Can AI Agents Answer Your Data Questions? A Benchmark for Data Agents
Abstract: Users across enterprises increasingly rely on AI agents to query their data through natural language. However, building reliable data agents remains difficult because real-world data is often fragmented across multiple heterogeneous database systems, with inconsistent references and information buried in unstructured text. Existing benchmarks only tackle individual pieces of this problem -- e.g., translating natural-language questions into SQL queries, answering questions over small tables provided in context -- but do not evaluate the full pipeline of integrating, transforming, and analyzing data across multiple database systems. To fill this gap, we present the Data Agent Benchmark (DAB), grounded in a formative study of enterprise data agent workloads across six industries. DAB comprises 54 queries across 12 datasets, 9 domains, and 4 database management systems. On DAB, the best frontier model (Gemini-3-Pro) achieves only 38% pass@1 accuracy. We benchmark five frontier LLMs, analyze their failure modes, and distill takeaways for future data agent development. Our benchmark and experiment code are published at github.com/ucbepic/DataAgentBench.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question with a hard answer: Can today’s AI “data agents” really answer people’s questions about company data just by using everyday language? To find out, the authors built a new test called the Data Agent Benchmark (DAB). It checks whether AI agents can do end-to-end data work—finding, cleaning, combining, and analyzing real data spread across different systems—like a human analyst would.
What the researchers wanted to find out
The team focused on a few easy-to-understand questions:
- Can AI agents handle data that lives in many different places and formats?
- Can they match records when IDs or names don’t line up (like “abc_123” in one table vs. “id-123” in another)?
- Can they pull facts out of messy text (like finding a location or rating hidden inside a paragraph)?
- Can they use domain knowledge (like finance or medical know-how) when the data alone isn’t enough?
- Overall, how accurate and reliable are these agents when asked realistic questions?
How they built and tested it
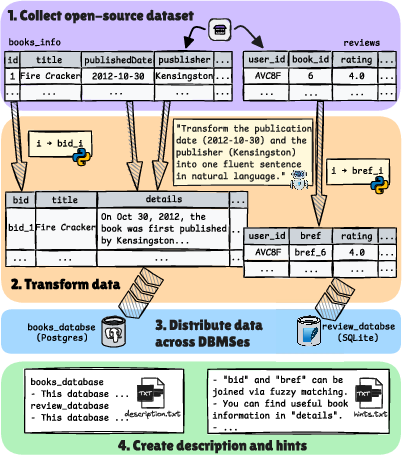
First, the team interviewed companies across six industries to learn what real user questions look like. Then they built DAB from open-source datasets (so everyone can use it) and carefully “messed them up” to mimic real-world problems. Think of it like making a realistic obstacle course for data agents:
- Multiple databases: Data is split across different systems (e.g., PostgreSQL, MongoDB, SQLite, DuckDB). An agent has to pull pieces from the right places and combine them.
- Messy matching (ill-formatted join keys): The same thing might be labeled differently in each database, like having slightly different IDs or added spaces, so the agent has to recognize they’re the same and join them correctly.
- Hidden facts in text (unstructured text): Useful details are buried in long text fields (like a review) instead of a neat column. The agent must extract and organize that info before using it.
- Domain knowledge: Some questions need expert rules (e.g., how to compute a financial metric correctly or what a medical term means).
They created 54 natural-language questions across 12 datasets and 9 topic areas (like news, books, CRM, GitHub, Yelp, stocks, patents, and cancer research). Each question has a clear, correct answer that can be checked by code.
To test AI agents, they used a common approach called a ReAct loop. Picture it like this:
- the agent thinks about the next step,
- runs a tool (like making a database query or a small Python script),
- looks at the result,
- decides what to do next, and repeats until it has an answer.
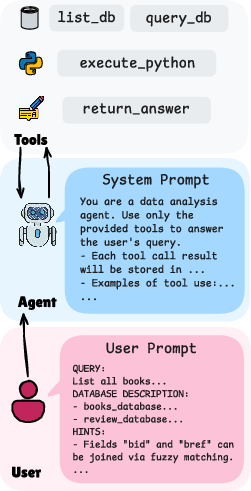
They evaluated five strong LLMs acting as agents, each allowed to:
- list what databases and tables exist,
- run read-only queries,
- execute small Python snippets,
- and return a final answer.
