- The paper presents a unified world model (ScaleZero) that leverages a Mixture-of-Experts backbone and Dynamic Parameter Scaling to overcome plasticity collapse in multi-task reinforcement learning.
- It employs innovative architectural interventions and quantitative metrics to diagnose and mitigate representational bottlenecks and gradient conflicts in shared-parameter models.
- Empirical results across benchmarks like Atari, DeepMind Control Suite, and text-based games demonstrate robust generalization and enhanced sample efficiency.
Unified World Models for Heterogeneous Multi-Task Planning: ScaleZero and Dynamic Parameter Scaling
Introduction and Motivation
The paper addresses the challenge of constructing a single, unified world model capable of efficient planning and learning across highly heterogeneous multi-task reinforcement learning (MTRL) environments. While prior work has demonstrated the efficacy of unified architectures such as UniZero in single-task domains, scaling these models to diverse multi-task settings exposes critical limitations: representational bottlenecks, plasticity collapse, and gradient conflicts. The authors diagnose these phenomena and propose architectural and training innovations—most notably, the Mixture-of-Experts (MoE) backbone (ScaleZero) and an online Dynamic Parameter Scaling (DPS) strategy—to overcome these obstacles.
Diagnosing Plasticity Collapse in Multi-Task World Models
The empirical analysis reveals that shared-parameter models like UniZero suffer catastrophic performance collapse on complex tasks when trained jointly on diverse environments. This collapse is tightly correlated with a spike in the dormant neuron ratio and uncontrolled inflation of the latent state norm in the Transformer backbone, indicating a loss of network plasticity and representational capacity.
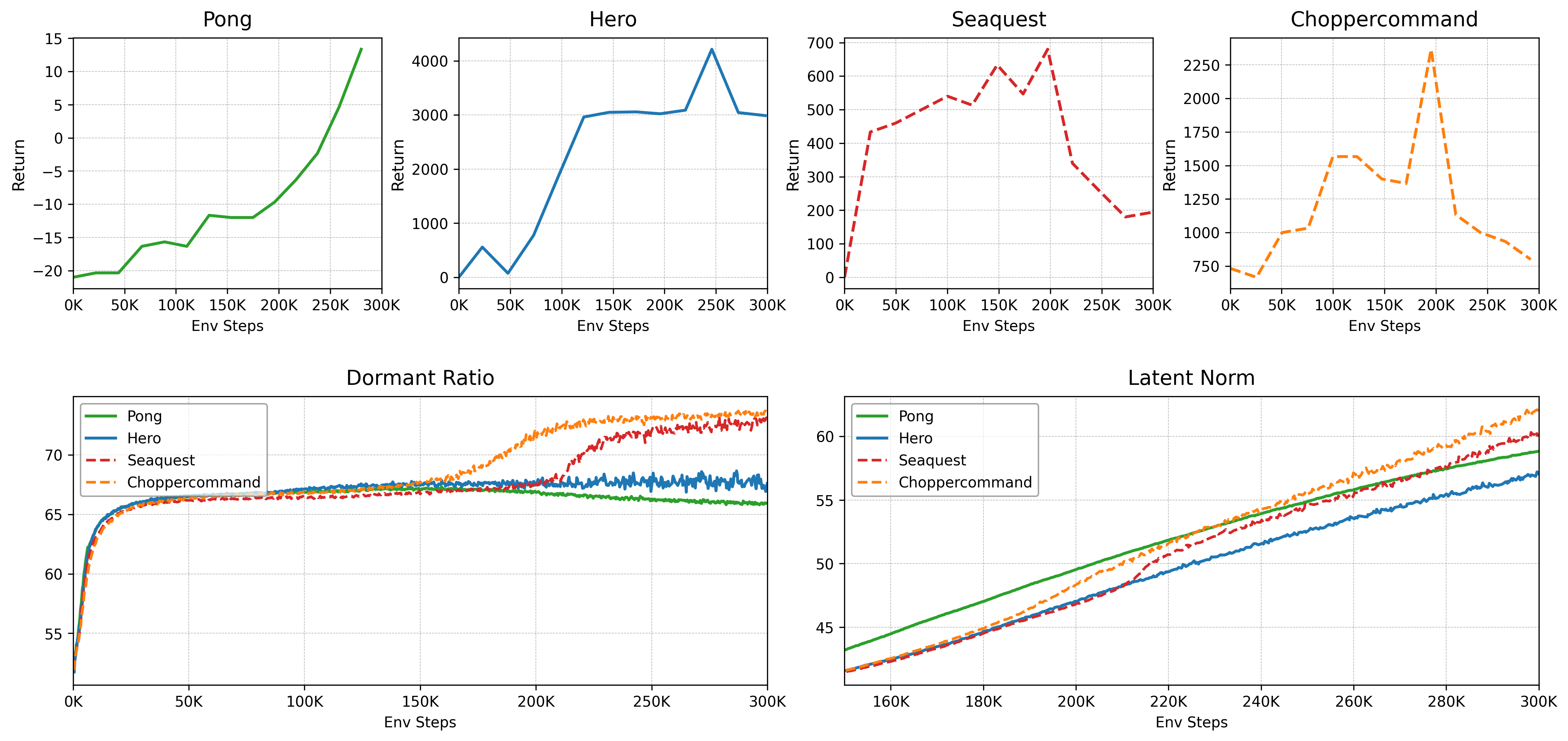
Figure 1: Diagnosing plasticity collapse in the baseline UniZero model on a multi-task Atari benchmark. Performance collapse on complex tasks is linked to dormant neuron ratio and latent norm inflation.
The authors introduce quantitative metrics—dormant neuron ratio and latent state norm—to track the internal dynamics of the model. The analysis demonstrates that gradient dominance from simpler tasks suppresses learning signals for harder tasks, leading to representational interference and a frozen, non-adaptive state.
Architectural Exploration: The ScaleZero Model
A systematic ablation study across five design axes (task conditioning, encoder architecture, latent normalization, backbone, and optimization) identifies the MoE backbone as the most effective intervention for mitigating plasticity collapse and gradient conflict.
