud providers, on-prem GPU clusters, workstation users.
- Tools/products: Triton/CUDA kernels with register-level dequantization, online softmax, and split-K; PyTorch backends integrating fused KV-cache int4 paths.
- Assumptions/dependencies: Re-engineering for different SIMD/wavefront sizes; memory hierarchy tuning; kernel fusion with existing FlashAttention-style ops.
- Model architecture choices informed by attention scaling
- What: Select or co-train models with attention scale factors compatible with angular or aggressive quantization (e.g., standard α = 1/√d) to reduce quantization-induced error.
- Sectors: model development (foundation model teams, open-source model authors).
- Tools/workflows: architectural sweeps that vary attention scaling and normalization schemes; training-time constraints/regularizations to enhance quantization resilience.
- Assumptions/dependencies: Potential trade-offs with training stability or downstream quality; requires re-training or fine-tuning for new scale settings.
- Next-generation KV compression validated at large scale
- What: Bring TurboQuant-like MSE-optimal codebooks and residual transforms to 31B–70B+ models with fused compute paths; explore mixed-precision KV (e.g., int4 K, higher-precision V) at extreme contexts.
- Sectors: efficient inference research, commercial inference stacks.
- Tools/workflows: codebook learning pipelines; mixed-precision caches; dynamic precision schedules (increase precision as context grows).
- Assumptions/dependencies: Need rigorous long-context quality benchmarks (RULER, Needle-in-a-Haystack, practical tasks); integration into fused kernels without losing speed.
- Breaking the bandwidth wall with MoE and weight compression
- What: Combine KV compression with MoE (fewer active parameters) and weight compression to push beyond ~10 tok/s for 70B-class models on-device.
- Sectors: productized assistants, IDE copilots, enterprise knowledge systems.
- Tools/workflows: sparse/router training; blockwise weight quantization or low-rank adapters; pipeline scheduling to hide memory stalls.
- Assumptions/dependencies: Training and serving complexity; router quality; potential latency variability.
- OS and framework-level APIs for stable memory and cache management
- What: First-class APIs for wired memory pinning and pre-allocated KV slices to avoid paging and reduce fragmentation-induced overhead.
- Sectors: operating systems, Apple developer ecosystem, MLX maintainers.
- Tools/workflows: MLX enhancements to support in-place KV updates safely; OS-level guarantees for pinned regions across long-running inference.
- Assumptions/dependencies: OS changes or documented best practices; coordination with framework maintainers.
- Robust, standardized evaluation for long-context quantization
- What: Community benchmarks and test suites across architectures to evaluate quantization vs. attention scaling (e.g., Gemma-like α = 1.0 vs. Llama-like α = 1/√d).
- Sectors: academia, standards bodies, open-source communities.
- Tools/workflows: cross-architecture test harnesses; metrics beyond top-1 match (perplexity, task accuracy, stability over depth and context).
- Assumptions/dependencies: Broad participation; access to multiple model families and long-context datasets.
- Policy frameworks encouraging on-device, privacy-preserving AI
- What: Guidance and incentives for processing sensitive text locally (health, legal, finance) when feasible, leveraging efficient on-device inference.
- Sectors: public policy, compliance, procurement.
- Tools/workflows: procurement criteria for on-device AI capabilities; compliance checklists for local processing; sustainability metrics (reduced data movement).
- Assumptions/dependencies: Regulatory acceptance; lifecycle management for on-device models; verifiable privacy posture.
- Extension to multimodal long-context on device
- What: Apply fused compressed-domain attention to vision/audio KV caches (e.g., long video transcripts, meeting audio) for unified long-context agents on Macs.
- Sectors: media, productivity, assistive tech.
- Tools/workflows: Metal kernels for multimodal encoders with fused dequantization; synchronized KV caches across modalities.
- Assumptions/dependencies: Multimodal model availability with compatible attention; memory pressure from additional modalities.
- Mobile and edge variants
- What: Tailor fused int4 attention for memory-constrained devices (e.g., M-series iPads, future mobile SoCs) to enable offline assistants with moderately long contexts.
- Sectors: consumer apps, field operations, IIoT.
- Tools/workflows: aggressive KV compression + MoE; task-specific distilled models; dynamic context windows.
- Assumptions/dependencies: Reduced memory budgets; different GPU architectures/APIs; tighter thermal envelopes.
- Commercial integrations into productivity suites and IDEs
- What: Add long-context capabilities to office suites, email clients, and IDEs for end-to-end workflows (e.g., whole-brief summarization, cross-repo reasoning) on-device.
- Sectors: productivity software, developer tooling.
- Tools/workflows: background prefill with batched FP16 attention; decode with fused int4 kernels; UX for managing very long contexts and memory budgets.
- Assumptions/dependencies: Product engineering and QA; performance targets; user controls for privacy and resource usage.
Glossary
- Bold
- Bold
- Alpha (attention scale): The scalar factor applied to dot-product attention scores, commonly set to to stabilize gradients and magnitudes. "Standard transformers compute with ."
- attn_scale: An architectural parameter that directly sets the attention scaling instead of using , affecting sensitivity to quantization error. "Gemma~4's attn_scale=1.0 amplifying directional error 25--100 more than Llama's standard scaling."
