MemExplorer: Navigating the Heterogeneous Memory Design Space for Agentic Inference NPUs
Abstract: Emerging agentic LLM workloads are driving rapidly growing demand on both memory capacity and bandwidth, with different phases of inference (e.g., prefill and decode) imposing distinct requirements. Industry is responding by composing heterogeneous accelerators into single interconnected systems, as exemplified by NVIDIA's Vera Rubin platform, where each device brings its own memory architecture. This heterogeneity is further compounded by a widening landscape of available memory technologies: high-density on-chip SRAM, HBM, LPDDR, GDDR, and emerging options such as high-bandwidth flash (HBF), each offering different capacity, bandwidth, and power trade-offs. Identifying the right memory architecture for next-generation inference accelerators requires navigating a vast and rapidly evolving design space, in which the interplay between workload characteristics, NPU design dimensions, and memory system design remains largely underexplored. To address this challenge, we present MemExplorer, a new memory system synthesizer for heterogeneous NPU systems. MemExplorer provides a unified abstraction for modeling diverse memory technologies across different hierarchy levels (e.g., on-chip and off-chip) and automatically determines an efficient heterogeneous memory system together with NPU design choices (e.g., matrix engine size) to balance throughput and power between prefilling and decoding devices in a multi-device NPU system. Experimental results show that, under the same power budget for agentic workloads, MemExplorer achieves up to 2.3x higher energy efficiency than the baseline NPU and 3.23x higher than H100 in the prefill-only setting. Under equivalent performance targets in the decode setting, it further delivers up to 1.93x and 2.72x higher power efficiency over the baseline NPU and H100, respectively.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “MemExplorer: Navigating the Heterogeneous Memory Design Space for Agentic Inference NPUs”
Overview: What is this paper about?
This paper is about making computer chips that run large AI models faster and more energy‑efficient by choosing the right kinds of memory. The authors built a tool called MemExplorer that helps designers mix and match different memory types (some fast and small, some big and slower) across different devices so AI systems can handle “agentic” tasks—like web browsing, using apps, or writing code—better.
Think of it like organizing a kitchen: you keep a few ingredients on the counter for quick use (fast, small memory), store lots more in the pantry (bigger, slower memory), and maybe add a deep freezer (huge but slower still). MemExplorer helps decide the best setup for your “kitchen” so cooking (AI inference) is speedy and efficient.
Key Questions the Paper Tries to Answer
- How do we design the memory system for AI chips to handle new “agent” workloads that use very long contexts and unpredictable behavior?
- Can different devices specialize in different parts of the job (one device optimized for “prefill,” another for “decode”) and work better together?
- What mix of memory types (like fast on‑chip SRAM, HBM, LPDDR/GDDR, or new high‑bandwidth flash) gives the best balance of speed and energy use?
- Can we automatically search this huge design space to find the best chip and memory setup?
Methods: How did they study it?
The authors built MemExplorer, a tool that models how different memory choices affect performance and power. Here’s what it does, in everyday terms:
- It models different memory types using a simple, unified set of properties:
- How fast they are (latency and bandwidth)
- How big they are (capacity)
- How much power they use
- It understands the two main phases of running a LLM:
- Prefill: reading a long input (like a long document). This needs lots of speed (bandwidth) to keep the chip fed with data.
- Decode: generating output one token at a time. This needs lots of space (capacity) to hold growing “memory” called the KV cache.
- It lets designers test different setups for:
- The compute unit (the AI “engine”)
- On‑chip memory (very fast but small)
- Off‑chip memory (bigger but slower), including new options like 3D‑stacked SRAM and high‑bandwidth flash (HBF)
- Software choices (how data is moved and stored)
- It uses a “smart search” method (multi‑objective Bayesian optimization) to quickly find the best designs that balance speed and energy use.
- It checks the math models against a detailed emulator (a kind of simulator) to make sure the predictions are accurate.
Simple analogy: MemExplorer tries many kitchen layouts and cooking routines, measures how fast and efficient each is, and then recommends the best ones.
Main Findings: What did they discover?
- Prefill and decode have very different needs:
- Prefill loves very fast, on‑chip memory with huge bandwidth—especially 3D‑stacked SRAM—so the compute engine never waits.
