GPU-Accelerated INT8 Quantization for KV Cache Compression in Large Language Models
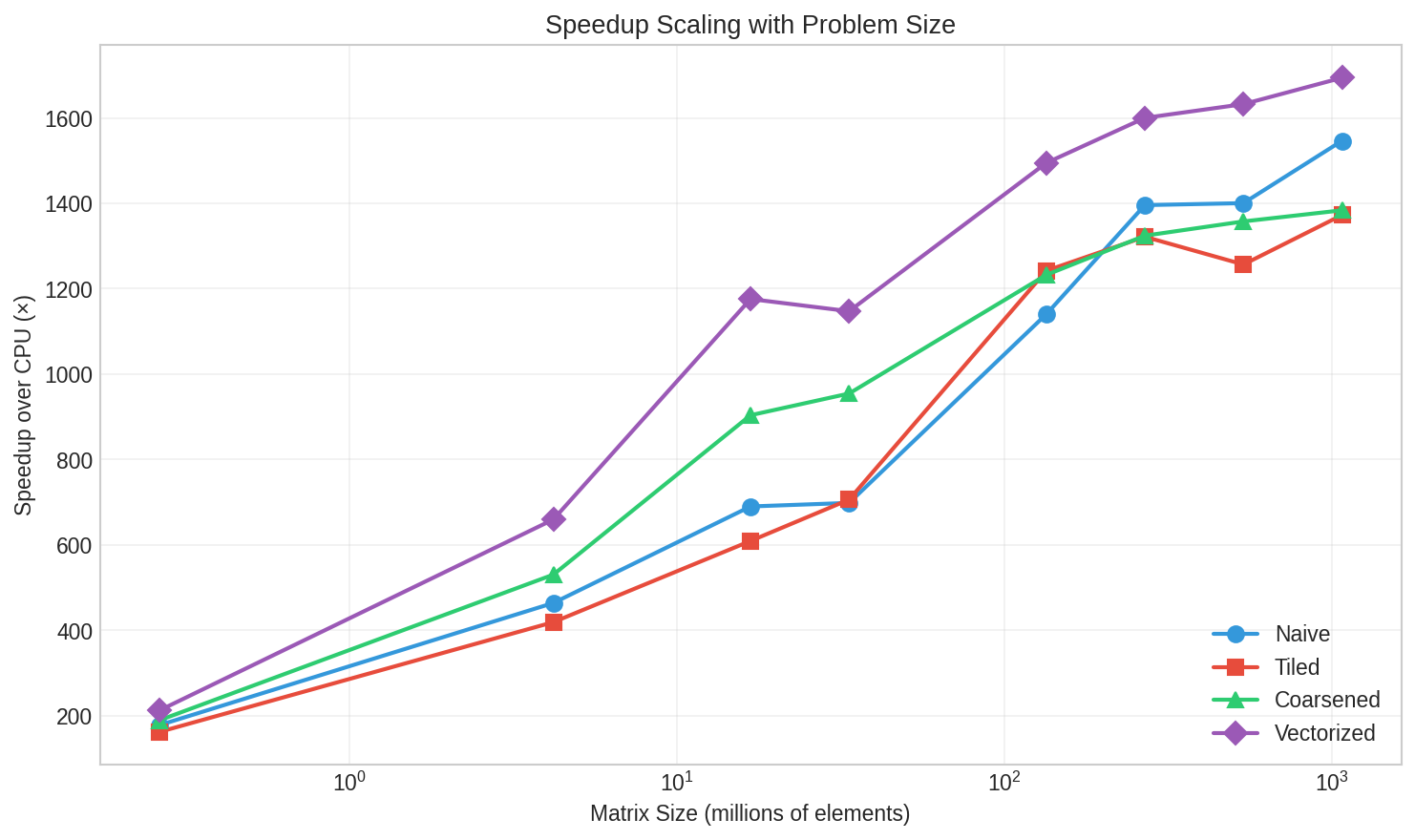
Abstract: The key-value (KV) cache in LLMs presents a significant memory bottleneck during inference, growing linearly with sequence length and often exceeding the memory footprint of model weights themselves. We implement and evaluate GPU-accelerated INT8 quantization for KV cache compression, achieving 4$\times$ memory reduction with minimal accuracy degradation. We develop four CUDA kernel variants -- naive, tiled, coarsened, and vectorized -- and benchmark them across realistic workload sizes up to 1 billion elements. Our vectorized kernel achieves up to 1,694$\times$ speedup over CPU baselines while maintaining reconstruction error below 0.004 and attention score error below 0.1 even for 8K-dimensional heads. These results demonstrate that INT8 quantization provides a practical approach for reducing memory pressure in LLM inference with negligible computational overhead (6--58ms) and minimal impact on downstream model behavior
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a big memory problem in LLMs, like ChatGPT. When these models generate long pieces of text, they store a lot of “key” and “value” data in something called a KV cache so they don’t have to recompute it every time. The KV cache can grow huge—sometimes bigger than the model itself. The paper’s main idea is to compress this cache using INT8 quantization, which stores numbers using 8 bits instead of 32. This cuts the memory by about 4× while keeping the model’s behavior almost the same.
What questions were they trying to answer?
The researchers wanted to answer three simple questions:
- Can we compress the KV cache by 4× using 8-bit numbers without hurting accuracy too much?
- How fast can we do this compression on a GPU compared to a CPU?
- Does this compression change important things the model computes, like attention scores?
How did they do it?
