- The paper demonstrates that instruction-augmented LLM retrievers achieve superior generalizability across diverse tasks through statistically principled evaluations.
- It details query and document perturbation experiments showing that architectural choices, particularly in decoder-only models, critically affect robustness.
- It highlights embedding geometry as a key diagnostic tool for vulnerability to perturbations, though it remains an intractable training target.
Robustness Evaluation of LLM-Based Dense Retrievers
Motivation and Scope
The paper "On the Robustness of LLM-Based Dense Retrievers: A Systematic Analysis of Generalizability and Stability" (2604.16576) provides a systematic robustness evaluation of state-of-the-art (SOTA) LLM-based dense retrievers. The work is centered around two axes: (1) generalizability across diverse retrieval tasks, query types, and corpus sources; (2) stability under query perturbations and document-side adversarial manipulations. The focus is on decoder-only architectures (e.g., Qwen3-Embedding, Linq, GTE, ReasonIR, DIVER, ReasonEmbed) which have overtaken encoder-based paradigms in leaderboard benchmarks like BEIR and BRIGHT. The evaluation protocol leverages linear mixed-effects models to disentangle intrinsic retriever performance from dataset heterogeneity, ensuring statistically principled comparison.
Generalizability Analysis
The generalizability study spans 30 datasets aggregated from MS MARCO, BEIR, BRIGHT, and BrowseComp-Plus. Datasets are classified by eleven task types, eight query types, and five corpus sources. Notably, standard macro-averaging is inadequate due to severe imbalance in dataset difficulty and query volumes. The proposed methodology, relying on linear mixed-effects models, produces difficulty-adjusted estimated marginal means (EMMs), enabling cross-model comparison in a statistically robust manner.
Instruction-augmented LLM retrievers (e.g., Qwen3, Linq, GTE) demonstrate the strongest average generalizability across diverse retrieval conditions, consistently outperforming encoder-based baselines. Reasoning-optimized retrievers (e.g., ReasonEmbed, ReasonIR, DIVER) exhibit a specialization tax: while excelling on reasoning-intensive benchmarks such as theorem retrieval and StackExchange posts, they underperform on standard factual or keyword-style tasks. Query-category-specific failure modes are observed, with ReasonEmbed nearly failing on INSTRUCTION and EXPERIENCE type queries.
