- The paper introduces RLIF, a novel framework enabling LLMs to learn reasoning using intrinsic self-certainty feedback rather than external rewards.
- The study demonstrates Intuitor’s comparable performance on in-domain tasks and superior generalization on out-of-domain code generation benchmarks.
- Empirical results show enhanced structured reasoning and scalable training, reducing dependency on human annotations in complex tasks.
Learning to Reason without External Rewards
Introduction
This paper titled "Learning to Reason without External Rewards" explores the limitations of current reinforcement learning (RL) techniques for training LLMs that rely heavily on external rewards. Current methods include Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning with Verifiable Rewards (RLVR), both of which necessitate substantial human involvement or domain-specific supervision. This paper proposes Reinforcement Learning from Internal Feedback (RLIF) as an innovative framework that allows LLMs to learn through intrinsic feedback, thereby negating the need for external rewards or labeled data.
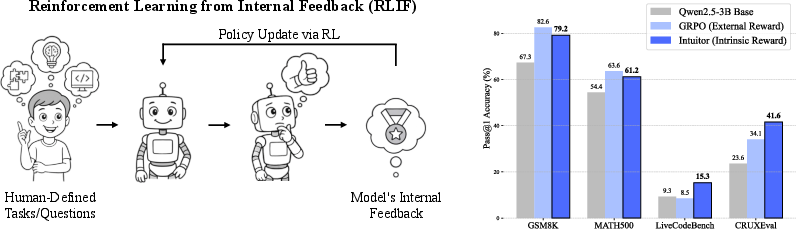
Figure 1: Overview of RLIF and Intuitor's Performance. Left: Illustration of RLIF, a paradigm where LLMs learn from intrinsic signals generated by the model itself, without external supervision. Right: Performance comparison of Qwen2.5-3B Base, GRPO, and Intuitor (our RLIF instantiation). Both GRPO and Intuitor are trained on the MATH dataset. Intuitor achieves comparable performance to GRPO on in-domain mathematical benchmarks (GSM8K, MATH500) and demonstrates better generalization to out-of-domain code generation tasks (LiveCodeBench v6, CRUXEval). Part of the illustration was generated by GPT-4o.
This advance aims to alleviate the challenges of high annotation costs and the need for domain-specific ground truths by proposing Reinforcement Learning from Internal Feedback (RLIF). The new approach leverages intrinsic model-generated signals, specifically self-certainty--the model's predicted confidence in its outputs--as a source of reward for learning, enabling LLMs to develop reasoning skills in an unsupervised fashion.
Figure 1: Overview of RLIF and Intuitor's Performance. Left: Illustration of RLIF, a paradigm where LLMs learn from intrinsic signals generated by the model itself, without external supervision. Right: Performance comparison of Qwen2.5-3B Base, GRPO, and Intuitor (our RLIF instantiation). Both GRPO and Intuitor are trained on the MATH dataset. Intuitor achieves comparable performance to GRPO on in-domain mathematical benchmarks (GSM8K, MATH500) and demonstrates better generalization to out-of-domain code generation tasks (LiveCodeBench v6, CRUXEval). Part of the illustration was generated by GPT-4o.
Reinforcement Learning from Internal Feedback (RLIF) Paradigm
The investigatory paradigm, RLIF, diverges from traditional reinforcement learning techniques by eschewing external rewards. Instead, it optimizes LLMs for reasoning tasks using intrinsic, self-generated feedback. In the RLIF framework, models refine their internal self-evaluation capabilities, drawing upon metrics like self-certainty to assess the quality of their outputs (Figure 2). This provides an elegant solution to the scalability issues inherent in RLHF and RLVR, as RLIF obviates the need for costly human annotations or domain-specific verifiers.