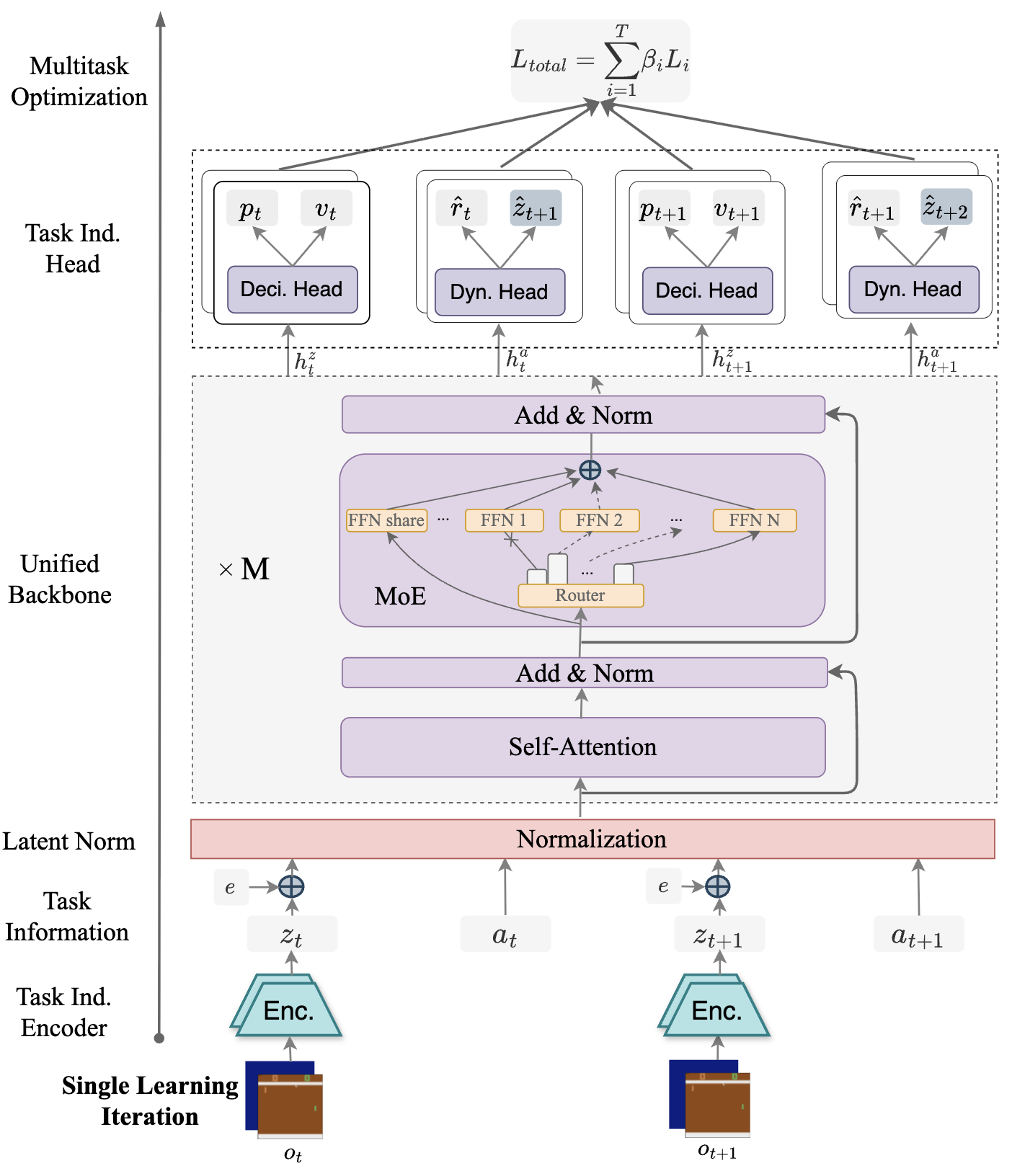
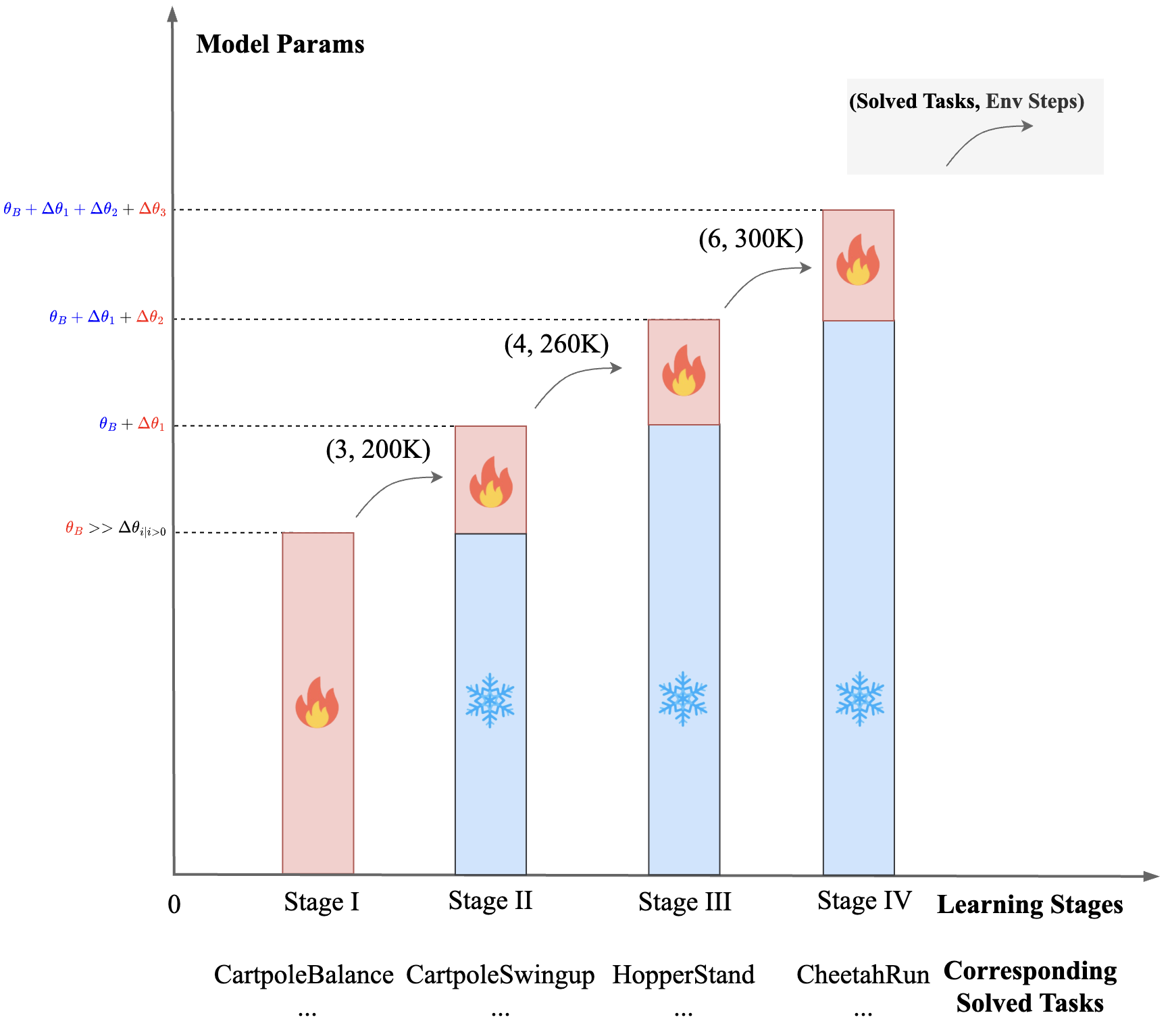
Figure 2: Design space of UniZero for multitask learning and conceptual diagram of Dynamic Parameter Scaling (DPS).
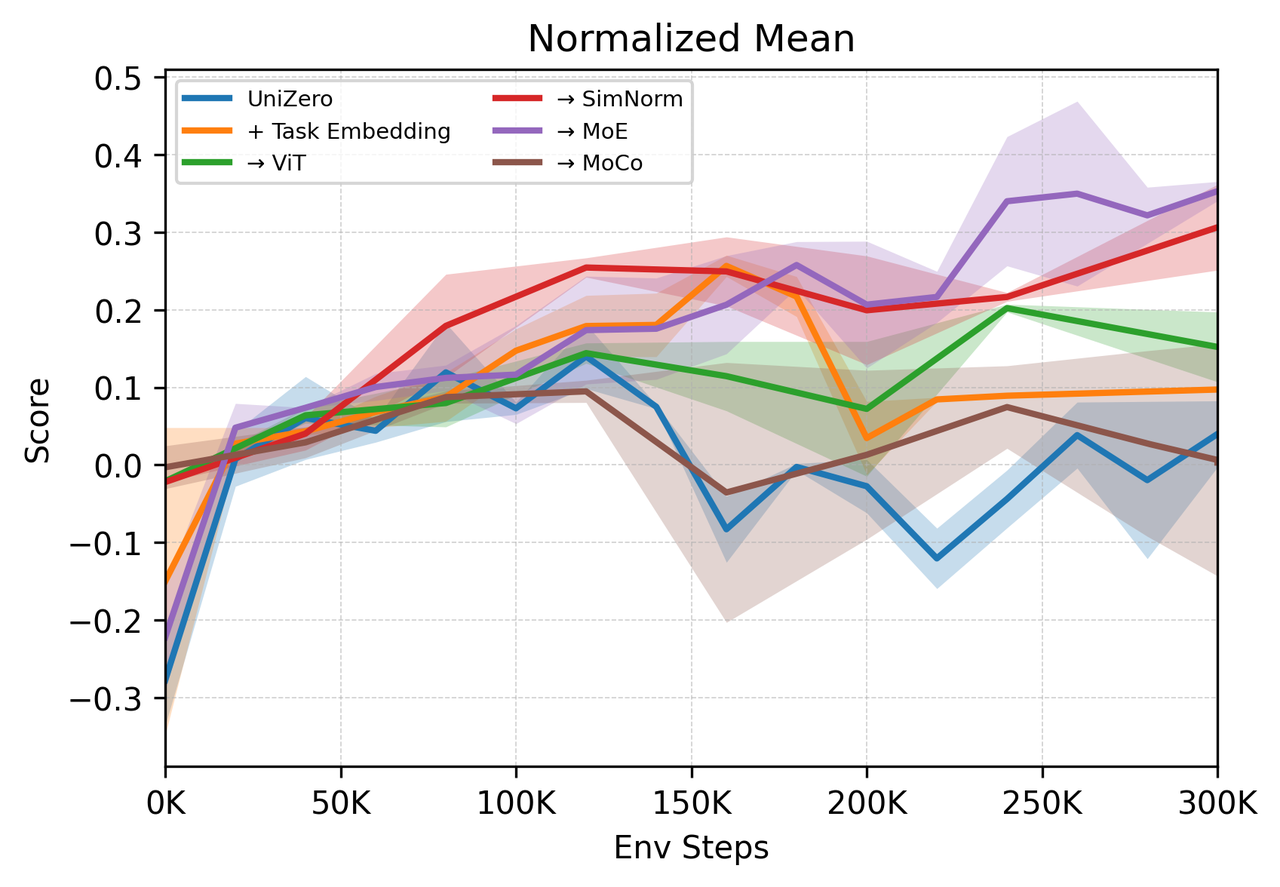
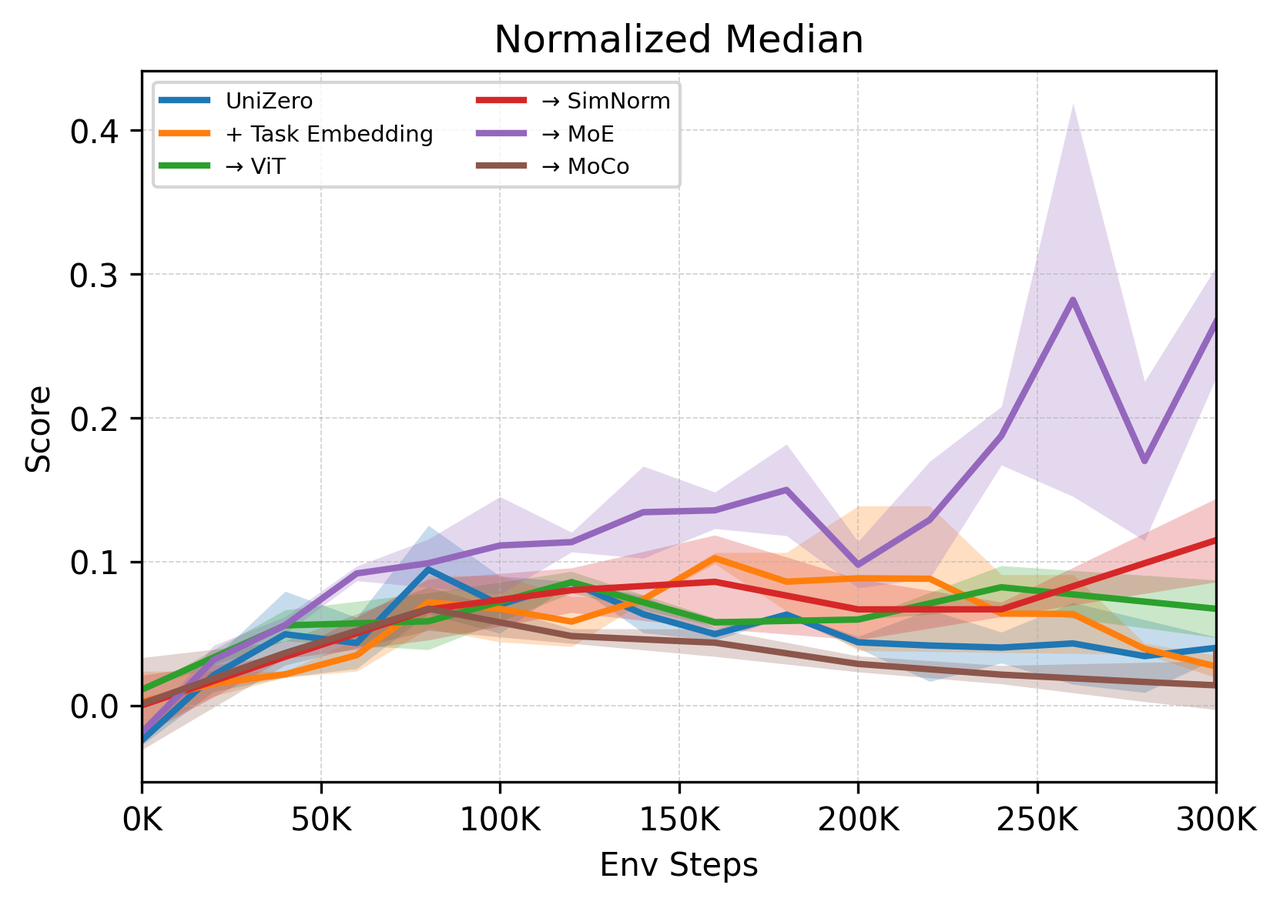
Figure 3: Performance impact of architectural modifications on the Atari8 multi-task benchmark. MoE backbone yields the most significant and consistent gains.
Explicit task conditioning via learnable embeddings accelerates convergence on simple tasks but fails to resolve deep representational conflicts. Encoder