- Decode runs better when there’s lots of memory capacity so it can keep bigger batches and reuse more cached information (KV cache). Here, big but slower memory helps (e.g., HBM, LPDDR, or even high‑bandwidth flash as an outer tier).
- A single “one‑size‑fits‑all” chip struggles to be great at both phases. A better approach is a heterogeneous system where:
- One device is tuned for prefill (fast memory, high bandwidth).
- Another device is tuned for decode (large memory capacity).
- Using MemExplorer to co‑design compute, memory, and software strategies:
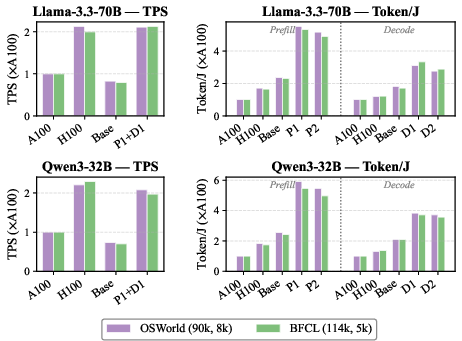
- For prefill: up to 2.3× better energy efficiency than their baseline NPU and up to 3.23× better than NVIDIA H100 in a prefill‑only setup.
- For decode: up to 1.93× (vs baseline NPU) and 2.72× (vs H100) better power efficiency when matching performance.
- Software choices (like how you keep certain data on‑chip and how you prioritize bandwidth) matter a lot—MemExplorer shows that combining the right software scheduling with the right memory hardware makes a big difference.
Why this is important
- Agentic AI (tools that browse, click, write, and reason across long tasks) needs both speed and lots of memory. This work shows how to design systems that handle these demands without wasting energy.
- It gives chip designers a way to rapidly explore many new memory technologies and combinations—useful because the memory world is changing fast.
- It supports the industry trend toward mixing different specialized devices (for example, one optimized for throughput, another for low latency) in a single system.
Implications: What could this change in the real world?
- Faster, cheaper, and more energy‑efficient AI assistants and agents that can handle very long contexts (like long documents or complex web tasks).
- Better guidance for building next‑generation AI hardware—helping companies decide when to use fast on‑chip memory, when to add larger off‑chip memory tiers, and how to split work across devices.
- Future‑proof design: as new memory types appear, MemExplorer can quickly evaluate them, speeding up innovation.
In short, the paper shows how to smartly “mix and match” memory and compute for AI chips so modern, long‑context AI tasks run faster and use less power—by letting different devices specialize and by carefully coordinating how data moves through the memory “kitchen.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research.
- Lack of silicon-level validation: results are based on analytical models and an emulator (extended PLENA) rather than measurements on real heterogeneous NPUs with the proposed memory stacks (3D-stacked SRAM, HBF), leaving the real-world feasibility and gains unverified.
- Limited validation scope: no quantitative reporting of model-to-emulator error across diverse workloads and configurations; robustness of the analytic model under varying batch sizes, sequence lengths, and dataflows remains unquantified.
- Simplified memory-traffic model: assumes bulk, contiguous transfers and omits queueing, bank conflicts, row-buffer locality, channel arbitration, protocol overheads, and controller scheduling—factors that can significantly affect LPDDR/GDDR/HBM behavior under decode access patterns.
- Idealized double-buffering overlap: the effective-bandwidth formulation and constant inter-level latency λ_i do not account for backpressure, partial overlap, DMA setup costs, burst granularity, or inter-tier contention in real memory controllers.
- PHY/link power and protocol overheads: power model aggregates per-bit energies and background power but does not explicitly account for SerDes/PHY energy, training, refresh, command overhead, or link-layer efficiency differences across memory types.
- Thermal constraints are unmodeled: no co-thermal analysis of 3D-stacked SRAM (power density, layer count limits, throttling) and dense HBM/HBF configurations (package temperature, hotspot coupling with compute).
- 3D-stacked SRAM assumptions: capacity, bandwidth, and per-bit energy figures are not stress-tested against vertical interconnect parasitics, layer-to-layer latency penalties, leakage scaling, yield/cost, and potential reliability impacts; no exploration of the maximum thermally viable layer count beyond the arbitrary cap in the design space.
