- The paper demonstrates that task rewards are essential for achieving stable and robust reinforcement learning outcomes in LLM fine-tuning.
- It compares four regimes—task-reward RL, tilted sampling, distribution sharpening, and tempered sampling—to reveal performance and stability trade-offs.
- Empirical results indicate that while distribution sharpening can boost inference accuracy, only task-reward RL reliably maintains optimal performance on complex tasks.
Beyond Distribution Sharpening: The Importance of Task Rewards
Introduction
The paper "Beyond Distribution Sharpening: The Importance of Task Rewards" (2604.16259) presents a rigorous, comparative study on the roles and limitations of distribution sharpening and task-reward-based reinforcement learning (RL) in the post-training of LLMs. Leveraging a unified KL-regularized RL framework, the authors establish experimental and theoretical boundaries for each paradigm, employing a suite of mathematical reasoning datasets and several state-of-the-art LLMs to substantiate their analysis.
Theoretical Foundations
The study formalizes the problem in the context of KL-regularized RL, where the policy optimization blends task reward maximization with divergence regularization to a reference model. Four regimes are instantiated by modulating the reward signal and KL reference:
- Task-Reward RL: Pure optimization for verifiable task rewards, leading to policies that prioritize maximizing external objective signals.
- Tilted Sampling: Intermediate regime balancing task rewards and reference likelihood via tempered distributions.
- Distribution Sharpening: Optimization that intensifies the base model's preference structure, seeking high-likelihood trajectories without external reward signals.
- Tempered Sampling: Sampling variants that increase concentration via temperature modulation without incorporating rewards.
The authors show that the global optimum under distribution sharpening is inherently biased toward shorter sequences due to the construction of log-likelihood objectives and EOS handling, which is not necessarily aligned with verifiable task performance.
Empirical Analysis
Experiments on Llama-3.2-3B-Instruct, Qwen2.5-3B-Instruct, and Qwen3-4B-Instruct-2507 using mathematical benchmarks reveal critical distinctions between distribution sharpening and task-reward approaches. Distribution sharpening via inference-time methods (e.g., beam search, power sampling) yields noticeable improvements over vanilla base models, confirming that the base model latent capabilities can be elicited by confidence amplification. However, these gains are limited and often plateau at a suboptimal level for more complex tasks.
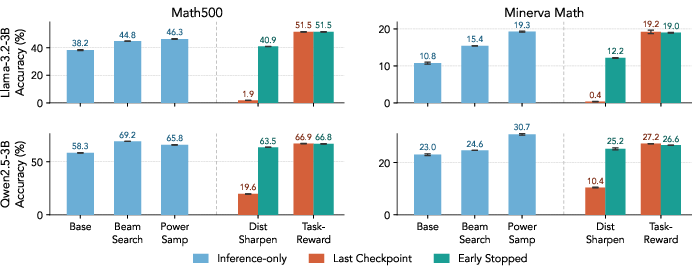
Figure 1: Pass@1 accuracy for 3B models; inference-time sharpening can approach task-reward RL early on, but RL-based sharpening is unstable.
Instances of fine-tuning for distribution sharpening with RL show high instability, with initial improvements followed by catastrophic degradation—especially in variable-length settings. In contrast, task-reward RL consistently converges to more favorable optima, with both stable training dynamics and superior final results. The phenomenon is accentuated as model and task complexity increase.
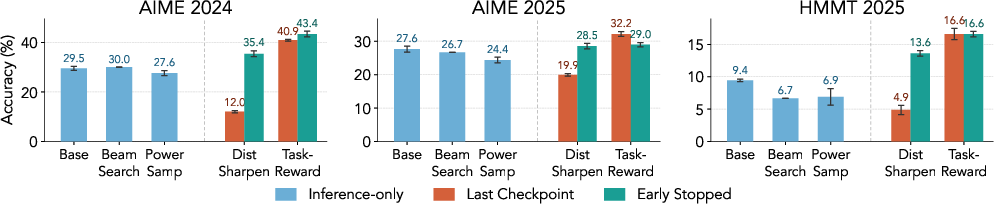
Figure 2: Pass@1 accuracy in a 4B setting; task-reward RL not only dominates, but distribution sharpening RL is less stable and frequently underperforms standard decoding.
Influence of Reward Signal and Parameters
The authors further quantify the essentiality of explicit task rewards using the tilted sampling regime. By sweeping the β parameter (controlling reward signal strength), they demonstrate a monotonic increase in both performance and training stability as reliance on the true environment reward increases. The extreme case with no task reward (β=∞) is highly unstable in variable-length settings.