choice (ResNet vs. ViT) is less critical in small-scale benchmarks but is expected to matter in larger, more heterogeneous settings. SimNorm stabilizes latent norm inflation but constrains expressivity. The MoE backbone, by routing inputs through specialized expert networks, decouples representational pathways and reduces destructive gradient interference.
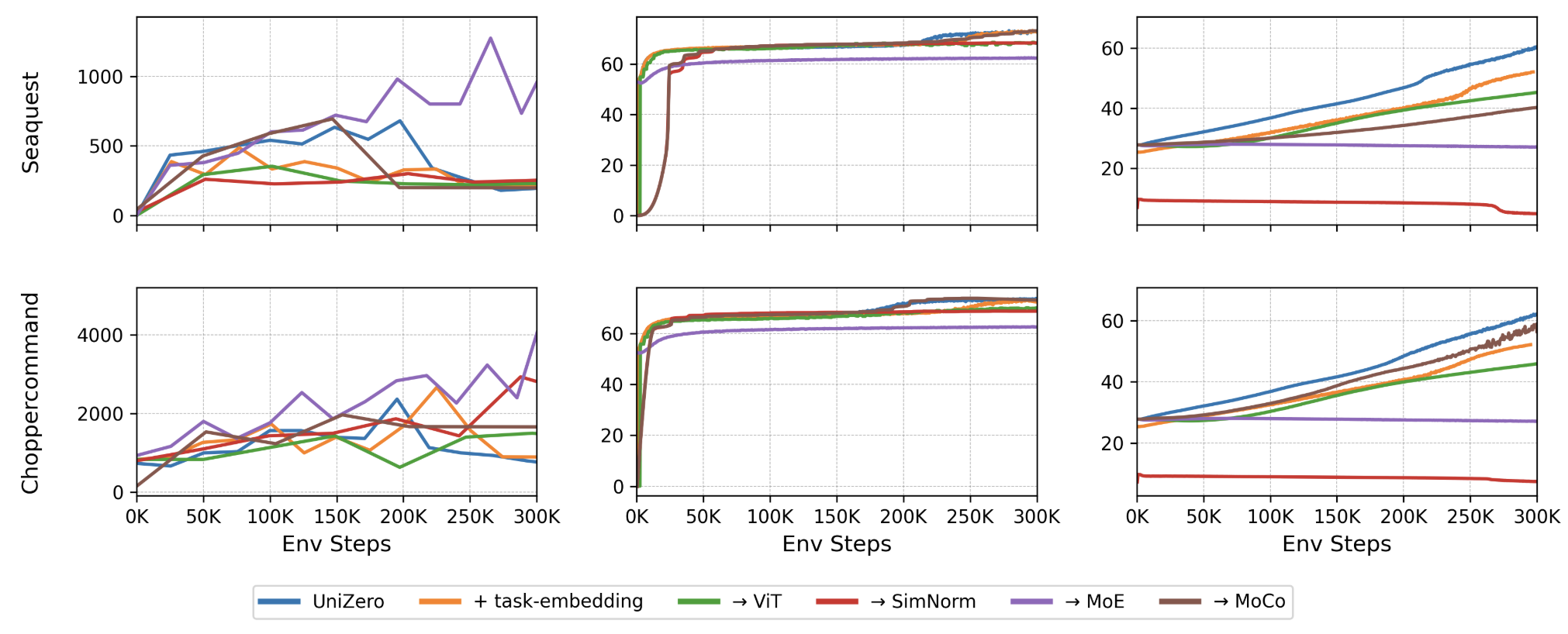
Figure 4: Detailed analysis correlating performance with plasticity metrics across model variants. MoE backbone maintains low dormant ratio and stable latent norm on hard tasks.
