Stargazer: A Scalable Model-Fitting Benchmark Environment for AI Agents under Astrophysical Constraints
Abstract: The rise of autonomous AI agents suggests that dynamic benchmark environments with built-in feedback on scientifically grounded tasks are needed to evaluate the capabilities of these agents in research work. We introduce Stargazer, a scalable environment for evaluating AI agents on dynamic, iterative physics-grounded model-fitting tasks using inference on radial-velocity (RV) time series data. Stargazer comprises 120 tasks across three difficulty tiers, including 20 real archival cases, covering diverse scenarios ranging from high-SNR single-planet systems to complex multi-planetary configurations requiring involved low-SNR analysis. Our evaluation of eight frontier agents reveals a gap between numerical optimization and adherence to physical constraints: although agents often achieve a good statistical fit, they frequently fail to recover correct physical system parameters, a limitation that persists even when agents are equipped with vanilla skills. Furthermore, increasing test-time compute yields only marginal gains, with excessive token usage often reflecting recursive failure loops rather than meaningful exploration. Stargazer presents an opportunity to train, evaluate, scaffold, and scale strategies on a model-fitting problem of practical research relevance today. Our methodology to design a simulation-driven environment for AI agents presumably generalizes to many other model-fitting problems across scientific domains. Source code and the project website are available at https://github.com/Gudmorning2025/Stargazer and https://gudmorning2025.github.io/Stargazer, respectively.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Stargazer, a kind of “obstacle course” for robot scientists (AI agents). In this course, the AI tries to discover planets around stars using real physics and messy data, not just textbook questions. The goal is to see if AI can do what human astronomers do: look at a star’s tiny back-and-forth “wobble” over time and figure out how many planets are there and what their orbits look like.
What questions did the researchers ask?
- Can AI agents follow a realistic, multi-step scientific process to find planets from noisy telescope measurements?
- Do AIs that make the data “look like a good fit” actually recover the right physical answers (the correct number of planets and their true orbits)?
- Does giving the AI more time or tokens (more “thinking”) help, or does it just make them repeat the same mistakes?
- Do simple “skills” or tips improve performance, especially on harder, more realistic problems?
How did they test their idea?
They built Stargazer, a testing environment with 120 planet-hunting tasks:
- 100 synthetic tasks made by simulating stars with planets using real physics. These are grouped into Easy, Medium, and Hard, with difficulty controlled by things like noise level, number of planets, and tricky timing patterns.
- 20 tasks based on real telescope data from past astronomy studies.
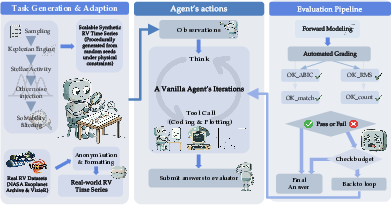
In each task, the AI gets a time series: when the star was observed and how fast it was moving toward or away from us. This “radial velocity” changes because orbiting planets tug on the star, making it wobble.
The AI works in a loop like a scientist:
- Analyze the data (look for repeating patterns).
- Try a model (for example, “there’s 1 planet with this period and strength”).
- Check how well the model matches the data.
- Revise and try again if needed.
To decide if an AI solved a task, Stargazer uses four checks:
- RMS (fit quality): Are the leftover errors small on average? Think of it like, “How far are the dots from the line you drew?”
- Delta BIC (model preference): Does your model explain the data better than a “flat line,” without being too complicated? It’s a score that rewards good explanations but penalizes adding unnecessary planets.
- Match score (physical correctness): Do the submitted planets’ periods and strengths line up with the true ones? This checks whether the AI found the right orbits, not just any curve that fits.
- Planet count: Did the AI report the correct number of planets?
A task only counts as solved if all four are passed at the same time.
They also gave each task a “budget” (limits on steps, time, and tokens) to prevent endless loops.
Key terms explained simply
- Radial velocity (RV): How fast a star moves toward or away from us. Planets make the star wobble, so RV goes up and down like a small wave.
- Signal-to-noise ratio (SNR): How loud the planet’s signal is compared to background noise. Finding a whisper in a crowded room is low SNR; a shout is high SNR.
- RMS (root-mean-square error): The average size of the leftover wiggles after you fit your model. Smaller is better.
