- The paper demonstrates that decoder LLMs yield 73% lower flip rates than encoders under realistic text perturbations, ensuring explanation stability.
- It introduces a unified four-stage occlusion-based evaluation pipeline that systematically perturbs inputs at character, word, and sentence levels.
- The study proposes a three-tier deployment strategy aligning model stability and cost, thereby supporting regulatory compliance in enterprise NLP applications.
Robust Explanations for User Trust in Enterprise NLP Systems
Motivation and Problem Setting
Robust explanations are essential for maintaining user trust, auditability, and regulatory compliance in enterprise NLP systems, especially within domains such as finance and human resources. The increasing migration from encoder-based models (BERT, RoBERTa) to decoder-based LLMs (Qwen, Llama) in production settings presents new challenges: enterprises often have only API access, restricting explainability to black-box, model-agnostic methods. Existing literature does not adequately inform whether LLMs yield more stable explanations under user-performed text perturbations, which are common in deployment due to edits, rephrasings, and noise. This paper addresses this gap by proposing a unified, architecture-agnostic evaluation protocol for explanation robustness and systematically comparing encoder and decoder models under realistic input perturbations.
Evaluation Pipeline and Methodology
The study introduces a four-stage, black-box robustness evaluation pipeline tailored for enterprise scenarios with only input-output model access. The framework systematically perturbs input text on character, word, and sentence levels with controlled severity and assesses explanation stability using a unified occlusion-based (Leave-One-Out) approach that measures the impact of token removal via API calls.
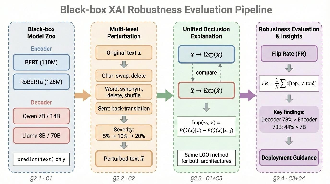
Figure 1: Four-stage pipeline for black-box robustness evaluation: Model selection, multi-level input perturbation, unified occlusion-based explanation, and actionable robustness analysis.
Flip Rate (FR), which measures the probability that the top-importance token in the explanation changes after perturbation, serves as the main robustness metric. This enables direct, interpretable comparison between models under multiple perturbation settings without access to internal representations, gradients, or attention scores.
Main Results: Decoder LLMs Surpass Encoders in Explanation Stability
A cross-architecture evaluation comprising 64,800 paired instances, with equal numbers of perturbations per setting, reveals that decoder LLMs provide substantially more stable explanations than encoder baselines. Specifically, decoders deliver 73% lower average flip rates across SST-2, AG News, and IMDB datasets—0.470 for encoders vs. 0.125 for decoders. This effect is consistent, with the largest stability gap in the IMDB dataset, which contains longer text instances. Encoder explanations degrade rapidly as context length increases, undermining trust in deployment scenarios reliant on explanation stability.
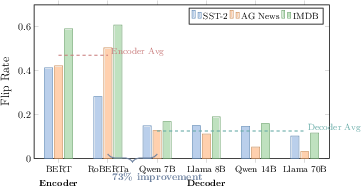
Figure 2: Flip rate comparison shows encoders (BERT, RoBERTa) exhibit markedly higher instability in explanations versus decoder LLMs across all datasets, most notably on longer-form text.
The analysis directly challenges the implicit assumption that scaling up encoder-based classifiers—or relying solely on their well-understood internals—ensures robust explanations in enterprise contexts. Instead, decoder LLMs, even at moderate scales (e.g., Qwen 7B, Llama 8B), significantly outperform both BERT and RoBERTa.
Scaling Effects and Perturbation Granularity
Explanation stability improves monotonically with decoder LLM scale: Llama 70B achieves flip rates (0.083) 44% lower than Qwen 7B (0.149) and Llama 8B (0.150). The impact of scale is most pronounced on medium and long-form classification datasets and persists across both Qwen and Llama families, indicating an architectural rather than training-specific effect.
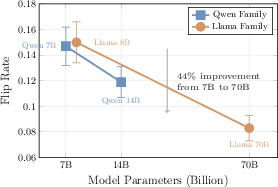
Figure 3: Flip rate reduction demonstrates monotonic gains in explanation stability as LLM scale increases, supporting a scaling law for robust explanations.
Granular analysis by perturbation type underscores that decoder LLMs offer superior robustness to destructive modifications (token deletion, word shuffling) that are prevalent in production user-generated data. While both model families display low flip rates under back-translation and synonym substitution (i.e., semantic-preserving perturbations), only decoders maintain stability under severe syntactic and surface-level disruptions. This strongly suggests decoder LLMs encode more holistic, distributional representations that are less brittle to surface noise at deployment time.
Implications for Enterprise Deployment and Regulation
The paper operationalizes its findings for use in real-world decision frameworks. A three-tier deployment strategy naturally emerges from the empirical flip rate distribution and associated inference costs. Large decoder LLMs are allocated to high-compliance and audit-heavy workflows (Regulatory tier), moderate-scale decoders to user-facing applications (Balanced), and encoders to high-speed/low-explanation stakes scenarios (Speed-first). The paper provides explicit cost multipliers to quantify the computational expense of occlusion-based explanation on these model classes, essential for cost-benefit analysis in large-scale enterprise roll-outs.
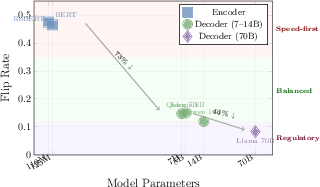
Figure 4: Cost-stability trade-off curve stratifies black-box explainers into three deployment tiers (encoder, mid-size decoder, large decoder), mapping stability and computational cost to practical enterprise needs.
In regulatory contexts—particularly under EU AI Act and other algorithmic accountability statutes—the high instability (≈47% top-token change rate) of encoder explanations likely fails consistency and traceability thresholds. The empirical evidence here motivates prioritizing decoder LLMs for any application where explanation robustness is tied to compliance or audit risk.
Theoretical Considerations and Future Directions
The results extend beyond empirical guidance to raise important theoretical questions. The scaling effect parallels known capability scaling laws in LLMs and suggests that robust explanation and robustness to input noise may be emergent properties of large-scale autoregressive training. Decoder LLMs’ superior stability under destructive perturbations implies a fundamentally different attribution topology compared to bidirectional encoders, perhaps due to more global conditioning per token. While the focus is on robustness (stability), the findings decouple stability from faithfulness—future work should interrogate whether more stable explanations are also more faithful in the presence of confounding or adversarially misleading inputs.
The computational cost of occlusion (proportional to input length and model size) remains significant for always-on explanations, but this is mitigated in pre-deployment validation or selective audit workflows. Opportunities exist for developing more sample-efficient or approximate black-box attribution methods without sacrificing robustness guarantees.
Conclusion
This work establishes, in a black-box enterprise-relevant regime, that decoder LLMs provide significantly more stable explanations than encoders, with explicit empirical quantification (73% average reduction in explanation instability, and a further 44% improvement with scale). The stability gains generalize across datasets and perturbation types, with strong implications for regulated and user-critical NLP deployments. The proposed three-tier framework for explanation robustness supports operational model selection under cost and compliance constraints. These results should inform the development of future regulatory guidelines and motivate further research into scaling laws, faithfulness-robustness decoupling, and efficient robust explainability methods for black-box LLMs.