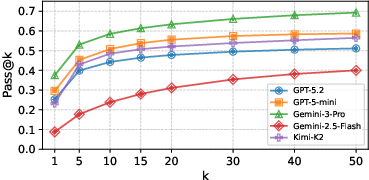
They tried each question 50 times to account for randomness and measured accuracy using “pass@1” (getting it right on the first try) and “pass@50” (getting it right at least once across 50 tries).
What they discovered
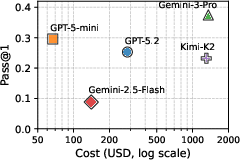
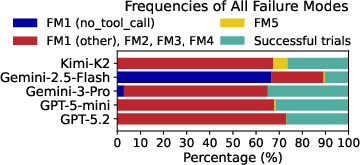
Results were surprisingly low. Even the best model (Gemini-3-Pro) got only 38% of questions right on the first try (pass@1). Even after 50 tries, it stayed under 69%. One dataset (patents) wasn’t solved correctly by any agent in any trial.
Here are the key takeaways, explained simply:
- End-to-end is hard: Agents struggled with the full pipeline—finding the right tables, cleaning keys, extracting from text, and applying domain rules—not just writing a single SQL query.
- A “just right” amount of exploring helps: The best-performing agents used about 20% of their actions to explore the data (like checking schemas or peeking at sample rows). Too little exploring misses important details; too much wastes time.
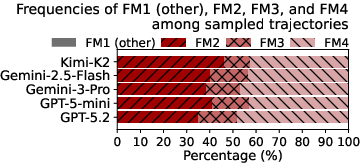
- Most errors were planning or implementation mistakes: About 85% of wrong answers came from flawed plans or buggy steps (e.g., not cleaning IDs correctly or misusing a query), not from picking the wrong database.
- Text extraction was basic: Every agent relied on simple patterns, like regular expressions (regex), to pull data out of text. None used more advanced NLP or LLM-based extraction inside the workflow.
- A production system helped a bit, but not enough: A specialized agent from an industry partner (PromptQL) improved first-try accuracy by 7 percentage points over the baseline setup but still failed completely on questions that required extracting data from unstructured text.
Why this matters
Many companies hope to let employees ask questions about their data in plain language. This paper shows we’re not there yet: real-world data is split across systems, has mismatched labels, and hides key facts inside text. Current AI agents often stumble on these specifics.
But the benchmark itself (DAB) is a big step forward. It gives researchers and companies a realistic, repeatable way to measure progress on end-to-end data tasks, not just pieces of the problem. The findings suggest clear directions for improvement:
- Better tools for extracting structured info from messy text (beyond simple regex).
- Smarter planning and checking—so agents can design and follow correct multi-step plans.
- Helpful “semantic layers” or shared definitions that reduce planning burden (e.g., standard ways to compute domain-specific metrics).
- Balanced exploration strategies to discover what’s in the data without getting lost.
In short, DAB highlights what’s hard about real data work and gives the community a common challenge to push AI data agents toward being truly useful in everyday business settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored, with concrete directions for future work:
- Benchmark scope excludes API integration and open-ended analytical reasoning. Develop extensions that: (a) evaluate API usage via snapshot/mock endpoints with deterministic outputs; and (b) assess open-ended tasks using rubric-based or programmatic judges (e.g., metric sets, constraint checks) that preserve reproducibility.
- Reliance on dataset-level hints. Measure agent performance with varied levels of assistance (no hints, partial, noisy, conflicting), and provide DAB variants to isolate robustness to missing or imperfect domain context.
- Limited DBMS coverage. Add enterprise systems (Snowflake, BigQuery, SQL Server, MySQL) and assess dialect-specific challenges (e.g., window functions, UDFs, semi-structured types, stored procedures, query optimizers).
- Stylized data perturbations may not fully capture real-world messiness. Validate representativeness by: (a) parameterizing corruption severity; (b) incorporating more realistic fuzzy entity resolution (synonyms, abbreviations, transpositions, multi-field matching); and (c) conducting external audits against production logs or red-teamed datasets.