- BIC (Bayesian Information Criterion): A score that balances “fits well” against “is too complicated.” More planets isn’t always better.
- Resonance/aliases: When planets have periods with neat ratios (like 2:1 or 3:2), or the data are irregularly spaced, false peaks can appear that look like real signals—this can fool simple searches.
- Match score: A measure of how close the AI’s planet parameters are to the truth, not just how well the curve hugs the data.
What did they find?
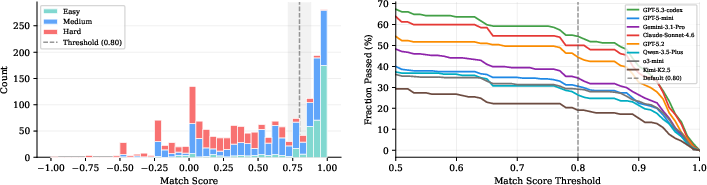
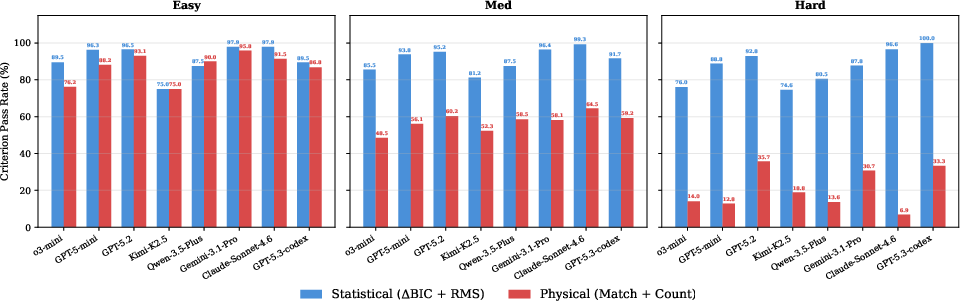
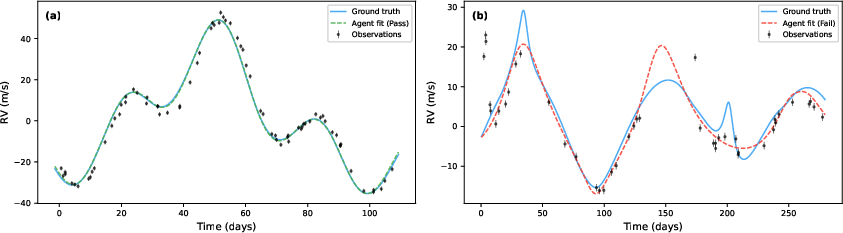
- Good curve fitting isn’t the same as good science: Many AIs made models that matched the data nicely (passed RMS and BIC), but they still guessed the wrong number of planets or the wrong orbits (failed Match and Count). In other words, they could draw a smooth line through the dots, but they didn’t figure out the real, underlying planets causing the wobble.
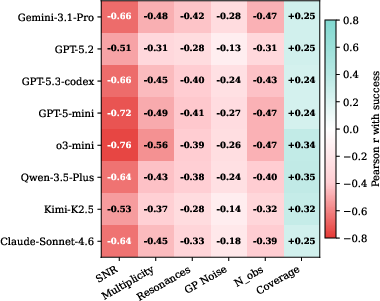
- Hard tasks were much tougher: On easy tasks, the best agents solved a lot of cases. On medium tasks, performance dropped. On hard tasks, almost none were solved. The hardest cases involved low SNR, multiple planets, and confusing resonances.
- Real data were especially challenging: Across the 20 tasks built from real telescope observations, none of the eight tested AI agents solved a single case—even though human astronomers have already solved them. This shows a big gap between current AIs and expert human performance in realistic scenarios.
- More compute didn’t fix the problem: Letting the AIs think longer or use more tokens mostly led to repeating the same wrong ideas (like getting stuck in a “local minimum” and resubmitting similar answers) rather than trying smarter strategies.
- Teaching “skills” helped a little but not enough: Giving agents a guide with best practices improved efficiency and success on easier tasks, but it didn’t solve the core issue on hard tasks: learning when to change the hypothesis, add a planet, or rethink the model.
Why does this matter?
