- The paper presents a novel adaptive hinting framework (HiLL) that co-trains a hinter and reasoner policy to recover learning signals in reinforcement learning.
- It introduces a transfer-aware reward structure measuring signal creation and hint reliance to ensure hints improve the original, no-hint policy performance.
- Empirical evaluations across multiple math reasoning datasets demonstrate that HiLL consistently outperforms GRPO and existing hint-based methods on both in-distribution and out-of-distribution tasks.
Hint Learning for Reinforcement Learning: A Technical Perspective
Motivation and Challenges in RL with Verifiable Rewards
Reinforcement Learning with Verifiable Rewards (RLVR) has become central in optimizing reasoning abilities within LLMs, especially in formal domains like mathematics, where correctness is objectively verifiable. GRPO (Group Relative Policy Optimization) has emerged as the preferred method, leveraging group-based advantage estimation without requiring a value critic. However, GRPO suffers from "advantage collapse": if all sampled rollouts in a group yield identical rewards (all correct or all incorrect)—a common scenario for both trivial and unsolvable questions—the estimator produces zero relative advantage and, thus, provides no policy gradient or learning signal. Critically, for hard questions at the model's capability boundary, GRPO cannot recover correct trajectories or learning signal, stagnating model improvement in these areas.
Alternative sampling and filtering strategies increase computation or reduce wasted steps but fundamentally cannot generate new learning signals when the model's probability of success is near zero. The recent trend of input augmentation via hints or scaffolds offers a pathway to recover mixed outcomes and restore non-zero group advantages, but prior approaches rely on fixed, offline, or non-adaptive hints, typically disregarding whether improvements obtained with hints transfer to the original, no-hint policy at test time.
HiLL Framework: Adaptive, Transfer-Aware Hint Learning
HiLL (Hint Learning for Reinforcement Learning) redefines hinting as a learnable co-training process, jointly optimizing a hinter policy and a reasoner policy throughout RL. The hinter generates online hints, conditioned not only on the question and reference solution but crucially on an incorrect rollout from the present reasoner, enabling the hint generation to adaptively target the evolving weaknesses of the model.
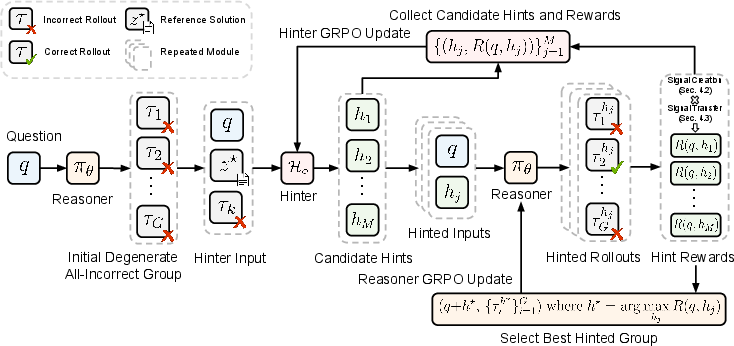
Figure 1: Overview of HiLL, displaying co-training between hinter and reasoner and the interaction for online hint generation and signal evaluation.
The core innovation is a transfer-aware reward structure for hinting: hints are evaluated not only by their ability to recover non-degenerate (i.e., mixed outcome) groups but also by their "hint reliance"—a measure quantifying how strongly success under the hint depends on the hint as opposed to the original question. By deriving a transferability bound, HiLL demonstrates theoretically that lower hint reliance guarantees tighter transfer from hinted to no-hint scenarios, leading to a transfer-weighted reward for hint generation. This framework encourages the hinter to produce hints that recover GRPO learning signals likely to improve the original, unaugmented policy, not merely shortcuts that solve the hinted variant.
Signal Creation and Signal Transfer: Quantitative Mechanisms
For each all-incorrect group, HiLL generates multiple candidate hints. The reasoner is re-sampled under each hint, and two quantitative metrics are computed:
- Signal Creation: The non-degenerate probability, s(p^h;G), measures the likelihood that the new group contains both correct and incorrect rollouts (maximal at p^h=0.5), quantifying the information available for the policy gradient update.
- Signal Transfer: Hint reliance, ρ^c(q,h), is computed as the average log-likelihood difference (normalized by trajectory length) between correct hinted trajectories sampled under q+h and q. The transfer bound asserts that the no-hint success probability is at least phexp(−ρ^c).