- Read-only tasks only. Introduce controlled write scenarios (e.g., cleaning, normalization, materialized views) with guardrails and rollback, to evaluate agents’ ability to propose and carry out corrective actions safely.
- Evaluation favors recall over precision. Design automatic graders with structured output schemas, canonicalization/normalization, numeric tolerance, and explicit checks for extraneous items—without resorting to LLM judges—to better penalize over-inclusive answers.
- Benchmark scale and coverage. Expand the number and diversity of queries, include multi-hop analytical chains, and provide per-property difficulty tiers and train/dev/test splits to support method development and reliable comparison.
- Architecture diversity is not explored. Systematically compare agent frameworks beyond ReAct (e.g., planning/decomposition, workflow orchestration, self-correction, memory-enabled agents, multi-agent collaboration) under matched toolsets and prompts.
- Tooling is minimal (list_db, query_db, execute_python). Evaluate the impact of richer primitives: row-wise semantic operators (LLM apply), built-in extractors (regex builder, pattern libraries), schema search/summarization, data profilers, and join-assist utilities.
- Model configuration and sensitivity. Study effects of temperature, reasoning effort, tool-call batching/parallelism, context window size, and prompt variants; include additional frontier/open models (e.g., Claude) and report standardized seeds and variance.
- Exploration–exploitation trade-offs are observed but not optimized. Develop adaptive controllers to tune exploration budgets (e.g., schema/data inspection rate) and quantify how exploration allocation affects accuracy, latency, and cost.
- Context management is intentionally minimal. Investigate structured memory, automatic summarization of tool results, chunked retrieval, and caching strategies; quantify the effect of truncation policies on downstream planning and correctness.
- Security and safety are not evaluated. Test for prompt injection via database content, unsafe code execution in Python, data exfiltration, privilege misuse, and sandbox escapes; define and benchmark mitigations (e.g., taint tracking, policy guards, network isolation).
- Single-turn tasks only. Add multi-turn interaction tasks that require clarifications, reformulations, and memory of prior context; measure agents’ ability to ask for missing information and maintain state across turns.
- Scalability limits untested. Introduce tasks over large tables/corpora (tens of millions of rows), streaming or time-partitioned data, and complex join graphs; report latency/cost scaling and success under strict time budgets.
- Ground-truth alignment after transformations. Provide automated consistency checks that ensure corrupted/perturbed datasets still deterministically yield the same answers; release regeneration scripts and versioned artifacts to support auditing.
- No detailed accuracy breakdown by benchmark property. Report per-property and cross-property performance (multi-db integration, ill-formatted keys, text extraction, domain knowledge) to identify which challenges drive failure.
- Fuzzy ER underrepresented. Include tasks requiring approximate string matching, multi-attribute linkage, probabilistic resolution, and deduplication across sources; benchmark ER algorithms as callable tools.
- Domain knowledge is supplied via hints; retrieval is not tested. Add settings where agents must fetch background knowledge from documentation or web snapshots and integrate it with database content under reproducible constraints.
- The patents dataset is entirely unsolved. Provide a deeper error analysis and targeted sub-tasks (e.g., simpler CPC hierarchy navigation, intermediate scaffolding) to isolate failure causes and incremental improvements.
- Cost reporting focuses on USD totals. Include token-level accounting, latency breakdown per tool, and cost–accuracy trade-off curves; explore budgeted pass@k optimization and anytime stopping policies.
- pass@k independence assumption is unverified. Report trial-level variance, correlations across attempts, and confidence intervals; consider bootstrapping or controlled randomization to validate metric assumptions.
- Reproducibility across model updates is not addressed. Establish model/version pinning, release prompt and tool specs with hashes, and track performance drift over time.
- Schema evolution and data volatility are absent. Add tasks requiring schema discovery across versions, handling missing/renamed columns, and time-aware reasoning (e.g., “assume today is …”).
- MongoDB coverage is limited. Include aggregation pipelines, nested arrays/documents, and cross-collection joins; evaluate translation challenges between SQL and document-oriented paradigms.