- HBF integration uncertainties: NAND endurance, write amplification, garbage collection (GC), latency spikes, QoS variability, and ECC/FTL overhead are not modeled—critical for decode, where KV updates generate frequent writes and reads.
- HBF DRAM-buffer policy: the size, placement, and management policy of the HBF-attached DRAM buffer (prefetching, caching, write coalescing) are not parameterized, yet these determine whether microsecond-scale flash latency can be effectively hidden.
- Device-attach feasibility of HBF: treating HBF as a die-shoreline attached memory akin to HBM ignores current packaging constraints; comparative analysis against host-attached/CXL-attached HBF-like devices is missing.
- Shoreline/reticle limits are oversimplified: the stack-count constraint does not consider interposer routing, I/O pitch, signal integrity, power delivery, TSV/via density, package stack-up, or cooling hardware footprint—all of which limit attachable memory counts.
- Inter-device disaggregation overheads: the framework does not model interconnects between prefill and decode devices (NVLink/PCIe/CXL/Ethernet)—latency, bandwidth, serialization/deserialization costs, and synchronization overhead that can dominate in multi-device serving.
- Data movement across devices: mechanisms and costs for sharing or relocating KV-cache/weights between prefill and decode accelerators are not specified (e.g., duplication vs migration, consistency, prefetch timing), leaving the system-level serving latency incomplete.
- Concurrency and multi-tenancy: no modeling of concurrent sessions, admission control, memory oversubscription, preemptions, or isolation/fairness—which are vital for real agent serving and can drastically affect bandwidth and capacity utilization.
- Runtime adaptivity is missing: bandwidth allocation (fixed 75/25), dataflow, and storage priorities are static; no evaluation of runtime controllers that adapt to observed traffic, contention, or token-level dynamics.
- Software kernel realism: kernels are abstracted to WS/IS/OS dataflows; fused operator pipelines (e.g., FlashAttention variants), paged attention, asynchronous prefetching, and kernel-specific memory access patterns are not integrated into the model.
- Workload generality: evaluation is anchored on two token-length configurations and a few models; variability across agentic traces (tool-calls, branching, retries), other model families (Mixture-of-Experts, state-space models), and multimodal agents (image/video) is not characterized.
- End-to-end serving pipeline: prefill-only and decode-only analyses do not evaluate complete pipelines where both phases overlap, including queueing, batching policies, KV-eviction strategies, and stage-level load balancing across heterogeneous devices.
- Quantization–memory co-optimization underexplored: after selecting 8/8/8 precision, the work does not explore per-stage/per-tensor mixed precision, KV compression schemes, or how precision choices interact with bandwidth/capacity tiers and accuracy on agentic tasks.
- Power model process/tech sensitivity: compute power is derived from 7 nm synthesis; scaling trends to 5/4/3 nm, voltage margins, DVFS, power gating, and technology-correlated memory-IO energy are not captured, limiting predictive accuracy for near-future nodes.
- Packaging and cooling power: total system power excludes cooling/fan/pump and interposer/package losses; absence of a TDP-to-cooling mapping risks overestimating deployable configurations.
- Cost and yield not considered: no analysis of /GB, or yield impacts of advanced packaging (3D SRAM, HBM4, HBF), which are central to practical design selection in heterogeneous systems.
- Memory reliability and ECC overheads: additional storage and bandwidth costs for ECC/SECDED, scrubbing, refresh-resiliency, and error handling (especially for flash-based tiers) are not budgeted.
- Decode latency tails: throughput is evaluated; per-token latency distribution and tail behavior—critical for user-perceived latency—are not modeled for different memory hierarchies.
- Extreme long-context regimes: beyond illustrative 90–114K prompts, scenarios at 1M+ context with KV-cache >500 GB are asserted but not stress-tested for migration/eviction strategies, tiering policies, or HBF saturation limits.
- Alternative and future memories: other emerging options (e.g., CXL memory pools, MRAM, HBM-PIM, NVRAM DIMMs, on-package GDDR, HBM-Next) are excluded; the framework’s extensibility is stated but not demonstrated for these technologies.
- Controller microarchitecture: requirements for a controller that orchestrates multi-tier movement (credits, QoS, arbitration) and supports the proposed policies are not specified or evaluated for area/power/timing.