The hinter’s reward is the product of signal creation and a transfer weight (an exponential function of negative hint reliance), favoring hints that facilitate both learning signal restoration and transferability.
Empirical Study: Main Results and Basis for Effectiveness
HiLL was evaluated using Llama-3.2-3B-Instruct and Qwen2.5-7B-Instruct as reasoners, with Qwen3-4B-Instruct as hinter, across six math reasoning datasets (AIME24/25, AMC23, MATH-500, Minerva, OlympiadBench) and two generalization benchmarks (GPQA-diamond, MMLU-Pro). The experiments demonstrate that HiLL consistently surpasses GRPO and hint-based baselines (LUFFY, Scaf-GRPO, SAGE), not only on in-distribution tasks but also on out-of-distribution reasoning benchmarks, despite training exclusively on math prompts.
HiLL’s ablated variant (HiLLw/o TW) significantly improves over GRPO by recovering GRPO signals, but full HiLL (with transfer weighting) further increases accuracy by ensuring low hint reliance, which translates into stronger transfer to no-hint performance.
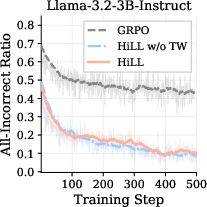
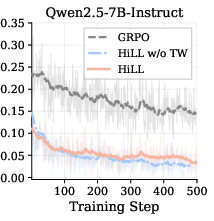
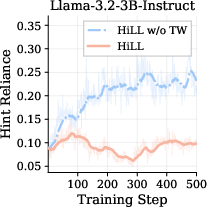
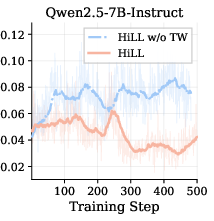
Figure 2: HiLL’s reduction of degenerate all-incorrect group ratio and lowered hint reliance compared to baselines and ablated variant, across training steps.
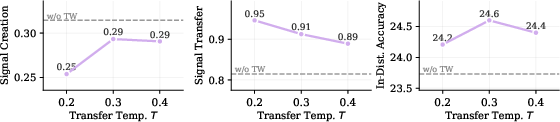
Figure 3: Influence of transfer temperature T on signal creation, signal transfer, and in-distribution accuracy, showing the trade-off controlled by transfer weighting.
Qualitative Effects and Behavioral Analysis
The transfer-weighted training objective substantively alters the nature of generated hints: HiLL produces shorter, more conceptual and strategic hints (e.g., "parameterize then eliminate" or "identify critical triangle configuration") versus explicit computation or step-by-step instructions seen in HiLLw/o TW. This is corroborated by quantitative analysis—average hint length and math expressions per hint—showing systematic reduction in verbosity and lower reliance on specific algebra, fostering conceptual reasoning. The ablation study confirms that without transfer weighting, the hinter optimizes solely for signal creation, which encourages hints with high reliance, often resembling shortcut solutions.
HiLL incurs additional computational overhead proportional to the frequency of all-incorrect groups, but this is viewed as an acceptable trade-off, because it converts otherwise useless training data into informative signal directly targeting model weaknesses.
Implications and Future Directions
HiLL resolves the two key shortcomings of prior hint-based methods: adaptivity and transfer-awareness. By linking hint quality to transferability, HiLL sets a new standard for reinforcement learning frameworks in reasoning-centric LLM domains. Theoretical guarantees, validated by strong empirical results, open avenues for extending adaptive hint learning to more general RL settings, multi-agent co-training structures, continual learning scenarios, and even personalized pedagogical hinting modalities.
Further directions include optimizing the computational efficiency of hint evaluation, leveraging hierarchical or self-distillation signals, and generalizing hint reliance metrics beyond logic-based domains, potentially integrating them with chain-of-thought and multimodal scaffolds.
Conclusion
HiLL establishes hint generation as a dynamic, learnable, and transfer-aware objective in RL for LLMs. By co-training the hinter and reasoner, and explicitly calibrating hints to both recover policy gradients and maximize transferability, HiLL demonstrates consistent improvements in both in-distribution and out-of-distribution reasoning tasks. Its theoretical transfer bound and empirical analyses underscore the practical necessity of adaptive, minimally reliant hints when optimizing reasoning models via RL.