- The paper introduces VideoZeroBench, a benchmark that rigorously tests video MLLMs on fine-grained evidence verification with spatio-temporal grounding, revealing significant shortcomings.
- It employs a five-level evaluation protocol that decouples answer generation from evidence localization, exposing critical model deficiencies in spatial and temporal reasoning.
- Empirical studies on 17 models show even advanced systems struggle to exceed 1% accuracy in fully grounded responses, highlighting a key challenge in video understanding.
VideoZeroBench: A Capability-Centric Benchmark for Fine-Grained, Evidence-Grounded Video MLLM Evaluation
Motivation and Benchmark Design
Despite the proliferation of multimodal LLMs (MLLMs) and their apparent success on various video understanding benchmarks, fundamental questions remain regarding genuine model capabilities. Prevailing evaluations measure answer correctness in QA, often with relatively short videos, neglecting the critical aspect of whether predictions are grounded in the actual spatio-temporal evidence that supports them. Consequently, deficiencies in fine-grained perception, reasoning, or evidence localization are obscured.
To address this, "VideoZeroBench: Probing the Limits of Video MLLMs with Spatio-Temporal Evidence Verification" (2604.01569) introduces VideoZeroBench, a rigorous hierarchical benchmark specifically designed to expose the boundaries of current video MLLMs. It does so through three central innovations: (1) open-ended, capability-centric QA in long, complex videos; (2) exhaustive manual annotation of questions alongside temporally- and spatially-grounded supporting evidence; (3) a five-level evaluation protocol decoupling answer generation and evidence grounding, progressing from QA with hints to stringent answer+grounding requirements.
VideoZeroBench encompasses 500 manually curated questions across 138 long videos (>667s on average) from 13 diverse domains, annotated for 11 atomic visual and reasoning capabilities—including counting, small-object perception, orientation discrimination, and multi-segment reasoning (Figure 1).
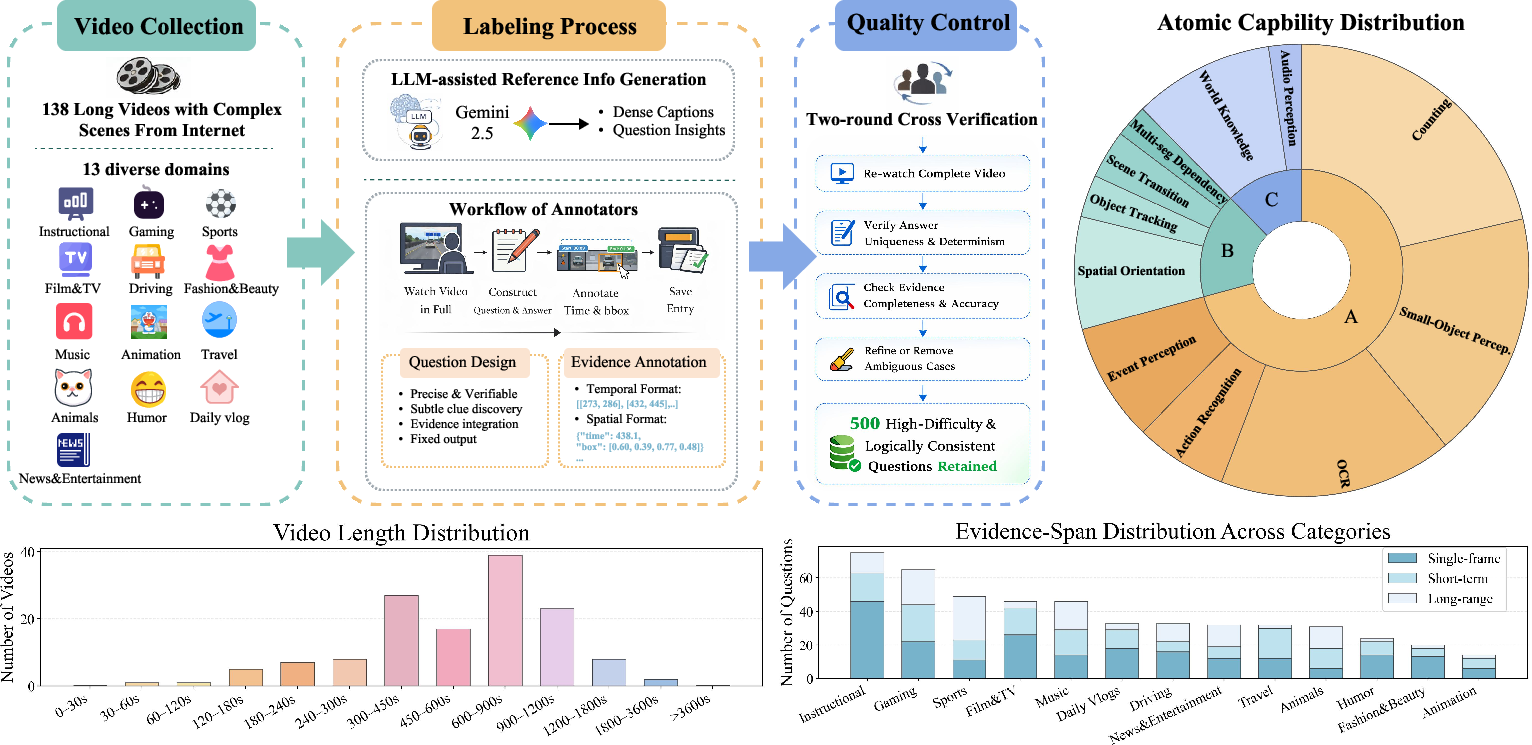
Figure 1: Data construction and statistics for VideoZeroBench, covering 13 domains and 11 atomic abilities, as well as statistics on video length and minimal evidence span distributions.