- Sensitivity of MOBO: the Bayesian optimization setup (100 evaluations, GP assumptions) lacks ablation on seed sensitivity, acquisition function choices, constraint handling, and scalability to larger design spaces.
- Fairness of GPU baselines: comparison methodology (software stack, kernels, quantization levels, cache policies) could bias results; explicit normalization for compiler/runtime maturity and optimized kernels is missing.
- Dataset/benchmarks breadth: impact of agent-task diversity (web agents, coding agents, CUAs) on capacity vs bandwidth balance is not statistically profiled; only two task settings are used for token traces.
- Deployment pathway: how MemExplorer’s recommended configurations translate into hardware–software co-design deliverables (compiler/runtime policies, memory-controller settings, device partitioning) is not articulated.
These gaps point to concrete next steps: integrate detailed memory-controller and interconnect models; perform co-thermal–power analysis; prototype small-scale 3D-SRAM+DRAM/HBF subsystems; incorporate realistic kernels and runtime adaptivity; broaden agentic workload characterization; and include system-level costs, reliability, and deployment considerations.
Practical Applications
Overview
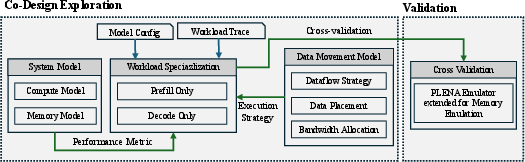
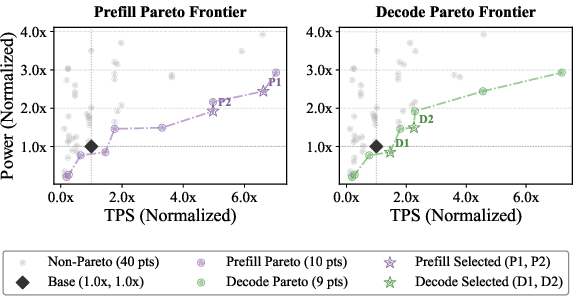
MemExplorer is a co-design framework that jointly explores heterogeneous memory hierarchies, NPU compute architectures, and software strategies (dataflow, storage placement, bandwidth allocation, quantization) for LLM inference—especially for agentic, long-context workloads. It models and synthesizes systems spanning on-chip SRAM (including 3D-stacked), HBM/LPDDR/GDDR, and emerging High Bandwidth Flash (HBF), and uses multi-objective Bayesian optimization to identify Pareto-efficient designs for prefill and decode phases (including disaggregated, multi-device setups). Reported improvements include up to 2.3×–3.23× energy efficiency for prefill and 1.93×–2.72× for decode over strong baselines.
Below are practical applications across industry, academia, policy, and daily life, grouped by deployment horizon.
Immediate Applications
These can be piloted or deployed today using the MemExplorer methodology and existing components.
- Industry (Cloud/AI Infrastructure): Pre- vs. decode device split for agentic LLM serving
- What: Adopt a heterogeneous serving workflow where high-throughput prefill runs on bandwidth-focused devices (e.g., HBM-rich GPUs or SRAM-heavy accelerators) and decode runs on capacity-focused devices (e.g., accelerators with larger off-chip memory or HBF tiers).
- Tools/workflows: Extend current orchestrators (e.g., vLLM, Triton, Ray Serve) to route requests by stage; implement KV-cache placement and streaming policies aligned to MemExplorer’s on-chip storage priority and off-chip bandwidth allocation.
- Sectors: Software/Cloud, Data Center AI, Enterprise IT.
- Assumptions/dependencies: Sufficient interconnect bandwidth/latency between disaggregated devices; availability of devices with distinct memory profiles; software support for stage-aware routing and KV sharing.
- Semiconductor Vendors/NPU Teams: Rapid architecture SKU planning
- What: Use MemExplorer’s co-design to create two near-term product variants:
- Prefill-optimized SKU: smaller compute die + 3D-stacked/on-die SRAM emphasis and high off-chip bandwidth (HBM4).
- Decode-optimized SKU: moderate bandwidth + greater capacity (e.g., more HBM stacks or hybrid capacity tiers such as LPDDR/GDDR and early HBF pilot).
