- The paper introduces a rigorous mathematical framework with simulated annealing to optimize KV cache placement and improve inference throughput by up to 5.87×.
- It examines the dynamic variation of token importance and its impact on memory bandwidth, highlighting the challenges of reducing migration overhead.
- Empirical evaluations on heterogeneous systems, such as NVIDIA GH200, reveal significant performance gains over static and reactive cache scheduling strategies.
Transformer-based LLMs exhibit pronounced bottlenecks during inference, primarily due to frequent read-dominant accesses to the key-value (KV) cache in the decode stage. The evolution of token importance, revealed through fluctuating attention scores, necessitates full KV cache accessibility for optimal model output—causing substantial load on both memory bandwidth and capacity. The mismatch between the rapidly advancing compute capabilities of modern AI hardware and relatively stagnant memory subsystem bandwidth exacerbates this bottleneck, restricting throughput scalability.
The integration of high-bandwidth memory (HBM) with increasingly comparable off-package DRAM (e.g., LPDDR5X, interfaced via NVLink) on AI platforms such as NVIDIA GH200 offers a heterogeneous memory system where runtime KV cache placement is non-trivial; it directly modulates aggregated bandwidth utilization while obeying strict high-capacity constraints. This paper provides a rigorous mathematical formalism for the dynamic KV cache placement problem, aiming to characterize attainable performance upper bounds rather than prescribing specific scheduling algorithms.
Temporal Variability of Token Importance and Its Implications
Token importance is highly dynamic during LLM inference, with distinct tokens exhibiting fluctuating attention scores that reflect changing contextual dependencies throughout sequential decoding steps (Figure 1).
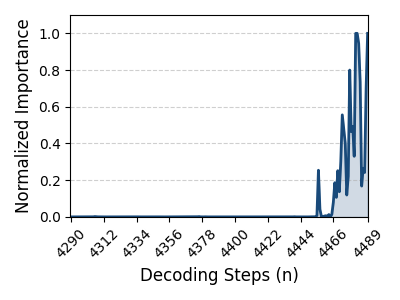
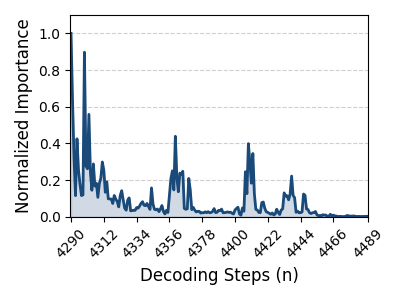
Figure 1: Visualization of attention score variation for token 2777 at layer 8, illustrating substantial temporal fluctuation in contextual importance.
This volatility implies that adaptive token bypassing, while reducing bandwidth pressure, cannot relax the full KV cache retention requirement. Hence, memory systems must be equipped to dynamically manage KV entries in real time, tracking evolving importance without sacrificing accessibility—posing a severe challenge as LLMs become longer-context and more sophisticated. HBM’s limited capacity thus becomes a core constraint motivating heterogeneous memory orchestration.
Recent advances in LPDDR interfaces and high-speed interconnects have narrowed the bandwidth disparity between HBM and external DRAM. For example, GH200 features HBM3 with up to 4 TB/s bandwidth and 24 GB capacity alongside LPDDR5X-backed DRAM delivering 900 GB/s interconnect and 500 GB/s DRAM bandwidth with notably higher capacity. Efficient KV cache distribution across this memory hierarchy can drastically impact inference throughput, underscoring the necessity of intelligent placement strategies as bandwidth utilization increasingly hinges on runtime data locality.
Mathematical Framework for Placement Optimization
The paper models inference latency as a sum of stepwise delays, each determined by maximum access time to HBM and off-package DRAM, modulated by KV cache placement and migration operations. Given a scheduling decision S(n,l) per step (composed of migration and write/read volume for each memory type), latency is derived analytically using bandwidth and migration overhead parameters from the underlying hardware configuration.
Formally, the optimization target is to minimize overall decode latency across all inference steps, subject to HBM capacity constraints. This encapsulates both the placement and migration schedule for each KV cache entry, given access patterns and memory architecture.
Theoretical Upper Bound Discovery Using Simulated Annealing
Exhaustive search of the placement solution space is infeasible due to its combinatorial complexity. The paper leverages simulated annealing (SA), assuming perfect knowledge of future access patterns, to approximate a near-optimal scheduling solution. SA dynamically adjusts look-ahead window size (W) and migration ratio (R), probabilistically accepting migration schedules with lower latency or exploring coordinated parameter perturbations to escape local minima.