The final ScaleZero architecture integrates a ViT encoder, MoE backbone, and standard LayerNorm, achieving robust generalization and plasticity across diverse tasks.
Dynamic Parameter Scaling: Efficient Resource Allocation
Static resource allocation in conventional architectures leads to inefficiency, as computational effort is wasted on already-mastered tasks. The DPS strategy dynamically expands model capacity by injecting LoRA adapters in response to task-specific progress, freezing previously trained parameters to preserve knowledge and direct plasticity toward unsolved tasks.
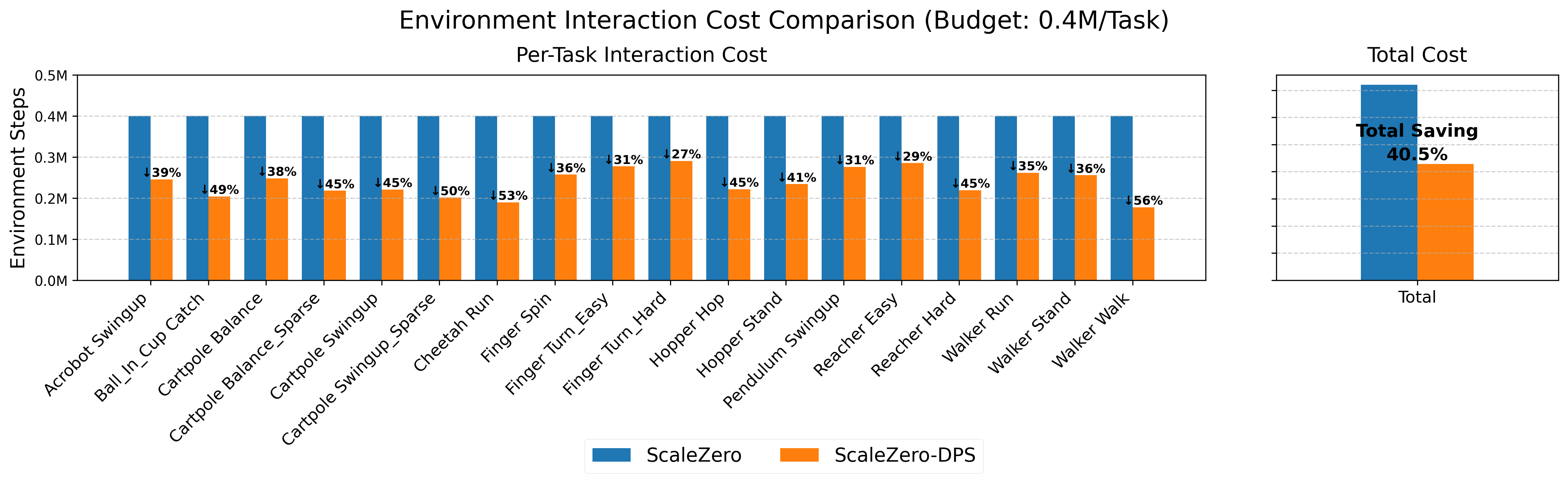
Figure 5: Comparison of interaction cost for ScaleZero vs. ScaleZero-DPS on DMC18. ScaleZero-DPS reaches target performance with ~80% of the interaction steps.
DPS is implemented as a staged curriculum, where new LoRA modules are introduced when a quota of tasks is solved or a budget threshold is reached. Only the newly added parameters and scaling factors are optimized in each stage, isolating updates and preventing negative transfer.
Atari 100k Benchmark
ScaleZero matches or surpasses the mean human-normalized score of 26 independently trained UniZero single-task models, demonstrating positive knowledge transfer and robust generalization. The multitask model achieves higher scores on challenging tasks, leveraging shared priors learned from simpler environments.
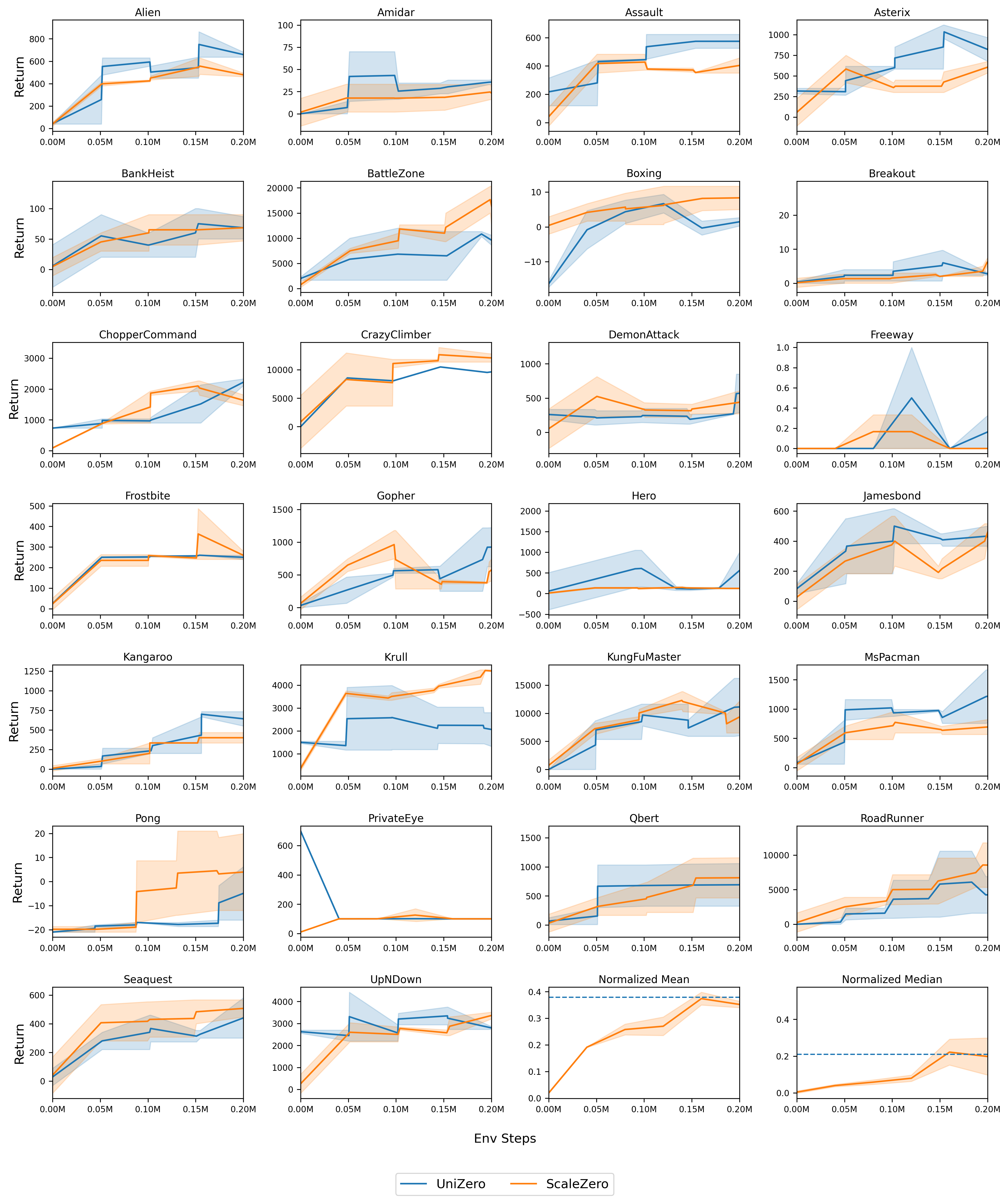
Figure 6: Performance comparison between ScaleZero (MT) and UniZero (ST) on the Atari26 benchmark.
DeepMind Control Suite
On 18 continuous control tasks, ScaleZero achieves returns comparable to or exceeding single-task baselines, validating its applicability to high-dimensional, continuous domains.