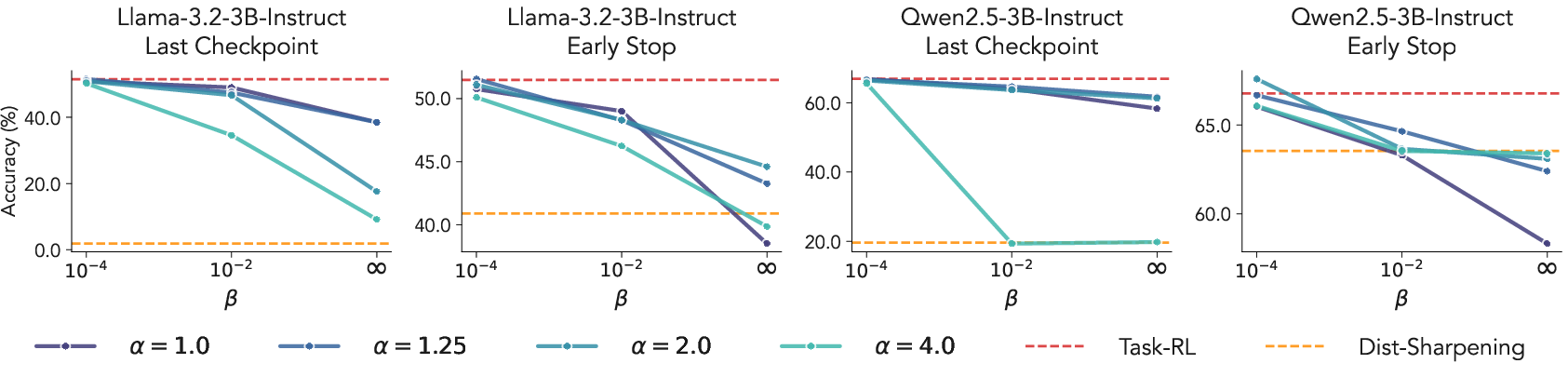
Figure 3: Increased reliance on task-reward (β↓) yields both smoother convergence and better accuracy in math benchmarks.
Stability and performance improvements are especially pronounced for the hardest tasks tested (AIME 2024/2025, HMMT 2025), where the base policy is demonstrably uncertain, highlighting that sharpening alone is insufficient for complex compositional reasoning.
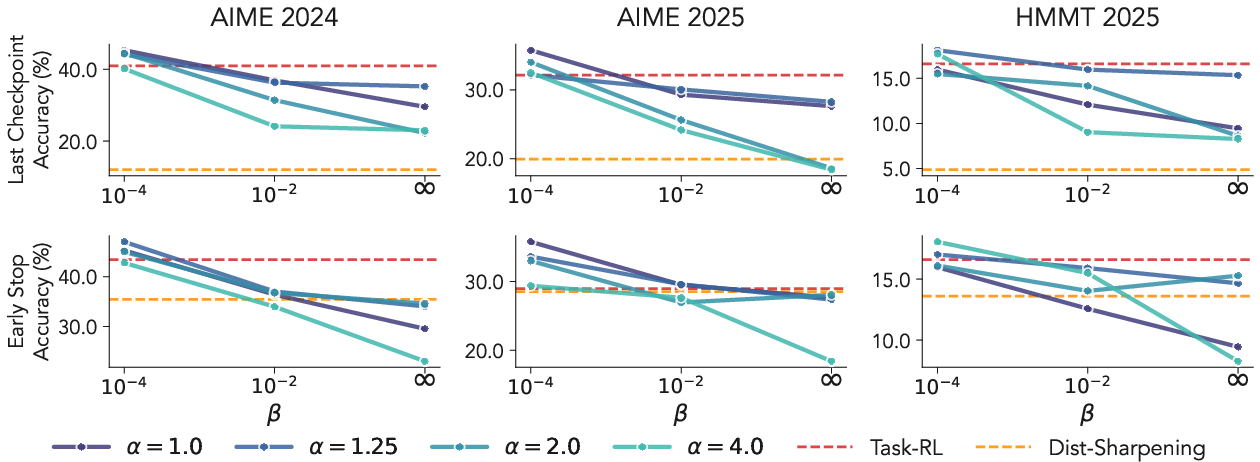
Figure 4: The same trend—task-reward signal dominates training stability and outcome—holds for 4B models on challenging data.
Training Dynamics and Pathologies
Fine-grained inspection of training curves reveals that while RL-based sharpening increases the training objective (log-likelihood), it systematically collapses entropy and sequence length, confirming the optima’s bias towards brevity and consequent decay in actual task reward. The RL optimization itself performs correctly—the limitation is intrinsic to the objective function, not to the optimization protocol.
