- The paper introduces DAHS, which synthesizes hints aligned with student-style responses to correct teacher-student distribution mismatches.
- It details BHA, employing adaptive hint dropout and length-bucketed annealing to maintain training signals and balance scaffold exposure.
- Experimental results on AIME benchmarks demonstrate improved pass@1 and pass@2048 metrics, indicating enhanced solution coverage with lower computational overhead.
Mitigating Distribution Sharpening in Math RLVR via Distribution-Aligned Hint Synthesis and Backward Hint Annealing
Problem Statement and Motivation
Reinforcement Learning with Verifiable Rewards (RLVR) has become a dominant approach for improving LLM-based mathematical reasoning. However, a persistent failure mode emerges: under group-relative policy updates, challenging problems fail to provide informative updates for extended periods, yielding training dynamics where easier questions dominate, and effective trajectory support narrows. This phenomenon, termed "distribution sharpening", leads to improved pass@1 but does not translate to broader solution coverage under large-k evaluation regimes.
Existing hint-based methods scaffold learning on hard questions by providing teacher prefixes, yet current implementations inadequately address two central issues:
- Teacher-student distribution mismatch: Teacher hints may introduce unnatural continuation contexts for the student, especially when model architectures diverge.
- Hint exposure versus evaluation distribution: Training with hints results in a distributional gap relative to no-hint evaluation, risking over-reliance on scaffolding.
DAHS and BHA: Framework Overview
To counter the above, the paper introduces two key components:
- Distribution-Aligned Hint Synthesis (DAHS): Verified teacher hints are synthesized by conditioning the teacher on student-style responses, aligning the hint distribution to the student’s trajectory space.
- Backward Hint Annealing (BHA): Hint exposure is annealed across length-bucketed difficulty bands, with per-question hint dropout preserving no-hint updates throughout RL training and gradually transitioning the policy towards the evaluation distribution.
The full framework operates as shown in (Figure 1):
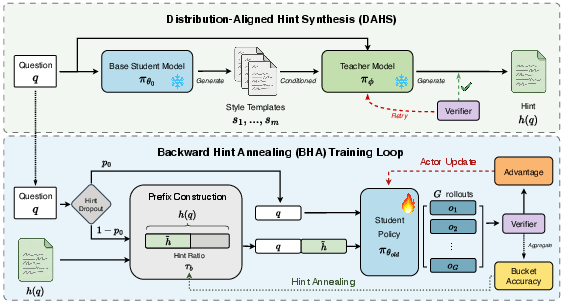
Figure 1: DAHS produces hints aligned to student-style continuations, while BHA applies length-bucketed annealing and per-question hint dropout during RL training.
Technical Contributions and Methodology
DAHS constructs a single verified teacher hint per question, using student outputs as templates to ensure contextual alignment. The teacher solution is retained only if verified correct, avoiding low-probability regions under the student policy. Empirical analysis confirms DAHS outperforms non-aligned and pre-hint CoT approaches in log-probability alignment (Figure 2):
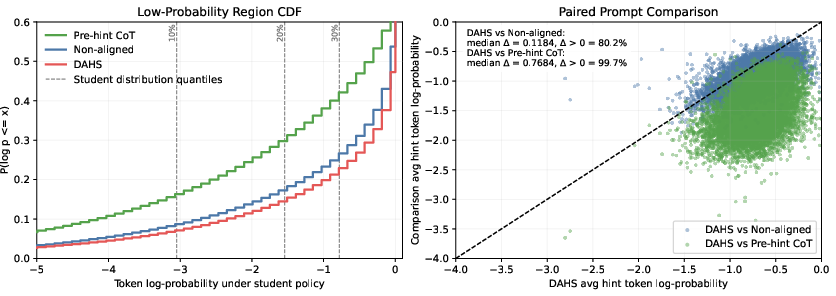
Figure 2: Student-policy log-probabilities for various hint sources demonstrate superior DAHS alignment versus non-aligned or raw teacher CoT hints.
BHA solves the challenge of transferring from hint-augmented training to no-hint evaluation. Hint prefixes are constructed from the full teacher hint and truncated per length bucket by an annealed ratio τb, which is adaptively decreased as bucket-level accuracy thresholds are met. Per-question hint dropout is applied, facilitating continual no-hint updates and enabling Go-Explore–like accumulation of policy-discovered correct trajectories.
The training loop employs suffix-only policy updates: only student-generated tokens after the hint prefix are updated, avoiding SFT-style losses and off-policy weighting.