- Asymmetric int4 quantization: A 4-bit per-element quantization scheme with per-group scales and zero-points to better fit asymmetric value ranges. "Per-group asymmetric int4 quantization partitions each vector into groups of consecutive elements and computes per-group scale and zero-point parameters:"
- Autoregressive inference: Generation where each next token is conditioned on all previously generated tokens, requiring persistent key/value state. "Autoregressive inference stores key and value projections from all previous tokens in the KV cache"
- Bandwidth wall: A throughput limit dominated by memory bandwidth rather than compute, constraining token generation speed. "The Bandwidth Wall"
- Binary sketch: A compact representation storing only sign information of projected vectors, used to approximate similarities. "yielding binary sketches in ."
- Cosine similarity: A measure of angular similarity between vectors, used here to assess reconstruction quality after quantization. "K/V cosine similarity"
- Dequantize-then-attend baseline: The standard approach that materializes full-precision tensors from quantized storage before computing attention. "dequantize-then-attend baseline"
- FlashDecoding: A decoding method that introduces efficient parallelism strategies (e.g., split-K) to accelerate attention. "split-K parallelism from FlashDecoding"
- FP16: Half-precision floating-point format (16-bit) commonly used for efficient inference with minimal quality loss. "FP16 KV requires 79.1\,GB (infeasible on 64\,GB)."
- Fused compressed-domain attention: Computing attention directly on quantized representations without forming intermediate full-precision matrices. "fused compressed-domain attention on Apple Silicon"
- GQA (Grouped-Query Attention): An attention variant where multiple query heads share a smaller set of key/value heads to reduce memory and compute. "GQA is handled by mapping ."
- Greedy decode: A decoding strategy selecting the highest-probability token at each step without sampling. "Output quality is identical: both paths produce the same top-1 token under greedy decode"
- Int4: 4-bit integer representation used to compress tensors (e.g., keys/values) for memory and bandwidth savings. "Open-TQ-Metal quantizes the KV cache to int4 on the fly"
- KL divergence: A statistical measure of distributional difference, used to compare attention outputs across quantization schemes. "with KL divergence differing by 25--100"
- KV cache: Stored key and value projections from prior tokens for efficient attention during decoding. "The KV cache grows linearly with sequence length and model depth"
- Lloyd-Max codebooks: Optimal scalar quantization codebooks derived from Lloyd-Max algorithms to minimize mean squared error. "Lloyd-Max codebooks,"
- Metal compute shader: GPU kernels written for Apple’s Metal API, used here to implement fused attention operations. "A Metal compute shader that reads packed int4 keys and values directly from device memory"
- MLX Primitive: A low-level operation in the MLX framework used to dispatch custom Metal kernels and compose computation graphs. "Split-K parallelism via chained MLX Primitives."
- MoE (Mixture-of-Experts): A sparse model architecture activating only a subset of experts per token to reduce compute/bandwidth. "MoE (4B active) reaches 59\,tok/s"
- MSE-optimal: Refers to quantizers or methods optimized to minimize mean squared error between original and reconstructed values. "proposes an MSE-optimal scalar quantizer"
- Nibble (vectorized nibble extraction): Handling 4-bit values packed into larger words by extracting “nibbles” efficiently for SIMD computation. "Vectorized nibble extraction."
- Online softmax: A numerically stable algorithm computing softmax incrementally without materializing full score matrices. "building on the online softmax technique"
- PolarQuant: A quantization method encoding vectors via polar/angle representations to achieve high compression. "PolarQuant transforms KV embeddings into polar coordinates via a recursive algorithm and quantizes the resulting angles."
- Prefill: The phase where multiple queries are processed before decoding, often benefiting from batch-efficient attention kernels. "For prefill (), MLX's built-in scaled_dot_product_attention batches the multi-query computation more efficiently."
- Qdot pattern: An implementation technique leveraging pre-scaling and masking to perform multiple nibble dot-product accumulations efficiently. "we adopt MLX's qdot pattern"
- QJL: A projection-based compression method storing sign-only features for approximate attention with high compression ratios. "QJL projects keys through a random Gaussian matrix and stores only the sign bits of the result"
- RMSNorm: Root-mean-square normalization applied to vectors, here used as an alternative to standard attention scaling. "normalizing Q and K via separate RMS norms instead."
- Scaled Dot-Product Attention (SDPA): The core transformer attention mechanism using scaled dot products between queries and keys followed by softmax-weighted values. "Fused int4 Scaled Dot-Product Attention"
- SIMD group: A group of lanes executing the same instruction on different data, the fundamental GPU execution unit on Apple Silicon. "Apple Silicon GPUs use 32-wide SIMD groups as the basic execution unit."
- Sliding-attention layers: Attention restricted to a fixed window around each position to reduce computation and memory. "Gemma~4's sliding-attention layers ()"
- Speculative decoding: A two-stage generation method using a lightweight draft model to propose tokens validated by the target model. "speculative decoding with a 2B draft achieves only 25\% acceptance"
- Split-K parallelism: Parallelizing attention over chunks of the key/value sequence and reducing partial results for long contexts. "Split-K divides the KV sequence into chunks"
- Threadgroup: A set of threads scheduled together on the GPU, sharing resources and synchronization. "a single threadgroup processing all KV tokens sequentially"
- TurboQuant: A compression method combining MSE-optimal quantization with a QJL residual stage for high-quality low-bit storage. "TurboQuant combines MSE-optimal quantization with QJL residual compression"
- Wired memory (pinning): Forcing memory to remain resident (unpaginable) to prevent OS-induced slowdowns from paging. "Pinning weights via mx::set_wired_limit() recovers 10 throughput"
- Zero-point: The offset used with scale in affine quantization to map integer codes to real values. "scale and zero-point parameters:"
Collections
Sign up for free to add this paper to one or more collections.