- The paper introduces a multi-sport benchmark for evaluating video MLLMs on rule-based officiating tasks across 11 sports.
- It employs curated match segments and expert-authored QA pairs to assess foul detection, temporal localization, and entity recognition.
- Results reveal that while models perform well in incident detection, they consistently struggle with sport-specific rule reasoning and temporal grounding.
RefereeBench: Evaluating Video MLLMs for Multi-Sport Automatic Refereeing
Introduction
The paper "RefereeBench: Are Video MLLMs Ready to be Multi-Sport Referees" (2604.15736) establishes a new evaluation paradigm for Multimodal LLMs (MLLMs) within the context of automatic sports refereeing. Unlike previous efforts predominantly focused on action recognition or isolated single-sport benchmarks, this work introduces the first large-scale, multi-sport benchmark tailored for systematic, rule-grounded officiating assessment. The benchmark spans 11 sports, comprising 925 curated match segments and 6,475 expert-authored multiple-choice QA pairs covering fine-grained officiating concepts, including foul detection, classification, rationale inference, entity perception, and temporal localization.

Figure 1: RefereeBench samples require fine-grained perception, temporal grounding, and rule-based decision-making with certified referee-curated annotations.
Benchmark Design and Dataset Properties
Construction Pipeline
RefereeBench is constructed through a meticulous pipeline encompassing initial large-scale video collection, careful semantic localization using ASR-based keyword identification, followed by multi-stage, double-blind human verification. Qualified national-level referees manually annotate structured event metadata and generate corresponding QA pairs, ensuring precise rule alignment and multimodal evidence dependency. Each QA is peer-reviewed, and textual-only bias is proactively minimized via LLM ablation analyses.
Dataset Statistics and Coverage
The benchmark encompasses 11 distinct sports—soccer, basketball, volleyball, tennis, table tennis, badminton, handball, field hockey, ice hockey, water polo, and short-track speed skating. These cover 64 unique foul types and 34 distinctive penalty classes, with substantial inter-sport heterogeneity in both match durations and event structure.
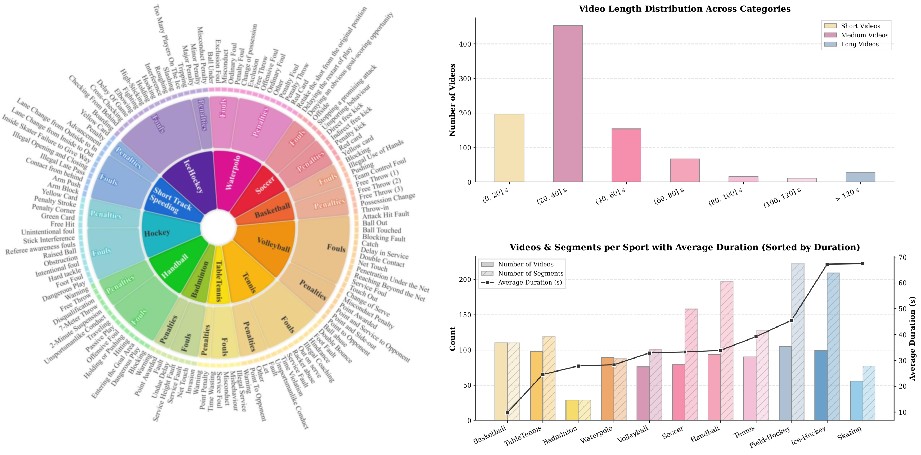
Figure 2: RefereeBench covers 11 sports, 64 foul types, and a spectrum of video lengths, supporting robust multi-sport evaluation.
Each video is paired with seven hierarchical QA types: foul existence, foul classification, foul reasoning, penalty classification, penalty reasoning, entity identification, and temporal event localization. The design supports granular dissection of model capacities, from low-level perception to intricate, rule-based multimodal reasoning.
