- The paper introduces SiMing-Bench as a benchmark for process-level procedural evaluation in full-length clinical skill videos using continuous interaction analysis.
- It leverages a curated dataset of 200 clinical exam videos annotated with step-wise rubrics and measured by metrics like PLCC and Cohen’s kappa.
- Empirical results reveal that current video MLLMs struggle with dynamic state tracking, underscoring a need for memory-augmented and causal reasoning architectures.
Expert Evaluation of "SiMing-Bench: Evaluating Procedural Correctness from Continuous Interactions in Clinical Skill Videos" (2604.09037)
Introduction and Motivation
The paper introduces SiMing-Bench, a new benchmark targeting the underexplored problem of process-level procedural judgment in the context of full-length clinical skill videos. Unlike prior MLLM video benchmarks that focus on event-level perception or temporal ordering, SiMing-Bench is designed to test whether models can track how ongoing, interaction-driven scene evolution affects procedural validity at each step. This is a core capability for expert judgment in clinical skill assessment, where accumulated interaction history determines the correctness of subsequent actions.

Figure 1: SiMing-Bench evaluates models on whole-procedure video with expert rubrics and step-wise scores, as opposed to existing benchmarks that focus on local video understanding tasks.
Benchmark Design and Dataset Construction
SiMing-Bench is instantiated using SiMing-Score, a curated and annotated dataset of 200 real-world clinical skill exam videos covering cardiopulmonary resuscitation (CPR), automated external defibrillator (AED) operation, and bag-mask ventilation (BMV). Each video captures a complete workflow in a clinical educational context and is annotated by two independent physicians using standardized, expert-defined step-wise rubrics.
The critical distinction in this benchmark is the focus on tracking and scoring sequential procedural steps, where correctness is only well-defined in the context of the evolving procedural state induced by prior actions. Each rubric decomposes the skill into clinically meaningful steps, each with explicit scoring criteria. The annotations deliver both step-level and overall-procedure scores with high inter-expert agreement—PLCC of 0.871 for overall scores and Cohen's κ of 0.732 at the step level—demonstrating the consistency and reliability of the human reference.

Figure 2: Multi-frame examples show temporally extended, interaction-driven procedural workflows for CPR, AED, and BMV, emphasizing the challenge of modeling continuous state change.
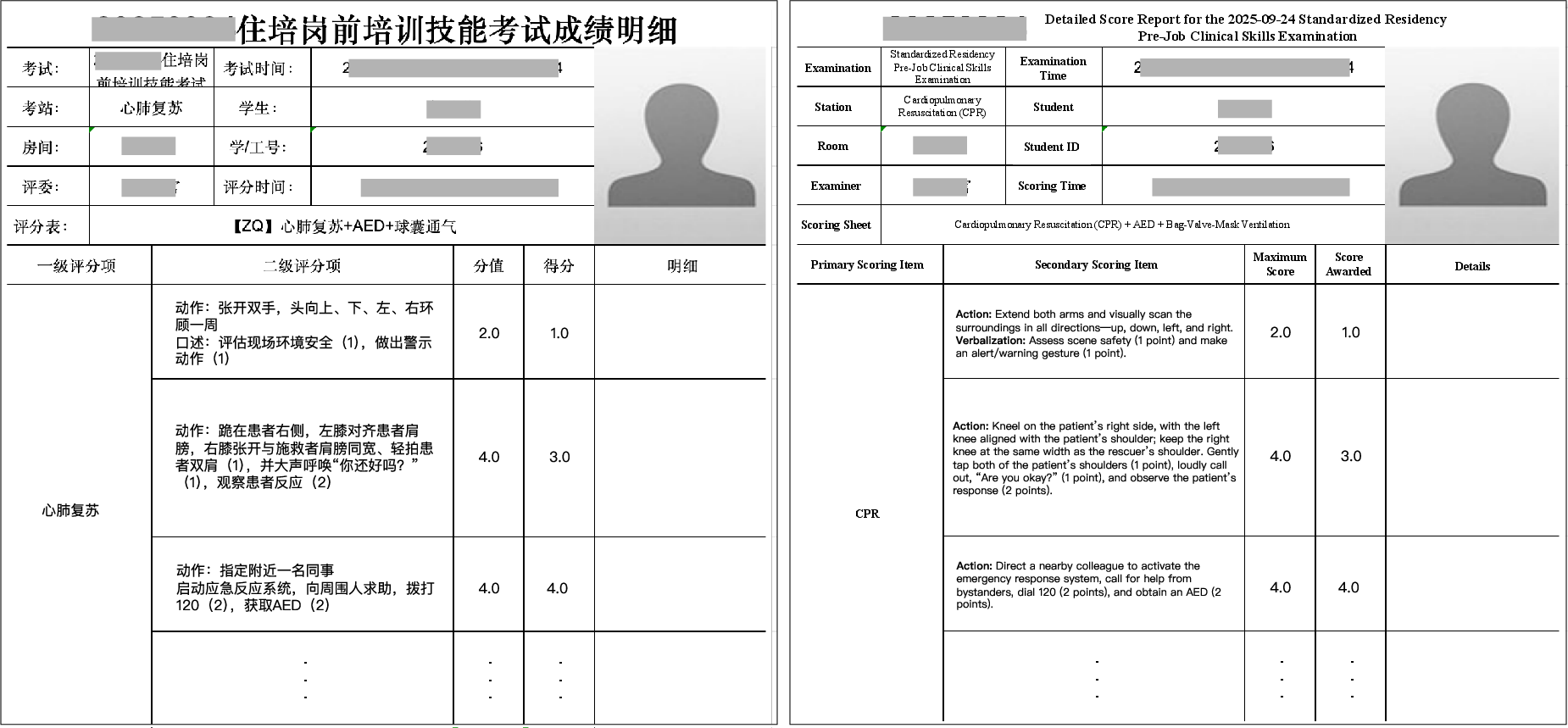
Figure 3: Sample of the bilingual, standardized physician-defined scoring rubrics paired with each procedural workflow.