This approach quantifies a theoretical performance ceiling, unattainable by any real-time system without omniscient foresight but revealing substantial potential for future heuristics employing predictive modeling or reinforcement learning. The SA-guided placement routinely identifies optimal migration points and allocation strategies that minimize unnecessary migration and maximize aggregate bandwidth utilization.
Empirical Evaluation and Sensitivity Analyses
A behavioral simulator is used, parameterized on GH200’s memory hierarchy and LLaMA-3.1-8B access patterns, to benchmark several placement strategies: unlimited HBM (ideal), static placement, reactive (LRU) scheduling, Quest-style page granularity scheduling, and the SA-guided upper bound.
Throughput results demonstrate that the SA-guided scheduler achieves up to 5.87× higher normalized tokens/sec than static placement, with performance approaching the unlimited HBM case under low importance variation. Migration overhead undermines reactive and page-based approaches under low attention sparsity, while high sparsity benefits all strategies by reducing active working set size.
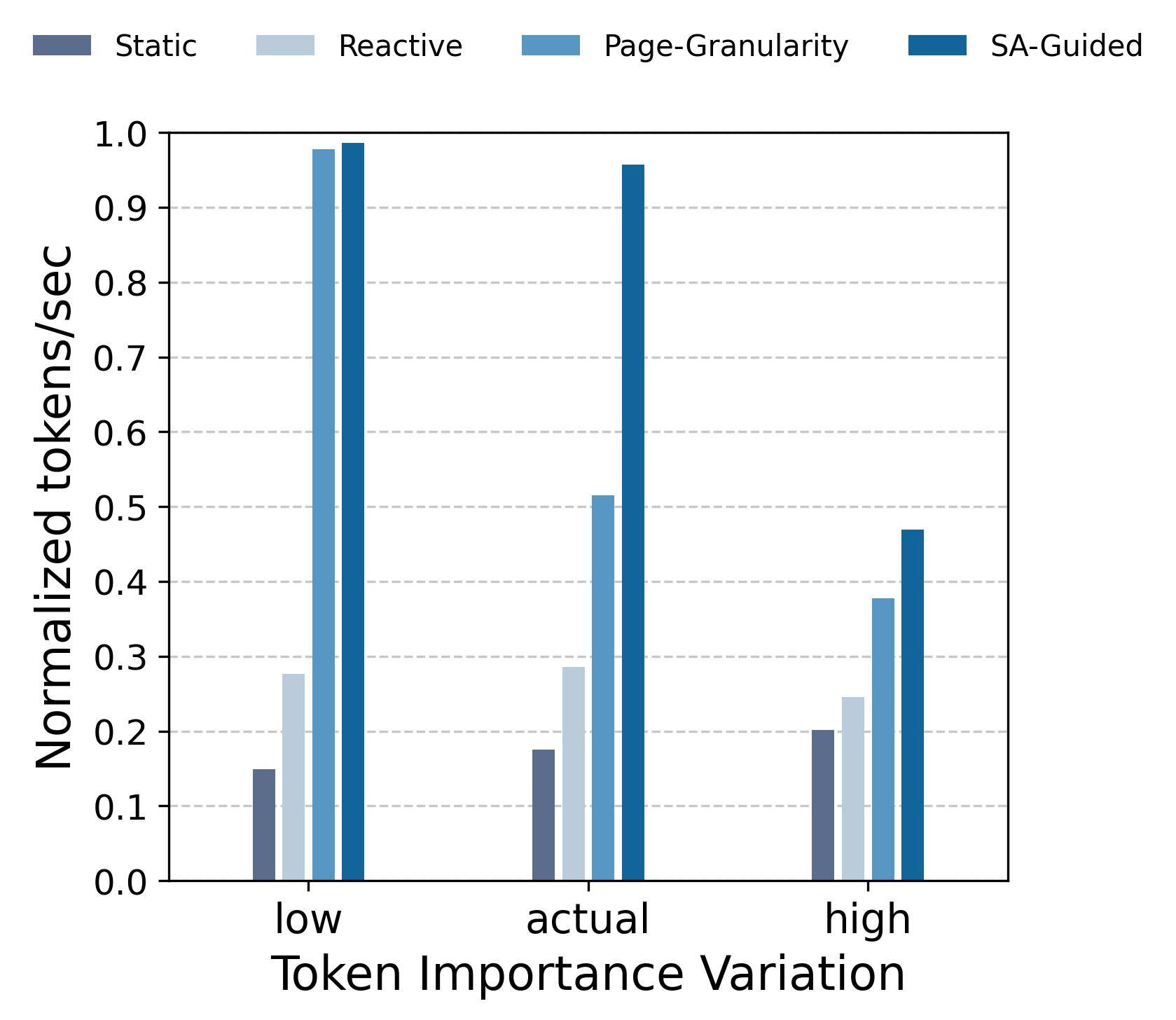
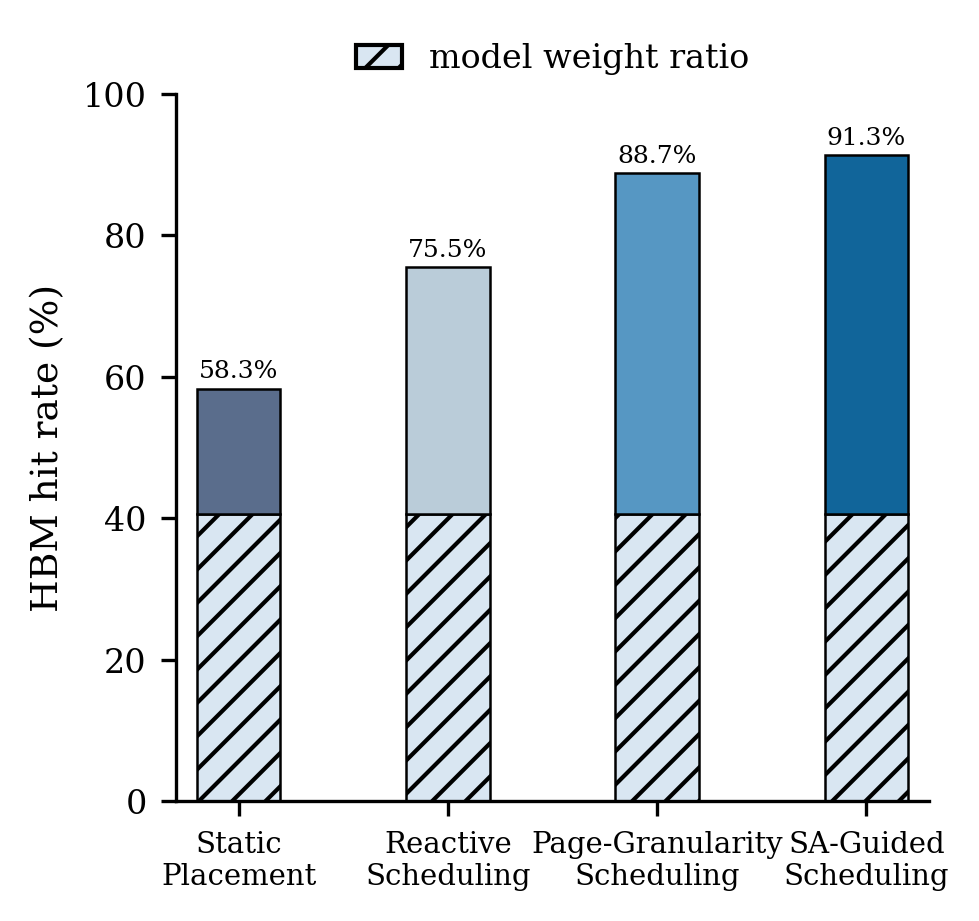
Figure 2: Left—tokens/sec normalized relative to unlimited HBM across synthetic importance variation scenarios; right—HBM hit rates at 60% sparsity.