- Bias and calibration in text-derived labels are not analyzed. For classification/extraction tasks, measure calibration, error types, and fairness across categories; provide ground-truth distributions to detect systematic biases.
Practical Applications
Immediate Applications
Below are practical, deployable-now applications that leverage the benchmark, methods, and findings reported in the paper.
- Procurement-grade evaluation of data agents for enterprises
- Sectors: software/SaaS, finance, healthcare, e-commerce, analytics vendors
- What: Use DAB to pressure-test vendor claims on end-to-end data agents (multi-DB integration, ill-formatted joins, text extraction, domain knowledge) with pass@k and cost metrics. Establish acceptance thresholds and compare cost–accuracy tradeoffs (e.g., GPT-5-mini vs. Gemini-3-Pro).
- Tools/workflows: Internal “Agent QA Suite” built around DAB; CI pipelines running nightly pass@1/pass@k; dashboards showing accuracy by dataset and failure taxonomy.
- Dependencies/assumptions: Access to model/tool-calling APIs; sandboxed DB instances; budget for evaluation runs.
- Pre-deployment regression testing and SLO setting for in-house data agents
- Sectors: any enterprise with analytics agents; data platform teams
- What: Adopt DAB as a regression suite to catch planning and implementation regressions before production. Use findings on exploration behavior (≈20% tool calls on schema/data exploration) to tune agent prompts and guardrails.
- Tools/workflows: GitHub Actions + DAB; automatic diffing of pass@k, latency, cost per release; heuristic limits on exploration vs. execution steps.
- Dependencies/assumptions: Stable staging data; telemetry to measure exploration ratios.
- Cost-aware model selection and routing
- Sectors: data platforms, BI tools, ML infra
- What: Route low-stakes or simple queries to lower-cost models (e.g., GPT-5-mini) and high-complexity ones to higher-accuracy models, guided by DAB’s cost–accuracy curves.
- Tools/workflows: Query complexity classifier; model-routing policy based on expected pass@1 and cost.
- Dependencies/assumptions: Historical logs to train a router; monitoring to detect drift.
- Ready-to-use ReAct agent scaffolding with secure tool execution
- Sectors: software, platforms
- What: Reuse the paper’s ReAct loop, tool set (list_db, query_db, execute_python, return_answer), and safety practices (read-only query enforcement, timeouts, context truncation, result file handles).
- Tools/workflows: Agent SDK templates; Dockerized Python sandbox with Pandas/PyArrow; SQL/Mongo read-only checkers.
- Dependencies/assumptions: Secure execution environment; DB credentials management.
- Operational guardrails and observability based on failure taxonomy
- Sectors: enterprise IT, analytics, regulated industries
- What: Instrument agents to log plan/implementation errors vs. source selection errors; alert when unstructured-text extraction is attempted via brittle regex only.
- Tools/workflows: Telemetry tags for error classes; dashboards with heatmaps by failure mode; automatic fallback to human review on risky modes.
- Dependencies/assumptions: Consistent error labeling; analyst-on-call workflows.
- Off-the-shelf “Join-Key Reconciler” microservice for cross-DB joins
- Sectors: data engineering, CRMs, e-commerce
- What: Package deterministic join-key fixes (prefix stripping, whitespace cleanup, stable mappings) discovered in DAB into a callable service to standardize identifiers before queries.
- Tools/workflows: Pre-join transform pipeline; library of deterministic transforms; config for dataset-specific rules.
- Dependencies/assumptions: Access to mappings; stable patterns in identifier corruption.
- Lightweight text-extraction primitives for agents (regex + patterns)
- Sectors: software, support/CRM analytics, finance
- What: Provide agents with a curated library of safe, tested extraction patterns for common fields (timestamps, ratings, locations) to reduce reliance on ad-hoc regex in the agent’s prompt.
- Tools/workflows: “Extraction Toolkit” (pattern catalog, validators); unit tests per pattern; integration with execute_python.
- Dependencies/assumptions: Coverage for frequent patterns; versioning and regression tests.
- Semantic layer documentation surfaced to the agent
- Sectors: BI, finance, healthcare
- What: Expose business definitions, metric formulas, and known mappings (as in DAB hints) to reduce planning burden and improve correctness in domain-knowledge tasks.