First, a quick reminder of what the KV cache is: When an LLM writes a story, it looks back at all previous words to decide what comes next. To do that quickly, it keeps “keys” and “values” from previous steps in a cache instead of recalculating them. If the story gets very long, the cache gets very big.
Now, the trick they use is called quantization. Think of it like saving space on your phone by storing photos at a lower quality. Instead of using 32-bit numbers (very precise), they use 8-bit numbers (less precise but much smaller). When the model needs the numbers again, they convert them back to 32-bit. This does add a tiny rounding error, but it’s small enough not to matter much.
They use “per-channel” quantization, which means each column of the matrix (each feature dimension) gets its own scale, like giving each instrument in a band its own volume knob. This keeps accuracy better than using one global scale for everything.
They built and tested four versions of the same GPU program (kernel) to do the quantization quickly:
- Naive: Each thread handles one number. Simple and straightforward.
- Tiled: Tries to reuse some data in faster memory on the GPU to save time.
- Coarsened: Each thread handles multiple numbers to reduce overhead.
- Vectorized: Loads and stores groups of 4 numbers at once, like carrying four grocery bags instead of one each trip.
They compared all of these against a CPU version to see how much faster the GPU could be.
What did they find and why is it important?
Here are the main results:
- 4× memory reduction: Storing KV cache in INT8 uses about one-quarter the memory of 32-bit floats. For example, a cache that would be around 137 GB in FP32 drops to about 34 GB in INT8.