If we want AI to be real scientific helpers, they must do more than fit curves—they must discover the correct explanation behind the data. Stargazer shows:
- Today’s AI agents can optimize numbers but often miss the real physics.
- Better strategies are needed, especially ones that notice when the current idea is wrong and then try a deeper, more complex model.
- This testbed can help researchers train and evaluate smarter agents, not just for astronomy, but for any science where you must fit models to data and interpret what those fits mean (like climate science, biology, or materials science).
In short, Stargazer is a realistic playground for building the next generation of AI “scientists” who can both match the data and correctly understand the universe behind it.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, organized by theme to guide future research.
Environment realism and data generation
- Incomplete specification and validation of stellar activity and correlated noise: the simulator mentions “correlated noise processes” but does not detail kernels (e.g., quasi-periodic GPs for rotation), timescale priors, or amplitude distributions; no evidence that the simulated activity reproduces the alias structure and non-stationarity of real RVs.
- Missing per-instrument “jitter” terms in grading and possibly in simulation: real RV analyses routinely include per-instrument excess noise parameters; the evaluator’s RMS threshold uses reported measurement uncertainties only, potentially penalizing valid fits on real data or encouraging overfitting.
- Unclear astrophysical realism of parameter priors: the paper does not document sampling distributions for periods, eccentricities, masses/semimajor axes, inclinations, multiplicities, and resonances versus occurrence-rate constraints; risk of distribution shift between synthetic suite and real RV populations.
- Ambiguity about N-body prevalence and its impact: tasks can include N-body interactions, but the fraction, strength of interactions, and their consequences for detectability and fitting are not quantified; the evaluator still matches via Keplerian components, which may be ill-posed when interactions are non-negligible.
- Limited observing-cadence realism: while “irregular” sampling is used, it is unclear if seasonal visibility gaps, instrument downtime, and heterogeneous baselines are faithfully modeled; these materially affect aliasing and period recoverability.
Tooling and fairness for complex noise/physics
- Tool-stack mismatch for realistic modeling: agents operate with a generic Python REPL but may lack domain tools (e.g., Gaussian-process RV modeling, exoplanet/PyMC, RadVel with jitter, The Joker, rebound-driven N-body fitting). It remains unclear whether failures, especially on real data, stem from missing tools rather than reasoning.
- No evaluation of agents equipped with state-of-the-art RV packages: stronger non-LLM baselines (e.g., GP + nested sampling, multi-planet model comparison pipelines) and agents scaffolded with these tools are not tested, leaving the achievable upper bound under realistic modeling unknown.
Evaluation protocol and metrics
- Fixed-count requirement may penalize plausible alternatives: ok_count demands exact planet number equality, even when multiple models explain the data similarly (common in low-SNR or alias-prone regimes). A graded count metric or Bayes-factor-based evaluation across models is not explored.
- Sensitivity of the matching metric is under-explored: while match-threshold sensitivity is shown, the hand-tuned distance weights (e.g., 4.0 for RV-curve RMS, 1.0 for log-period) and rejection cutoff (d>5) lack a systematic sensitivity study, especially near resonances and strong aliasing.
- Lack of uncertainty quantification assessment: the benchmark grades only point estimates (RMS, ΔBIC vs null, match, count). Scientific workflows require calibrated posteriors, credible intervals, and robust evidence-based model comparison; none are evaluated or required.
- ΔBIC baseline against a flat model only: requiring ΔBIC/N>0 versus the null does not directly penalize over-complexity; joint consideration of ΔBIC between n and n±1 planet models (or Bayes factors) is not used in grading, placing more burden on the ok_count gate.
- Potential misalignment between simulator noise and grader thresholds: the RMS gate uses the median reported uncertainty; if simulation or real-data tasks include unmodeled systematics, the pass/fail boundary may not reflect realistic detectability limits.
Real-data subset and sim-to-real transfer
- Small and opaque real-data set: only 20 archival systems are included; selection criteria, instrument mix, activity levels, and difficulty composition are not detailed, limiting diagnosis of the 0% pass rate and hampering generalization claims.
- Missing per-system error analysis: the paper notes overestimated semi-amplitudes in near-misses but does not provide a systematic breakdown by failure mode (aliases, jitter, cadence, multiplicity) or by difficulty drivers on real systems.