Evaluation Protocol and Model Benchmarks
A comprehensive suite of closed-source (e.g., GPT-5, Gemini-3, Claude-4.5, Doubao-Seed-1.8) and open-source (e.g., Qwen3-VL, InternVL3.5, VideoLLaMA3, LLaVA-Video) video MLLMs are benchmarked under controlled multiple-choice decoding, with video inputs standardized to 720p and frame or full video input variants.
Results: Analysis and Findings
The leading closed-source MLLMs (Doubao-Seed-1.8, Gemini-3 Pro/Flash) obtain only 60–61% average accuracy across RefereeBench; GPT-5 lags at 54.8%, while open-source SOTA Qwen3-VL achieves just 47.1%. Strongest models excel modestly in incident existence (up to 92.5%) and entity perception (up to 79.2%); however, performance deteriorates significantly for sport-specific rule reasoning (often near or below 50%) and precise temporal grounding.
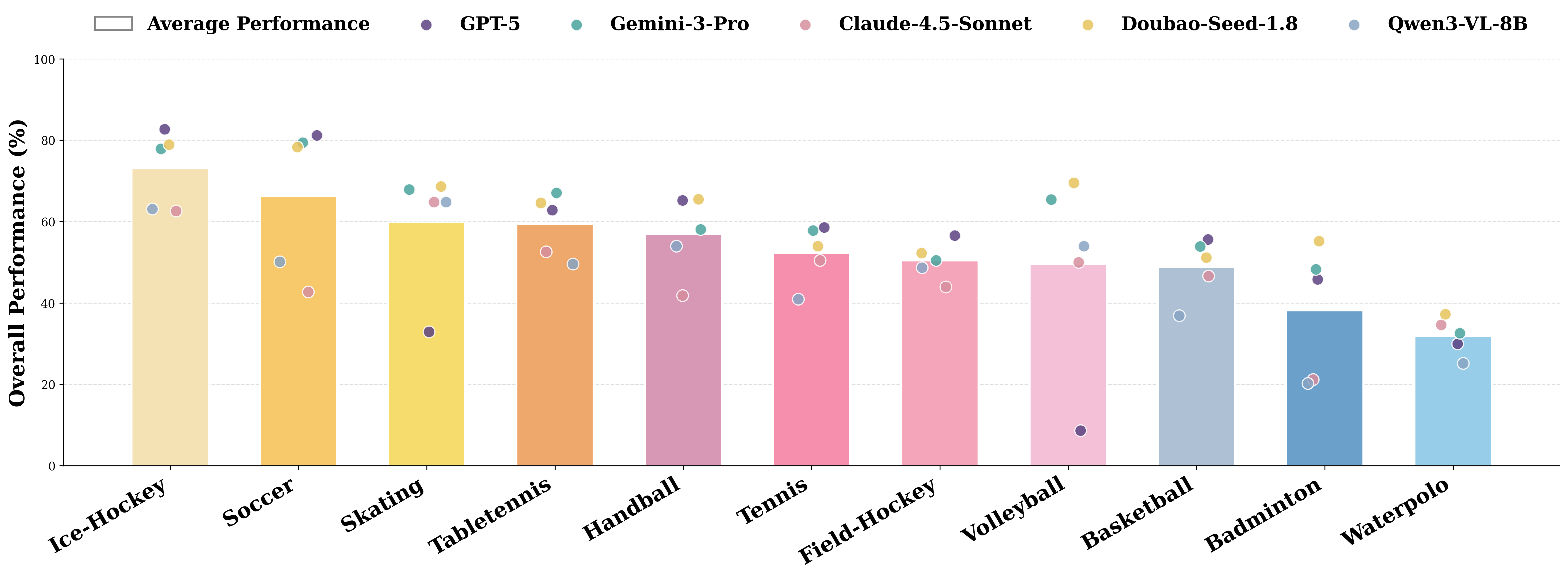
Figure 3: Performance breakdown per sport shows high variance in accuracy and highlights uneven generalization and sport-dependent difficulty.
Prominent inter-sport performance variation is observed, with models generalizing better in sports like ice hockey and soccer, but consistently failing in contexts such as water polo and badminton. This exposes core limitations in both learned visual-semantic representations and rule application.