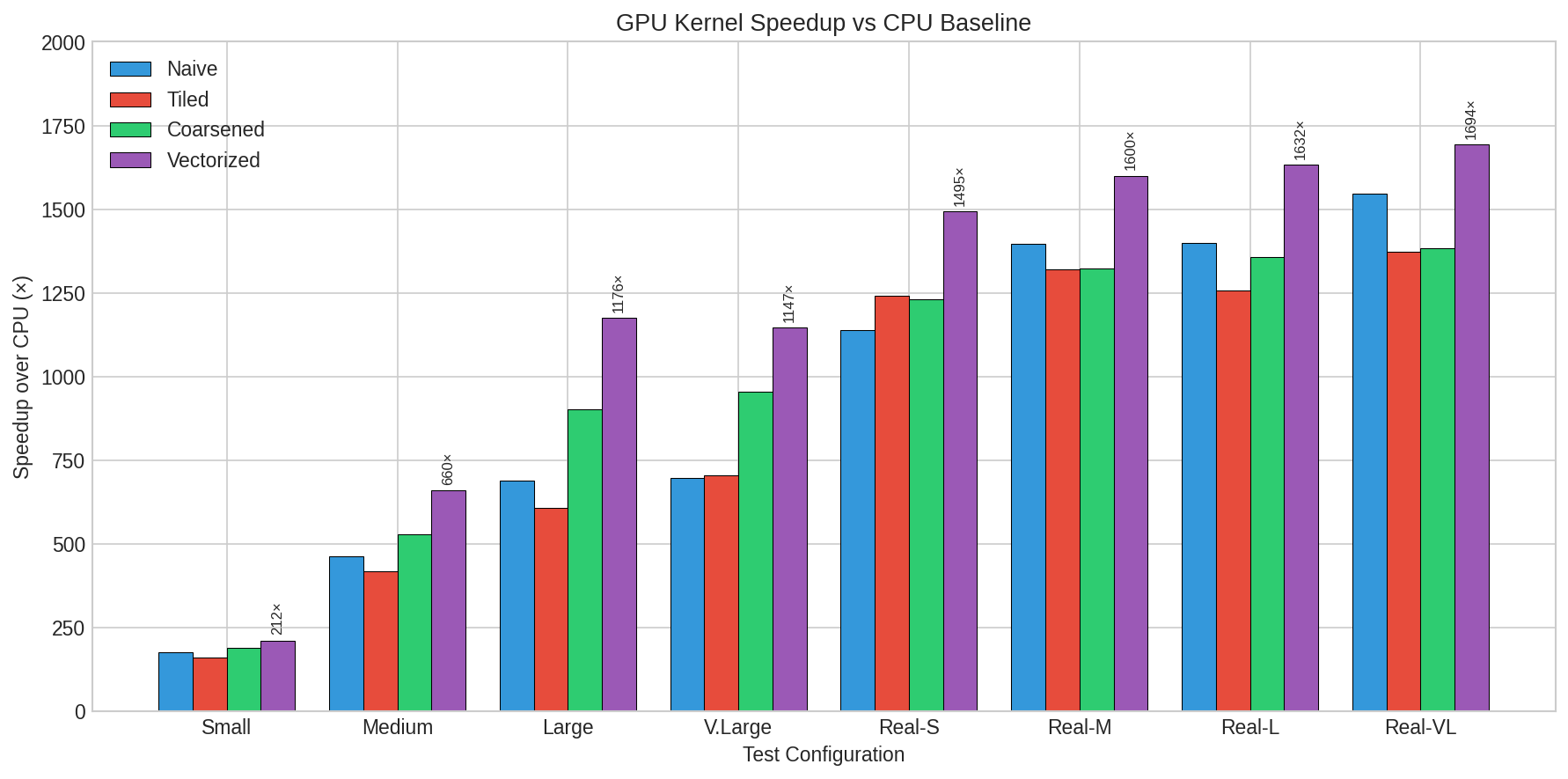
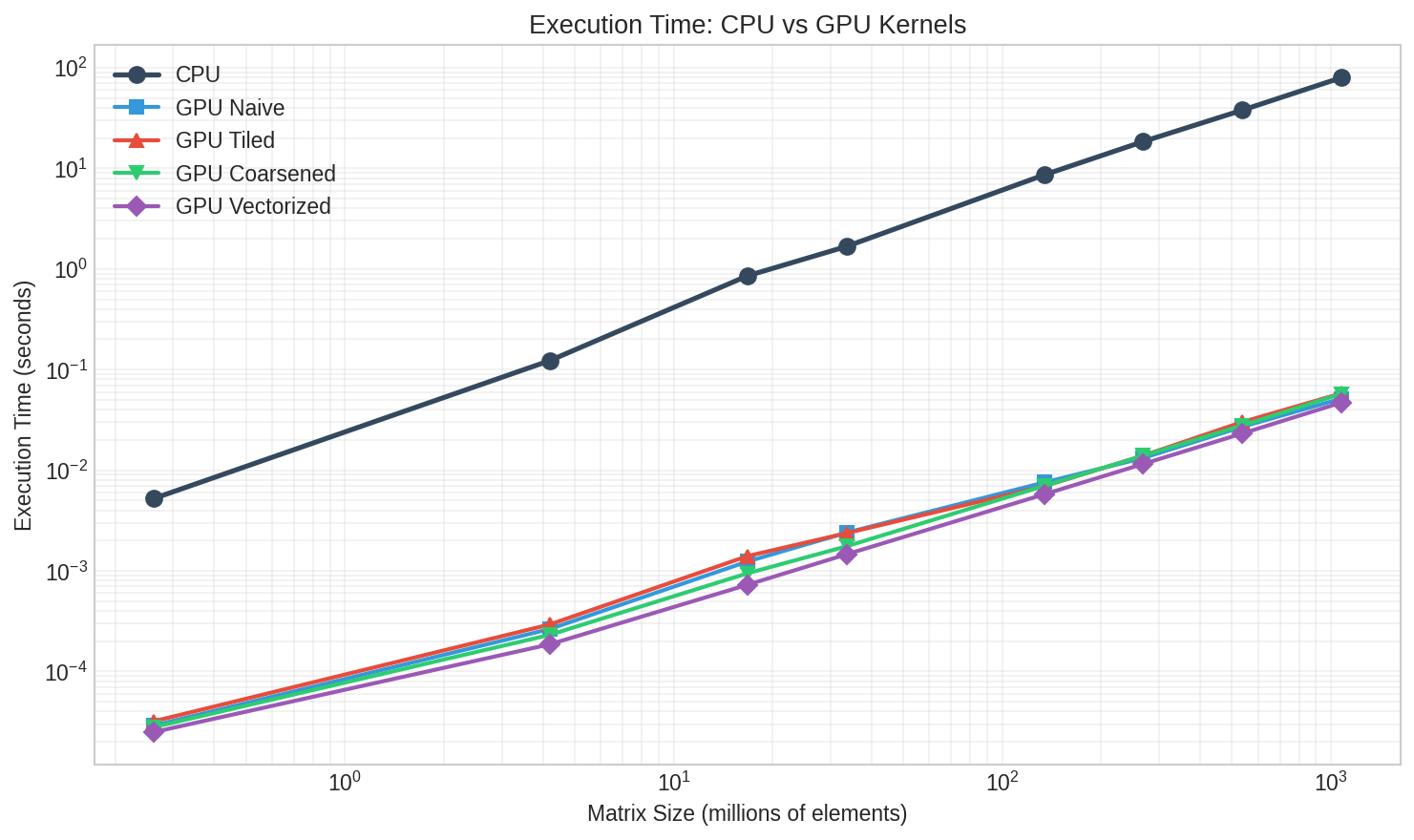
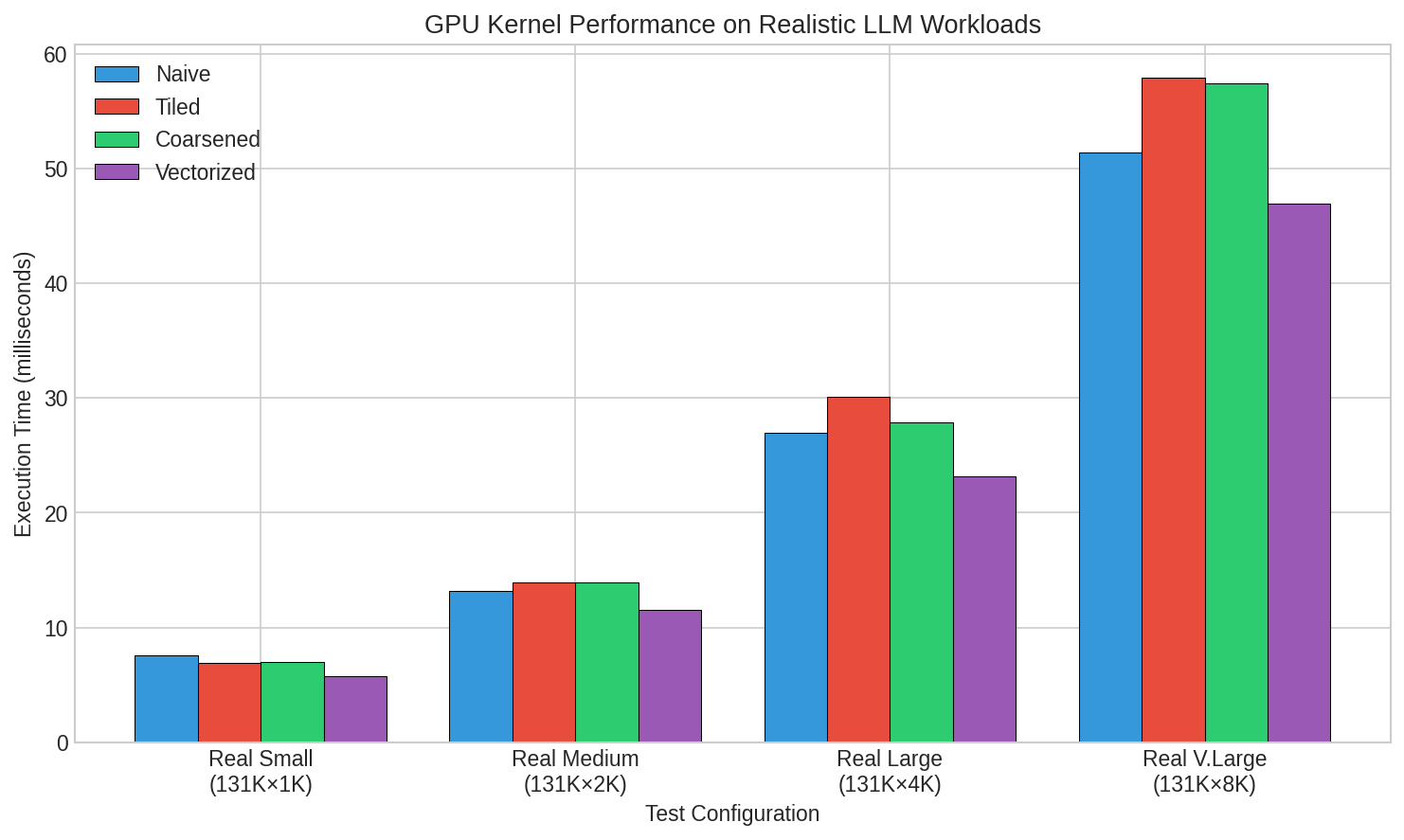
- Very fast on GPUs: The best GPU version (the vectorized kernel) was up to 1,694× faster than the CPU. Even for massive workloads (about 1 billion elements), the GPU finished in under 50 milliseconds, while the CPU took about 79 seconds.
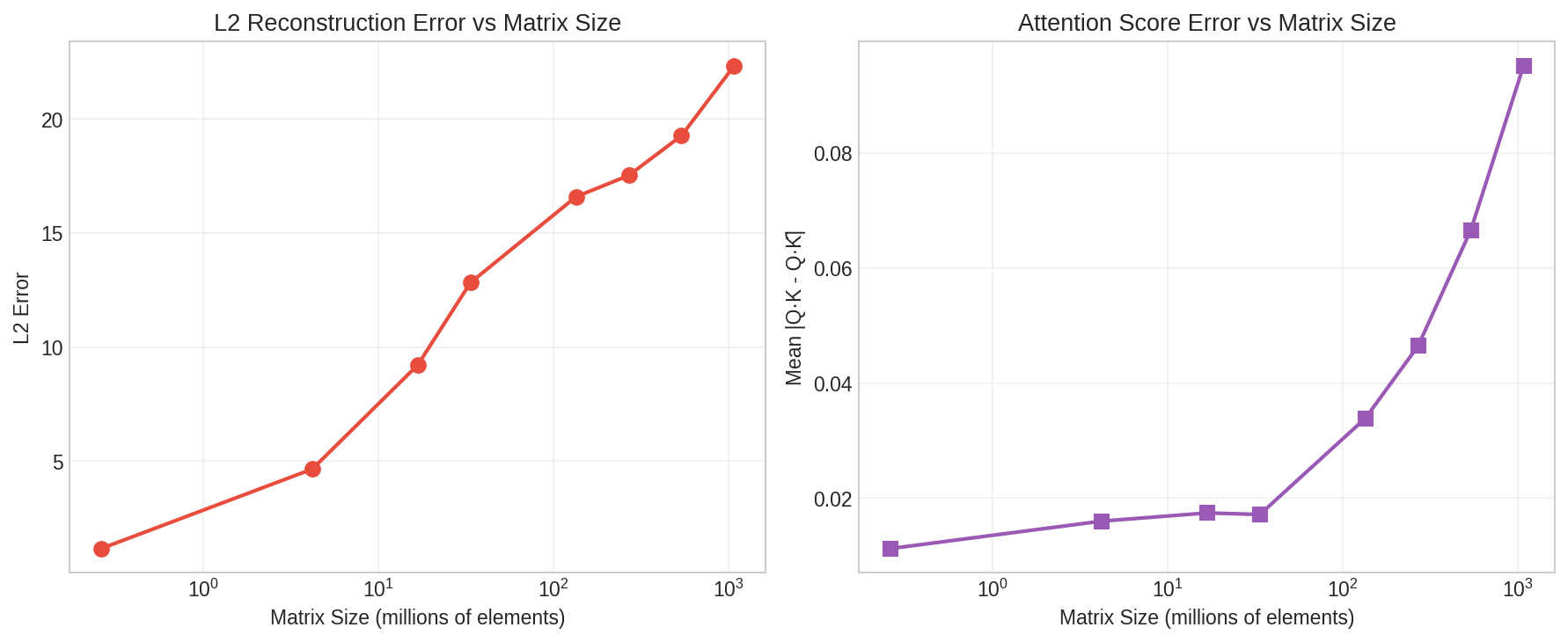
- Tiny errors: The difference between the original and the dequantized numbers stayed below about 0.004 per element. The change in attention scores (the model’s “who should I pay attention to?” math) stayed below 0.1 even for very large dimensions. That’s small enough that it shouldn’t meaningfully change the model’s decisions.