- No demonstration that a modern human-grade pipeline passes the benchmark’s grader: while RadVel refits match literature values, there is no end-to-end verification that a contemporary GP + nested sampling pipeline would pass ok_rms/ok_ΔBIC/ok_match/ok_count under the same evaluator, leaving the grading criteria on real data uncalibrated.
- Sim-to-real transfer strategies untested: suggested curricula, physics-grounded data mixtures, or RL fine-tuning on synthetic tasks are not experimentally evaluated for transfer gains to the real subset.
Agent learning, search, and compute scaling
- No training-time experiments: agents are only evaluated; whether RL, self-play, or curriculum learning in Stargazer closes the statistical–physical gap is not tested.
- Insufficient compute–performance scaling analysis: budgets are fixed at ~3× median costs from pilots; the paper shows that more tokens do not help in failure loops but does not produce systematic performance curves versus budget or step caps (especially on Medium/Hard).
- Lack of trajectory-level reasoning diagnostics: beyond case studies, there is no quantitative metric for hypothesis revision, model-complexity escalation, or exploration coverage over the model space, making it hard to benchmark improvements in scientific reasoning strategies.
Task difficulty and identifiability
- Identifiability filtering is described but not deeply audited: criteria that determine “physically non-identifiable” tasks are not disclosed in detail; no public audit of borderline tasks (e.g., near-commensurate periods with short baselines) to ensure uniqueness of the “ground truth” within realistic uncertainty.
- Hard-tier aliasing and resonance edge cases: while desirable for challenge, it is unclear when alternate alias solutions achieve comparable fits; the current evaluator may strictly penalize these, despite scientific ambiguity.
Scope and extensibility
- RV-only focus: modern exoplanet characterization integrates photometry (transits), activity indicators (e.g., BIS, S-index), and astrometry; the environment does not include multimodal data or cross-instrument activity proxies needed to disentangle planets from stellar signals.
- No cross-domain validation: the paper claims the methodology “presumably generalizes” to other model-fitting problems but provides no instantiation in another field (e.g., spectroscopy line-fitting, gravitational lens modeling), leaving external validity untested.
- Lack of leaderboard and anti-overfitting protocol: while seeds allow infinite generation, best practices for held-out suites, versioning, and train/dev/test splits for agent training are not specified.
Reproducibility and transparency details
- Incomplete disclosure of simulator hyperparameters: key priors (e.g., eccentricity, period, SNR distributions), noise-kernel forms, and N-body configuration sampling are not enumerated, complicating reproducibility and external replication.
- Feedback signals and “hints” are underspecified: the content, granularity, and consistency of post-submission hints are not detailed or ablated, making it unclear how much implicit supervision the environment provides and whether it biases agent strategies.
These gaps suggest concrete avenues for future work: augment the simulator with realistic activity/jitter and cadence models; integrate and grade GP/N-body fits; introduce graded count and uncertainty-aware metrics; expand and document the real-data suite; evaluate trained agents and stronger baselines; and extend the framework to multimodal, cross-domain settings.
Practical Applications
Immediate Applications
Below are concrete, near-term uses that can be deployed with today’s tools and the released Stargazer codebase and data.
- Academia (Astronomy) — Teaching and training module for RV analysis:
- Use Stargazer’s end-to-end “periodogram → Keplerian fit → model selection → submission” workflow in undergraduate/graduate labs to teach practical exoplanet detection and characterization.
- Tools/workflow: Jupyter labs leveraging the provided PythonREPL flow, Rebound for dynamics, and the four-criterion evaluator (RMS, ΔBIC, Match, Count).
- Assumptions/dependencies: Python environment with scientific stack; instructors align grading with Stargazer’s thresholds.
- Academia (Astronomy) — Benchmarking and regression testing of RV pipelines:
- Stress test in-house RV analysis codes across controlled difficulty factors (SNR, multiplicity, resonances, cadence, correlated noise) to identify failure modes before analyzing new telescope data.
- Tools/workflow: Seeded synthetic tasks for reproducible comparisons; conversion scripts for anonymized archival data.
- Assumptions/dependencies: Willingness to adopt BIC- and match-based gating; stable compute and code-exec environment.
