- The paper proposes a registry-driven data intelligence layer that integrates LLMs, relational, web, and user context sources for multi-modal query execution.
- It outlines an architecture using streams, sessions, and orchestrated agents to construct and optimize complex, cross-modal query plans.
- Demonstrations in apartment search and cooking assistance validate Blue’s ability to handle iterative, heterogeneous data workflows in enterprise applications.
Blue Data Intelligence Layer for Multi-Source, Multi-Modal Agentic Data Applications
Motivation and Background
The proliferation of NL2SQL systems has enabled natural language interfaces to structured databases, facilitating broader accessibility to enterprise data. However, real-world interactions rarely align with simple, atomic queries; instead, queries are iterative, span multiple utterances, and rely on heterogeneous sources, including external world knowledge, personal context, and multimodal data. The closed-world assumption—wherein all relevant information resides in a single relational schema—is increasingly untenable. LLMs provide access to world knowledge, but systematic integration of LLMs, relational databases, web data, and personal user context within a scalable, orchestrated framework has remained an unresolved challenge.
Blue is a compound AI architecture designed for agent and data orchestration in enterprise environments, organized around two central abstractions: streams (for data and control message flow) and sessions (for contextual task boundaries). Agents, modeled as data processors, subscribe to streams and participate in sessions, dynamically producing and consuming data. Blue maintains registries for data, agents, models, operators, and tools, each cataloging metadata, operational statistics, embeddings, and semantic descriptors to enable efficient agent discovery and resource utilization.
Task and data planners leverage these registries to construct executable plans. Task planners orchestrate agent workflows; data planners build multi-source, multi-modal query plans. This architecture affords granular coordination of complex, agentic workflows with dynamic data and resource allocation.
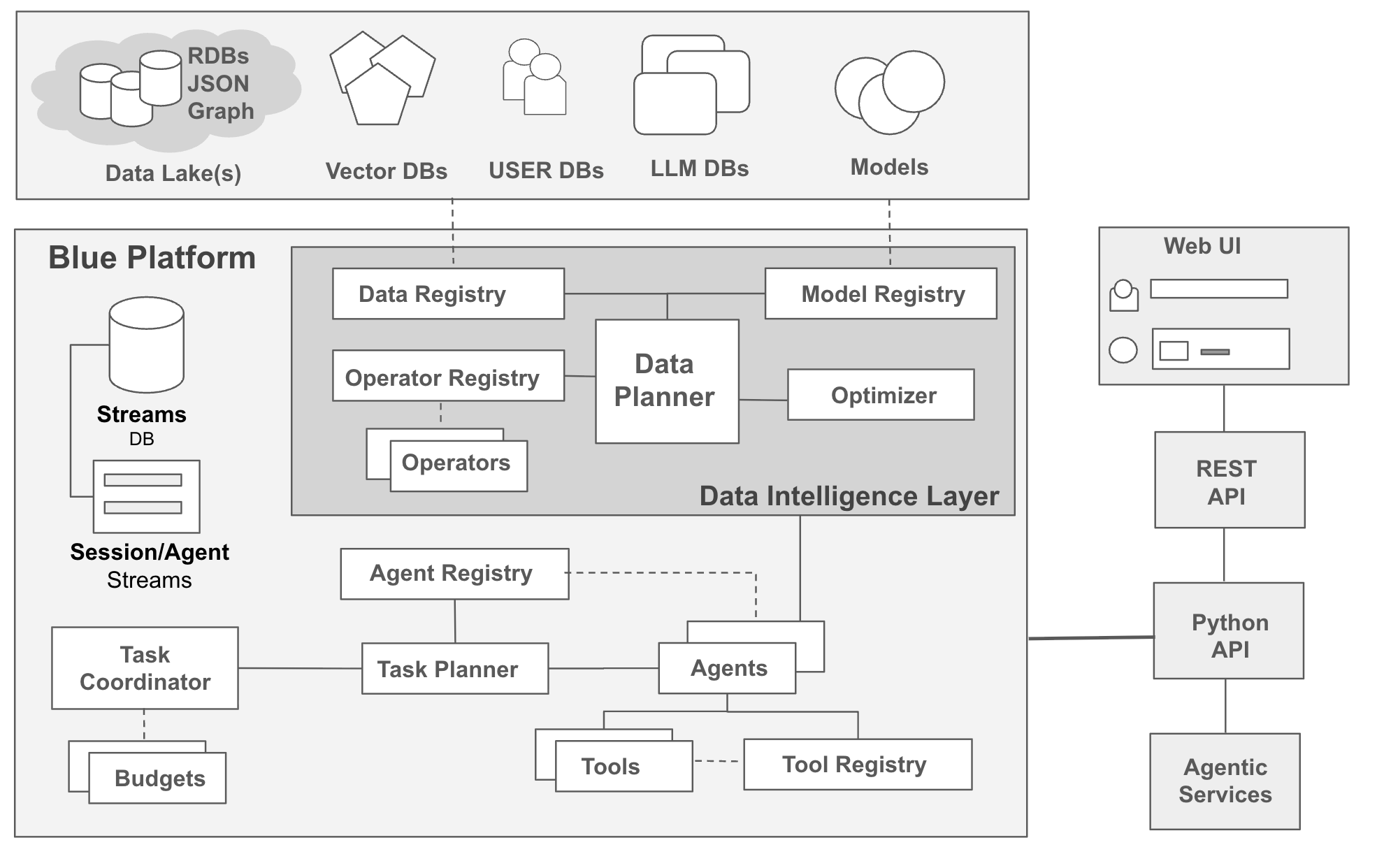
Figure 1: Blue Architecture: Registries are touch points that interface to available data, models, operators, and agents.