Case Studies: Domain-Specific Reasoning Challenges
Representative event instances highlight the operational demands of rule-grounded decision-making: models must differentiate between visually similar but legally distinct contacts, correctly classify infraction types, map physical events to penalty logic, and justify discrete temporal segmentation. For example, correctly adjudicating "Tripping" in ice hockey or distinguishing a "Service Foul" in table tennis requires sport-specific legal definitions tied to precise temporal cues.

Figure 4: In ice hockey, models must identify spatial interaction and infraction reasoning for 'Tripping'.

Figure 5: For soccer, mapping actions to 'Unsporting behaviour' and determining correct penalty signage is required.
The necessity for robust multimodal reasoning and precise temporal event grounding is consistent across all sports, as further illustrated:
- (Figure 6): Lane change infraction in skating
- (Figure 7): Service error in table tennis
- (Figure 8): Push foul in handball
- (Figure 9): Double bounce call in tennis
- (Figure 10): Intentional foul in field hockey
- (Figure 11): Net touch in volleyball
- (Figure 12): Blocking violation in basketball
- (Figure 13): Service fault in badminton
- (Figure 14): Ordinary foul in water polo
Detailed Error Analysis
Modality and Multimodal Reasoning
Incorporating audio yields consistent performance gains (up to +17% absolute), underscoring the importance of multimodal cues (e.g., whistle signals, commentator events) for robust decision-making. Nonetheless, even with audio, neither proprietary nor open-source MLLMs reach human-expert-level reliable performance.
Rule Knowledge and RAG Integration
Text-only professional referee exam results confirm that leading models possess partial rule knowledge (e.g., 69% for Gemini-3-Flash, 54% for Qwen3-VL), but exhibit pronounced deficits in game management and execution dimensions. Naive retrieval-augmented generation (RAG) over official rulebooks fails to close the gap; in some cases, model performance deteriorates as irrelevant or ambiguously retrieved text can anchor models to incorrect decisions—highlighting the necessity for deeper multi-hop, visually-grounded rule comprehension.
Bias and Robustness
Models display a systematic tendency to over-call fouls, with misidentification rates for negative samples (i.e., correct legal actions) exceeding 37–63% in neutral settings and surging higher under suggestive questioning. Sensitivity to adversarial or leading context points to insufficient robustness and calibration, a critical limitation for real-world officiating scenarios.
Implications, Limitations, and Future Directions
Practical Consequences
Current MLLMs are not deployment-ready for trustworthy, automated refereeing in either professional or amateur sports settings. While some components—entity recognition, event spotting—approach functional adequacy, the central competencies of temporal localization and legal rule application remain underdeveloped and error-prone.
Theoretical Implications
The findings expose the boundaries of parametric multimodal learning vis-à-vis structured, domain-specific reasoning. Scaling model or data size alone does not resolve the disconnect between perceptual event understanding and actionable, rule-compliant decision-making. Progress will require architectures capable of tightly integrating physical evidence, temporally synchronized semantics, and explicit symbolic reasoning over sport rulebooks.
Future Research Directions
Promising research directions include:
- Enhanced multimodal pretraining with explicit sports officiating supervision
- Visual chain-of-thought approaches for transparent, stepwise event-to-rule reasoning
- Agentic pipeline architectures decomposing the task into incident detection, candidate classification, and rule validation modules
- Data augmentation spanning underrepresented sports, interaction patterns, and evidence types to promote generalization and debiasing
- Reinforcement learning leveraging human-in-the-loop calibration for robustness against bias and adversarial context
Conclusion
RefereeBench establishes a rigorous, expert-verified testbed for evaluating the hierarchical reasoning capacities of MLLMs in multi-sport automatic refereeing. Present generation models—despite demonstrating impressive general multimedia capabilities—fall short of the reliability threshold required for real-world officiating, especially in high-stakes or ambiguous scenarios. The benchmark provides a critical evaluation lens and foundation for subsequent research into trustworthy, rule-grounded, and interpretable multimodal AI systems for complex real-world decision-making (2604.15736).