- Tools/workflows: Integrate MemExplorer in early-stage architecture exploration; product definition based on Pareto frontiers (token/J, token/s, , latency budgets per stage).
- Sectors: Cloud, Finance/Enterprise IT, Ops/FinOps.
- Assumptions/dependencies: Workload traces representative of production; accurate memory energy parameters; stable model architectures.
- Academic Research and Coursework
- What: Employ MemExplorer to study trade-offs across emerging memories (HBM4, LPDDR6, GDDR7, HBF, 3D-stacked SRAM), validate analytical/transaction-level models, and teach heterogeneous memory design for AI.
- Tools/workflows: Extended PLENA emulator, GP+EHVI DSE scripts, reproducible memory parameter sets.
- Sectors: Academia (Computer Architecture, Systems, ML Systems).
- Assumptions/dependencies: Access to emulators and parameterized models; open-source or license-friendly tooling.
- ESG/Energy Reporting and Optimization
- What: Adopt token/J and dominated hypervolume-based evaluation to report and optimize energy efficiency for AI inference fleets, aligning with internal sustainability targets.
- Tools/workflows: Integrate MemExplorer metrics into dashboards; scenario test different device mixes and quantization schemes.
- Sectors: Cloud/Data Centers, Enterprise Sustainability.
- Assumptions/dependencies: Organizational buy-in; instrumentation to collect energy and throughput data.
Long-Term Applications
These require additional R&D, scaling, standardization, or ecosystem changes.
- Productized heterogeneous inference platforms
- What: Commercialize systems with specialized “prefill chips” (compute + large 3D-stacked SRAM + HBM4) and “decode chips” (capacity-optimized with HBM stacks and/or HBF) connected over high-speed interconnects; akin to the trends exemplified by NVIDIA’s Vera Rubin + specialized LPX devices.
- Tools/products: Appliance-class boards and racks; standardized APIs for stage-aware serving; hardware/software codesign kits.
- Sectors: Semiconductor, Cloud OEMs, Systems Integrators.
- Assumptions/dependencies: Mature 3D SRAM manufacturing and cooling; production-grade HBF with predictable endurance and latency; robust interconnects and software orchestration.
- Standardized high-capacity, near-memory tiers (HBF-class)
- What: Define interfaces and controller IP for on-package or near-package HBF as a streaming capacity tier for KV-cache overflow and long-context weights.
- Tools/products: HBF controllers, PHYs, firmware; JEDEC-like standards and vendor interoperability.
- Sectors: Semiconductors, Memory Vendors, Standards Bodies.
- Assumptions/dependencies: Endurance, latency, and power characteristics acceptable for inference; cost per GB competitive vs. DRAM; coherent integration with existing memory controllers.
- Adaptive runtime that dynamically migrates tensors across tiers and devices
- What: Build runtimes that reposition weights/activations/KV cache dynamically across on-chip SRAM, HBM, LPDDR/GDDR, and HBF based on instantaneous bandwidth/capacity pressure and stage (prefill/decode).
- Tools/workflows: Online DSE via GP+EHVI, telemetry-driven policies, prefetching and double-buffering informed by MemExplorer’s model.
- Sectors: AI Systems Software, Cloud.
- Assumptions/dependencies: Fine-grained monitoring; low-overhead migration; predictable access patterns or robust predictors.
- Cluster-level schedulers for heterogeneous fleets
- What: Extend cluster orchestration (Kubernetes, SLURM, Ray) to be memory-stage-aware—assigning prefill-heavy jobs to bandwidth-rich nodes and decode-heavy to capacity-rich nodes; co-scheduling to maximize token/J.
- Tools/workflows: Admission control with memory/throughput SLAs; phase-aware autoscaling; multi-tenant isolation compatible with disaggregated memory.
- Sectors: Cloud, Enterprise IT.
- Assumptions/dependencies: Accurate phase segmentation and telemetry; device-agnostic APIs for KV sharing; network QoS and predictable latencies.
- EDA and silicon design flows with “memory-system synthesizer” in the loop
- What: Integrate MemExplorer-like synthesizers into standard EDA flows to auto-generate memory hierarchies and outline die-edge budgets (shoreline) for different product targets.
- Tools/workflows: Parameterized macro generators (3D SRAM, HBM PHYs), thermal-aware floorplanning, automated Pareto reporting.
