- The paper introduces TeLAPA, a framework that maintains diverse policy neighborhoods to prevent representational collapse and catastrophic interference in continual RL.
- It employs a shared latent behavior space with mechanisms such as anchor sets and replay buffers to robustly align policies across shifting tasks.
- The approach outperforms traditional single-model methods on metrics like success rate and Time-To-Threshold, demonstrating superior recoverability and coverage.
Preserving Plasticity via Policy Neighborhoods in Continual Reinforcement Learning
Introduction
This paper systematically interrogates limitations inherent to the dominant paradigm of continual reinforcement learning (RL): single-model preservation, wherein an agent retains and adapts only one evolving policy across sequential tasks. The authors argue, drawing from empirical, theoretical, and geometric perspectives, that this paradigm induces pronounced loss of plasticity—decreasing the agent’s adaptation capacity as a result of representational collapse and catastrophic interference. They introduce TeLAPA (Transfer-Enabled Latent-Aligned Policy Archives), a framework that departs from point-solution retention by instead maintaining behaviorally diverse, skill-aligned policy neighborhoods in a shared, dynamically maintained latent behavior space. This structure is shown to support robust continual learning, significantly enhancing recoverability on revisited tasks, coverage, and overall performance in non-stationary task streams.
The fundamental instability–plasticity dilemma in sequential neural network training manifests as catastrophic forgetting and, more perniciously, loss of plasticity, where prior success on previous tasks does not guarantee capacity to relearn or adapt after distributional shift or interference. While prior methods address forgetting through regularization, replay, or architectural expansion, most are strongly single-model in nature, tracking only a high-performing parameter vector optimized until convergence, which is acutely vulnerable to drift, dead units, or rank-deficiencies in the loss landscape.
The authors thus position their work in the context of recent advances in Quality-Diversity (QD) optimization, which foregrounds discovering diverse local optima by creating archives of ‘elites’ defined not just by performance but behavioral diversity. Extending from QD, TeLAPA’s library-based approach leverages policy neighborhoods as stepping stones, connecting to ‘policy manifold’ hypotheses where solution sets exist on lower-dimensional structures with significant transfer potential.
TeLAPA: Framework and Implementation
TeLAPA instantiates per-task policy archives using parameter-space MAP-Elites, initialized from competent PPO-trained base agents. Around each converged policy, local mutations are performed, and offspring are selected for archive inclusion based on both task fitness and behavioral diversity in a learned latent space. Across a task sequence, at each new task boundary, TeLAPA retrieves a compact candidate pool by diversity-aware selection from the union of all previous task archives, supporting transfer not just from the most recent, but from any previously encountered task.
Critical to the framework is the establishment and continual maintenance of a shared latent behavioral space: a trajectory encoder processes structured per-episode features (not raw observations), mapping behaviors into a normalized latent geometry. Since task transitions induce encoder drift, TeLAPA employs robust alignment mechanisms at each boundary, including anchor sets, replay buffers, teacher-student distillation, and periodic re-embedding, thus preserving the relative organization necessary for meaningful cross-task retrievals.
Evaluation: Continual RL on MiniGrid
Evaluation centers on a sequence of procedurally generated MiniGrid tasks arranged as a curriculum, including explicit revisits that operationalize plasticity. The main metrics include standardized Time-To-Threshold (TTT), mean success rate (SR), coverage (fraction of tasks learned), normalized backward transfer (nBWT), and threshold retention (TR). Comparative baselines include pure scratch training, parameter regularization (EWC, L2Init), architectural perturbation (DFF), task-policy caching, and ablations that disable TeLAPA's latent space maintenance.
TeLAPA achieves the highest mean SR (0.706±0.08), the lowest TTT ($3.35$M steps), the highest coverage ($0.50$), and the highest threshold retention ($0.25$), outperforming all single-model and archive-ablated baselines. Notably, even when only one policy per task is cached for transfer (scratch-reuse), TeLAPA's advantage persists, demonstrating that it is not simplistic task-indexed storage but the retention of neighborhood structure that affords superior recoverability and adaptation.
Mechanistic Analysis: Policy Neighborhoods versus Single-Model Retention
To dissect the source of TeLAPA’s performance, the authors analyze the local transfer landscape. They demonstrate that source-optimal policies—those with the highest task-specific return—are often suboptimal seeds for transfer on revisits or new tasks, even when compared to nearby, source-competent alternatives within the local latent basin. Quantitatively, in over a third of transfer pairs, the best transfer result comes from an archive member other than the source-task optimum.

Figure 1: Pooled QD structure across runs: task-dependent behaviors show broad support across fitness and normalized novelty dimensions, reflecting the presence of non-redundant policy neighborhoods.
Moreover, the ‘good-enough’ set—source-task elites within 90% of best fitness—occupies a large portion of the candidate latent region, directly contradicting the intuition that task learning collapses the solution to a single parameter vector. Even highly local neighborhoods exhibit substantial spread in transfer utility, indicating that meaningful adaptability is encoded in policy diversity, not just in maximizing performance on prior tasks.