Corpus provenance significantly modulates retrieval effectiveness: Wikipedia-based corpora are easier for all retrievers, but domain-specific KBs and noisy web corpora induce substantial variance. The interaction between retriever architecture and corpus source is highly non-uniform, reinforcing the necessity of factor-level, not pooled, evaluation.
Stability under Query and Document Perturbation
Query-Side Robustness
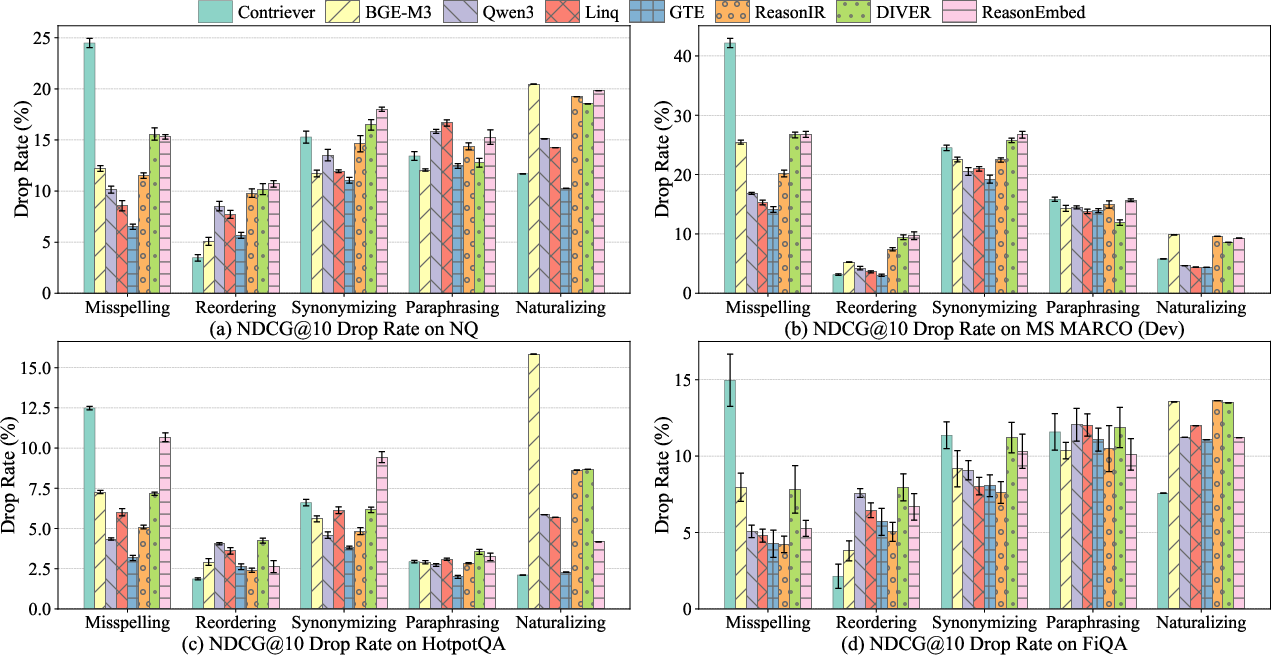
Query-side robustness is evaluated against five perturbation types: misspelling, reordering, synonymizing, paraphrasing, and naturalizing. The most prominent findings are:
Document-Side Robustness: Corpus Poisoning
Corpus poisoning attacks are examined both in white-box and transfer-based black-box settings with HotFlip-style adversarial document injection. Substantial variability emerges:
- White-box attacks: GTE consistently achieves 0% ASR@20, indicating empirical immunity. ReasonIR and Qwen3 also exhibit marked resistance (ASR@20 typically ≪ 5%). Encoder baselines (Contriever) are highly vulnerable (>90% ASR@20 at large attack budgets). Reasoning-oriented retrievers show no systematic improvement: ReasonEmbed and DIVER are moderately vulnerable on complex QA and multi-hop settings.
- Direct-transfer attacks: Transferability of adversarial documents across architecture boundaries is negligible; all ASR@20 values are <1%. This is attributed to architectural heterogeneity and embedding space divergence.
Factors Predictive of Robustness
Multiple candidate predictors are analyzed:
- Embedding Geometry (Isotropy): Angular uniformity (average pairwise cosine similarity) emerges as a robust diagnostic for lexical and surface-level perturbation vulnerability. Concentrated embedding spaces correlate with higher susceptibility to misspelling and synonymizing, and to corpus poisoning.
- Model Size: A scaling analysis within the Qwen3 embedding family shows improved robustness (lower drop rates, lower ASR@20) as model parameter count increases, but trends are not strictly monotonic cross-architecture.
- Spectral Norm: Shows weak, non-significant and dataset-dependent associations with robustness metrics, thus is not a reliable proxy.