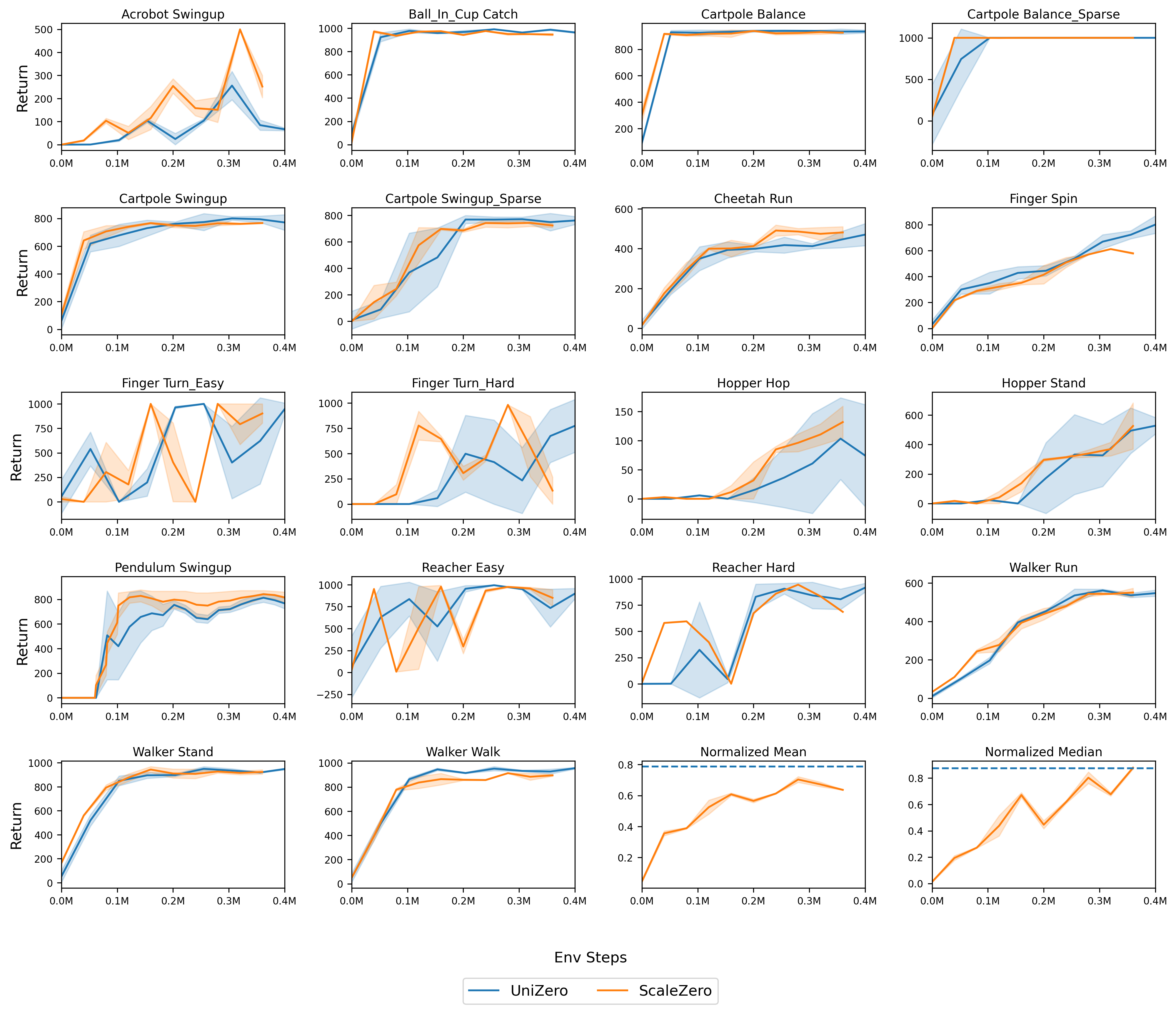
Figure 7: Learning curves of ScaleZero (MT) vs. UniZero (ST) on the DMC18 benchmark.
Jericho Text-Based Games
ScaleZero attains returns on par with single-task UniZero and outperforms LM-in-the-loop baselines on most text-based tasks, indicating effective language understanding and planning in combinatorial action spaces.
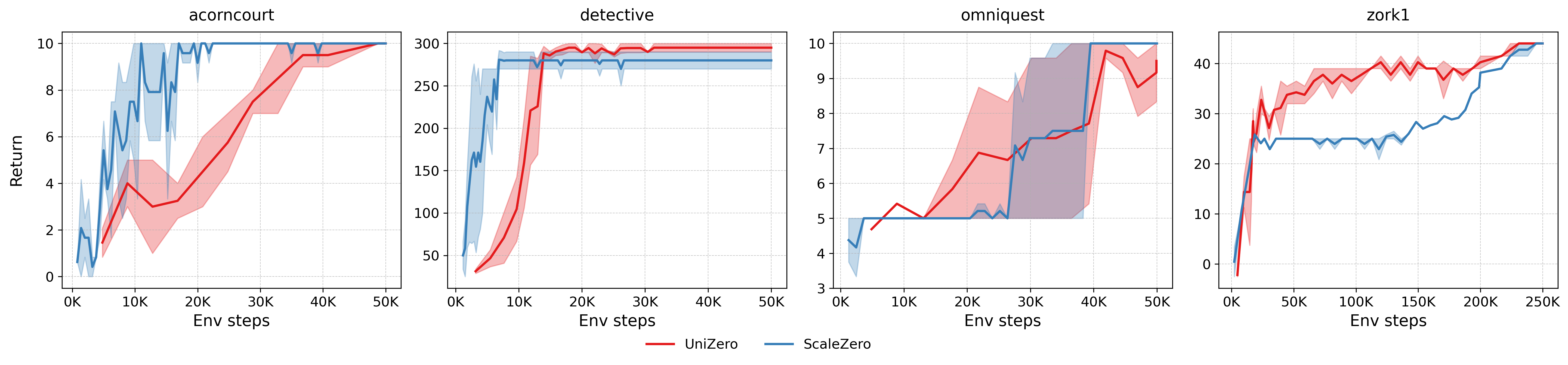
Figure 8: Learning curves of ScaleZero (MT) vs. UniZero (ST) on the Jericho benchmark.
Sample and Computational Efficiency
ScaleZero-DPS achieves target performance with only 80% of the environment interaction steps required by standard ScaleZero, demonstrating substantial gains in sample efficiency.
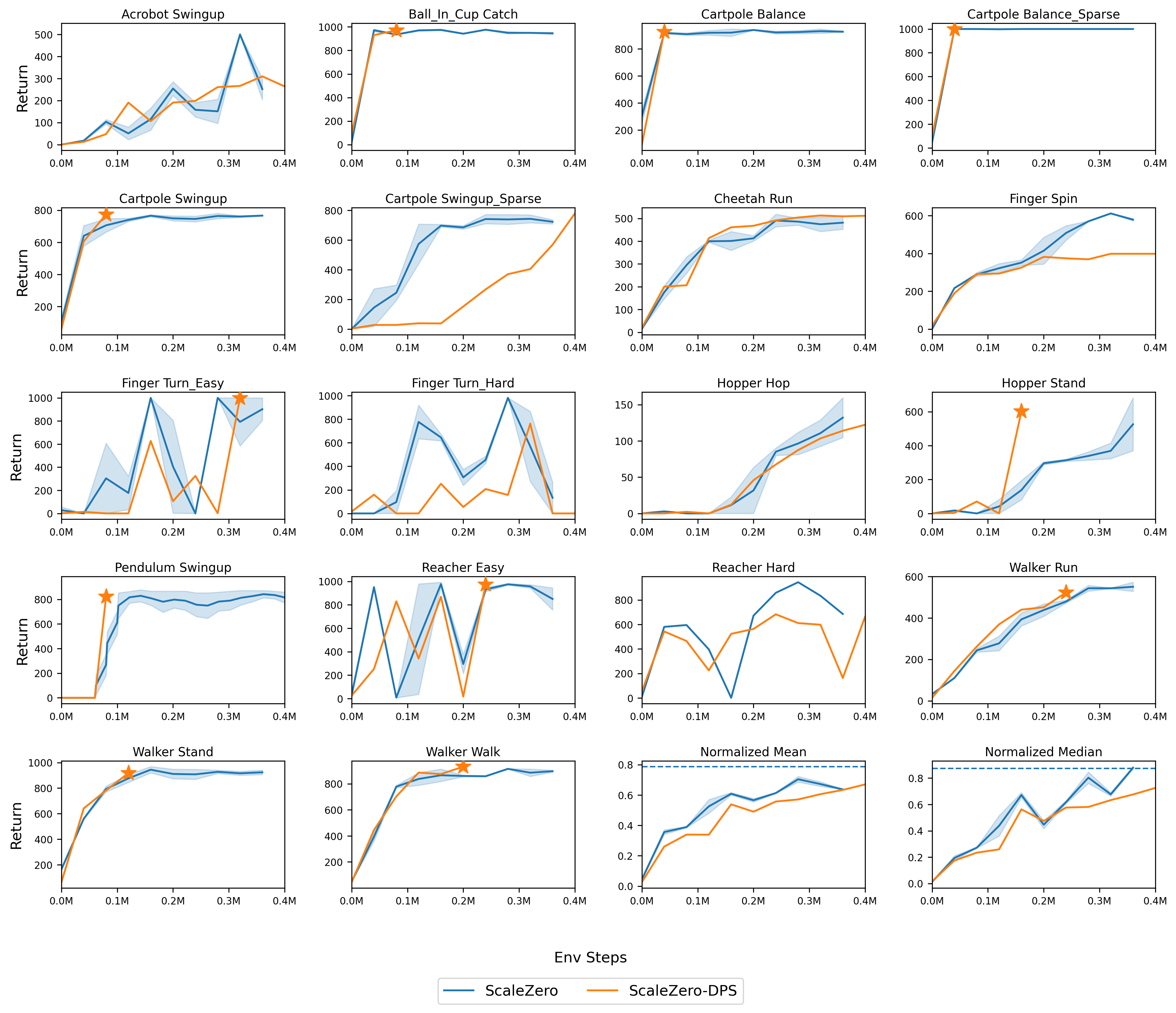
Figure 9: Performance and efficiency comparison of ScaleZero-DPS vs. standard ScaleZero on DMC18.