- Software/AI (Agent frameworks) — CI “agentic model-fitting” test suite:
- Integrate Stargazer into continuous integration to catch regressions in tool-use, code execution, and reasoning policies (e.g., loop detection, over-budget runs).
- Tools/workflow: ReAct-style loop with PythonREPL and submit_action; budget constraints and stop conditions; diagnostics per criterion.
- Assumptions/dependencies: Sandbox for safe code execution; token/time budgets configured.
- Software/AI (Evaluation) — Multi-criteria scoring for scientific agents:
- Adopt the four-criterion rubric (fit and physics) as a template to evaluate agent outputs in other scientific data tasks where “good fit ≠ correct physics.”
- Tools/workflow: Hungarian matching–style physical recovery scoring adapted to target domain.
- Assumptions/dependencies: Existence of interpretable physical/structural parameters and a forward model.
- Academia/Industry (Observatories and instrument teams) — Pre-deployment scenario testing:
- Simulate observing schedules and noise scenarios to plan cadence strategies that improve planet recoverability; validate that pipelines avoid alias traps and count errors.
- Tools/workflow: Seed-based generation for what-if studies; BIC-gated planet addition; residual periodogram checks.
- Assumptions/dependencies: Representative simulator parameterization; domain expertise to interpret trade-offs.
- Education (Data science and physics curricula) — Concepts of model selection vs. curve fitting:
- Use the statistical–physical dissociation exposed by Stargazer to teach why low residuals do not guarantee correct scientific interpretation.
- Tools/workflow: Classroom exercises comparing solutions that pass RMS/ΔBIC but fail Match/Count.
- Assumptions/dependencies: Access to the benchmark and minimal domain primer on RV methods.
- Open Science (Competitions/leaderboards) — Reproducible challenges:
- Host Kaggle-style challenges with seeded task generation to avoid saturation and ensure comparability over time.
- Tools/workflow: Public seeds and evaluator; Pass@k metrics and tiered budgets.
- Assumptions/dependencies: Community governance of task rotation and anti-overfitting practices.
- Space/Aerospace & Remote Sensing (Time-series analytics) — Adapted gating for physics-constrained fits:
- Apply the “fit + physical recovery” pattern to telemetry/anomaly models that have underlying physics (e.g., orbital dynamics, thermal models), catching plausible-but-wrong fits.
- Tools/workflow: Domain-specific forward models; parameter matching thresholds.
- Assumptions/dependencies: Availability of validated forward models and tolerance thresholds.
- LLM/Agent Development (Efficiency tuning) — Skills injection for workflow compression:
- Use self-generated skills documents to reduce token/time usage on simpler tasks and increase episode completion within budgets.
- Tools/workflow: skills.md extracted from successful trajectories; ablation studies on budget usage.
- Assumptions/dependencies: Gains mostly in efficiency, not hard-case reasoning; risk of over-templating.
- Risk/Compliance (R&D governance) — Evaluation protocols that penalize over-parameterization:
- Adopt ΔBIC per-point and explicit planet-count checks (or domain analogs) to discourage overfitting in internal AI-science evaluations and grant reviews.
- Tools/workflow: Standardized reporting of both statistical and physical metrics.
- Assumptions/dependencies: Consensus on thresholds; transparency of model degrees of freedom.
Long-Term Applications
These opportunities require further research, scaling, or engineering to overcome the current “statistical fit vs. physical recovery” gap and the sim-to-real transfer challenges.
- Astronomy (Autonomous exoplanet researchers) — Agent-assisted discovery and follow-up planning:
- End-to-end agents that propose candidate planetary systems, quantify uncertainties, and recommend additional observations to break aliases and confirm signals.
- Tools/products: Hybrid pipeline combining classical optimization/nested sampling with agentic hypothesis search; telescope scheduling integration.
- Assumptions/dependencies: Robust multi-planet recovery on real data; validated treatment of stellar activity and multi-instrument systematics; human-in-the-loop oversight.
- Software/AI (Benchmarks-as-a-Service) — Domain-portable “agentic model-fitting gyms”:
- Commercial platforms offering curated, simulation-driven, feedback-rich environments for physics/structure-constrained model fitting across disciplines (astronomy, materials, climate, robotics).
- Tools/products: Task generators, evaluators, budget policies, and dashboards; API for custom forward models.
