- The paper introduces a tool-augmented LLM framework leveraging iterative REPL feedback to boost formal translation faithfulness from 28% to over 60.5%.
- The evaluation reveals that compiler feedback is dominant, with symbol search stabilizing iteration efficiency while expert drafting shows marginal benefits.
- A full factorial analysis uncovers negative tool interactions and highlights iterative repair as key to achieving robust Lean 4 formalization.
Agent Architecture and Design Principles
The paper "Understanding Tool-Augmented Agents for Lean Formalization: A Factorial Analysis" (2604.16538) systematically investigates tool-augmented LLM-based agents for the translation of natural-language mathematical statements into faithful Lean 4 code. The proposed architecture features a central LLM orchestrator (primarily GPT-5.2), which interacts through API interfaces with three tool modalities: (i) Mathlib symbol retrieval, (ii) fine-tuned expert drafting, and (iii) Lean compiler feedback (REPL). The system operates in an iterative control loop, enabling persistent state tracking and incremental correction of both syntactic and semantic errors.
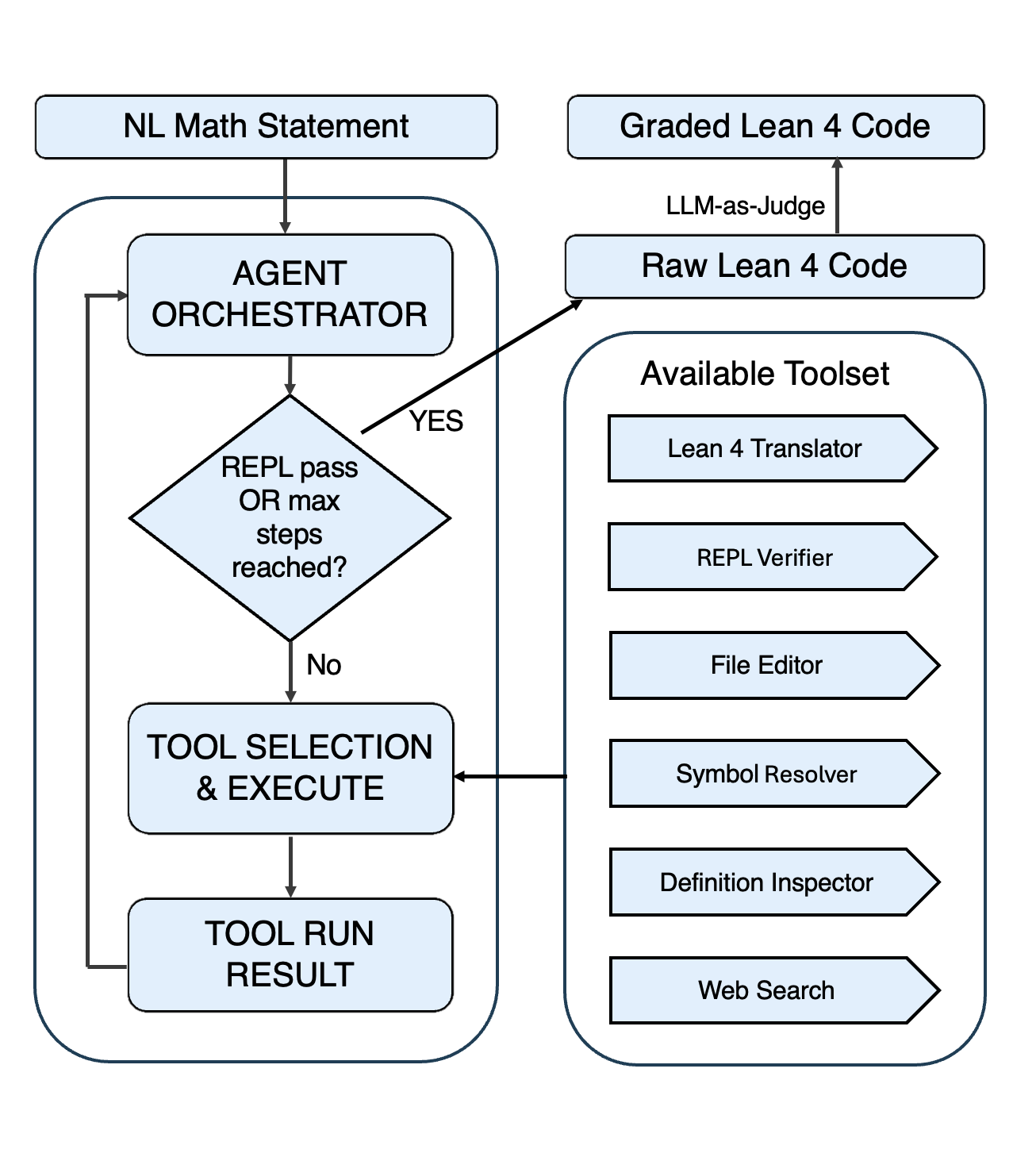
Figure 1: Agent orchestration logic, comprising a central LLM orchestrator interfacing with Lean 4 execution and tool APIs.
