- The paper presents a hierarchical roofline analysis that quantifies how HBS bandwidth and latency, alongside DDR scaling, dictate gen-AI inference performance.
- Selective data placement strategies, such as caching QKV in DDR, deliver up to a 3.1× speedup for large multimodal LLMs.
- SRAM-based chiplet buffers yield moderate throughput gains for small models by redirecting QKV traffic to mitigate high-latency DDR bottlenecks.
Technology Solutions Targeting gen-AI Inference Under Memory Constraints
Introduction
Rapid advances in generative AI have accentuated the need for efficient, high-throughput inference on resource-constrained platforms, such as edge devices and smartphones. The memory footprint of modern multimodal LLMs, especially for large context windows, introduces critical bottlenecks not only in terms of memory capacity but also bandwidth and latency. This work systematically analyzes two emerging technology solutions—High Bandwidth Storage (HBS) for large models, and SRAM-based chiplet buffers for small models—using a hierarchical roofline-based analytical framework to quantify their implications for gen-AI inference performance (2604.11128).
Analytical Framework for Memory-Bounded Inference
The study utilizes a hierarchical roofline model, extending traditional single-level roofline analysis to account for complex memory hierarchies incorporating emerging components like HBS and chiplets alongside conventional DDR and on-chip SRAM. The framework profiles kernel-level arithmetic intensity and traffic, especially focusing on GEMM-heavy operators that dominate the inference phase of Transformer-based models. Sequential dependencies, tiling strategies, and the data residency (e.g., QKV, weights, activations) at various hierarchy levels are explicitly modeled. The framework captures shifts in the memory- or compute-boundedness regime as a function of model size, context length, and hardware configuration.
High Bandwidth Storage (HBS) for Large Models
HBS Bandwidth-Latency Tradeoffs
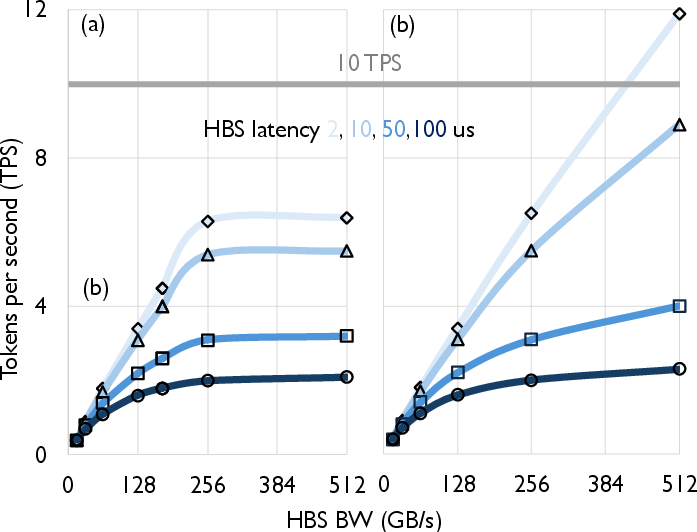
A central focus is establishing operational bandwidth and latency specifications for HBS so that target throughput (≥10 TPS) can be reached for a 13B-parameter multimodal LLM (LLaVa1.5-13B) with demanding context sizes. The results clearly indicate that:
Notably, even with high-bandwidth HBS (e.g., 512 GB/s), the absolute latency (≥10 μs) remains limiting unless DDR bandwidth is simultaneously scaled (e.g., via 3D-stacked LPDDR6). Only configurations with both high HBS bandwidth and low latency approach the target TPS.
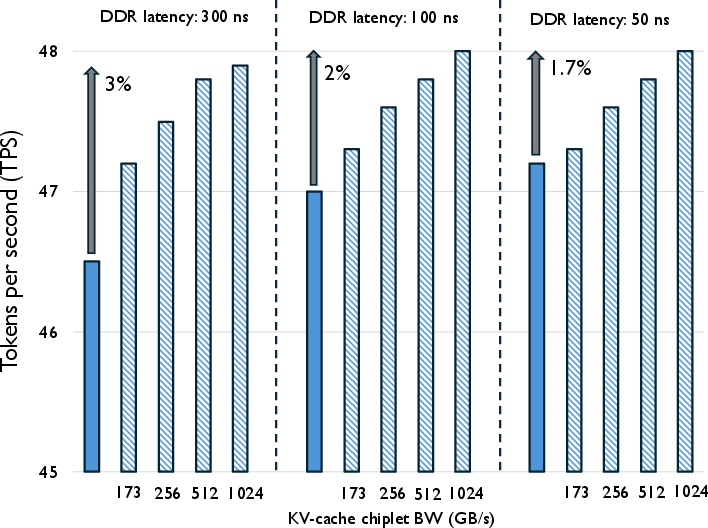
Hierarchical Memories and Selective Data Placement
Placing Q, K, V matrices in DDR while leaving weights and activations in HBS further amplifies performance gains, as it reduces high-latency HBS transactions during attention computation, a dominant runtime component for large context lengths.
