- The paper demonstrates that strategic hint placement with PieceHint effectively addresses reward sparsity and overfitting in RL for LLM reasoning.
- The methodology employs variance-based problem selection, semantic decomposition, and value scoring to identify and allocate critical reasoning bottlenecks.
- Empirical results show that PieceHint-augmented models achieve performance comparable to much larger baselines while maintaining solution diversity.
Strategic Hint Allocation in RL for LLM Reasoning: The PieceHint Framework
Context and Motivation
Reinforcement Learning (RL) for reasoning in LLMs frequently encounters a critical bottleneck: training on simple problems induces overfitting and pass@k collapse, while challenging instances yield sparse, non-informative rewards, hampering learning. Previous question augmentation strategies, notably uniform stepwise hinting, help mitigate exploration dead-ends, but indiscriminately injecting hints introduces redundancy, may bypass high-impact reasoning bottlenecks, and can degrade solution diversity. The "Placing Puzzle Pieces Where They Matter" paper introduces PieceHint, a principled framework for focused hinting that systematically identifies, allocates, and withdraws key reasoning steps aligned to model capability and problem structure (2604.15830).
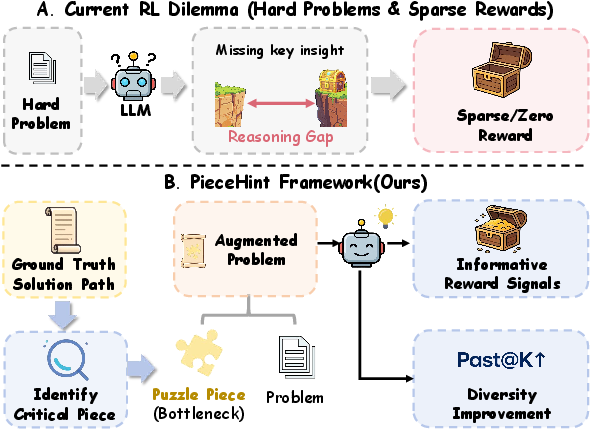
Figure 1: Conceptual illustration of the RL training dilemma and the solution provided by PieceHint, addressing sparse rewards at reasoning bottlenecks via targeted hint injection.
PieceHint: Value-Driven Critical Piece Identification and Curriculum
PieceHint centers on the insight that most solution chains in mathematical reasoning are blocked by a small set of high-impact reasoning steps—bottlenecks—while other steps are routine. Instead of prefix-truncation or random hints, PieceHint employs a multi-step pipeline:
- Variance-Based Problem Selection: Select training problems from the optimal difficulty regime, maximizing reward signal variance, by filtering with a weak reference model and the current model’s own success rate.
- Semantic Reasoning Piece Decomposition: For each candidate problem, decompose the ground-truth solution into semantically coherent pieces (not just sequential steps), each representing a discrete logical advance.
- Value Scoring and Bottleneck Identification: Use an external LLM as a scoring oracle to ascribe discrete value to each piece, evaluating novelty, difficulty, and impact (with emphasis on unlocking further reasoning). Normalize these scores for cross-problem comparison, identifying 1–3 critical bottlenecks per problem.
- Capability-Aligned Piece Allocation: Dynamically allocate the top-k highest-value pieces as hints, where k reflects model capabilities—harder problems receive more strategic scaffolding, easy problems are left unsupported.
- Progressive Piece Withdrawal Curriculum: Implement per-problem frequency-based withdrawals such that hint reliance is gradually reduced, eventually training models to solve each problem fully independently.
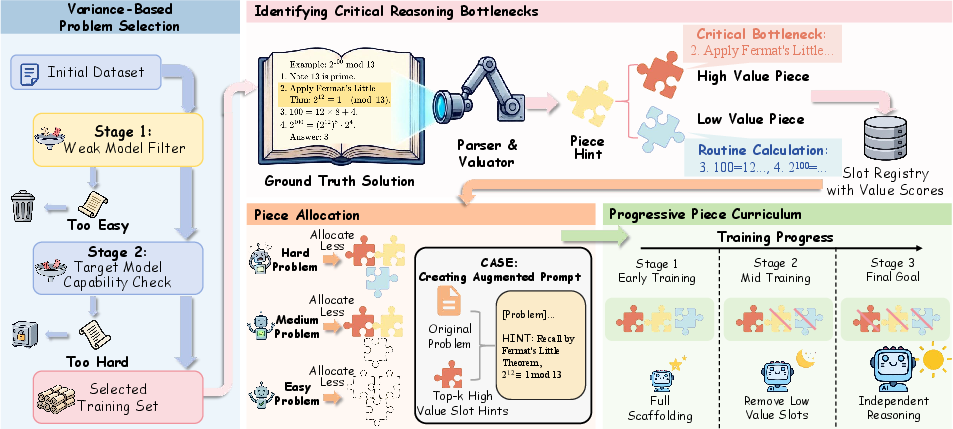
Figure 2: Schematic of the PieceHint pipeline: identifying critical steps, adaptive allocation based on model success rates, and progressive withdrawal for robust hint-free generalization.
Empirical Results: Sample Efficiency, Model Scale, and Pass@k Preservation
Quantitative results across six mathematical reasoning benchmarks show that PieceHint-augmented 1.5B parameter models (e.g., Nemotron-1.5B, Qwen3-1.7B) achieve average pass@1 performance commensurate with or surpassing much larger 32B parameter baselines, closing the capability gap with extraordinary efficiency. For example, PieceHint-Nemotron-1.5B attains performance on par with DeepSeek-R1-32B on challenging AIME and Olympiad benchmarks, and significantly outpaces models trained with uniform or prefix hinting strategies.