- Sectors: EDA, Semiconductors.
- Assumptions/dependencies: IP availability (TSVs, hybrid bonding), accurate thermal/power co-simulation models.
- Sector-specific accelerators tailored to long-context agents
- What: Build domain accelerators with memory hierarchies tuned for:
- Healthcare: EHR summarization with very long context; privacy-preserving on-prem devices using capacity-rich tiers.
- Finance/Legal: Multi-document retrieval and analysis; archive-scale KV management.
- Education: Personalized tutoring with multi-session memory.
- Tools/products: Verticalized SKUs, secured KV-cache policies, governance tooling (logging, audit).
- Sectors: Healthcare, Finance, Education.
- Assumptions/dependencies: Compliance (HIPAA, GDPR); secure memory management; workload stability and clear accuracy targets for quantization.
- Robotics and embedded agentic assistants
- What: Leverage maturing 3D-stacked SRAM and efficient LPDDR6/GDDR7 to enable on-device agents with large working memory for long-horizon tasks (e.g., household robots, field service bots).
- Tools/products: Low-power NPUs with compact on-chip capacity and tiered off-chip memory; streaming-friendly planners.
- Sectors: Robotics, Embedded Systems.
- Assumptions/dependencies: Power/thermal constraints; form-factor-driven shoreline limits; robustness to real-time latency spikes.
- Policy and standards for heterogeneous AI accelerators
- What: Establish guidance and benchmarks that reflect stage-aware efficiency (token/J by prefill vs decode), and support heterogeneous procurement (mixing bandwidth- and capacity-optimized devices).
- Tools/workflows: Public benchmark suites for agentic workloads; reporting standards (e.g., stage-stratified energy and cost metrics).
- Sectors: Government/Regulators, Industry Consortia.
- Assumptions/dependencies: Industry consensus on metrics; disclosure of device-level energy profiles; evolving model behaviors (KV patterns) captured by benchmarks.
- Consumer-facing improvements in agentic apps
- What: Cheaper, faster, and more reliable agentic assistants (web-use agents, office automation, coding copilots) due to reduced serving cost and latency from memory-optimized infrastructures.
- Products: Productivity suites with long-context reasoning; tool-using agents with reduced “context overflow” failures.
- Sectors: Consumer Software, Enterprise SaaS.
- Assumptions/dependencies: Backend adoption of heterogeneous serving; stability of long-context agentic interaction patterns; privacy/security controls for large KV caches.
Cross-cutting assumptions and dependencies
- Technology readiness: Availability and maturity of 3D-stacked SRAM (including thermal solutions) and HBF with predictable latency/power/endurance.
- Packaging/physical limits: Die shoreline constraints and reticle limits bound stack counts and interface placement.
- Interconnects: High-bandwidth, low-latency links between disaggregated devices are needed for stage split.
- Workload validity: Agentic workloads with long contexts remain prevalent; token-length distributions and KV-cache behavior match planning assumptions.
- Software stack: Compiler/runtime hooks to implement dataflow/storage/bandwidth strategies; serving frameworks that support stage-aware routing and KV management.
- Accuracy: Quantization strategies must preserve task performance for target models and datasets.
Glossary
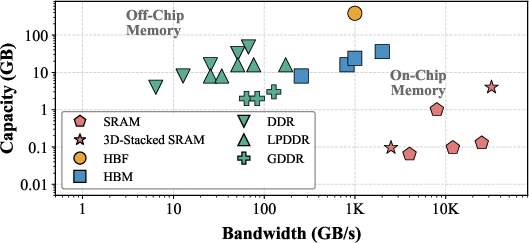
- 3D-Stacked on-chip SRAM: A vertically integrated SRAM where multiple SRAM dies are bonded atop the compute die to greatly increase on-chip capacity and bandwidth at very low latency. "Beyond established devices, two emerging technologies—3D-Stacked on-chip SRAM and High Bandwidth Flash (HBF)."
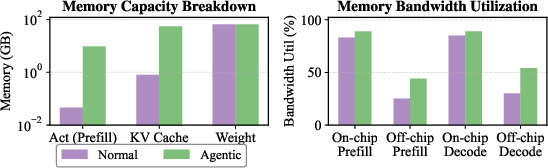
- Agentic workloads: LLM use-cases where the model interacts with tools or environments, producing dynamic, long, and bursty sequences that stress memory capacity and bandwidth. "Agentic workloads significantly increase memory capacity requirements for activations and KV cache."