Five-Level Evaluation Protocol
To ensure that evaluation does not conflate correct guessing or hallucination with authentic understanding, VideoZeroBench incorporates a five-level hierarchical testing regime:
- Level-1: QA with both correct temporal and spatial evidence given.
- Level-2: QA with only temporal evidence provided.
- Level-3: Standard end-to-end QA (no evidence hints).
- Level-4: Correct answer and temporally grounded evidence required (temporal IoU > 0.3).
- Level-5: Correct answer with both accurate temporal and spatial grounding (temporal IoU > 0.3, visual IoU > 0.3).
This protocol enables structured attribution of errors to reasoning failure, weak temporal search, or poor spatial localization. Level-5 captures the most rigorous, evidence-grounded setting for trustworthy model evaluation.
The benchmark evaluates 17 leading architectures, including proprietary foundation models (Gemini-3/2.5, Seed-2.0, GPT-5.2), open-source baselines (Qwen3.5, Qwen3-VL, InternVL3.5), and reasoning-specialist models (Video-R1, VideoChat-R1.5, Video-o3, Open-o3-Video). Key outcomes indicate a systemic failure in both answering and grounding:
- Under standard QA (Level-3), the best-performing model (Gemini-3-Pro) reaches only 17% accuracy, with leading open-source at ∼10%.
- Under full spatio-temporal grounding requirements (Level-5), no model exceeds 1% accuracy, and most are at zero.
Performance degrades monotonically from Level-3 to Level-5 for all models, highlighting a severe gap: even when correct answers are produced, models rarely identify authentic supporting evidence, indicating frequent reliance on hallucination or pattern-matching rather than robust reasoning. This bottleneck persists even when evidence hints are provided—Level-1 accuracy remains below 30%, suggesting limited exploitation of explicit cues and integration of fine-grained signals.
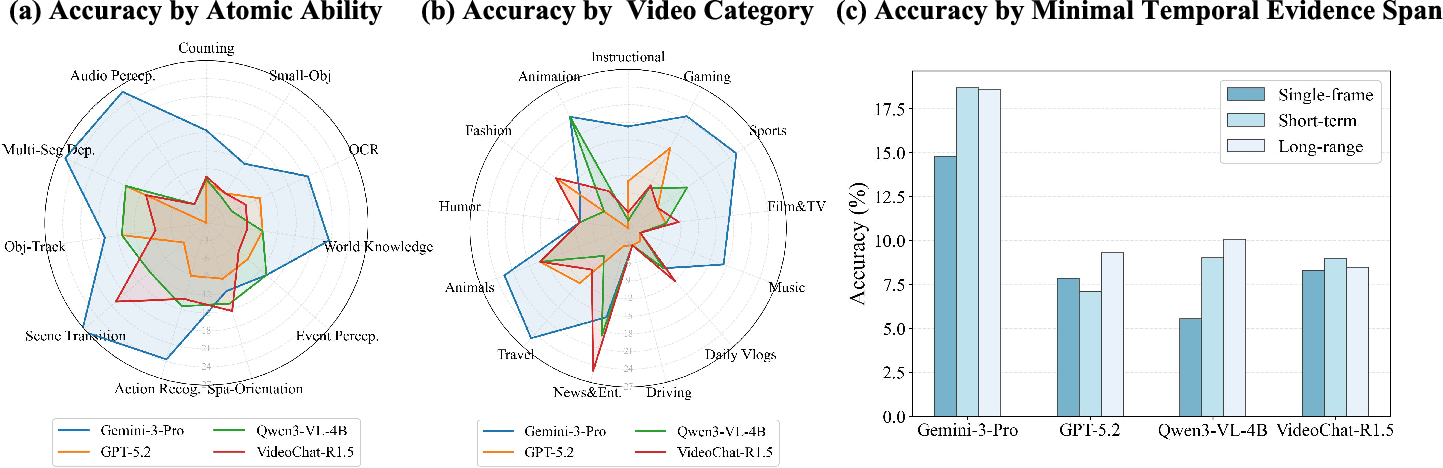
Figure 2: Comparative performance across atomic abilities, categories, and evidence spans.