Mechanistic Analysis: MoE Efficacy and Gradient Conflict
Empirical and theoretical analyses confirm that MoE architectures reduce gradient conflicts both within expert layers and at their inputs. The gating network in MoE enables specialization, routing conflicting tasks to distinct experts and minimizing destructive interference.
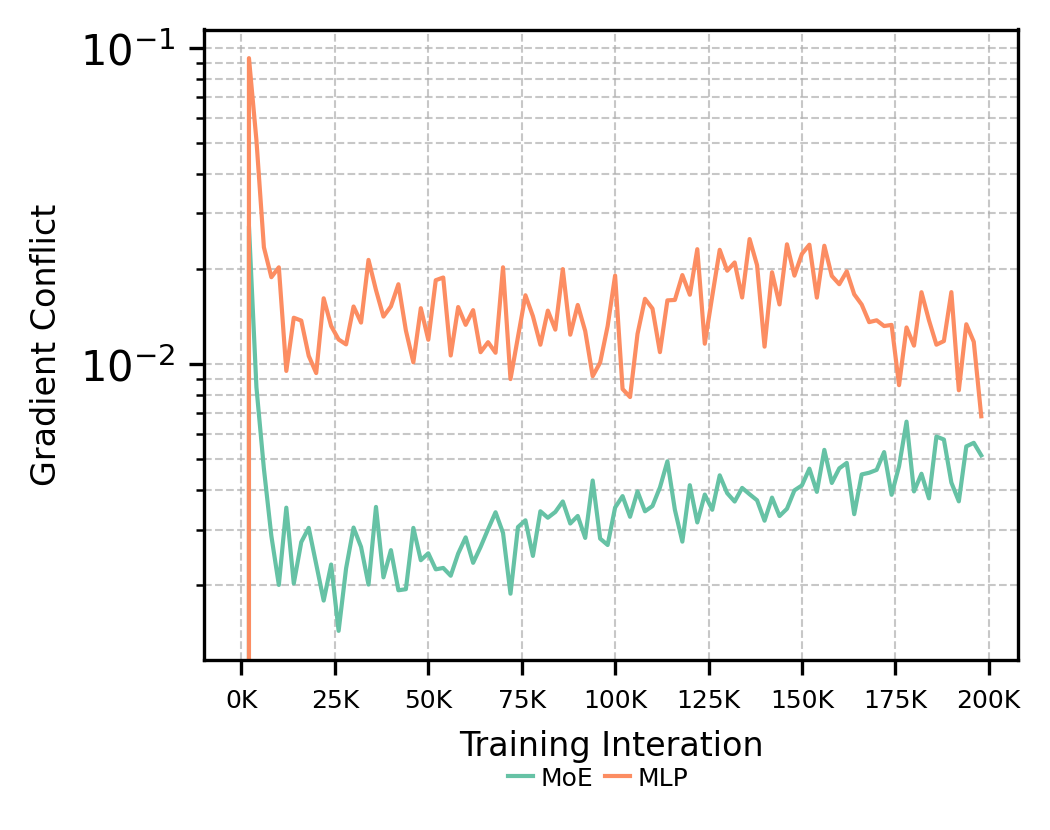