- Dataflow processor: A processor architecture organized around the flow of data, enabling extremely high on-chip bandwidth for streaming computations. "This hardware employs a dataflow processor with 128 GB of aggregated on-chip SRAM without co-packaged DDR memory, delivering 40 PB/s of aggregated bandwidth."
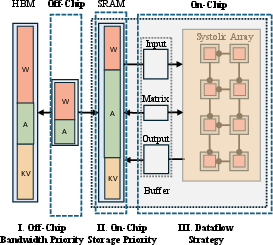
- Dataflow strategy: The policy determining which tensor (weights, inputs, outputs) remains stationary on-chip to maximize reuse and minimize memory traffic. "This strategy determines how weights, inputs, and outputs are accessed during computation (e.g., weight-stationary, input-stationary, or output-stationary)"
- Decode stage: The inference phase that generates new tokens incrementally and is often latency- and KV-cache–dominated. "the decode stage typically generates only a small number of tokens compared to prefilling yet contributes significantly to the end-to-end latency."
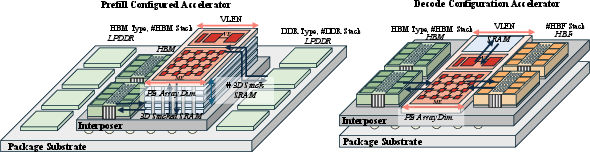
- Die shoreline: The physical perimeter of a compute die used to attach off-chip memory and I/O PHYs, limiting the number of memory stacks that can be placed. "connected through high-speed PHY interfaces, collectively referred to as the die shoreline~\cite{shorline}."
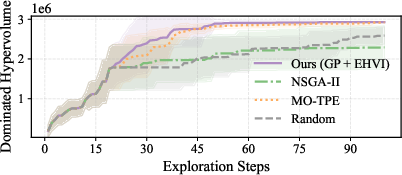
- Dominated hypervolume: A multi-objective optimization metric measuring the volume of objective space dominated by the current Pareto set relative to a reference point. "The dominated hypervolume measures the volume of the objective space dominated by the current Pareto set"
- Double buffering: A technique that overlaps data transfer with computation by alternating between two buffers to hide memory latency. "When level supports double buffering and simultaneously transfers data to level , the effective bandwidth is limited by the remaining available bandwidth of level ."
- Expected Hypervolume Improvement (EHVI): An acquisition function for multi-objective Bayesian optimization that selects new evaluations by maximizing expected gains in dominated hypervolume. "We adopt Expected Hypervolume Improvement (EHVI)~\cite{emmerich2006single,daulton2020differentiable}, as the dominated hypervolume is the only unary indicator that is strictly monotone with respect to Pareto dominance"
- Gaussian Process (GP): A probabilistic, non-parametric model used as a surrogate for expensive objective functions in Bayesian optimization. "We model each objective independently with a Gaussian Process (GP)~\cite{seeger2004gaussian}, a non-parametric probabilistic model that places a distribution over functions."
- GDDR: A high-speed graphics DRAM family used as off-chip memory providing high bandwidth per chip at moderate capacities. "we consider on-chip SRAM and three widely deployed off-chip memory families: GDDR, LPDDR, and HBM."
- GPTQ: A post-training quantization method for LLMs that reduces precision while preserving accuracy. "such as GPTQ~\cite{gptq}, QuaRot~\cite{quarot}, and output-norm guided blockwise clipping~\cite{plena}."
- HBM (High Bandwidth Memory): Stacked DRAM connected via wide interfaces to deliver very high aggregate bandwidth with relatively low latency. "constrained by a single, homogeneous memory architecture (typically HBM)"
- High Bandwidth Flash (HBF): A NAND-flash–based memory tier integrated with DRAM buffers and high-speed PHYs to offer very large capacity and high throughput at microsecond latencies. "emerging options such as high-bandwidth flash (HBF), each offering different capacity, bandwidth, and power trade-offs."