This agentic design fundamentally decouples language modeling from formal verification. Unlike static prompting, the framework leverages actionable compiler diagnostics and retrieval-based contextualization, iterating until either compilation succeeds or the inference budget is exhausted.
Benchmark and Evaluation Methodology
The authors constructed a rigorous benchmark consisting of 400 graduate-level theorems sampled evenly across Real Analysis, Complex Analysis, Topology, and Algebra. The evaluation proceeds in two stages: (1) Lean 4 compilation checks enforce strict syntactic validity; (2) a LLM-as-a-Judge protocol (GPT-5.2, validated against Gemini-2.5-Pro and human experts) assigns a faithfulness score (0–10) based on semantic equivalence to the source statement.
The faithfulness metric is conservative, requiring both successful compilation and a subjective score ≥9 to count as a "Faithful" translation. Cross-validation demonstrates >97% binary agreement between independent judges for faithful outputs, with human expert audits corroborating the robustness and precision of the metric.
Tool augmentation produces substantial gains over static one-shot prompting. One-shot GPT-5.2 and Herald both compile only 26% of statements, with faithfulness rates from 10.8% (Herald) to 28.0% (Gemini-2.5-Pro). The fully enabled agent (Tmax=24) achieves 89.5% compilation and 60.5% faithfulness—more than doubling the strongest baseline.
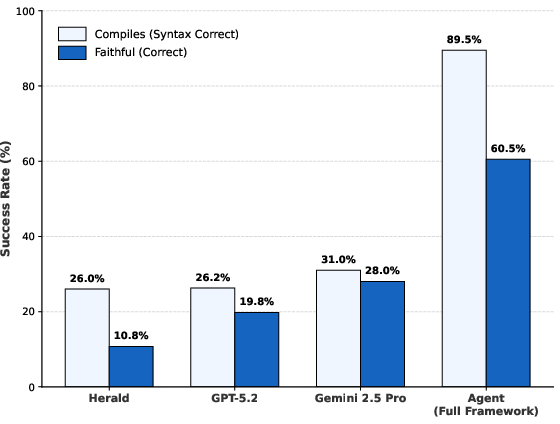
Figure 2: The full tool-augmented framework outperforms one-shot baselines in compilation and semantic faithfulness.
Stepwise analysis reveals rapid convergence in the first 8 iterations, with diminishing returns after step 14, suggesting practical saturation of agentic repair within this budget.
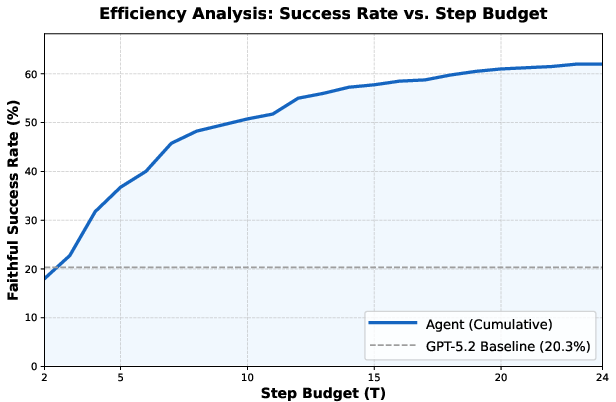
Figure 3: Cumulative faithfulness rate as a function of inference step budget, illustrating agent convergence behavior.
Domain-level analysis indicates that Complex Analysis statements require fewer iterations for successful formalization, while Real Analysis and Algebra are more computationally expensive, corresponding with observed domain difficulty in both agent performance and judge disagreement levels.
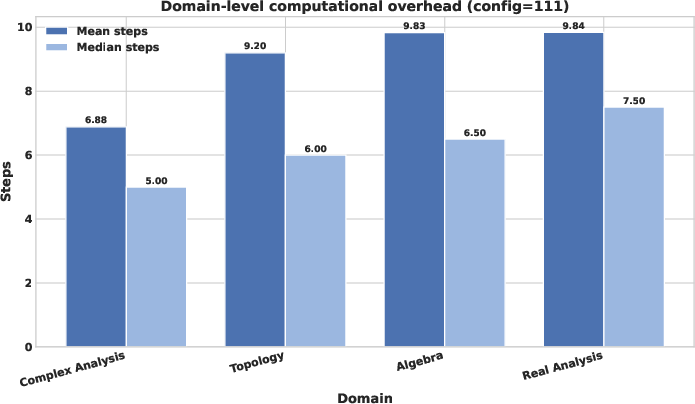
Figure 4: Domain-level computational overhead, reporting mean and median agent steps for each mathematical domain.