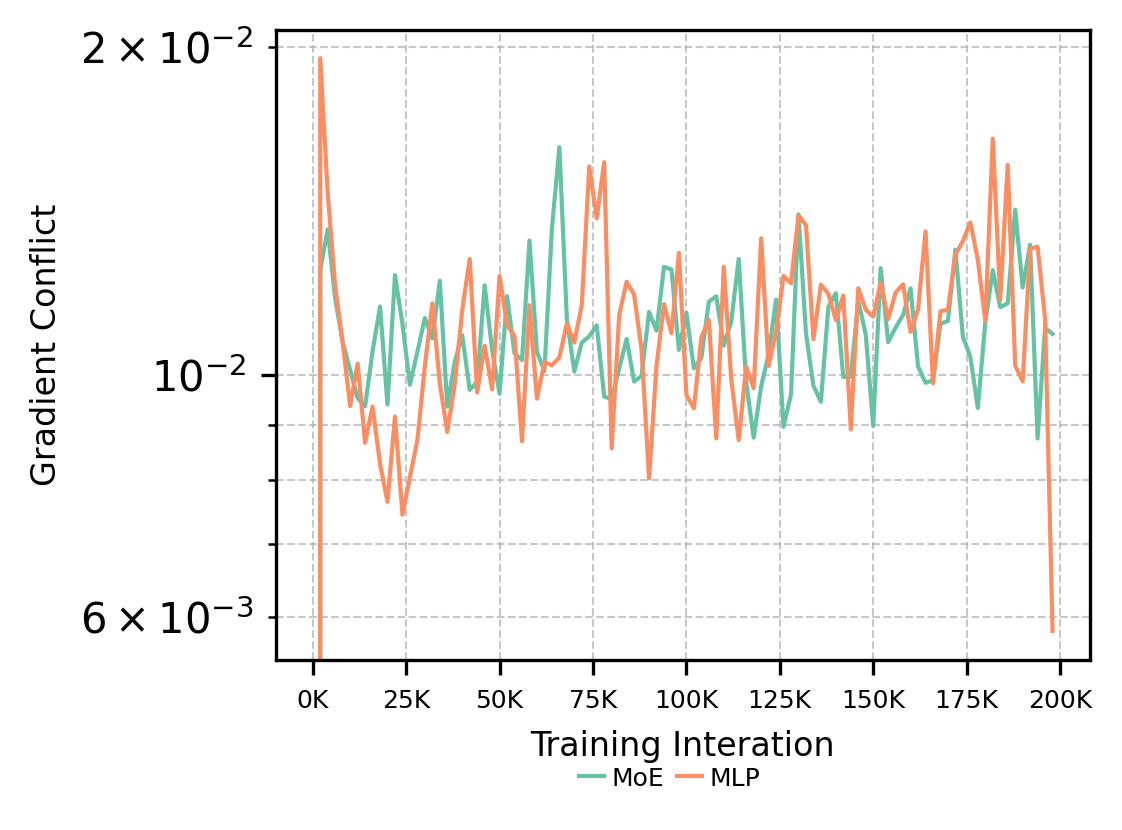
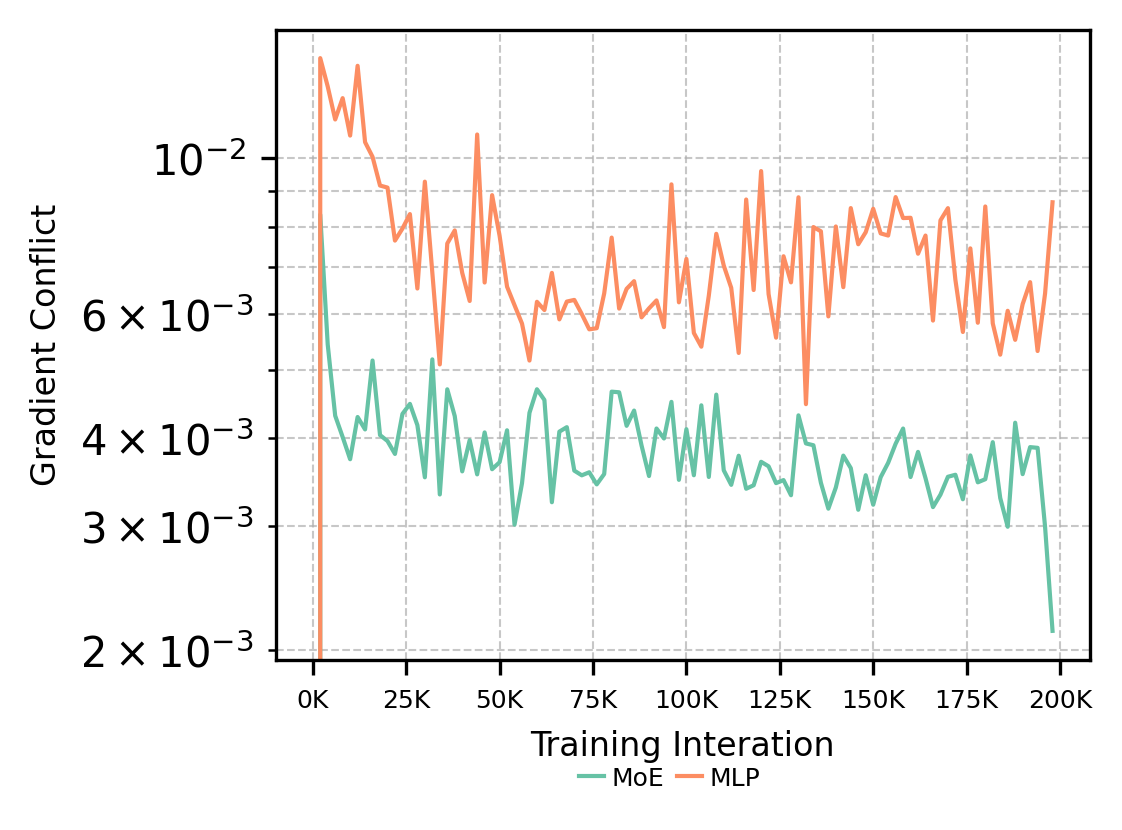
Figure 10: Comparison of gradient conflicts between MoE and MLP baselines. MoE-based Transformer exhibits fewer conflicts in MoE input and layer.
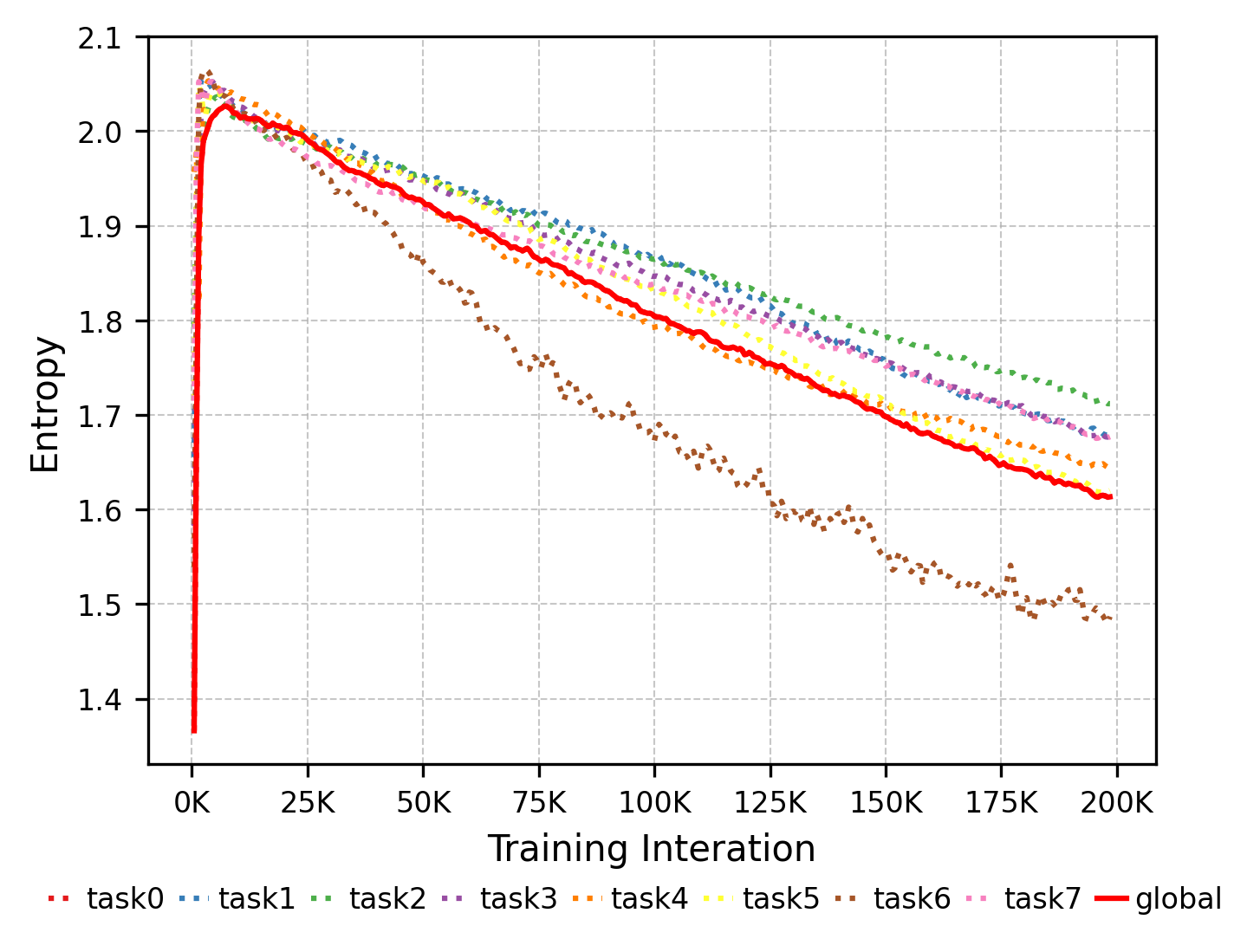
Figure 11: Evolution of expert selection entropy. Lower entropy reflects more specialized expert selection as training progresses.