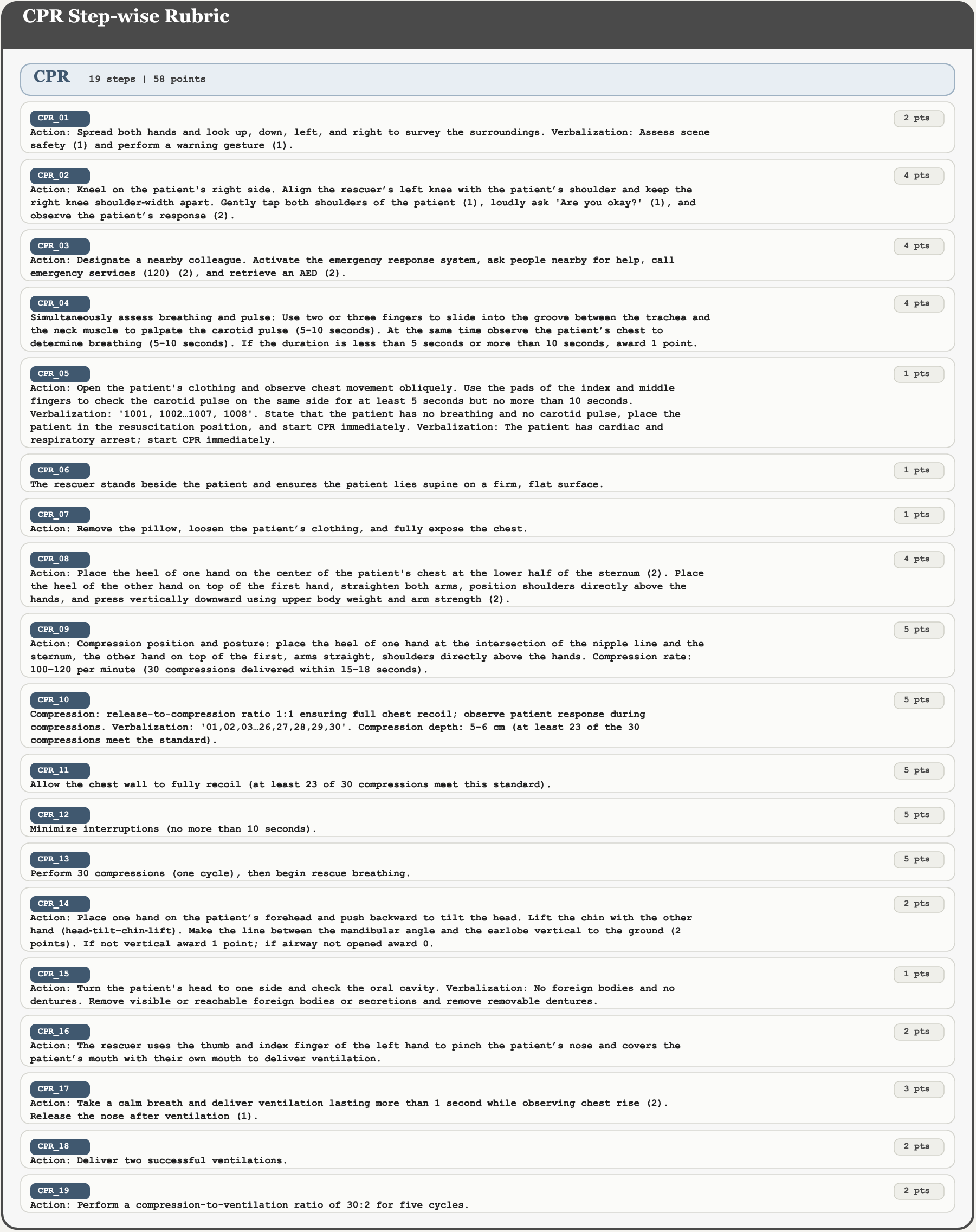
Figure 4: The CPR-specific standardized rubric structure used for rigorous step-level annotation.