- Hybrid-bonding interconnects: Fine-pitch bonding technology that directly connects stacked dies, enabling dense, low-latency vertical links. "via dense TSV or hybrid-bonding interconnects, multiplying effective capacity per compute-die footprint"
- Input-stationary: A dataflow where input activations remain resident on-chip while weights/outputs stream, to maximize reuse of inputs. "(e.g., weight-stationary, input-stationary, or output-stationary)"
- KV cache: The stored key and value tensors for each processed token used to accelerate attention during decoding, often dominating memory capacity in long contexts. "Agentic workloads significantly increase memory capacity requirements for activations and KV cache."
- LPDDR: A low-power DRAM family (e.g., LPDDR5X/LPDDR6) used off-chip, offering lower bandwidth than HBM but with better energy efficiency and smaller packages. "we consider on-chip SRAM and three widely deployed off-chip memory families: GDDR, LPDDR, and HBM."
- Lithography reticle limit: The maximum exposure field size of a lithography stepper, constraining die dimensions and thus available shoreline for memory attachment. "This constraint is further tightened by the lithography reticle limit: current DUV/EUV steppers impose a maximum die exposure field of approximately "
- Microscaling (MX) data formats: Hardware-friendly numeric formats (e.g., MXFP, MXINT) with shared exponents/scales to enable fine-grained mixed-precision quantization. "the full range of Microscaling (MX) data formats~\cite{plena, darvish2023shared} used across the memory hierarchy."
- MO-TPE: A multi-objective variant of the Tree-structured Parzen Estimator algorithm for black-box optimization. "MO-TPE~\cite{ozaki2020multiobjective}, a multi-objective Tree-structured Parze Estimator implemented via Optuna;"
- Multi-Objective Bayesian Optimization (MOBO): A sample-efficient optimization framework using probabilistic surrogates to find Pareto-optimal designs across multiple objectives. "We therefore employ Multi-Objective Bayesian Optimization (MOBO)~\cite{daulton2020differentiable}, a sample-efficient framework that maintains a probabilistic surrogate model"
- NSGA-II: A popular evolutionary algorithm for multi-objective optimization using non-dominated sorting and crowding distance. "NSGA-II~\cite{deb2002fast}, a population-based evolutionary algorithm using non-dominated sorting and crowding distance;"
- NPU (Neural Processing Unit): A specialized accelerator for neural network workloads with tailored compute and memory hierarchies. "a new memory system synthesizer for heterogeneous NPU systems."
- NVLink: A high-bandwidth, low-latency interconnect used to connect GPUs/accelerators within a node for scale-up communication. "scale-up interconnects (e.g., NVLink), and other I/O."
- Output-stationary: A dataflow where partial sums/outputs remain resident on-chip, reducing writebacks by maximizing output reuse. "(e.g., weight-stationary, input-stationary, or output-stationary)"
- Pareto frontier: The set of designs that cannot be simultaneously improved in all objectives, representing optimal trade-offs. "identify the Pareto frontier for disaggregated serving"
- PLENA: An analytical and emulation framework for modeling and evaluating configurable matrix/vector compute and memory systems for LLM inference. "we integrate the analytical hierarchical memory model (discussed in \Cref{sec:memory_traffic_model}) with the PLENA~\cite{plena} performance analytical model."
- Prefill stage: The inference phase that processes the input context in bulk, typically compute- and bandwidth-intensive with large activation footprints. "During LLM inference, the prefill and decode stages exhibit fundamentally different compute and memory access patterns."
- Sobol quasi-random sequences: Low-discrepancy sequences used to initialize exploration with good coverage of high-dimensional design spaces. "In the initialization phase, $N_{\mathrm{init}$ ( in our experiments) configurations are drawn via Sobol quasi-random sequences to provide broad coverage"
- Systolic array: A spatial compute architecture with data flowing rhythmically through an array of processing elements for high-throughput matrix operations. "such as the systolic array matrix units."
- TSV (Through-Silicon Via): Vertical electrical connections passing through silicon dies to enable dense, low-latency 3D stacking. "via dense TSV or hybrid-bonding interconnects"
- Weight-stationary: A dataflow where weights remain resident on-chip to maximize reuse, reducing off-chip bandwidth for weights. "under weight-stationary execution."
Collections
Sign up for free to add this paper to one or more collections.