Data Intelligence Layer: Abstractions and Components
The Data Intelligence Layer (DIL) underpins agentic data processing, bridging the semantic gap between user intent and available information. DIL treats relational databases, LLMs, web content, and user context as first-class, queryable data sources, each with standardized interfaces supporting both native and natural language access.
Unified Data Source Abstraction
DIL generalizes traditional sources—relational, document, graph, and vector databases—to encompass:
- LLMDB: Structured representation of LLM-accessible external knowledge, supporting query rewriting, partitioning, schema design, cardinality estimation, entity resolution, model selection, caching, and distributed execution.
- UserDB: Persistent/interactive capture of structured user context and preferences, with on-demand clarification via iterative interaction.
- WebDB: Structured extraction from web documents, with enrichment, schema design, and distributed execution.
Query plans aren’t limited to SQL but can trigger retrieval from LLMs, the web, and the user, supporting cross-modal and iterative reasoning.
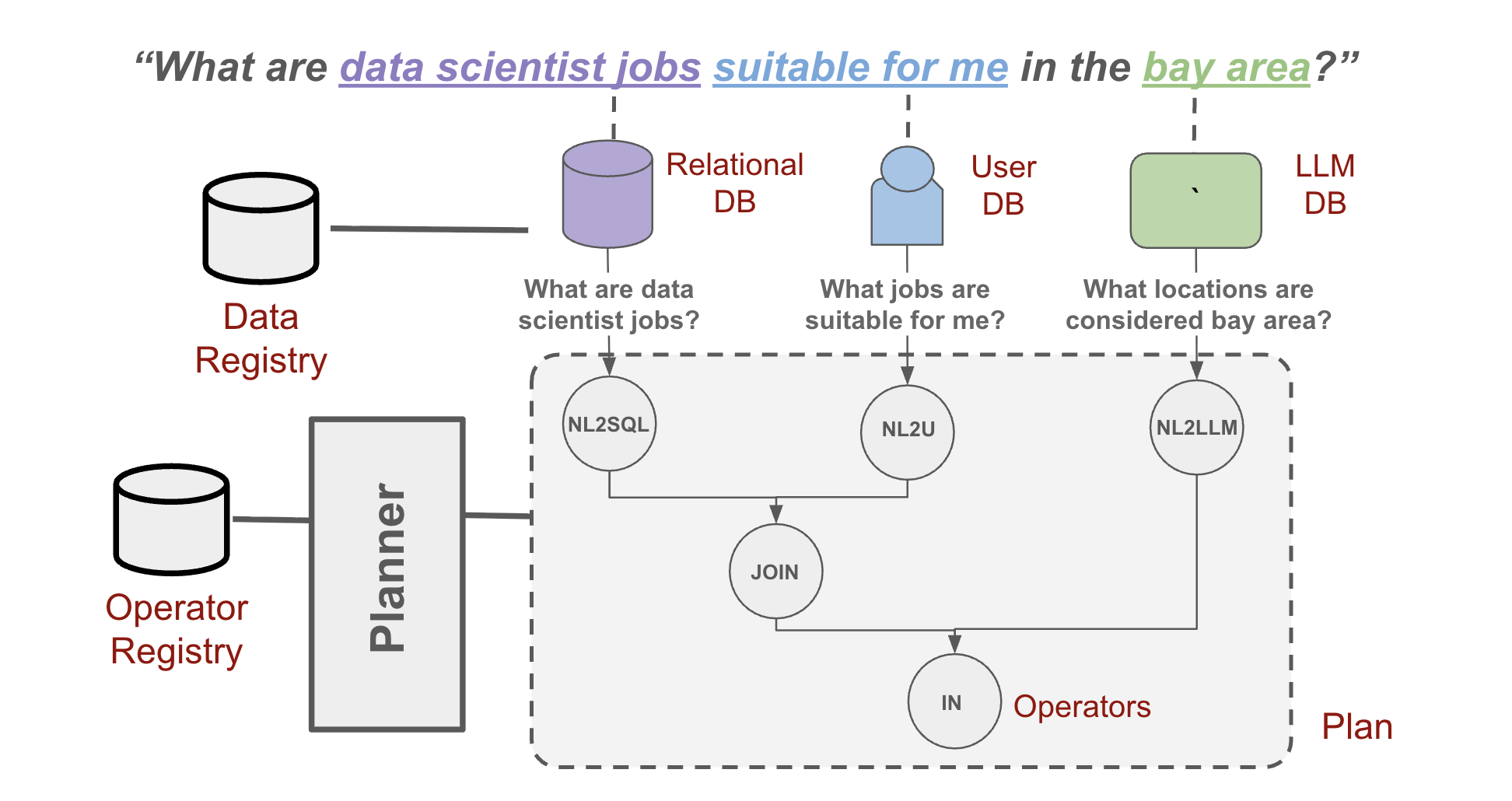
Figure 2: An example query over multiple data sources.