Evaluation Protocol and Baselines
Model evaluation is rubric-grounded: given a full video and the expert rubric, models must predict both step-wise and overall scores. Metrics include PLCC and SRCC for overall scoring, and quadratically weighted Cohen’s κ for step-level agreement, thus assessing models’ ability to recover both coarse and fine-grained expert procedural judgment.
The benchmark covers diverse open-source Video-MLLMs (e.g., LLaVA-Video, Qwen3-VL), omni-modal proprietary models (e.g., GPT-4o, Gemini-3 Pro, GPT-5.2), and medical-domain MLLMs (e.g., UniMed-VL, MedGemma, MediX-R1) with official prompting protocols and frame sampling matching model capabilities.
Empirical Results and Analysis
Systematic Underperformance of Current MLLMs:
All evaluated MLLMs demonstrate weak agreement with physician judgments at both the overall and step levels. The strongest model (GPT-4o) attains only 0.158 PLCC for overall scoring and zero step-level κ. No system, open or closed source, approaches human-level agreement. Performance does not consistently improve with model scale or medical specialization—e.g., large models such as LLaVA-Video-72B perform worse than their smaller variants, and medical-specialized models (UniMed-VL, MedGemma, MediX-R1) show no systematic advantage.
Coarse Global Assessment Masks Process-Level Deficiencies:
Some models exhibit moderate overall score correlations but still fail at step-level procedural agreement, indicating that global performance estimation can arise from superficial statistical regularities without capturing the expert reasoning underlying procedural validity.
Diagnostic Task Simplifications Do Not Resolve Core Failures:
Diagnostic experiments reduce step scoring to binary correctness and restrict input to manually segmented, step-aligned clips to control for scoring granularity and temporal localization. Despite these simplifications, models’ median MCC remains near zero for binary step judgment, and Cohen’s κ remains at or near zero for step-aligned clips, indicating that the key limitation lies in representing and updating procedural state through continuous interaction, not in output format or temporal search.
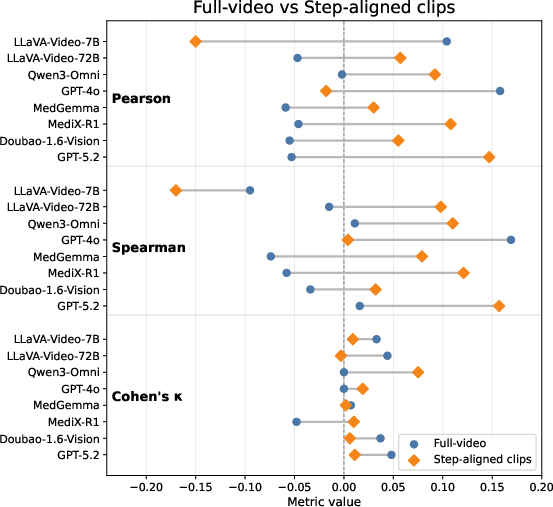
Figure 5: Direct comparison of model performance between full-video and step-aligned clip settings, highlighting persistently low agreement.

Figure 6: Evaluation of binary step correctness judgment reveals that even with the detection task reduced to its simplest form, models consistently fail to replicate expert assessment.
Theoretical Implications and Bottleneck Analysis
The results demonstrate a bottleneck in world modeling for current video MLLMs: they do not reliably turn observed, continuous procedural interactions into explicit, expert-aligned judgments about evolving procedural state. Agreement at the global score level can coexist with near-zero step-wise accuracy. Even strong scaling and domain-tuning in both general and specialized MLLMs fail to induce the structured memory and dynamic state-tracking required for valid process-level assessment.
The benchmark’s multi-granularity design is therefore critical: models require assessment at both intermediate and global levels to avoid overestimating process understanding based on coarse statistical cues.
Practical Applications and Future Directions
SiMing-Bench exposes essential limitations for deploying MLLMs in automated clinical skill assessment, patient safety monitoring, and other domains demanding rigorous process-level understanding. It sets a new standard for evaluating reasoning beyond event-level perception—demanding the integration of interaction sequencing, causal impact, and expert-aligned state evolution.
Future key research directions include:
- Memory-Augmented Architectures: Integration of persistent or dynamic memory modules to retain evolving procedural context across long-horizon tasks.
- State Causality and Predicate Tracking: Explicit modeling of state transitions and action-conditioned changes, potentially via symbolic, causal, or hybrid neural-symbolic world models.
- Temporal Abstraction and Workflow Hierarchy: Hierarchical approaches that leverage the structured nature of clinical workflows for more abstract, temporally coherent process modeling.
- Domain-Integrated Instruction Tuning: Leverage task-specific instructional data and process rubrics to align model outputs with expert-validated procedural logic.
Conclusion
SiMing-Bench provides a rigorously constructed and expertly annotated benchmark that exposes the fundamental inability of current MLLMs to convert evolving, interaction-rich video into expert procedural judgments. The persistent gap between algorithmic and expert process-level assessment persists across models, scales, and simplification attempts, underscoring the need for fundamentally new approaches in world-state modeling, memory, and procedural reasoning. SiMing-Bench is poised to drive progress in robust real-world video understanding and the next generation of expert-aligned, multimodal intelligent systems.