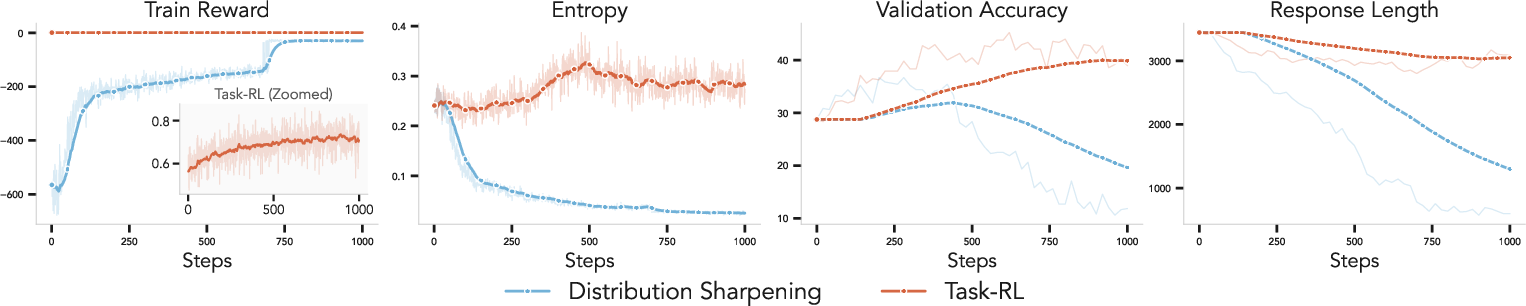
Figure 5: Both RL variants steadily improve their own objective, but only task-reward RL maintains validation accuracy and healthy entropy/length.
By fixing output response lengths (i.e., eliminating EOS-handling pathologies), distribution sharpening RL can achieve stability. However, such a solution is artificial and not aligned with general sequence modeling desiderata.
Sampling Regimes and Practicality
Further analysis shows that while combining both reward and distribution sharpening (tilted sampling) may, in rare cases, realize marginal performance gains for the hardest instances, these improvements are not robust, and excessive sharpening (high α, high β) destabilizes training.
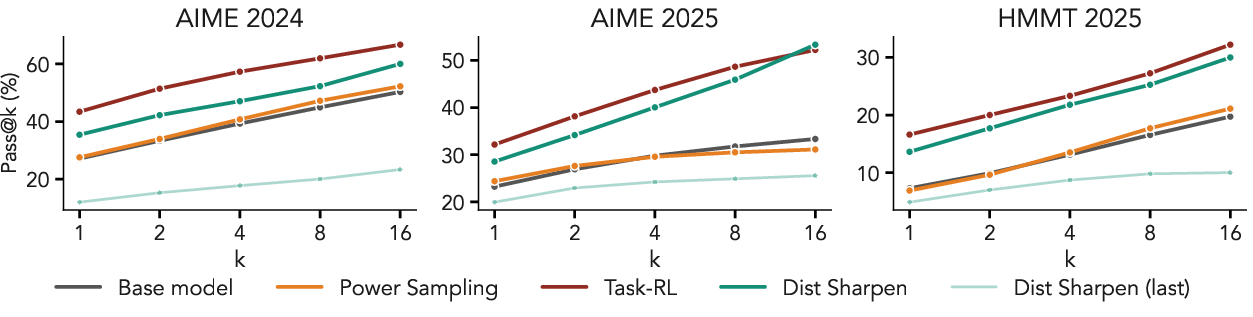
Figure 6: Pass@k performance for various sampling and fine-tuning regimes; task-reward RL dominates all.
The cost of power sampling and similar methods is also highlighted: inference-time complexity is significantly increased with limited return compared to principled reward-driven RL.
Theoretical and Practical Implications
The results establish several key observations:
- Limitations of Distribution Sharpening: While distribution sharpening can elicit latent knowledge from LLMs, it is fundamentally limited by unfavorable optima and instability, particularly in autoregressive, variable-length settings.
- Centrality of Task Rewards: Task-reward signals are both necessary and sufficient for stable, high-reward policies, especially as task complexity increases. They induce policies that generalize better beyond sharpening-induced confidence amplification.
- Unified Training Recipe: By decoupling the effects of environment reward and latent preference sharpening on a common training scaffold, the analysis clarifies that improvements attributed to RL cannot be reduced to sharpening.
- Design of RL Pipelines: For future scaling of instruction- or capability-driven LLMs, emphasis must remain squarely on well-engineered reward functions, rather than further sophistication in inference-time or self-improvement sharpening.
Conclusion
This work provides a formal demarcation between distribution sharpening and task-reward-based RL in LLM finetuning. Empirical and theoretical evidence jointly demonstrate the inadequacy of sharpening as a sole post-training strategy; only explicit optimization for ground truth rewards yields the robust, stable, and scalable improvements demanded by complex reasoning tasks. Future progress in RL-driven LLMs will require continued investment in task- and preference-model design, rather than reliance on inference-time augmentation or self-sharpening paradigms.