- Best strategy: The vectorized kernel was consistently the fastest because it reduced the number of memory operations, which is the main bottleneck. Surprisingly, “tiled” didn’t help much, because the scales were small and already fast to access. This shows the workload is mostly limited by memory bandwidth, not computation.
These results matter because they show you can cut memory by 4× with almost no slowdown and very small accuracy loss. That means longer context windows, bigger batch sizes (more users served at once), and lower costs.
Implications and impact
This approach makes running LLMs cheaper and more practical:
- Longer context: Models can remember more text without running out of GPU memory.
- Higher throughput: With smaller caches, servers can handle more requests at the same time.
- Lower costs: You need fewer or smaller GPUs to serve the same workload.
It also gives engineers clear advice: focus on vectorized memory operations for this kind of task, because the main limit is how fast you can move data, not how fast you can do math. In the future, the same idea could be pushed further (like using 4-bit or 2-bit numbers), tested across full end-to-end models, and integrated into popular LLM serving systems to see the real-world benefits.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper that future researchers could address:
- End-to-end model quality: Quantify the impact of INT8 KV quantization on downstream metrics (e.g., perplexity, QA accuracy, generation quality) across diverse LLMs and context lengths.
- Keys vs values: Explicitly evaluate quantizing both K and V (not just K) and measure effects on attention distributions and the final weighted-sum over V.
- Dequantization strategy during attention: Compare full dequantization to performing scaled INT8×FP16/FP32 dot products (avoiding a full FP32 reconstruction) in terms of latency, bandwidth, and accuracy.
- Streaming/incremental scale computation: Implement and benchmark running max per channel for growing caches; design policies for sliding-window eviction when maxima leave the window and measure recalibration overhead.
- Robust scaling under outliers: Assess max-based scaling versus percentile clipping, SmoothQuant-style scaling, or learned scales; characterize trade-offs for channels with heavy-tailed distributions.
- Asymmetric quantization and zero-points: Explore non-zero zero-points for K and V and compare error/accuracy against symmetric [-127, 127] clamping.
- Lower bit-widths: Implement INT4/INT2 KV quantization kernels; determine accuracy thresholds and fallback/escape hatches for sensitive channels/heads/layers.
- FP16 starting point: Evaluate quantizing from FP16 (common in production KV caches) to INT8, including the precision of stored scales (FP16 vs FP32) and resulting accuracy/memory gains (2× vs FP16).
- Softmax-level effects: Measure KL divergence in attention distributions, changes in top-k attention indices, and induced differences in logits/next-token choices (beyond dot-product MAE).
- Layer/head sensitivity: Quantify cumulative error across layers and heads on long sequences; identify the most sensitive components and whether selective higher precision is warranted.
- Kernel fusion with attention: Integrate quantize/dequantize steps into FlashAttention/PagedAttention or fused attention kernels to avoid separate passes; evaluate performance and correctness.
- Overlap and scheduling: Study stream-level concurrency to overlap quantization with attention/FFN kernels; measure throughput under realistic pipeline contention.
- Multi-GPU and sharding: Analyze costs and strategies for transferring/storing quantized KV across devices; evaluate compression-aware sharding and synchronization overhead.
- Hardware generalization: Re-benchmark on A100/H100/L4 and consumer GPUs; assess how cache sizes, memory bandwidth, and native INT8/FP8 support alter performance/accuracy.
- CPU baseline rigor: Compare against optimized multi-threaded, vectorized CPU implementations (AVX2/AVX-512/NEON) to establish fair speedups.
- Tail handling in vectorization: Implement and quantify performance impact when D is not divisible by 4/8/16, including alignment/padding strategies and divergence costs.
- Scale storage format: Test storing scales in FP16/BF16 to further reduce memory; quantify the accuracy loss and bandwidth benefits.
- Quantization impact on value aggregation: Measure numeric error in the attention-weighted sum over V when both K and V are quantized, including downstream hidden-state deviations.
- Adaptive/mixed precision policies: Design sensitivity-aware policies (per head/layer/token) that use higher precision selectively; define detection criteria and runtime schedulers.
- Robustness to extreme inputs: Characterize worst-case attention errors under outlier/adversarial inputs; evaluate clipping or guardrails to bound instability.
- Calibration procedure: Specify deployment-time scale calibration (per session/batch/layer) and refresh frequency; measure overhead and stability under evolving distributions.
- Storage/layout compatibility: Validate alignment, packing (e.g., char4), and integration with tensor layouts and memory managers (e.g., PagedAttention/vLLM/TensorRT-LLM).
- Energy/power effects: Quantify power draw and energy efficiency changes due to added quantization/dequantization passes and increased memory transactions.
- Expanded error metrics: Include relative error, cosine similarity, KL divergence, and task-level metrics to capture effects beyond L2 and dot-product MAE.
- Decoding stability: Assess whether small attention perturbations induce different decoding trajectories under typical sampling/beam search (temperature, top-p), and quantify variability.