- Tools/workflows: Metrics catalog (e.g., YAML or dbt docs) injected as context; agent-side retrieval of definitions prior to planning.
- Dependencies/assumptions: Maintained semantic layer; governance for definitions.
- Academic use in courses and research labs
- Sectors: academia (CS, data systems, HCI)
- What: Use DAB to teach end-to-end data-centric agents, multi-DB integration, and evaluation. Run ablations on exploration budgets and tool design.
- Tools/workflows: Course assignments; reproducible notebooks; leaderboards for student agents.
- Dependencies/assumptions: Computing credits; containerized DBMS setups.
- Policy and risk assessment checklists for AI-driven analytics
- Sectors: public sector, healthcare, finance
- What: Create procurement and risk checklists requiring DAB-style end-to-end accuracy evidence, read-only enforcement, audit logs of tool calls, and cost reporting.
- Tools/workflows: Standardized reporting templates (pass@k, dataset coverage, failure modes); internal approvals before deployment.
- Dependencies/assumptions: Organizational mandate for evaluation; data privacy constraints.
- Human-in-the-loop workflows for high-stakes queries
- Sectors: healthcare, finance, operations
- What: Given low pass@1 (≈38% best), route multi-DB and unstructured-text tasks to analyst review at key steps (plan approval, join-key mapping, final answer).
- Tools/workflows: UI for plan preview; stepwise confirmations; diff views of intermediate query results.
- Dependencies/assumptions: Trained reviewers; SLAs acknowledging added latency.
- Domain-specific sandboxes for safe experimentation
- Sectors: healthcare, finance, IP/patents
- What: Mirror DAB’s dataset distribution to create internal “messy mirrors” of production schemas (with synthetic perturbations) for safe agent testing.
- Tools/workflows: Data virtualization of production metadata; seeded perturbations (key reformatting, text embedding); deterministic ground truths.
- Dependencies/assumptions: Synthetic or de-identified data; reproducibility infrastructure.
Long-Term Applications
These applications require further research, scaling, or productization beyond what the current results support.
- Robust, production-grade data agents for multi-DB analytics
- Sectors: BI, SaaS/CRM, finance, healthcare, e-commerce
- What: Agents that reliably integrate heterogeneous backends, reconcile identifiers, transform unstructured text, and apply domain definitions at scale.
- Potential products: “Enterprise Data Copilot” with certified pass@k thresholds per domain.
- Dependencies/assumptions: Significant improvements in planning and implementation reliability; stronger text-extraction methods than regex; organizational adoption of semantic layers.
- Database-native semantic operators for text (LLM UDFs)
- Sectors: DBMS vendors, enterprise data platforms
- What: Safe, cost-controlled row-wise LLM operators (classify/extract/cluster/summarize/search) exposed in SQL and integrated with query planners.
- Potential products: SQL extensions (e.g., EXTRACT_JSON(field USING MODEL …)) with budgets and caching; vectorization across rows.
- Dependencies/assumptions: Execution cost controls, caching, and data privacy controls; accuracy monitoring.
- Automated semantic layer discovery and maintenance
- Sectors: analytics, governance
- What: Learn or mine business metrics, entity mappings, and synonyms from code, docs, and query logs to autopopulate the “hints” agents need.
- Potential products: “Semantic Layer Builder” that suggests canonical joins, metric formulas, and abbreviations.
- Dependencies/assumptions: Access to documentation and logs; human validation loops; versioning and lineage.
- Learned entity resolution and fuzzy joining across systems
- Sectors: CRM, supply chain, healthcare
- What: Replace deterministic transforms with learned matching models that resolve entities across noisy systems (names, addresses, abbreviations).
- Potential products: “Cross-DB Resolver” service with active learning and confidence thresholds integrated into agent workflows.
- Dependencies/assumptions: Labeled pairs or weak supervision; privacy-compliant training; performance guarantees and fallbacks.
- Planning-first agent architectures with verification
- Sectors: software platforms, research
- What: Agents that synthesize and verify executable plans before running tools, with unit tests on sub-steps and self-correction when checks fail.