Ablation experiments confirm the superiority of value-driven over position-based hint allocation; both random and prefix-truncation strategies fail to robustly inject critical insights (see Figure 3).
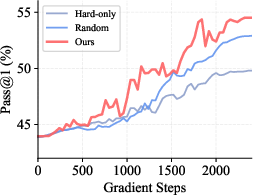
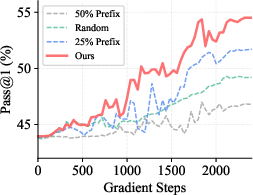
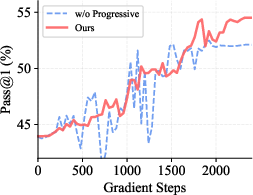
Figure 3: Comparative training dynamics on AIME24 as various hinting and selection strategies diverge in effectiveness; PieceHint yields stable, superior convergence.
Additionally, PieceHint preserves pass@k diversity across sampling budgets, demonstrating that targeted hinting does not induce over-narrow reliance on specific solution paths, but rather stimulates model exploration and combinatorial diversity in outputs.
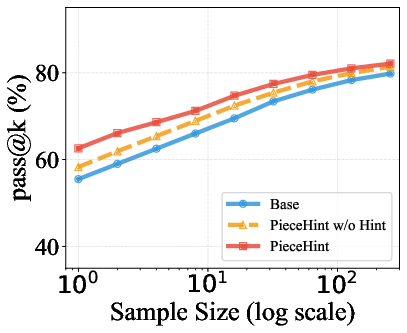
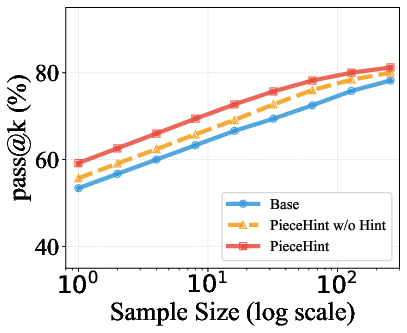
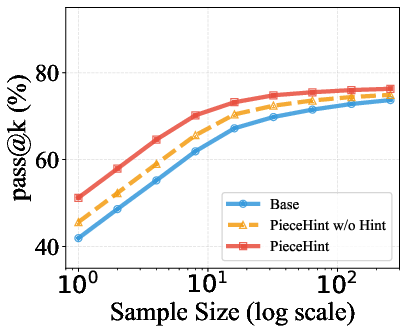
Figure 4: Pass@k performance on AIME24, AMC23, and related datasets for PieceHint and baselines: robust improvements with diminishing gap at higher k.
Theoretical and Practical Implications
Robustness and Scalability: PieceHint’s core decomposition and scoring steps are robust across scoring LLMs, prompt phrasing, and are agnostic to the specific RL algorithm or LLM backbone. The method scales well to larger models (e.g., 7B parameters), although relative gains are most pronounced for smaller, weaker models where bottlenecks are more frequent and impactful.
Generalizability: The critical piece identification and allocation mechanism directly transfers to structured domains beyond mathematics, demonstrated by strong gains in code generation benchmarks such as LiveCodeBench and CodeForces.
Bias Mitigation and Hint Dependency: Progressive withdrawal, coupled with outcome-based binary rewards, ensures that models do not overfit to hints or exploit shortcuts. Ablation studies confirm that PieceHint-trained models generalize better under hint-free evaluation compared to those trained with fixed hint sets.
Computational Efficiency: Strategic placement of hints at reasoning bottlenecks dramatically improves sample efficiency, obviating the need for brute-force model scaling or costly validation on extensive easy problem curricula.
Potential Drawbacks: PieceHint currently relies on an offline bottleneck identification process via stronger LLMs as oracles, and uses a fixed progressive withdrawal schedule rather than real-time adaptive adjustment, which could limit optimality for certain datasets.
Connections to Broader RL for Reasoning
PieceHint occupies a complementary niche with respect to recent advances in RL-based reasoning: while orthogonal works alter optimization dynamics (e.g., advantage estimation [yang2026your], exploration via entropy or temperature policy [zhou2026look]), reward modeling, or credit assignment, PieceHint operates at the input-level, directly targeting the source of reward sparsity via augmentation. The framework is compatible with process-level supervision, adaptive scheduling, and preference optimization.
Future Directions
Higher adaptivity in hint withdrawal, potentially informed by real-time measurements of model mastery per problem, could further enhance sample efficiency and responsiveness to learning curves. Exploring joint optimization with advanced reward/credit assignment and entropy-based exploration strategies is a natural next step. Extending PieceHint to domains such as logical proof generation, scientific reasoning, or even multi-agent collaborative settings marks a promising research avenue.
Conclusion
PieceHint establishes a principled and robust methodology for resolving reward sparsity and overfitting in RL for LLM reasoning. Through value-driven, capability-aligned hint injection and progressive scaffolding withdrawal, PieceHint empowers smaller models to match the reasoning prowess of much larger counterparts while preserving exploration diversity. Its methodologically modular approach is broadly adaptable and establishes a new baseline for parameter-efficient RL-based reasoning augmentation (2604.15830).