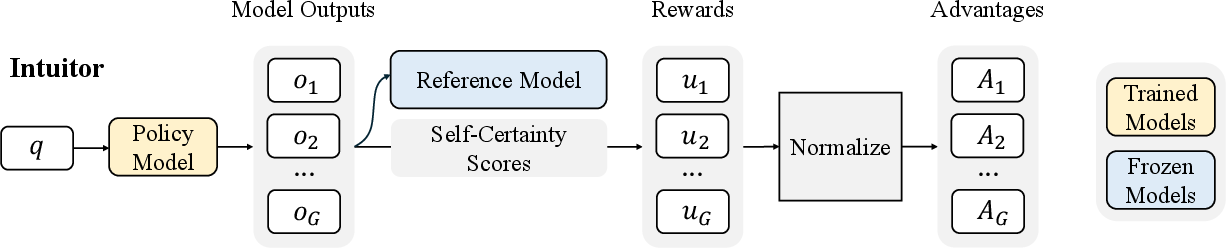
Figure 2: Illustration of Intuitor, highlighting its use of self-certainty as the intrinsic reward.
Intuitor implements RLIF with self-certainty as an intrinsic reward, where self-certainty is defined using the mean KL divergence between the LLM's output distribution and a uniform distribution (Equation \ref{eq:self_certainty}). Higher values indicate greater model confidence in output correctness, guiding the learning process towards paths of increasing certainty (Figure \ref{fig:main}).
Figure 1: Overview of RLIF and Intuitor's Performance. Left: Illustration of RLIF, a paradigm where LLMs learn from intrinsic signals generated by the model itself, without external supervision. Right: Performance comparison of Qwen2.5-3B Base, GRPO, and Intuitor (our RLIF instantiation). Both GRPO and Intuitor are trained on the MATH dataset. Intuitor achieves comparable performance to GRPO on in-domain mathematical benchmarks (GSM8K, MATH500) and demonstrates better generalization to out-of-domain code generation tasks (LiveCodeBench v6, CRUXEval). Part of the illustration was generated by GPT-4o.
Superior Generalization and Structured Reasoning
The experiments conducted provide crucial insight into the effectiveness of Intuitor. The framework was evaluated on the MATH dataset using Qwen2.5-3B base and demonstrated a 65% relative improvement on the LiveCodeBench code generation task compared to GRPO’s lack of improvement. On CRUXEval-O, Intuitor achieved a 76% gain compared to GRPO's 44%.
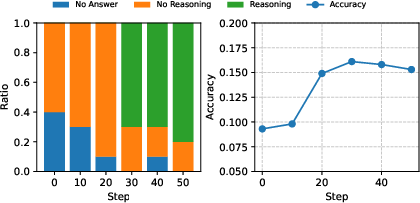
Figure 3: (a) Left: Distribution of answer types for ten random LiveCodeBench questions across training steps. Right: Corresponding model accuracy. The model first learns to generate correct code, then adds reasoning to improve understanding. (b) Training with Intuitor on code corpora leads to spontaneous reasoning before coding and explanation of outputs.
As shown in Figure 3, Intuitor models trained on MATH data exhibited emergent structured reasoning in code generation tasks. Training with Intuitor on code corpora induces spontaneous reasoning before coding and explanation of outputs. These empirical results suggest that, while matching GRPO’s performance on inâdomain tasks, Intuitorâs intrinsic self-certainty metric positively influences generalization to out-of-domain tasks. Moreover, Intuitor unexpectedly enhances structured reasoning and instruction-following abilities. Despite providing no outcome-based or human-derived rewards, Intuitor guided models in generating detailed, coherent solutions to complex tasks. The results suggest that LLMs can leverage their latent understanding to create self-explanatory responses.
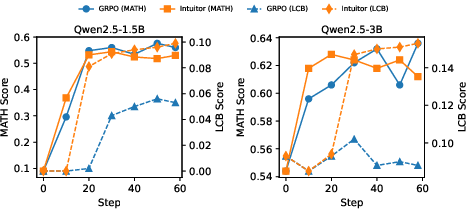
Figure 4: Performance evolution on MATH500 (in-domain) and LiveCodeBench (transfer) for models trained on MATH. In-domain (MATH500) accuracy improves rapidly early in training, preceding gains in code-generation (LiveCodeBench) accuracy. LiveCodeBench performance continues to rise even after MATH500 accuracy plateaus.
Implications for Model Training: The proposed RLIF framework, exemplified by Intuitor, presents a promising, fully unsupervised alternative to RLHF and RLVR, with implications for autonomous AI systems. By eliminating the need for both human and verifiable external rewards, Intuitor offers a scalable solution for tasks resistant to conventional RL training paradigms.