Data Registry
The data registry is a comprehensive metadata catalog that abstracts available sources and modalities. It supports discovery, search, and integration across databases, collections, entities, relations, attributes, and values. It also maintains descriptions, samples, statistics, logs, and learned representations for planning, verification, conflict resolution, synchronization, enrichment, ontology alignment, and semantic discovery.
Data Operators
Operators encapsulate data processing logic and expose standardized function signatures that support composable data pipelines spanning multiple modalities, structured and unstructured data, and agentic tools. Logical operators specify intent; physical operators realize concrete implementations via dictionaries, models, or LLMs. Operators expose configurable hyper-parameters for dynamic execution strategies, ensuring interoperability and integration across operator classes.
Data Planning
DataPlanner constructs executable, multi-source, multi-modal workflows as DAGs of operators. Abstract operators are recursively decomposed into subplans until all leaf nodes correspond to physical operators. Operator-level and plan-level optimization refine execution strategies—adjusting parameters, restructuring DAGs, parallelizing branches, or adapting to available resources. These declarative plans enable dynamic, cross-modal query execution with task, cost, and quality-driven selection.
Demonstrations: Apartment Search and Cooking Assistant
Two top-performing system demonstrations illustrate the capabilities of DIL.
Apartment Search
Agents are orchestrated to scrape and enrich SQL databases with heterogeneous web and file data, support NL2SQL conversion, profile database attributes, and generate visualizations (e.g., rent trends). The workflow dynamically integrates noisy, unstructured, and multi-source data—enabling actionable insights for high-context, human-centric tasks.
Cooking Assistant
Ingredient recognition from fridge images leverages visual models, retrieves candidate recipes using vector (ChromaDB) and relational search (PostgreSQL), and adapts results via iterative dialogue to accommodate constraints. Modular sub-agents coordinate structured databases, recipe text, multimodal user input, and LLM-driven reasoning to deliver reliable, personalized cooking workflows.
Developer Experience and Abstraction Intuitiveness
A hackathon-based survey of practitioners revealed strong flexibility and modularity of Blue’s architecture and data abstractions. The registry and source abstractions were intuitive, while complex constructs like planners and data plans posed more of a learning challenge. Developers appreciated the ease of discovering data sources and integrating query results, although debugging, error tracing, and multi-agent workflow orchestration were identified as friction points.
