- The paper demonstrates that RL, via the PASS@(k, T) framework, uniquely expands the capability boundary of LLM agents on compositional tool-use tasks.
- The study shows RL’s strength lies in reweighting reasoning paths rather than solely improving sampling efficiency, distinguishing it from SFT.
- The experiments reveal that for deep sequential tasks, RL attains a net gain in problem-solving, underscoring its advantage in compositional reasoning.
Reinforcement Learning and the Capability Boundary of LLM Agents: A PASS@(k, T) Analysis
Introduction and Motivation
This work addresses the ambiguity underlying observed performance improvements in LLM agents trained with reinforcement learning (RL): whether RL primarily enhances the efficiency with which LLM agents solve tasks they could already tackle in principle, or whether it extends the set of tasks the agent can solve at all—i.e., expands the agent's capability boundary. Previously, static mathematical reasoning studies have shown that RL redistributes probability mass within the base model's capability set, with RL-trained and base models converging at large sampling budgets (high k) and no evidence of true boundary expansion.
However, the genericization from static reasoning to agentic LLMs that perform multi-round tool use is nontrivial. In agentic settings, the interaction depth T—the number of consecutive actions with the environment (e.g., retrievals)—may grant RL-trained agents structural access to compositional strategies that base policies cannot realize through repeated sampling. To systematically disentangle efficiency versus true capability expansion, the authors introduce a two-dimensional evaluation metric, PASS@(k,T), which separates the roles of sampling breadth (k) and interaction depth (T).
The PASS@(k,T) Framework
PASS@(k,T) defines the probability that an agent correctly solves a problem given a sampling budget of k independent episodes, each allowed at most T interaction rounds. This directly generalizes standard pass@k, which ignores agentic interaction and is insufficient for evaluating compositional tool-use. Increasing T0 probes sampling reliability, whereas increasing T1 enables deeper sequential interaction with the environment—potentially unlocking qualitatively novel solution strategies.
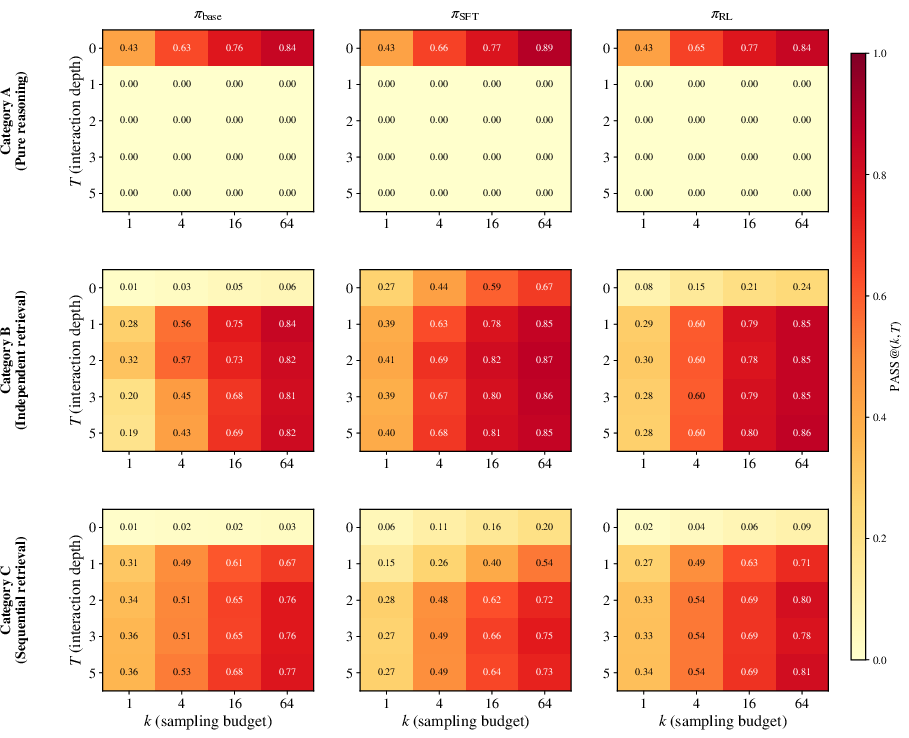
Figure 1: The two-dimensional PASS@T2 landscape, with rows for task categories and columns for models. Category A is flat in T3. In Category B, surfaces saturate at T4. In Category C, the RL-trained agent's panel warms with increasing T5 (especially at T6), while SFT's is cooler, reflecting the varying degree of capability expansion.