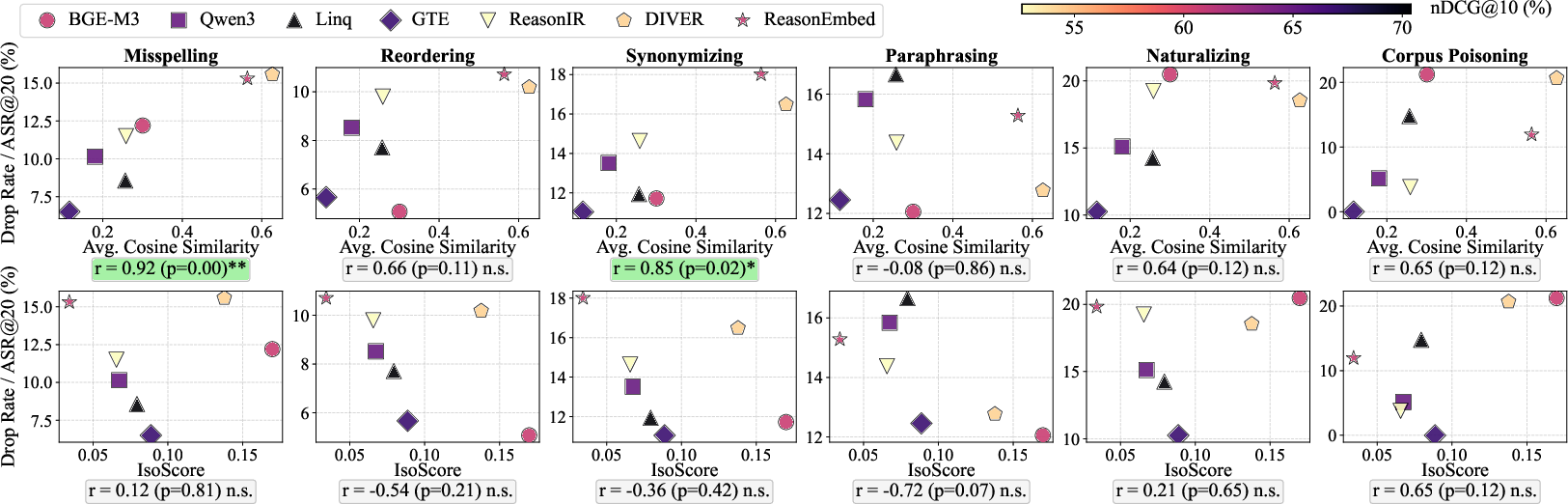
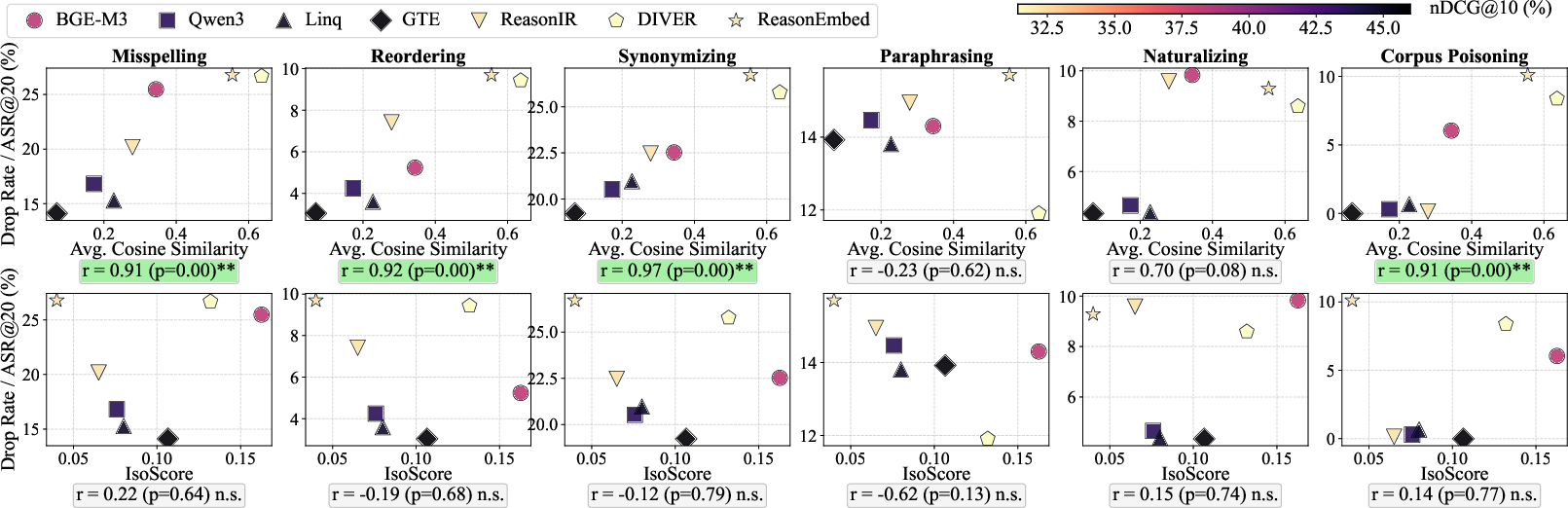
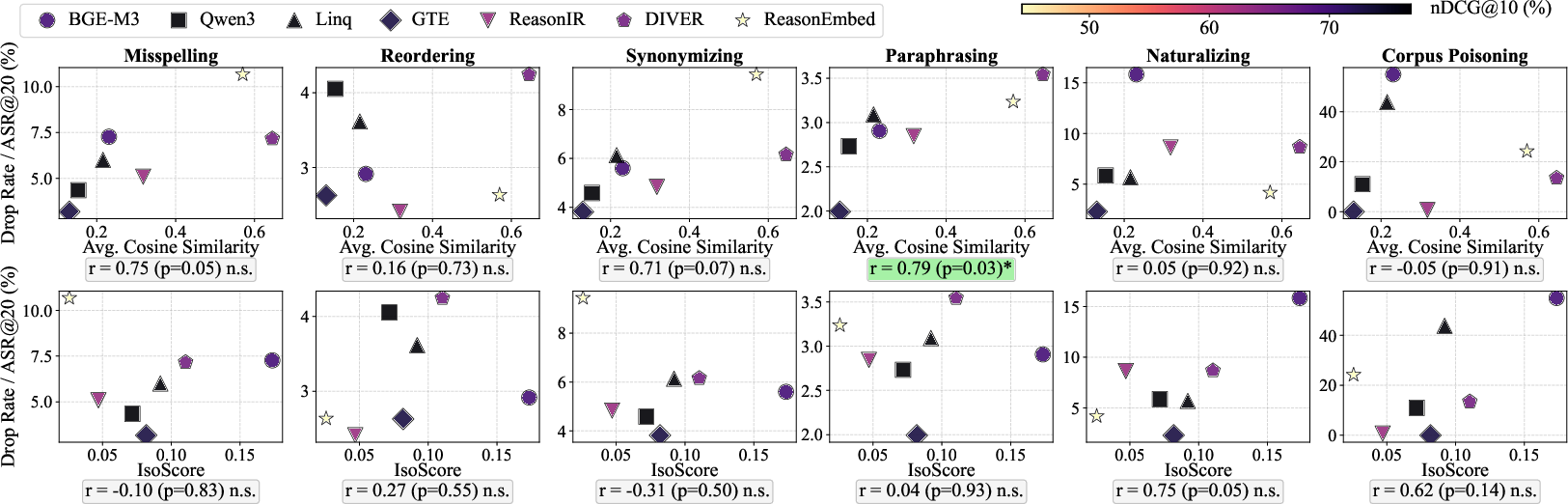
Figure 2: Embedding isotropy metrics (angular and variance uniformity) versus robustness across NQ.