- Assumptions/dependencies: High-quality simulators and realistic noise models per domain; customer data governance.
- Policy & Standards (Certification of scientific AI) — Multi-criteria validation frameworks:
- Regulatory-style checklists and certification that require physical plausibility recovery (not just goodness-of-fit) before deployment in science-heavy sectors.
- Tools/workflow: Standardized match metrics, count checks, and robustness audits; sim-to-real validation protocols.
- Assumptions/dependencies: Community consensus on domain metrics; auditing infrastructure.
- Cross-Disciplinary Science (Generalized method) — Simulation-driven agent training for model-based inference:
- Extend Stargazer’s methodology to other model-fitting problems:
- Healthcare: PK/PD parameter inference from patient time series.
- Energy: Grid or building dynamics identification with demand response planning.
- Robotics: Online system identification with multi-criteria guards.
- Climate/Earth science: Parameter estimation in simplified climate/transport models.
- Tools/products: Domain-specific forward simulators, parameter matching rules, and pass/fail gates.
- Assumptions/dependencies: Scientifically credible forward models; labeled or semi-synthetic ground truth; domain expert thresholds.
- AI Research (Reasoning architectures) — Agents that revise hypotheses, not just optimize:
- Develop agent policies that treat diagnostic mismatches (e.g., pass RMS, fail Match) as triggers for model-complexity escalation and hypothesis revision.
- Tools/workflow: Physics-informed reward shaping for RL, curricula that emphasize sim-to-real transfer, and memory structures for hypothesis graphs.
- Assumptions/dependencies: Stable training signals; avoidance of reward hacking; compute for multi-episode training.
- Observatory Operations (Closed-loop experiment design) — Adaptive scheduling guided by uncertainty and alias risk:
- Agents propose observational cadences that maximize information gain for ambiguous systems (e.g., near-resonant chains) detected in RVs.
- Tools/workflow: Bayesian design or active learning on top of the evaluator; simulation-informed priors.
- Assumptions/dependencies: Accurate uncertainty modeling; observation cost constraints; human vetting.
- Hybrid Pipelines (Classical × LLM) — Division of labor between numeric solvers and reasoning agents:
- Classical methods handle local optimization; agents manage model selection, residual diagnostics, and escalation (e.g., adding planets, switching noise models).
- Tools/products: Orchestrators that coordinate solvers and agents, with guardrails to prevent compute spirals.
- Assumptions/dependencies: Reliable interfaces, error recovery, and deterministic baselines.
- Developer Tools (IDE/Notebook plugins) — Scientific guardrails for code-first workflows:
- Plugins that auto-grade fits against statistical and physical criteria during exploratory analysis, flagging alias-like solutions and count mismatches.
- Tools/products: Lightweight evaluators; visualization widgets; “explain-why-failed” diagnostics.
- Assumptions/dependencies: Domain configuration and thresholds; user adoption in research labs.
- Consumer/Daily Life (Interpretability-first personal analytics) — Plausibility-aware assistants:
- Long-term, consumer data assistants (e.g., wearables, home energy) that fit interpretable models while enforcing plausible parameter ranges and structure.
- Tools/products: Domain-specific forward models (e.g., human physiology, appliance dynamics) with match-like plausibility scoring.
- Assumptions/dependencies: Trustworthy models for personal data; UX for communicating plausibility vs. fit; privacy safeguards.
- Safety & Cost Control (Agent operations) — Budget-aware governance for autonomous tools:
- Standardize token/time budgeting, loop detection, and “best-submission” selection to prevent runaway costs in autonomous scientific agents.
- Tools/workflow: Monitoring, anomaly detection for recursive failure loops, and automatic de-escalation strategies.
- Assumptions/dependencies: Telemetry hooks from model providers; organizational policies on compute governance.
Glossary
- Aliasing: Spurious frequency content arising from sampling or interacting signals, causing peaks at incorrect periods that can mislead detection. "producing alias peaks and combination frequencies in the periodogram"
- Argument of periastron: The angular position of the orbit’s closest approach point relative to a reference direction within the orbital plane. "Each planetary system is parameterized by orbital period, eccentricity, argument of periastron, and orbital phase"
- Bayesian Information Criterion (BIC): A model selection metric that balances goodness of fit with model complexity; lower BIC indicates a preferred model. "The BIC is computed as "
- Correlated noise processes: Noise with temporal (or structured) correlations rather than independent random fluctuations, complicating inference. "Gaussian observational uncertainty and correlated noise processes."