The two axes thus enable a direct operationalization of:
- Capability boundary: The class of tasks an agent can solve at least once as T7, for a fixed T8.
- Capability expansion: An RL-trained agent solves problems no base model can solve at any T9, (k,T)0 fixed.
- Efficiency improvement: At fixed (k,T)1, RL improves pass@1 or pass@(k,T)2 within the shared solvable set.
Experimental Design and Task Structure
To empirically quantify RL's effect on agentic LLMs, three categories of increasing compositionality are used:
- Category A: Pure parametric (static) reasoning (MATH-500), no tool access.
- Category B: Comparison questions requiring independent (parallel) retrievals (HotPotQA).
- Category C: Bridge questions requiring sequential, compositional retrievals, with later queries dependent on knowledge extracted in earlier interactions.
All models utilize Qwen2.5-7B-Instruct as a base. The SFT model is fine-tuned on expert demonstrations; the RL model is trained via GRPO with binary exact-match reward, matched in both architecture and data exposure to SFT. The key manipulation is that only the training signal differs between SFT and RL—expert imitation versus self-directed reward optimization.
Quantitative Results: Boundary Expansion and RL
The experiments reveal a tripartite pattern by task complexity:
- Category A (No tool use): All models, including RL, exhibit equal capability boundary. RL has no effect, an orthogonal replication of static pass@(k,T)3 results.
- Category B (Independent retrieval): RL achieves a small net expansion (e.g., 5 additional problems solved, 1 regression), similar in effect to SFT.
- Category C (Compositional, sequential retrieval): RL expands the boundary most substantially: 5 new problems uniquely solved compared to base, and only 1 regression (yielding a net +4), while SFT actually regresses relative to base (net -4 problems).
At the capability-boundary limit ((k,T)4, (k,T)5) in Category C, RL achieves (k,T)6 versus base at (k,T)7 and SFT at (k,T)8 for PASS@(k,T)9.
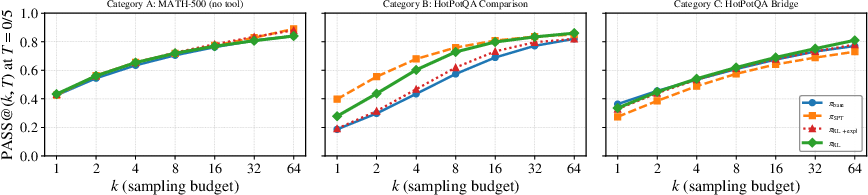
Figure 2: PASS@k0 versus k1 on a log scale. In Category C, the RL-trained agent's curve pulls away from base as k2 increases, contradicting static-case convergence.
Uniquely, on bridge questions, the RL curve diverges above the base as k3 grows, indicating problems that RL can solve with at least one sample that the base never solves, for any k4. This is incompatible with the static-case conclusion that RL only improves reliability.
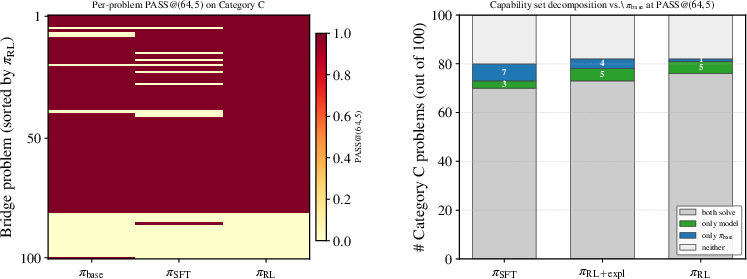
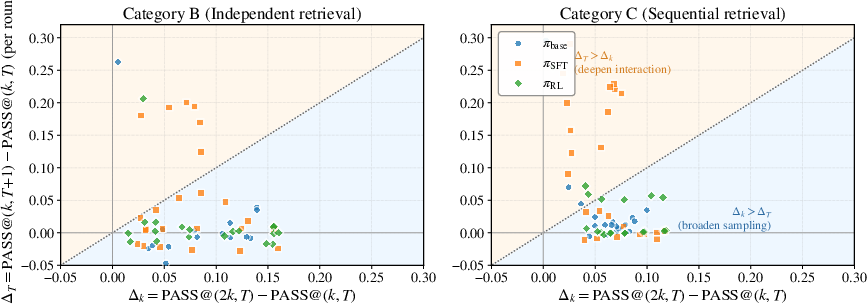
Figure 3: Left, per-problem PASS@(64,5) on bridge questions, rows sorted by RL values. Right, capability-set decomposition against base; RL exhibits a 5:1 asymmetry (5 RL-only, 1 base-only), the sharpest evidence of boundary expansion.