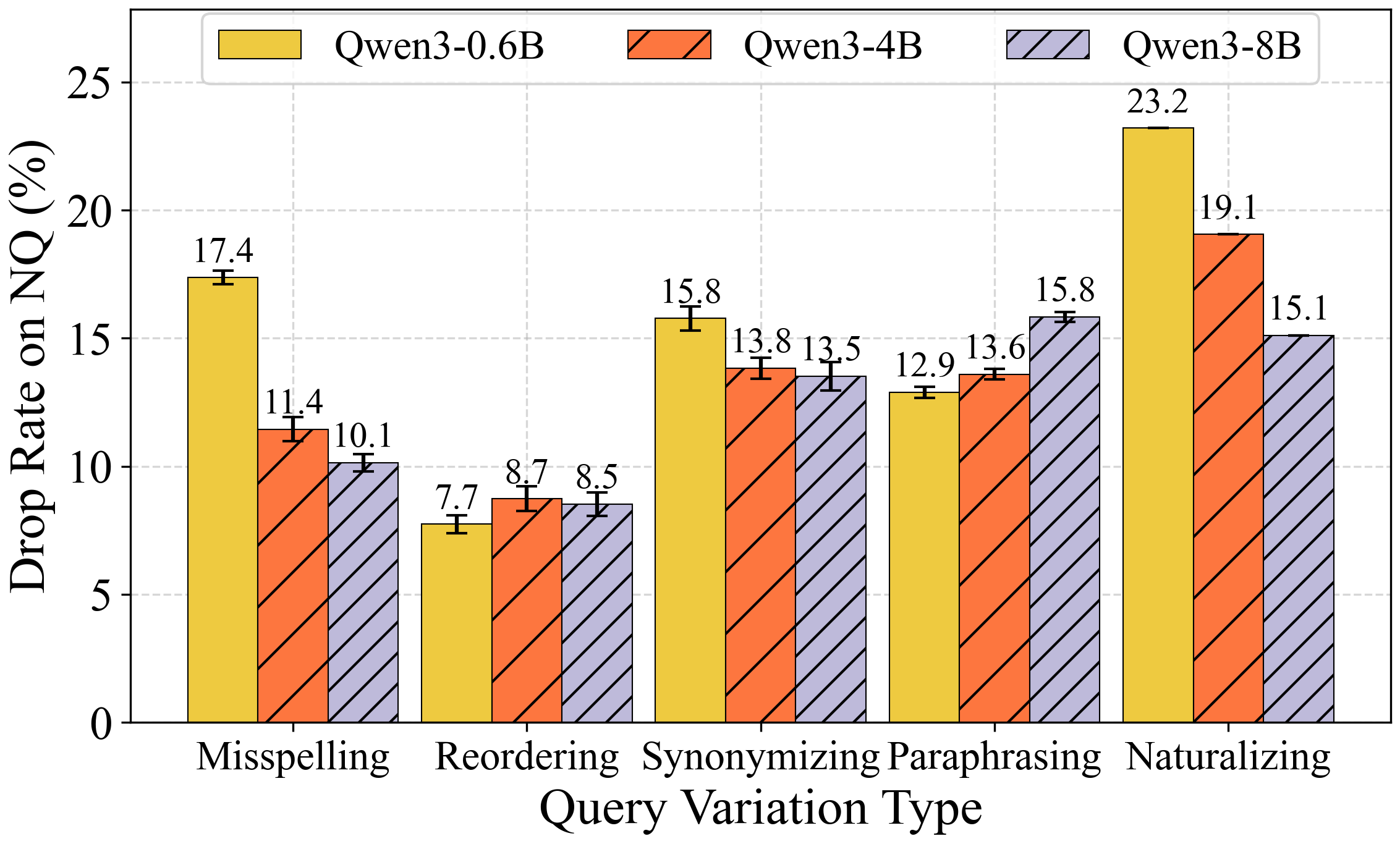
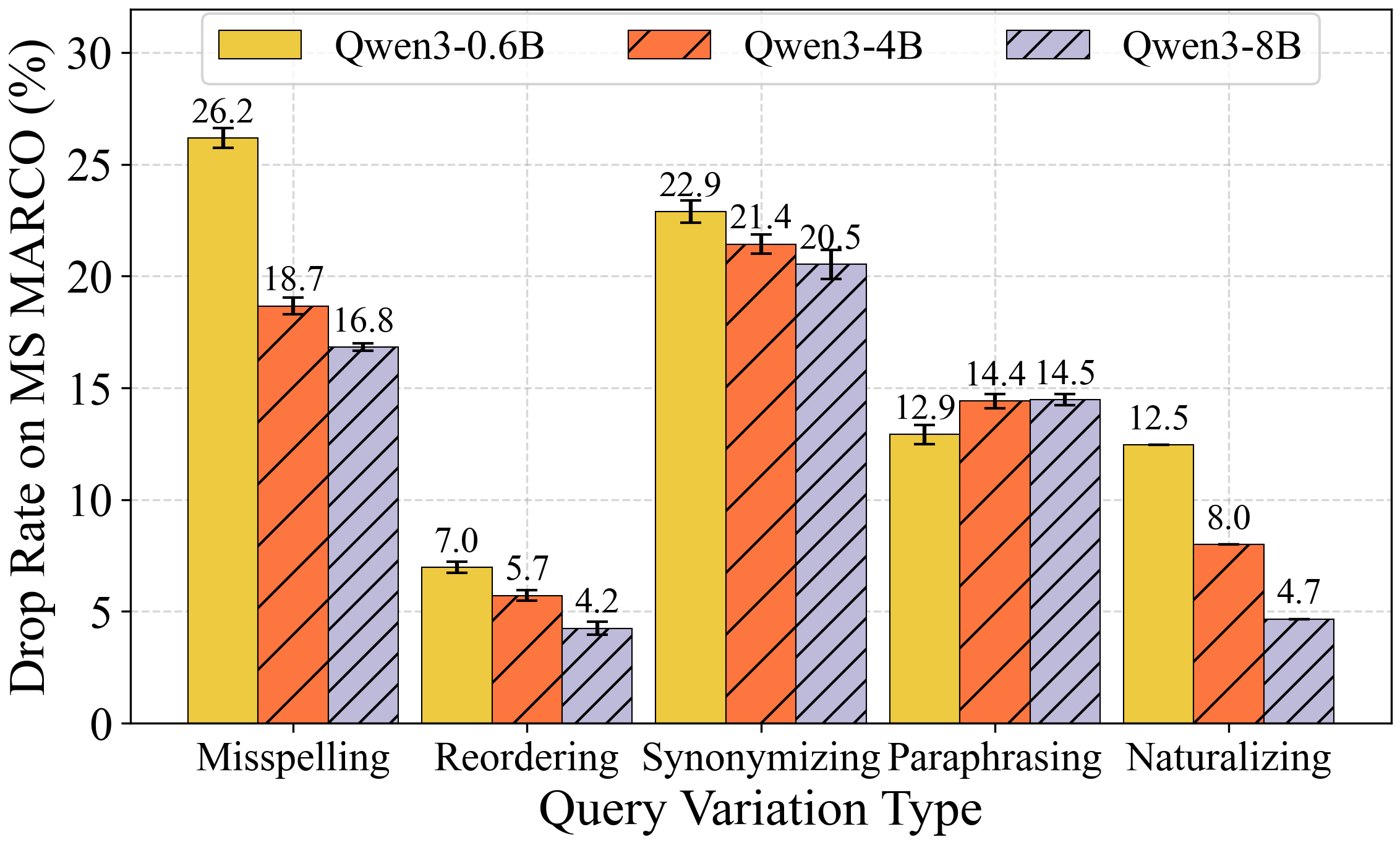
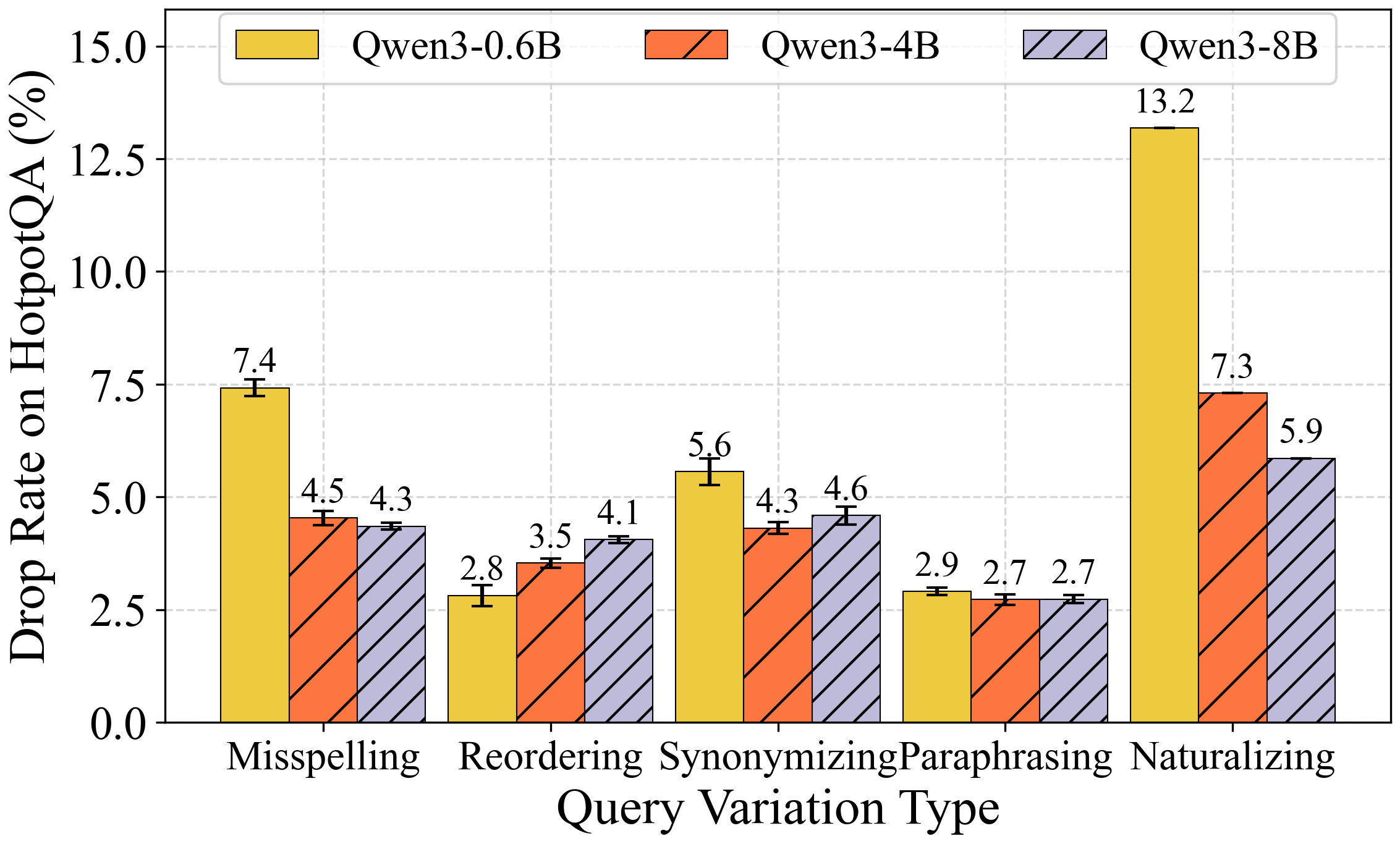
Figure 3: nDCG@10 drop rate (\%) for NQ under five query perturbation types for different retrievers.
Causal Interventions and Practical Implications
Controlled intervention experiments (LoRA fine-tuning with angular uniformity regularization, bidirectional attention conversion) demonstrate that manipulating embedding geometry does not yield consistent robustness gains, indicating that isotropy is a diagnostic but not yet an actionable training target. GTE's robustness is not reproduced by these interventions, underscoring the importance of unseen optimization-induced factors and training data diversity.
Robustness-aware model selection cannot be reduced to architecture labels or scale alone; empirical evaluation under threat-model-specific risk profiles is essential. Training objectives must be reoriented toward explicit query reformulation invariance—current SOTA retrievers remain vulnerable to semantic-preserving variations and adversarial document injection.
Conclusion
The study brings clarity to the robustness characteristics of LLM-based dense retrievers in both generalizability and stability dimensions. Instruction-augmented decoder retrievers achieve broad generalizability and improved robustness against input noise and corpus poisoning, though semantic perturbations remain critical failure modes. Reasoning-oriented retrievers exhibit a specialization tax which limits their applicability in heterogeneous environments. Embedding geometry is a powerful diagnostic, but is not causal at the current stage. Robustness remains a multi-dimensional challenge requiring factor-specific evaluation protocols and adversarially-aware objective design. Future work should develop training recipes for semantic perturbation invariance, expand black-box surrogate attack analyses, and generalize findings to multilingual retrieval.