- Potential products: Planner–Executor frameworks; program-synthesis with static analysis; query plan validation against small samples.
- Dependencies/assumptions: Advances in program synthesis and verifiable reasoning; tight integration with data sampling and test oracles.
- Cross-DB interoperability layers for agents
- Sectors: data engineering, vendors
- What: Standardized intermediate representation (IR) for multi-DB queries and tool calls, enabling optimization and provenance across heterogeneous systems.
- Potential products: Agent Query IR + adapters for SQL dialects and MongoDB; cross-engine cost models.
- Dependencies/assumptions: Community standards; performance benchmarks; security and governance alignment.
- Evaluation standards and certification for AI data agents
- Sectors: regulators, standards bodies, large enterprises
- What: Formalize DAB-like end-to-end evaluations as certifications for data agents (accuracy, cost, auditability), tailored to risk tiers.
- Potential products: “Data Agent Safety Mark” with test batteries per sector (e.g., healthcare addenda).
- Dependencies/assumptions: Multi-stakeholder consensus; periodic test refresh to prevent overfitting.
- Personal knowledge agents that integrate across consumer data silos
- Sectors: consumer productivity, privacy tech
- What: Agents that reason over emails, documents, calendars, and notes to answer questions requiring multi-source joins and text extraction.
- Potential products: “Personal Data Analyst” with local-first execution and privacy-preserving sandboxes.
- Dependencies/assumptions: Strong privacy/security; reliable unstructured-text extraction and entity reconciliation; app API access.
- Sector-specific copilots with domain knowledge libraries
- Sectors: healthcare (EHR + notes), finance (market + internal risk data), energy (sensor + work orders)
- What: Pre-packaged agents with curated domain metrics, mappings, and extraction patterns; validated against sector-specific DAB variants.
- Potential products: “CRM Success Copilot,” “Clinical Trial Data Copilot,” “Plant Ops Copilot.”
- Dependencies/assumptions: Curated, up-to-date domain ontologies; compliance approvals; ongoing evaluation and monitoring.
- Human–AI collaboration loops for dataset and policy evolution
- Sectors: enterprise IT, governance
- What: Agents propose join rules/extraction patterns; humans approve and promote to the semantic layer; policies evolve with audit trails.
- Potential products: “Agent Suggestion Inbox” with diff-based reviews; auto-rollback on error spikes.
- Dependencies/assumptions: UX for reviewers; metrics to detect regressions; cultural adoption.
- Expanded research benchmarks (APIs, streaming, open-ended tasks)
- Sectors: research, vendors
- What: Extend DAB to include API integrations, streaming sources, and exploratory analytics with rubric-based judgments.
- Potential products: DAB-API and DAB-Explore tracks; public leaderboards and workshops.
- Dependencies/assumptions: Stable evaluation protocols for non-deterministic tasks; LLM-judge reliability or human review budgets.
- Privacy- and compliance-aware agent runtimes
- Sectors: healthcare, finance, public sector
- What: Policy engines that enforce read-only modes, data minimization, per-source access policies, and comprehensive tool-call audit logs while maintaining agent performance.
- Potential products: “Compliance Agent Runtime” integrating with IAM, DLP, and SIEM.
- Dependencies/assumptions: Integration with enterprise identity and data catalogs; legal sign-off and audits.
Notes on feasibility across items:
- Current accuracy limits (best pass@1 ≈ 38%, pass@50 ≤ 69%) necessitate human oversight for high-stakes use.
- Many long-term applications depend on advances in text extraction beyond regex, improved planning/verification, and robust semantic layers.
- Secure, sandboxed execution and governance are prerequisites for both immediate and long-term deployments.
Glossary
- adjusted closing prices: Price series corrected for corporate actions (splits, dividends) used to compute comparable returns and volatility. "must be computed from adjusted closing prices to account for splits and dividends."
- agent trajectory: The full sequence of an agent’s model calls, tool invocations, and observed results during a trial. "All agent trajectories are publicly available."
- API integration: Combining data from external application programming interfaces with database sources within a single workflow. "API integration, where relevant data resides not in databases but in external APIs (e.g., email clients, web search endpoints, third-party data providers) that must be queried alongside database sources."