Practical Applications
Immediate Applications
The paper’s main contribution—GPU-accelerated per-channel INT8 quantization of the KV cache—is deployable today to reduce LLM inference memory by 4× with negligible overhead and small attention-score error. The following use cases can be implemented immediately:
- LLM serving: 4× KV cache memory reduction to unlock longer context windows and larger batch sizes
- Sectors: software, cloud, enterprise IT
- Tools/products/workflows:
- Integrate the vectorized INT8 KV-cache kernels into vLLM, TensorRT-LLM, or HuggingFace Transformers as a configurable “enable_int8_kv_cache” flag
- Add an A/B testing harness and guardrails (e.g., monitor attention-score error thresholds, fallback to FP16)
- Pair with FlashAttention/PagedAttention for complementary speed/memory gains
- Assumptions/dependencies:
- CUDA-capable GPUs; vectorized kernel benefits when head dimension D is divisible by 4 (or with tail-handling)
- Minimal downstream accuracy impact holds across target models and workloads (end-to-end metrics recommended before mission-critical use)
- Cost optimization for AI inference (FinOps)
- Sectors: finance (operational cost management), cloud providers, SaaS AI platforms
- Tools/products/workflows:
- Lower per-request GPU memory footprint to fit more concurrent requests per GPU
- Pricing tiers offering larger contexts or lower cost per token due to higher utilization
- Assumptions/dependencies:
- Serving stack supports quantized KV cache and monitoring for rare precision-edge cases
- Proper scheduler tuning to realize higher utilization
- On-prem and edge deployment of LLMs on smaller GPUs
- Sectors: embedded, mobile, robotics, manufacturing, retail
- Tools/products/workflows:
- Enable long-context assistants on single T4/A10 GPUs or edge accelerators by shrinking KV memory
- Local, privacy-preserving assistants (customer support kiosks, factory HMIs) with extended session memory
- Assumptions/dependencies:
- Adequate GPU bandwidth and driver/CUDA support for the vectorized kernel
- Robust fallbacks for edge devices where D may not align to vector widths
- Long-document and long-session applications
- Sectors: legal (contract review), finance (research reports), healthcare (EHR summarization), education (grading long essays), software (codebase understanding)
- Tools/products/workflows:
- Offer 128k+ token contexts in document QA, coding copilots across large repos, and persistent multi-hour chat sessions
- Product features: “Extended Memory Mode” leveraging INT8 KV cache
- Assumptions/dependencies:
- End-to-end validation that small attention-score deviations do not materially affect outputs in domain-specific tasks
- Multi-tenant GPU hosting and capacity planning
- Sectors: cloud, MSPs, platform engineering
- Tools/products/workflows:
- Increase tenant density per GPU by compressing KV caches; update autoscaling and placement logic to use “effective KV memory” as a resource metric
- Assumptions/dependencies:
- Serving orchestrators aware of per-request KV footprint; workload isolation and QoS policies updated accordingly
- MLOps monitoring and QA for quantized inference
- Sectors: software, enterprise IT
- Tools/products/workflows:
- Runtime dashboards tracking reconstruction and attention-score error against configurable budgets; alerts triggering FP16 fallback
- CI/CD checks with unit tests similar to the paper’s suite (edge cases, rounding tolerances)
- Assumptions/dependencies:
- Access to model telemetry and test suites; operational guardrails to mitigate outlier distributions and clipping
- Teaching and research labs: practical GPU kernel design for memory-bound workloads
- Sectors: academia, HPC training programs
- Tools/products/workflows:
- Course modules/labs on vectorized kernels, memory coalescing, and per-channel quantization using the open-source codebase
- Assumptions/dependencies:
- Availability of CUDA-capable devices; alignment of course outcomes with modern LLM workloads
- Sustainability and energy efficiency improvements (near-term)
- Sectors: data centers, sustainability/ESG
- Tools/products/workflows:
- Lower memory footprint reduces DRAM traffic and allows consolidation to fewer/lower-tier GPUs, modestly decreasing energy per request
- Assumptions/dependencies:
- Actual energy savings depend on workload mix and memory bandwidth utilization; measurement required to quantify benefits
Long-Term Applications
Several directions require further research, scaling, or systems development before broad deployment:
- Sub-8-bit KV cache (INT4/INT2) and learned quantization parameters
- Sectors: software, hardware co-design
- Tools/products/workflows:
- Learned or asymmetric quantization (e.g., KIVI, KVQuant) to achieve 8×–16× compression with controlled error
- Assumptions/dependencies:
- Rigorous end-to-end accuracy evaluation; potential per-layer/token selectivity to limit degradation
- Dynamic/adaptive quantization during streaming inference
- Sectors: software, real-time systems
- Tools/products/workflows:
- Runtime scale recomputation or adaptive scaling windows to handle distribution drift and outliers
- Persistent kernels, warp-level reductions for fast per-channel scale updates
- Assumptions/dependencies:
- Careful overhead management; feedback loops to keep attention errors within budgets
- Quantization-aware training and task-level evaluation
- Sectors: academia, applied ML
- Tools/products/workflows:
- Fine-tune models to be robust to quantized KV caches; establish benchmark suites for perplexity, QA accuracy, and generation quality under quantization
- Assumptions/dependencies:
- Training data and compute; standardized evaluation to ensure generalization
- Multi-GPU/distributed KV cache with memory tiering
- Sectors: cloud, HPC
- Tools/products/workflows:
- Sharded, quantized KV caches across GPUs/CPU/NVMe with PagedAttention-like paging; million-token context serving
- Assumptions/dependencies:
- Careful orchestration to avoid bandwidth bottlenecks; consistency and latency management across tiers
- Hardware support and co-design (FP8/INT8 cache paths)
- Sectors: semiconductors, systems integrators
- Tools/products/workflows:
- Native support for INT8/FP8 KV storage with vectorized load/store and cache-friendly layouts; memory-controller optimizations for quantized access patterns
- Assumptions/dependencies:
- Vendor roadmaps; ISA and compiler support; ecosystem adoption