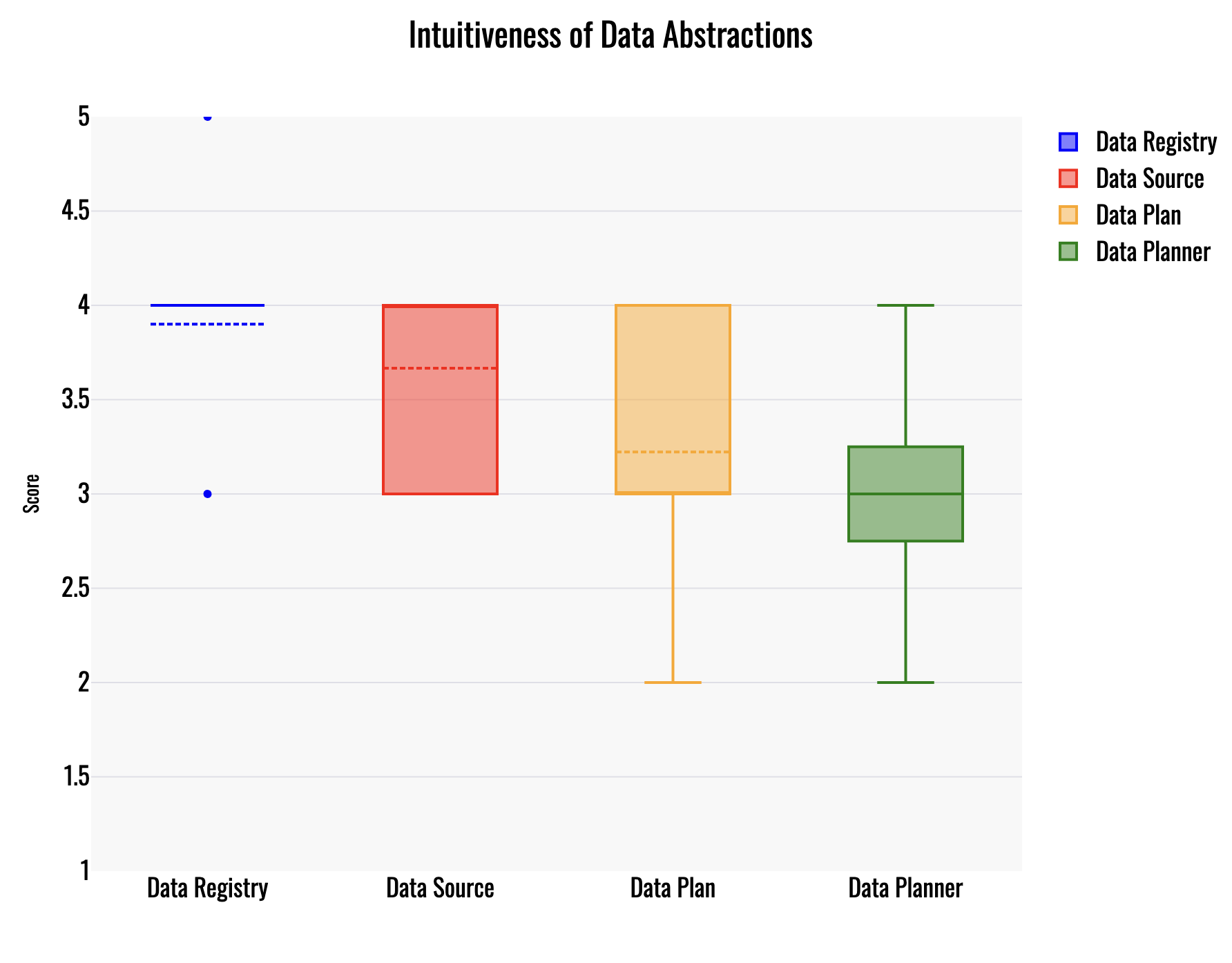
Figure 3: Intuitiveness of data abstractions.
Future improvements should address onboarding, documentation, deterministic replay, simulation modes, and error messaging to facilitate productive multi-agent development.
Analysis, Implications, and Future Directions
Blue’s DIL represents a model-agnostic, registry-driven architecture capable of orchestrating agentic data workflows across relational, semantic, and multimodal sources. This elevates agentic systems beyond NL2SQL to complex, cross-modal tasks with iterative, context-driven reasoning. The abstraction of LLMs, web, and user context as structured, queryable sources supports robust integration, reasoning, and optimization.
Practical implications extend to enterprise applications where heterogeneous sources, noisy unstructured data, and dynamic user context are routine. Theoretical implications include formalization of data source abstractions, operator taxonomy, and declarative planning/optimization in compound agentic systems. Integration with scalable AI infrastructure, distributed execution, and semantic integrity constraints remains an open area of research, as identified by recent works (e.g., "LLM-Powered Proactive Data Systems" (Zeighami et al., 18 Feb 2025), "Semantic Integrity Constraints" [Lee et al., 2025], "Task Cascades for Efficient Unstructured Data Processing" (Shankar et al., 9 Jan 2026), "Beyond Relational: Semantic-Aware Multi-Modal Analytics with LLM-Native Query Optimization" (Zhu et al., 25 Nov 2025), "A Declarative System for Optimizing AI Workloads" (Liu et al., 2024)).
Sustained advances in registry-driven agentic architectures could enable deterministic, semantically-grounded, extensible data intelligence systems for both enterprise and end-user applications, with potential for cross-modal analytics, proactive agent coordination, and seamless integration of world knowledge and user context.
Conclusion
Blue’s Data Intelligence Layer establishes a comprehensive, registry-driven abstraction for orchestrating agents and streaming data across heterogeneous sources and modalities. By treating relational databases, LLMs, web sources, and user context as structured, queryable entities and integrating them through extensible operators and declarative DAG-based planning, Blue advances agentic data intelligence for complex, real-world applications. System flexibility, modularity, and semantic grounding are evidenced in practical demonstrations and developer experience. Open challenges include further abstraction refinement, workflow debugging, and scalable optimization in multi-agentic environments.