Sensitivity analysis reveals that dynamic in-memory placement yields superior gains for inference tasks where token importance remains stable across decoding steps. High variation leads to excessive migration, reducing effective bandwidth utilization. The HBM hit rate, critical to throughput, is tightly regulated under SA, validating its heuristic advantage.
Theoretical and Practical Implications
The results and formalism illustrate large performance gaps between naive placement heuristics and theoretically optimal dynamic schemes, indicating substantial room for systems research in adaptive memory scheduling for LLMs. Practically, runtime solutions should evolve towards leveraging predictive access pattern analytics, RL, or online learning to adapt placement dynamically, exploiting near-optimal aggregate bandwidth utilization in heterogeneous memory environments.
From a theoretical perspective, this paper provides the first formal foundation for KV cache scheduling in LLM inference over heterogeneous memory, exposing explicit bounds and stimulating subsequent algorithmic exploration for aggressive latency minimization.
Conclusion
This paper establishes a rigorous mathematical framework for dynamic KV cache placement in LLM inference on heterogeneous memory architectures, deriving a theoretical upper bound using simulated annealing with perfect foresight. Simulation results demonstrate up to a 5.87× throughput improvement over static strategies, motivating the pursuit of advanced adaptive scheduling methods to approach this bound and fully harness emerging AI hardware memory hierarchies.