Mechanistic Diagnostic: How Does RL Achieve Expansion?
A three-pronged mechanism analysis interrogates where RL's gains originate:
- Perplexity decomposition: RL's divergence from base is concentrated in reasoning (how to integrate observations), not the search queries issued. Median base-model perplexity is substantially higher for reasoning tokens than for queries in successful RL trajectories.
- Strategy diversity: RL retains much of the base model's strategic diversity, focusing on reweighting within the existing strategy space toward trajectories with successful downstream reasoning. SFT, by contrast, collapses to a narrow set of expert-demonstrated query chains, losing diversity and regressing on problems where expert demonstrations are suboptimal.
- Cross-policy swapping: Isolating retrieval plan and reasoning components demonstrates that both components contribute to overall accuracy, with a mild tilt toward retrieval planning. However, improvement concentrates in RL's handling of observation integration, not query generation.
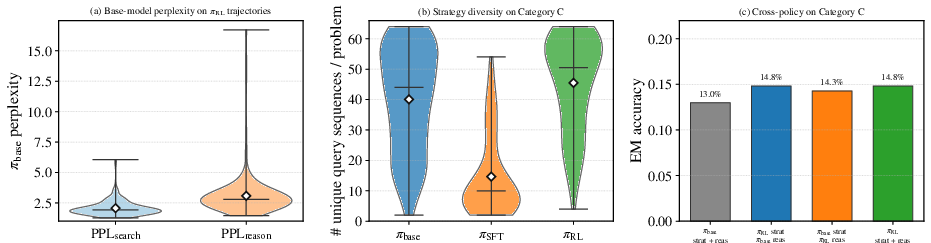
Figure 4: a) Perplexity over reasoning tokens is notably greater in successful RL compared to base; b) SFT collapses query-sequence diversity more than RL; c) Cross-policy evaluation of retrieval/reasoning decoupling supports the causal role of reasoning in RL improvements.
Diagnostic and Budgetary Insights from PASS@k5
The joint k6 framework enables quantitative statements about marginal value and interaction saturation. Marginal improvement via increasing k7 versus k8 confirms that for compositional tasks, deeper interaction initially gives larger returns, but once a saturation point (k9) is reached, further gains come mostly from increased sampling (T0). This holds for both base and RL—RL raises the overall capability plateau, not the required interaction depth.
Practical and Theoretical Implications
These results demonstrate that, on compositional tool-use tasks, RL with task reward (such as GRPO) outperforms expert-trajectory SFT, which can actively contract the agent's capability boundary in settings where data exposure does not supply sufficient exploratory coverage. The mechanism is not the learning of novel retrieval strategies per se, but the reweighting and selection of reasoning paths that most successfully integrate acquired observations.
Implications include:
- Evaluation: Single-dimensional analysis (e.g., accuracy, pass@T1) fails to disentangle true boundary expansion from efficiency improvement. PASS@T2 provides necessary diagnostic resolution for agentic LLMs.
- Training strategy: For tasks requiring multi-step tool use and compositional reasoning, RL is strongly preferable to SFT, especially under data-matched conditions.
- Reward shaping: Gains accrue in how agents reason over retrieved content, not merely which information is retrieved, emphasizing the design of rewards targeting integration and reasoning.
- Scaling: Results suggest that improvements from RL may be greatest for tasks structurally requiring strategic composition—extrapolation to more complex compositional/agentic environments is warranted.
Conclusion
PASS@T3 exposes that RL can materially expand the agentic capability boundary on compositional tool-use tasks, a qualitative divergence from prior conclusions drawn for static reasoning. The expansion arises via strategic reweighting of the base model's existing trajectories, yielding new problem-solving capabilities not attainable through resampling alone. In contrast, SFT-based expert imitation can fail or regress without adequate demonstration coverage. For future agentic LLM progress, focus should prioritize advanced RL methods and exploration frameworks designed to make deep, compositional environment interaction productive.