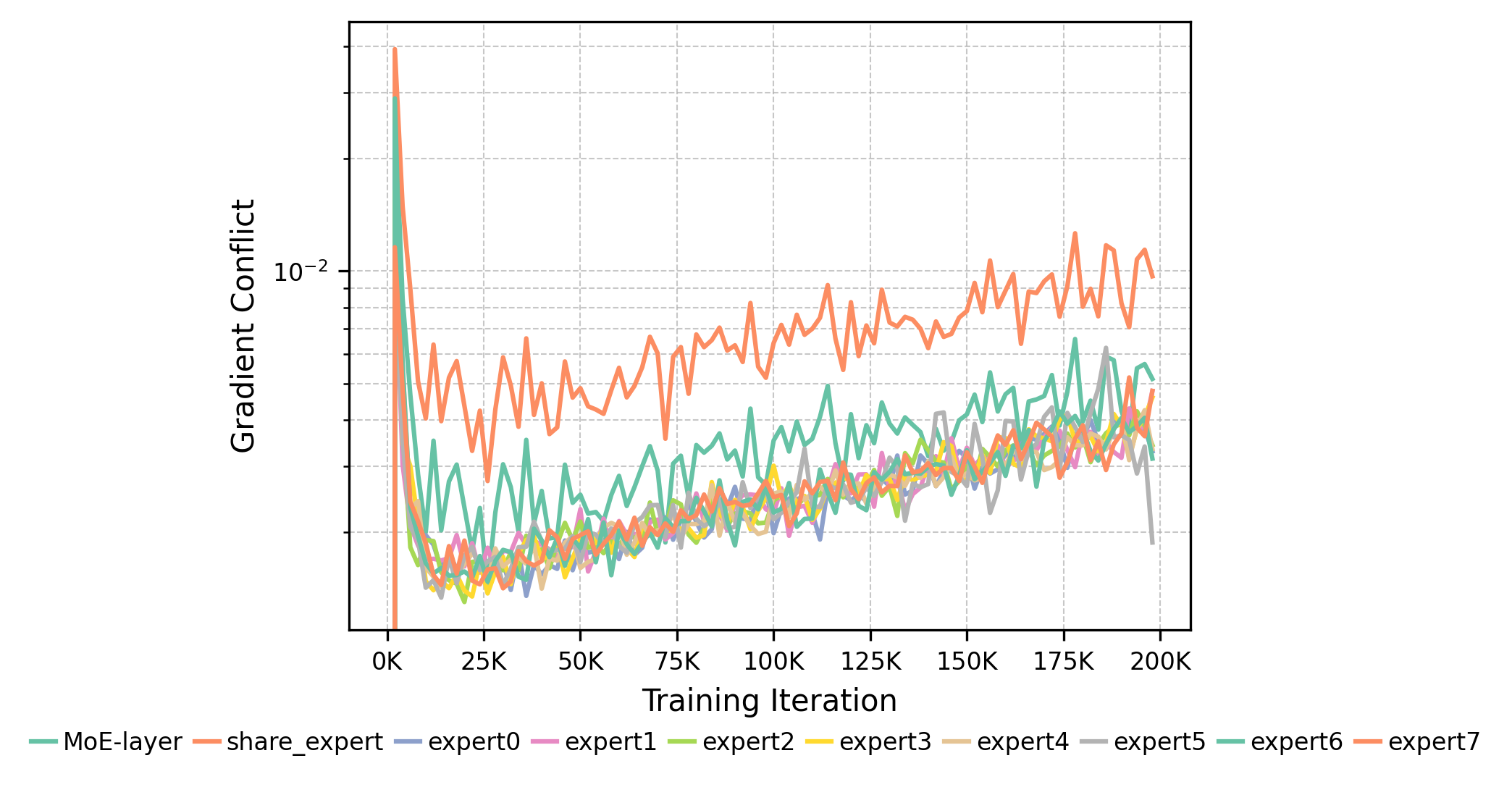
Figure 12: Gradient conflicts across experts in MoE training. Shared expert accumulates most conflicts; non-shared experts show effective specialization.

Figure 13: Heatmaps of expert selection distributions. Task-specific expert utilization patterns emerge and evolve during training.
Theoretical bounds show that the expected gradient conflict in MoE layers is strictly lower than in dense MLPs, especially when the router achieves effective task separation. Task embeddings can further enhance clustering signals for the router, though naive implementations may collapse without explicit constraints.
Representational Analysis
T-SNE visualizations of latent embeddings reveal that the model learns task-specific features while maintaining meaningful separation across environments, supporting the claim of robust representational capacity.
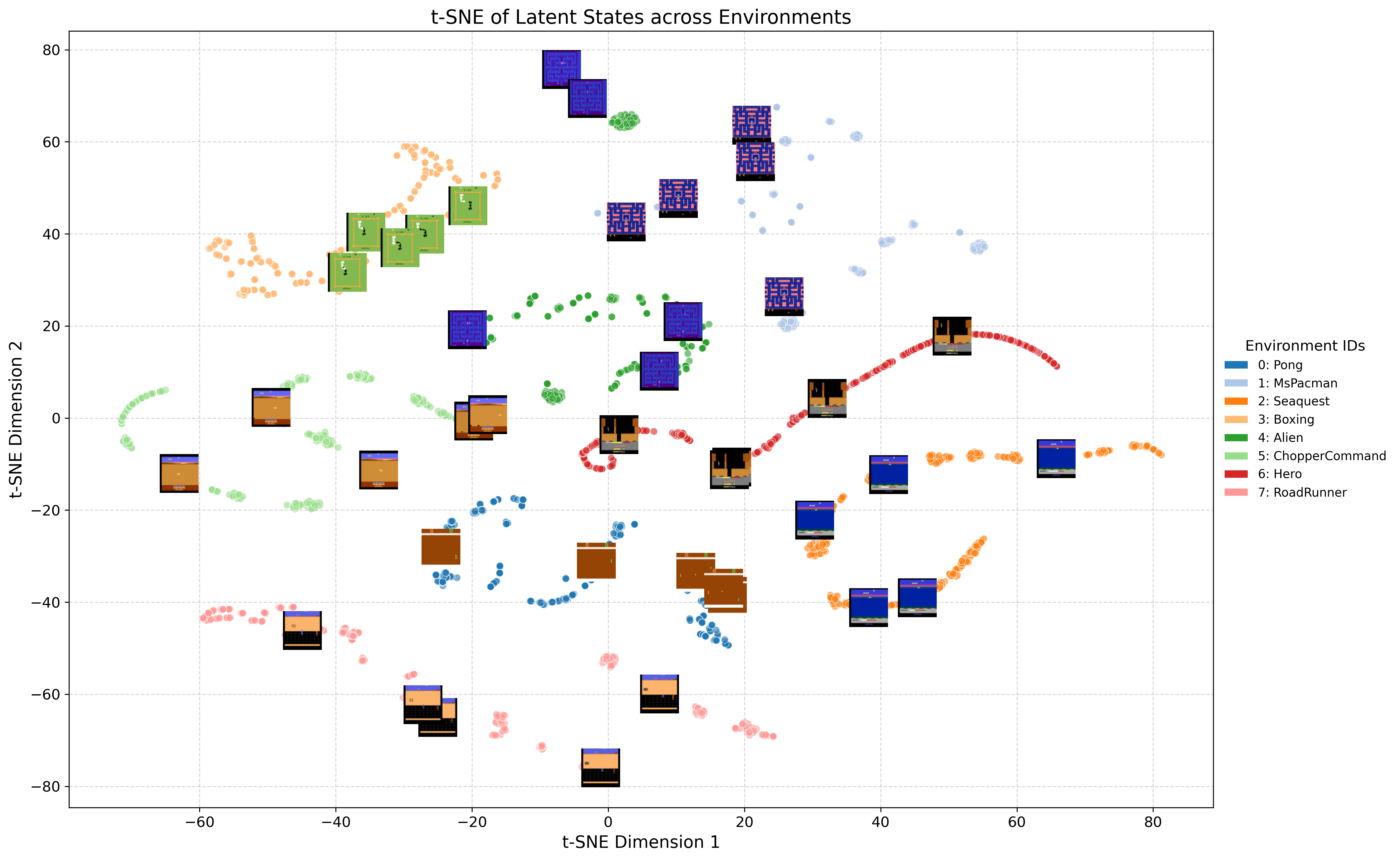
Figure 14: T-SNE visualization of latent embeddings. Similar game states cluster together, distinct environments form separate groups.
Implementation Considerations
The ScaleZero model is implemented with a ViT encoder for image-based tasks, BGE for text, and a Transformer backbone with MoE layers. DPS is realized via staged LoRA module injection, with adaptive triggers for expansion. Training is performed on 8x A100 GPUs, with hyperparameters aligned to the UniZero baseline for fair comparison.
Implications and Future Directions
The integration of MoE and LoRA within a unified world model architecture enables scalable, efficient multi-task planning and learning. The demonstrated gains in sample efficiency and generalization suggest that conditional computation and dynamic capacity allocation are critical for advancing generalist agents. Future work should explore the scalability of DPS to larger benchmarks, deeper synergies between MoE and LoRA, and the combination of online RL with offline pre-training for further efficiency and performance improvements.
Conclusion
This work provides a rigorous diagnosis of plasticity collapse in unified world models for multi-task RL and introduces principled architectural and training solutions—ScaleZero and Dynamic Parameter Scaling—that achieve strong performance and efficiency across diverse benchmarks. The empirical and theoretical analyses establish MoE as a robust backbone for mitigating gradient conflict and preserving plasticity, while DPS offers a practical mechanism for adaptive resource allocation. These contributions advance the state of multi-task planning and lay the groundwork for future research in scalable, generalist AI agents.