- Serving-system schedulers and admission control tuned for quantized caches
- Sectors: platform engineering, cloud
- Tools/products/workflows:
- Batch-size scaling and request coalescing strategies that exploit reduced KV memory; dynamic policies for request mixing by context length
- Assumptions/dependencies:
- Accurate real-time resource accounting; fairness/QoS safeguards
- Formal verification and safety for regulated domains
- Sectors: healthcare, finance, public sector
- Tools/products/workflows:
- Certifiable pipelines with bounds on attention perturbation, worst-case error analysis, and audit trails for quantized inference
- Assumptions/dependencies:
- Standards and regulatory guidance; model validation protocols tailored to quantized operations
- Policy and procurement guidelines for sustainable AI deployment
- Sectors: public policy, enterprise procurement, ESG
- Tools/products/workflows:
- Best-practice documents recommending quantized KV caches to reduce hardware requirements and energy footprint; incentives for efficiency-first deployments
- Assumptions/dependencies:
- Verified energy savings at scale; stakeholder consensus on acceptable accuracy trade-offs
- Education: advanced curriculum on memory-bound GPU optimization for AI systems
- Sectors: academia, workforce development
- Tools/products/workflows:
- Specialized courses on vectorization, memory coalescing, and attention-kernel integration; capstone projects integrating quantization into full inference stacks
- Assumptions/dependencies:
- Long-term access to relevant hardware; partnerships with open-source frameworks for experiential learning
- Generalized memory-tiering plugins for LLM servers
- Sectors: software infrastructure
- Tools/products/workflows:
- Pluggable components that decide precision per layer/head/time-slice based on error budgets and resource constraints
- Assumptions/dependencies:
- Rich telemetry and decision policies; integration with schedulers and attention kernels to avoid fragmentation or latency spikes
These applications leverage the paper’s core findings: KV cache is a memory-bound workload, per-channel INT8 quantization yields 4× savings with low error, and vectorized GPU kernels provide the best performance with negligible overhead. To maximize feasibility, deployments should incorporate monitoring, fallbacks, and targeted end-to-end validation in domain-specific contexts.
Glossary
- __shfl_down_sync: A CUDA warp-level intrinsic that enables threads within a warp to exchange values efficiently for reductions and other collective operations. "Warp-level primitives such as __shfl_down_sync could enable more efficient reduction operations during scale computation"
- Activation quantization: The process of converting activation values (intermediate layer outputs) to lower-precision representations to reduce memory and computation. "SmoothQuant addresses activation quantization challenges through per-channel scaling"
- Arithmetic intensity: The ratio of arithmetic operations to memory operations; low intensity indicates a memory-bound workload. "KV cache quantization is a strictly element-wise operation with no data reuse across threads... with extremely low arithmetic intensity"
- Asymmetric quantization: A quantization approach where the integer range is offset (non-zero zero-point), allowing better fit for non-symmetric value distributions. "KIVI proposes 2-bit asymmetric quantization specifically for KV caches"
- Attention dot products: Inner products computed between queries and keys that determine attention scores before softmax. "We measure the mean absolute difference between attention dot products computed with original and reconstructed keys"
- Attention heads: Independent attention mechanisms within a transformer layer that allow the model to focus on different parts of the input in parallel. "For a model with layers, attention heads, head dimension , and sequence length "
- Attention score error: A metric quantifying the difference in attention scores caused by quantization, assessing downstream impact. "attention score error remains below 0.1 even for 8K-dimensional heads"
- Autoregressive text generation: A generation process where the model predicts one token at a time conditioned on previously generated tokens. "During autoregressive text generation, the model produces one token at a time"
- CUDA kernel: A function executed on the GPU by many threads in parallel, used to perform data-parallel computations. "We implement four CUDA kernel variants with increasing levels of optimization"
- Dequantization: The process of converting quantized integer values back to approximate floating-point values using scale factors. "Dequantization recovers approximate FP32 values:"
- FlashAttention: An optimized attention algorithm that improves speed and memory efficiency via IO-aware design and fused kernels. "FlashAttention and FlashAttention-2 optimize attention computation through kernel fusion and memory hierarchy exploitation"
- FlashAttention-2: A second-generation FlashAttention with improved parallelism and work partitioning for faster attention. "FlashAttention-2... optimize attention computation through kernel fusion and memory hierarchy exploitation"
- FP16: Half-precision 16-bit floating-point format, often used to reduce memory and improve performance with minimal accuracy loss. "Even with FP16, this is nearly 70 GB"
- FP32: Single-precision 32-bit floating-point format commonly used for model parameters and activations. "instead of storing cached keys and values in 32-bit floating point (FP32), we compress them to 8-bit integers (INT8)"
- FP8: An 8-bit floating-point format supported on some modern GPUs, offering reduced precision with potential hardware acceleration. "GPU-specific numeric formats such as FP8, which recent architectures natively support"
- GDDR6: A high-bandwidth graphics memory technology used in GPUs to enable fast data transfer for parallel workloads. "GPU & NVIDIA Tesla T4 (16 GB GDDR6)"
- Global memory bandwidth: The rate at which data can be read from or written to GPU global memory; a key limiter for memory-bound kernels. "performance is dominated by global memory bandwidth rather than arithmetic throughput"
- Head dimension: The dimensionality of each attention head’s key/query vectors in transformers. "Head dimension ()"