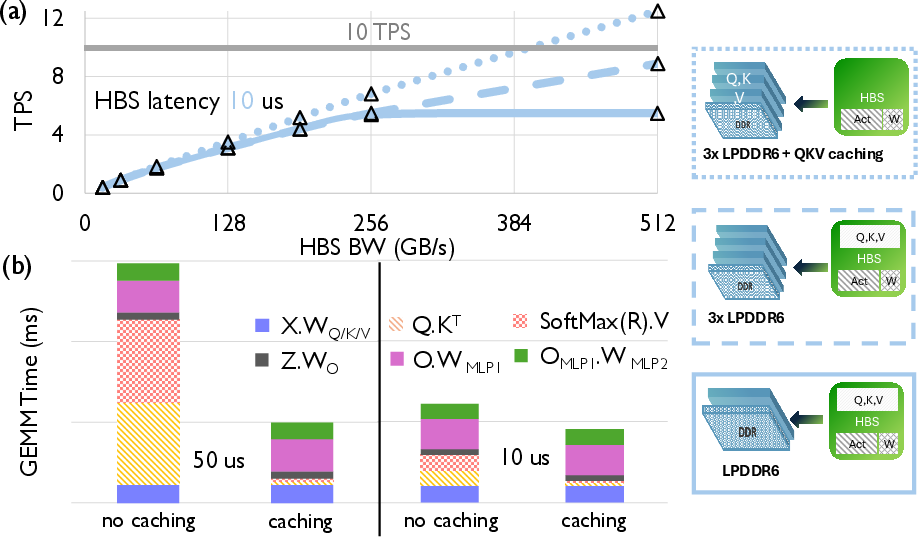
Figure 2: TPS scaling as a function of HBS bandwidth and selective attention traffic placement, plus GEMM-level breakdowns for two HBS latencies.
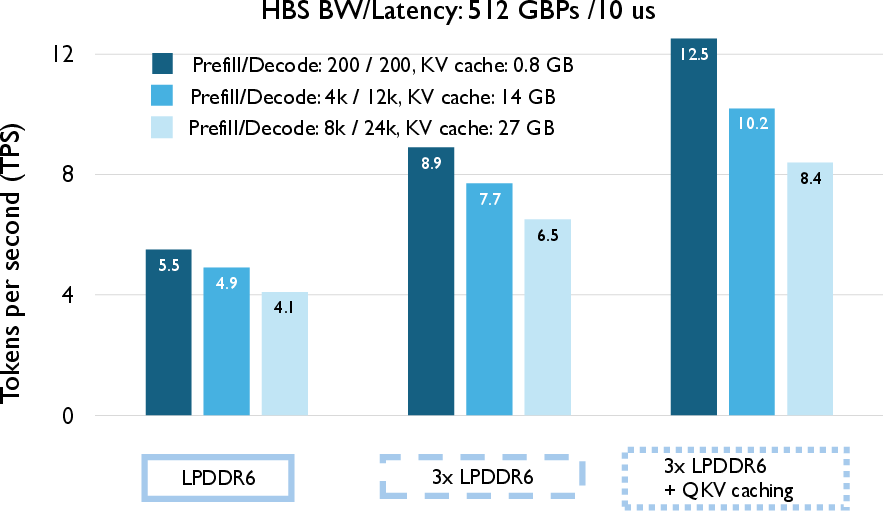
Figure 3: TPS across varying context windows for three DDR configurations, highlighting the degradation with increased context and the mitigation via traffic placement.
Restricting QKV movement to DDR drastically reduces attention phase time, which constitutes 31–69% of total GEMM time, especially as context windows grow.
Key Takeaways
- HBS is the limiting factor for both capacity and bandwidth unless its bandwidth and latency are substantially improved alongside DDR scaling.
- Selectively caching QKV in DDR achieves a 3.1× speedup over the baseline and meets the interactive threshold (12.5 TPS at 10 μs HBS latency).
- For large models and extended contexts, performance degradation due to quadratic context scaling is consistent, but relative advantages of HBS and data placement strategies persist.
SRAM-Based Chiplet Buffer for Small Models
The paper extends the analysis to smaller LLMs (e.g., Llama3.2-1B), where the KV cache fits comfortably within a tens-of-megabytes SRAM-based chiplet tightly coupled to the NPU.
Hence, retargeting the chiplet for MLP and projection weights, rather than QKV, is projected to yield more substantial gains for small models.
Implications and Future Directions
The results highlight the importance of co-optimization across model architecture, memory hierarchy, and data placement:
- System-Technology Co-Optimization (STCO): Compute-centric hardware must be evaluated in concert with innovations in hierarchical memory to meet stringent real-time requirements, especially on low-power edge devices.
- HBS Scaling: For large, multimodal or long-context LLMs, practical deployment depends critically on the availability of HBS subsystems with bandwidth and latency characteristics closely tracking those of DRAM, not just expanded persistent Flash capacity.
- Data Placement Policies: Workload-aware, fine-grained memory traffic steering (e.g., QKV on fast DDR, remainder on slower high-capacity memory) is necessary for harnessing these hardware advancements.
- Chiplet-based Approaches: For smaller models, fine-grained chiplet cache assignment targeted to bottleneck layers (MLP/projection) rather than wholesale QKV storage may be critical for maximal benefit.
As device vendors and infrastructure designers continue to scale model and context sizes, further research directions include co-understanding model sparsity, algorithmic KV-cache compression, non-uniform memory access optimizations, and the integration of intelligent scheduling middleware to dynamically adjust placement and offloading.
Conclusion
This work presents a rigorous architectural and analytical investigation into technical solutions for mitigating the severe memory bandwidth and capacity constraints imposed by gen-AI inference, particularly in edge contexts. It quantitatively demonstrates that HBS, when coupled with selective traffic allocation and DDR scaling, can deliver interactive-level throughput for large models. For small models, SRAM-based chiplets confer moderate speedups if targeted appropriately to the dominant bottlenecks in the execution graph. These findings reinforce the critical need for hardware-software-system co-design in future on-device AI deployments, pointing towards hybrid, workload-aware memory hierarchies as a central pillar of scalable gen-AI inference (2604.11128).