$\text{Performance}_{output} =
\begin{cases}
\text{Increases sharply during training} & \text{For Intuitor on small tasks}\
\text{if} & \text{no external supervision exists}
\}
\begin{array}{llcl}
u_{i,t}(o|q):= & \dfrac{\log\bigg(\pi_\theta(o_i|q)\bigg)}{\mathrm{KL}[\pi_\theta(o|q) \parallel U(o)]}\
R(q,o) & = \alpha\mathbb{I}\{v(q,o) = 1\}
\end{align}$.
Intuitor provides a scalable foundation for harnessing LMs' self-generated behaviors toward domainâgeneral reasoning.
Figure 2: Illustration of Intuitor, which simplifies the training strategy by leveraging self-certainty (the model's own confidence) as an intrinsic reward.
\section{Practical Deployment Considerations}
Given these results, various pathways exist for implementing Intuitor in production systems:
- Plug-and-Play across Tasks: The model's ability to learn and generalize across domains without external rewards makes it particularly suited for diverse applications, from mathematical reasoning to instruction-following and beyond. Minimal task-specific engineering is required, as evidenced by Intuitorâs gains across LiveCodeBench, CRUXEvalâO, AlpacaEval and other benchmarks.
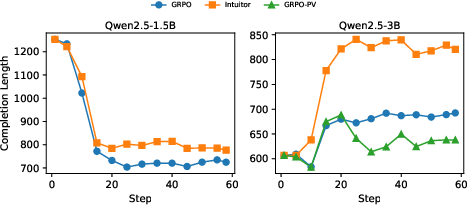
Figure 5: Average response lengths during training rollouts. For Qwen2.5-1.5B, Intuitor and GRPO reduce gibberish outputs. For Qwen2.5-3B, Intuitor and GRPO increase reasoning length; Intuitor yields significantly longer responses. GRPO-PV shows minimal length increases.
- Mitigating Reward Hacking in Self-assessed Models: One consideration when deploying autonomous agents that learn from internal feedback is reward hacking or assigning increased self-certainty to low-quality outputs early in training, only to perform degenerately later. This can be mitigated by alternating static self-reward and online self-reward estimation to ensure stability.
- Online Calibration: In practice, static self-certainty estimates (such as from pre-trained models) may need recalibration over time. Periodic updates with online self-certainty serve to correct this drift, realizing steady improvements without regressing into reward element exploitation modes.
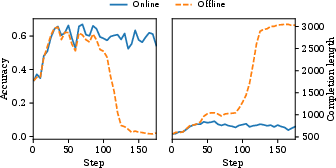
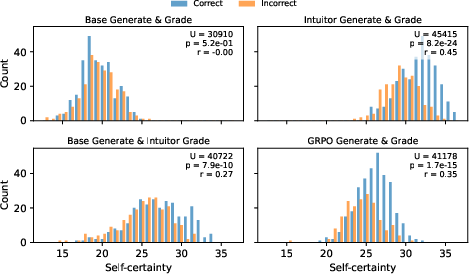
Figure 6: (a) Left: Offline self-certainty model is exploited early in training (around 100 steps), leading to increased response length and decreased accuracy. The online annotator maintains stable training. Right: Distribution of self-certainty on MATH500 responses, for policies trained with GRPO and Intuitor. Histograms are split by response correctness. The inset shows MannâWhitney U test statistics (p-value and effect size r) comparing self-certainty of correct versus incorrect responses.
In conclusion, this research establishes the ability of LLMs to drive their reasoning improvement using intrinsic feedback, paving the way for scalable, broadly applicable techniques like RLIF that significantly reduce dependency on human annotation or external verification. Intuitor, as a specific realization of RLIF, introduces promising capabilities for facilitation of structured reasoning across various domains using self-certainty rewards alone. This general-purpose reinforcement learning paradigm represents a powerful contribution to the field and opens up new avenues for autonomous LLM development. Future work will continue exploring the integration of intrinsic and extrinsic feedback, alongside optimization of large, diverse datasets and model architectures.