- Instruction-level parallelism: Executing multiple independent operations within a single thread to utilize hardware pipelines more effectively. "Thread coarsening assigns multiple elements to each thread, amortizing thread management overhead and improving instruction-level parallelism"
- INT8 quantization: Compressing floating-point values to 8-bit integers to reduce memory and improve performance, with controlled error. "We implement and evaluate GPU-accelerated INT8 quantization for KV cache compression"
- Kernel fusion: Combining multiple GPU kernels or operations into a single kernel to reduce memory traffic and overhead. "optimize attention computation through kernel fusion and memory hierarchy exploitation"
- Kernel launch overhead: The fixed cost of initiating a GPU kernel execution, which can dominate at small problem sizes. "validate correctness and numerical stability under light workloads, where kernel launch overhead and instruction latency dominate"
- KV cache: A memory structure storing keys and values from previous tokens to avoid recomputation during autoregressive inference. "The key-value (KV) cache in LLMs presents a significant memory bottleneck during inference"
- KV cache compression: Techniques to reduce the memory footprint of the KV cache, such as quantization. "INT8 quantization for KV cache compression"
- L2 cache: A hardware cache layer on GPUs that stores frequently accessed data to reduce global memory latency. "the scales array is small enough to remain in L2 cache"
- L2 error: The Euclidean norm of the difference between original and reconstructed data; a measure of reconstruction quality. "We report L2 error and maximum absolute error"
- Learned quantization parameters: Quantization scales or offsets trained to minimize error, rather than computed heuristically. "KVQuant achieves sub-4-bit precision through learned quantization parameters"
- Mean absolute difference: The average of absolute differences between two sets of values, used here to compare attention scores. "We measure the mean absolute difference between attention dot products computed with original and reconstructed keys"
- Memory-bound operation: A computation whose performance is limited by memory access speeds rather than computation. "KV cache quantization is fundamentally a memory-bound operation"
- Memory coalescing: Aligning thread memory accesses so that they map to contiguous addresses, maximizing bandwidth utilization. "Better memory coalescing"
- Memory fragmentation: Inefficient memory usage due to small, non-contiguous blocks, which paging can mitigate. "applies paging techniques to reduce memory fragmentation"
- Memory hierarchy: The layered structure of memory (registers, shared memory, caches, global memory) with varying speed and capacity. "optimize attention computation through kernel fusion and memory hierarchy exploitation"
- Naive kernel: A straightforward GPU kernel mapping one thread per element without advanced optimizations. "The naive approach assigns one thread per matrix element"
- PagedAttention: A method that uses paging to manage attention memory efficiently, as implemented in vLLM. "PagedAttention, implemented in the vLLM serving system, applies paging techniques to reduce memory fragmentation"
- Per-channel quantization: Using a separate scale factor per feature dimension to preserve precision across varying ranges. "We use per-channel quantization, where each dimension of the key vectors gets its own scale factor"
- Persistent kernels: Long-lived GPU kernels that retain resources across multiple operations to reduce launch overhead. "persistent kernels that maintain thread blocks across multiple quantization operations could amortize launch overhead"
- Quantization step size: The interval between adjacent quantized levels; half of this bounds the maximum rounding error. "This error is bounded by - half the quantization step size"
- Reconstruction error: The discrepancy between original data and its dequantized reconstruction after quantization. "Reconstruction error: How closely does the dequantized matrix match the original?"
- Reduction operations: Aggregations like sum or max across elements; often optimized with warp-level primitives. "enable more efficient reduction operations during scale computation"
- Scale factor: A value used to map floating-point ranges to integer ranges during quantization. "each dimension of the key vectors gets its own scale factor"
- Shared memory tiling: Caching data in fast shared memory per block to reduce redundant global memory accesses. "traditional optimizations like shared memory tiling offer limited benefit"
- Softmax: A function that converts logits into probabilities by exponentiation and normalization. "Given that attention scores typically span several orders of magnitude before softmax"
- TensorRT-LLM: An inference framework that integrates quantization and other optimizations for efficient transformer deployment. "TensorRT-LLM and similar systems integrate quantization into optimized inference pipelines"
- Thread coarsening: Assigning multiple data elements to each thread to increase work per thread and ILP. "Thread coarsening assigns multiple elements to each thread"
- Transformer architecture: The neural network design using self-attention mechanisms for sequence modeling. "Modern LLMs based on the Transformer architecture"
- vLLM: A serving system for LLM inference that incorporates memory optimizations like PagedAttention. "PagedAttention, implemented in the vLLM serving system"
- Vector load/store instructions: GPU operations that move multiple values per transaction (e.g., float4, char4) to improve bandwidth utilization. "The vectorized kernel uses vector load/store instructions (float4, char4) to process multiple elements per memory transaction"
- Vectorization: Processing multiple data elements per instruction to reduce memory transactions and increase throughput. "vectorization provides the most effective optimization by reducing memory transaction overhead"
- Vectorized kernel: A GPU kernel that operates on vectors of elements per thread, improving memory bandwidth efficiency. "Our vectorized kernel achieves up to 1,694× speedup over CPU baselines"
- Warp-level primitives: Operations enabling coordination and data exchange among threads within a GPU warp. "Warp-level primitives such as __shfl_down_sync could enable more efficient reduction operations during scale computation"
Collections
Sign up for free to add this paper to one or more collections.