Failure Modes, Fine-Grained Analysis, and Insightful Examples
Detailed dissection by atomic abilities confirms acute deficiencies:
- Small-object perception and spatial orientation: Both are notably weak (Gemini-3-Pro ~12%), especially in challenging categories like driving.
- Counting and multi-segment integration: Models underperform on tasks requiring aggregation across scenes or frames.
- Agentic, multi-round reasoning (e.g., VideoChat-R1.5, Video-o3): Provides marginal gains (<2% improvement in QA), but no significant improvement for evidence grounding.
Furthermore, single-frame answerable questions are not universally easier: fleeting, crucial evidence frames in long videos are commonly missed, especially under uniform sampling strategies. Audio-visual integration remains primitive; full-video input boosts audio perception yet often reduces fine-grained visual task performance.

Figure 3: Representative VideoZeroBench scenarios with ground-truth evidence and MLLM predictions, illustrating common reasoning and grounding errors, such as mislocalization, spatial misinterpretation, fragmented evidence integration across temporal segments, and inability to combine audio and visual cues.
Failures are not limited to inaccurate evidence localization but extend to cases where correct answers are produced by guessing without corresponding grounding. Error analysis across multiple figures demonstrates models misinterpreting spatial relationships, counting under occlusion, and neglecting transient, yet essential, visual or audio clues.

Figure 4: Categorized examples exhibiting correct and incorrect spatio-temporal localization and answer generation, with color-coded evaluation (green: correct/within IoU threshold; red: incorrect/fails IoU).

Figure 5: Challenging cases—models struggle with chart interpretation and complex, constraint-bound counting tasks featuring highly confusable instances.

Figure 6: Scenarios requiring nuanced integration of audio and fleeting visual signals, where current models typically fail to localize key segments or perceive small objects under transient events.
Practical and Theoretical Implications
These findings delineate critical theoretical implications for video MLLM researchers:
- High QA accuracy on extant benchmarks does not equate to true video understanding. Benchmarks that lack evidence verification are susceptible to answer-hallucination or pattern-matching artifacts.
- Grounded, evidence-based reasoning and perception—particularly in long, cluttered, and semantically complex videos—remains a profound technical barrier.
- Agentic "thinking-with-video" approaches that focus on iterative temporal zoom-in yield only incremental improvements due to underlying weaknesses in both spatial and temporal grounding.
- Purely increasing sampling budgets or test-time scaling does not solve the core problem; the model's localization and integration capabilities are paramount.
From a practical standpoint, deployment of video MLLMs in domains requiring high reliability (e.g., autonomous driving, medical video analysis, surveillance) is fundamentally limited by their inability to produce verifiable evidence for their predictions.
Future Prospects
VideoZeroBench establishes a new, rigorous evaluation paradigm for video understanding. Future advances should target:
- Architectures with explicit mechanisms for dynamic evidence-seeking, temporal–spatial search, and compositional reasoning.
- Learning protocols that jointly optimize answer generation and grounding, potentially with explicit reward signals for evidence localization.
- Richer agentic frameworks that integrate both temporal and spatial zoom-in and facilitate iterative, multi-modal hypothesis verification.
The substantial performance gap to human-level (over 67% on a subset of questions vs. < 17% for the best machine) as revealed by controlled studies underscores the magnitude of the challenge and the necessity for genuinely evidence-grounded video intelligence systems.
Conclusion
VideoZeroBench (2604.01569) rigorously demonstrates that current video MLLMs are far from genuine, trustworthy spatio-temporal understanding, with critical weaknesses in evidence-based perception, reasoning, and grounding. The field must move beyond superficial answer correctness and aggressively pursue explicit, verifiable evidence-gathering and integration as the cornerstone of future progress in video MLLMs.