Experimental Evaluation and Ablation Analysis
Comprehensive evaluation on AIME24/25/26 benchmarks, using Qwen3-1.7B-Base and Llama-3.2-1B-Instruct, is performed under the DAPO-Math-17k dataset. DAHS+BHA consistently improves both pass@1 and pass@2048 metrics relative to DAPO, with the most pronounced gains for Qwen3-1.7B-Base (Figure 3):
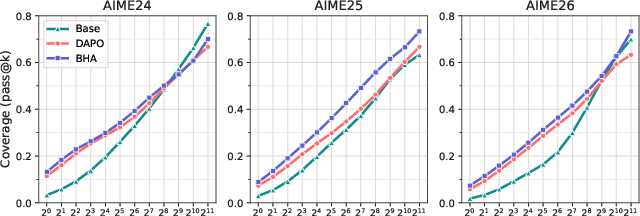
Figure 3: Pass@k curves for Qwen3-1.7B-Base, showing substantial DAHS+BHA gains across all k.
BHA's length-bucketed annealing avoids premature removal of hint scaffolds for harder questions, preserving training signals (Figure 4):
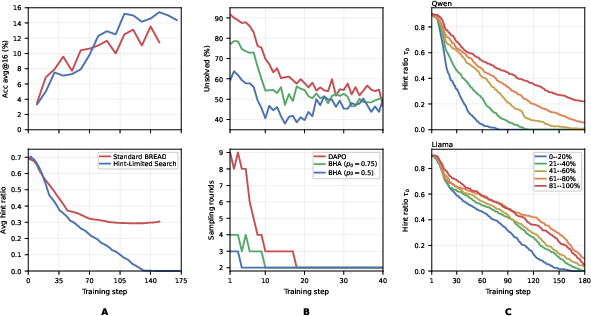
Figure 4: Panel C demonstrates BHA bucketed hint-ratio annealing pacing per question length, while Panel A shows improved transfer at no-hint evaluation.
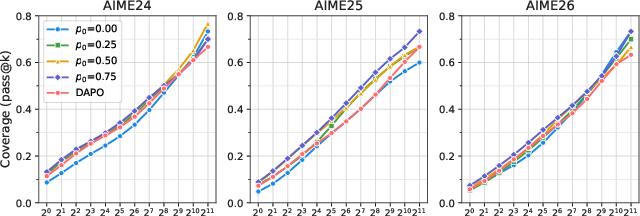
Ablation studies confirm:
On Llama-3.2-1B-Instruct, gains are concentrated in the large-k regime (Figure 6), corroborating effectiveness under smaller model capacity.
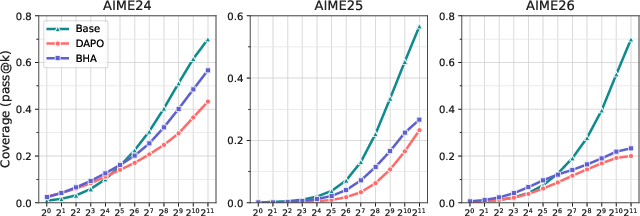
Figure 6: Pass@k curves for Llama-3.2-1B-Instruct demonstrating improved coverage primarily at high k (large sampling budgets).
Related Work Contextualization
The work sits within a growing literature on RLVR and hint-scaffolding in LLMs, extending prior frameworks like BREAD and SCAF-GRPO. By focusing on suffix-only guidance, DAHS+BHA avoids pitfalls of distribution mismatch and over-dependence on teacher hints. The length-bucketed annealing draws explicit inspiration from curriculum learning and backward algorithm methodologies, merging automated context alignment and gradual reduction of scaffolds.
The empirical results directly align with analyses of distribution sharpening, reinforcing the principle that low-k gains alone cannot guarantee broad solution coverage [yue2025does, he2025rewarding]. The explicit policy-level alignment and backward hint annealing offered here provide a practical pathway to maintaining exploration diversity and effective RLVR learning signals.
Implications and Future Directions
Practically, the DAHS+BHA recipe yields reliably improved mathematical reasoning in base LLMs and scalable RLVR pipelines, without the computational overhead of per-prompt search. Theoretically, it demonstrates that aligned context design and scaffold reduction are joint necessary conditions for high-coverage RLVR optimization. The framework supports broader solution coverage and restores learnability on previously hard, untrainable questions.
Potential future developments include extending DAHS+BHA to larger models and additional domains, integrating more sophisticated alignment measures, and further automating the curriculum by dynamic difficulty estimation. The promise of RLVR training that maintains diversity and adaptability across training and evaluation distributions is likely to stimulate additional research into exploration and scaffold management in scalable RL systems.
Conclusion
The paper rigorously addresses a concrete failure mode in math RLVR—distribution sharpening and stalling on hard questions—by introducing Distribution-Aligned Hint Synthesis and Backward Hint Annealing. The combined approach improves solution coverage throughout the sampling regime, with ablation analyses confirming the necessity of distribution alignment, the practical utility of length-bucketed schedules, and the value of per-question hint dropout. These findings establish DAHS+BHA as an effective strategy for countering distribution sharpening and restoring learning signals on challenging mathematical reasoning tasks.