- Eccentricity: A parameter describing how non-circular an orbit is (0 for circular, approaching 1 for highly elongated). "Each planetary system is parameterized by orbital period, eccentricity, argument of periastron, and orbital phase"
- Forward modeling: Simulating observed data from proposed model parameters to compare against measurements. "The evaluator reconstructs the RV curve from the agent's submitted parameters via forward modeling"
- Gaussian observational uncertainty: Measurement noise modeled as Gaussian-distributed errors on observations. "Measurement noise and stellar activity are incorporated through Gaussian observational uncertainty and correlated noise processes."
- Hungarian algorithm: A polynomial-time algorithm for solving the assignment problem by finding a minimum-cost matching. "Submitted planets are matched to truth planets via the Hungarian algorithm~\citep{kuhn1955hungarian,budavari2016assignment,hopkins2015sourcefinding}"
- Keplerian elements: The set of parameters (e.g., period, eccentricity, etc.) defining a Keplerian orbit under two-body dynamics. "five Keplerian elements per planet"
- Keplerian orbital dynamics: Motion governed by Newtonian two-body gravitational laws, producing elliptical orbits. "The stellar reflex motion is modeled using Keplerian orbital dynamics"
- Lomb-Scargle periodogram: A spectral analysis method for detecting periodic signals in unevenly sampled time series. "The Classical Pipeline chains Lomb-Scargle periodogram search"
- Match score: A quantitative measure of agreement between submitted and ground-truth planetary signals after optimal pairing. "Match Score remains at 0%"
- Nested sampling: A Bayesian technique for estimating model evidence and performing model comparison by exploring likelihood contours. "The Nested Sampling baseline uses Bayesian model comparison via nested sampling"
- N-body integration: Numerical simulation of gravitational interactions among multiple bodies beyond the two-body approximation. "and can optionally incorporate full -body integrations for multi-planet systems when dynamical interactions become significant."
- Orbital phase: The position of an object along its orbit at a reference time, often expressed as an angle or fraction of the period. "Each planetary system is parameterized by orbital period, eccentricity, argument of periastron, and orbital phase"
- Period coverage: How well the observation timespan and cadence sample the true orbital periods, affecting detectability and accuracy. "resonant configurations, period coverage, observation count, and correlated noise amplitude"
- Planet multiplicity: The number of planets present in a star system. "planet multiplicity, SNR, resonant configurations, period coverage, observation count, and correlated noise amplitude"
- Radial velocity (RV): The component of a star’s velocity along the line of sight, used to infer orbiting planets via periodic Doppler shifts. "Stargazer simulates the problem of exoplanet discovery and characterization from stellar radial velocity (RV) observations."
- ReAct-style loop: An agent control pattern that interleaves reasoning (planning) with actions (tool use) in iterative cycles. "The agent operates in a ReAct-style loop with two tools"
- Rebound: An open-source N-body integrator/library used for simulating gravitational dynamics in multi-body systems. "via Rebound~\citep{rein2012rebound}"
- Resonant configurations: Orbital period ratios near small integers (e.g., 2:1, 3:2) leading to gravitational resonances and complex dynamics. "resonant configurations, period coverage, observation count, and correlated noise amplitude"
- Root-mean-square (RMS) residual: A scalar measure of average deviation between model predictions and observations. "the root-mean-square residual "
- Semi-amplitude (K): The half-amplitude of the star’s radial-velocity signal induced by an orbiting planet; a proxy for planet mass. "but overestimate semi-amplitudes"
- Sim-to-real gap: The discrepancy between performance in simulated environments and in real-world data settings. "Mind the sim-to-real gap."
- Stellar reflex motion: The wobble of a star around the system barycenter due to gravitational pull from orbiting planets. "The stellar reflex motion is modeled using Keplerian orbital dynamics"
- Systemic velocity (offset): A constant velocity term representing the star’s baseline radial velocity (or per-instrument offset). " is the systemic velocity offset of the star"
Collections
Sign up for free to add this paper to one or more collections.