A full 23 factorial design is employed to quantify the marginal and interactive effects of each tool category: Translation expert (T), Compiler Feedback (F), and Search (S). The analysis reveals:
- Compiler Feedback (F) is the dominant capability bottleneck. Enabling REPL feedback increases faithfulness by +32.3 points, transforming low-success regimes into high-success regimes. The compiler acts as the key mechanism for semantic verification and repair.
- Search tools (S) stabilize and accelerate convergence. Symbol-level retrieval adds +6.8 points on average, with pronounced effect (+12.4 pts) when REPL is absent, but near-zero marginal improvement when feedback is present, indicating functional subsumption.
- Expert drafting (T) has marginal impact (+0.9 pts). Specialist drafts only enhance accuracy in feedback-free regimes and can induce anchoring penalties when coupled with REPL-driven repair, primarily due to generalist orchestrator strength and wide-scale pretraining.
Interaction analysis exposes negative synergy (F×S=−11.1, F×T=−5.9), confirming that whole-program diagnostics via REPL subsume symbol-level search, and that specialist drafting becomes redundant or counterproductive once repair dynamics are operationalized.
Behavioral Traces and Practical Efficiency
Tool invocation logs validate that symbol-search tools dramatically lower REPL invocation counts (up to 29.8% reduction). This suggests that agents shift from expensive compile-repair iterations to more cost-efficient symbol-level validation when both modalities are available. These interaction traces constitute valuable datasets for further RL-based research on iterative repair and trial-and-error learning for formalization tasks.
Robustness and Generalizability
The superiority of compiler feedback is not model-specific. Multi-model evaluations (Gemini-2.5-Pro, Claude Sonnet 4.5) under full agent configuration converge to 60–65% consensus faithful, regardless of highly variable one-shot baseline performance, indicating that structural gains derive from tool modalities, not orchestrator idiosyncrasies.
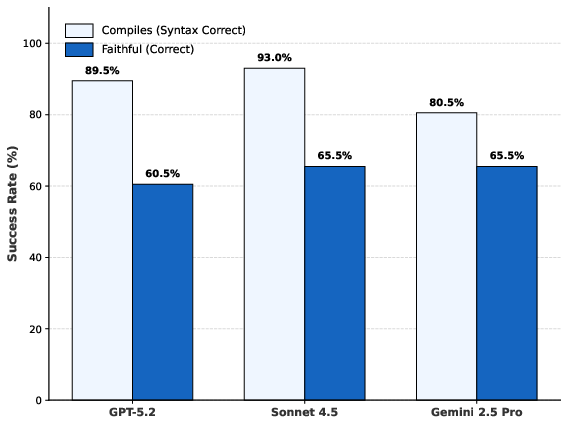
Figure 5: Multi-model agent comparison, demonstrating model-agnostic convergence to consensus faithfulness under tool augmentation.
Disagreements in judge scores concentrate in Real Analysis, likely due to intrinsic domain difficulty and less robust Mathlib coverage, reinforcing that semantic evaluation challenges correlate with formalization complexity.
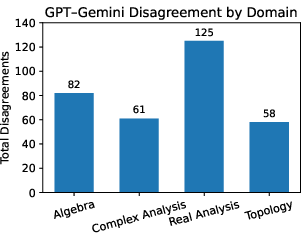
Figure 6: Domain-level judge disagreements, with Real Analysis exhibiting the greatest variance between LLM judges.
Limitations and Theoretical Implications
The framework focuses on statement-level translation, not on provability or proof search; thus, the scope is limited to assertion formalization. The study depends on the Lean 4 environment for feedback—future extensions could integrate offline retrieval or static Mathlib indices to reduce environmental dependency. Benchmark coverage excludes combinatorial or discrete domains and remains compute-intensive compared to one-shot generation.
Future Directions and Impact
This research demonstrates that iterative verification and retrieval are more critical to reliable Lean formalization than parametric specialization. High-precision execution environments should scaffold LLM reasoning, complemented by targeted retrieval for efficiency. For evolving formal libraries, static snapshots and offline fine-tuning are brittle; sustained progress requires verification-coupled iteration and continuous adaptation.
The paradigm outlined in this work will shape future systems for bridging informal and formal mathematics. The released benchmarks, tool logs, and agent traces will facilitate RL research and benchmarking for the broader formalization community.
Conclusion
Systematic tool augmentation transforms the landscape of automatic formalization in Lean 4, elevating faithfulness from 28% to 60.5% in a challenging benchmark. Compiler feedback is the primary capability driver, while symbol-level search accelerates the process and expert drafting is largely substitutable. These results establish verification-coupled iteration as the central pillar for scalable mathematical formalization, with theoretical and practical implications for future AI-driven formal reasoning systems.