Figure 2: Stepping-stone lineage structure: transfer and reuse patterns confirm non-sequential, multi-archive candidate selection and the role of historical, multi-hop ancestry in enabling transfer.
Archive Geometry: Stepping Stones and Latent Space Structure
TeLAPA’s design facilitates the formation of multi-task, multi-step policy lineages. Empirical analysis of transfer ancestry records reveals non-sequential, multi-archive transfer paths; effective revisits frequently re-enter basins established through earlier historical sequences, rather than directly from the most recently encountered archive. Task archives are shown to form well-separated, but coherent, neighborhoods in the shared behavior space, and successful transfer is associated with occupation of such structured regions—not with maximal global separation.
Figure 3: Lineage utility: transfer candidates whose lineages contain target-relevant historical archives yield consistently higher transfer scores, underscoring the functional value of multi-stage, skill-aligned ancestry.
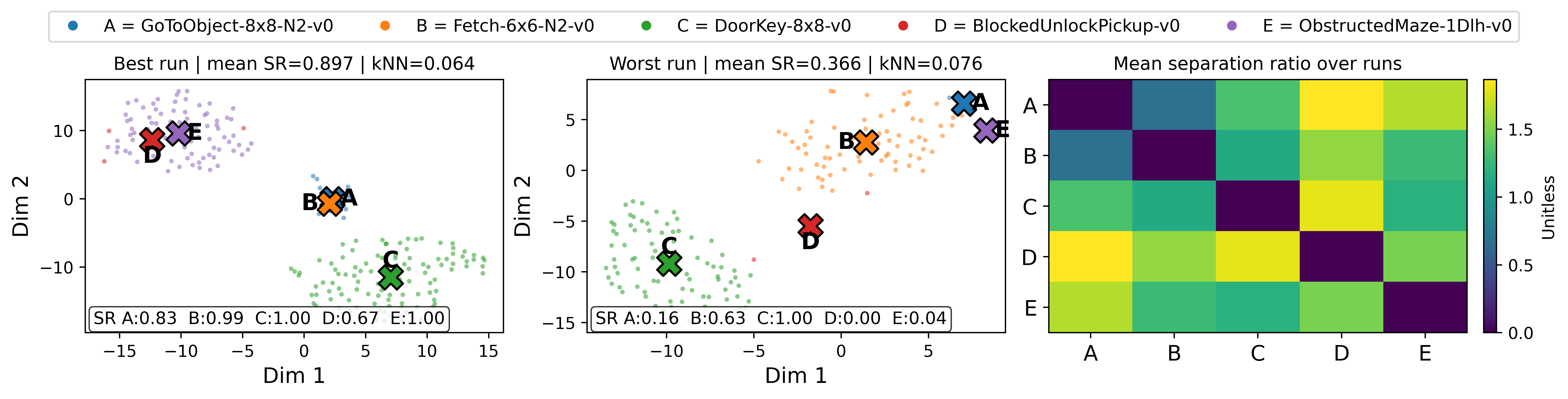
Figure 4: Cross-task geometry in the shared latent space: in successful runs, task archives manifest as compact, well-aligned neighborhoods, while poor runs exhibit fragmented, poorly separated clusters.
Implications and Future Research Directions
This work’s central implication is to reshape the objective of continual RL from perfect retention of a single solution to the maintenance of rich, skill-aligned, and navigable policy neighborhoods. TeLAPA’s framework makes clear that diversity is not a generic asset: only diversity that is organized and preserved relative to a stable latent geometry supports efficient relearning and transfer. Archive-based methods with proper latent maintenance outperform both regularized and task-cached single-model baselines, yielding robust adaptation under severe interference and task drift.
Pragmatically, this finds direct application in long-horizon, open-ended agents where non-stationarity and revisits are the norm, and in multitask/meta-RL where transfer depends crucially on capturing basin structure—not just parameter values. Theoretically, it necessitates reconsidering the role of representation drift, the formal structure of behavioral embedding spaces under continual learning, and the development of archive construction and maintenance mechanisms that maximize transfer utility.
Future advances will require: (1) extending the archive/latent space approach beyond discrete-task curricula to open-ended and environment-changing streams, (2) formal optimization of archive selection regarding transferability criteria, (3) direct integration of latent space maintenance into policy optimization, and (4) scaling policy archive frameworks to domains with higher-dimensional observations and actions.
Conclusion
The presented results establish that single-model preservation induces structural brittleness and loss of plasticity in continual RL. Preserving behaviorally structured, dynamically maintained policy neighborhoods—including explicit maintenance of latent behavioral alignments—is a quantitatively and functionally superior strategy. TeLAPA’s explicit organization and navigation of skill archives constitutes an actionable blueprint for constructing truly lifelong, continually adaptive agents (2604.15414).