- approximate string matching: Techniques that match similar but not identical strings (e.g., to align noisy identifiers). "using approximate string matching or contextual reasoning"
- BRCA: A cancer type (Breast Invasive Carcinoma) designation used in genomics datasets and analyses. "Among alive BRCA patients, which top 3 histological types show the highest % of CDH1 gene mutations?"
- CDH1 gene mutations: Alterations in the CDH1 gene (E-cadherin) with clinical and biological significance in certain cancers. "CDH1 gene mutations"
- Cooperative Patent Classification (CPC): A hierarchical system for categorizing patents into technology areas. "Identify CPC areas with the highest EMA of patent filings (smoothing 0.2); return level-5 codes whose best year is 2022."
- CRM (Customer Relationship Management): Systems and processes for managing interactions with customers, leads, and sales operations. "customer relationship management (CRM) tool"
- data-dependent transformations: Text/data processing where rules vary per record and cannot be captured by a single fixed pattern. "Data-dependent transformations require the agent to examine individual rows"
- data-independent transformations: Text/data processing solvable by a fixed program or pattern that applies uniformly to all rows. "Data-independent transformations can be resolved by fixed-size programs regardless of data cardinality."
- data silos: Isolated data stores that hinder integration and cross-system analysis. "store data in disparate silos"
- database management system (DBMS): Software for creating, querying, and managing databases. "4 database management systems (DBMSes)."
- Docker environment: A containerized runtime that packages code and dependencies for consistent execution. "in a Docker environment with Python 3.12"
- entity resolution: The process of determining when records from different sources refer to the same real-world entity. "where entity resolution is required to match records across sources"
- exact-match joins: Joins where identifiers align perfectly across sources without transformation. "exact-match joins, where identifiers match one-to-one across sources"
- Exponential Moving Average (EMA): A time-series smoothing technique that weights recent observations more heavily. "Identify CPC areas with the highest EMA of patent filings (smoothing 0.2)"
- failure taxonomy: A structured categorization of error types or failure modes observed in system behavior. "We develop a failure taxonomy"
- frontier LLMs: State-of-the-art LLMs at the leading edge of capability. "We benchmark five frontier LLMs"
- fuzzy joins: Cross-source joins that rely on approximate matching or contextual cues due to inconsistent identifiers. "fuzzy joins, where entity resolution is required to match records across sources"
- ground-truth answer: The correct, authoritative answer used to evaluate system outputs. "Each query consists of a natural-language question, a ground-truth answer, and a validation script."
- histological types: Categories of tissue characteristics used to classify tumors in pathology. "which top 3 histological types show the highest % of CDH1 gene mutations?"
- ill-formatted join keys: Identifiers for the same entity that differ across sources (e.g., prefixes, whitespace), requiring normalization before joining. "ill-formatted join keys"
- intraday volatility: A measure of how much an asset’s price fluctuates within the trading day. "Which stock index in Asia has the highest average intraday volatility since 2020?"
- LLM-based judge: A LLM used as an evaluator to assess correctness or quality of outputs. "would require either manual inspection of every trajectory or an LLM-based judge"
- open-ended analytical reasoning: Exploratory analysis where the approach and metrics are not pre-specified and multiple answers may be acceptable. "Open-ended analytical reasoning."
- pass@1: The probability that a single attempt produces a correct answer (special case of pass@k with k=1). "achieves only 38% pass@1 accuracy"
- pass@k: The probability that at least one of k independent attempts succeeds; a reliability metric for stochastic systems. "measure accuracy using pass@"
- petabyte-scale: Data sizes on the order of 1015 bytes, indicating extremely large volumes. "petabyte-scale data volumes."
- programmatic-transform joins: Cross-source joins where identifiers differ but can be reconciled via deterministic transformations. "programmatic-transform joins, where identifiers refer to the same entity but differ in format and can be reconciled via deterministic rules"
- ReAct pattern: An agent design that alternates between reasoning and acting via tool calls in iterative loops. "using the ReAct pattern"
- regular expressions: Pattern-matching syntax for extracting or transforming text based on specified rules. "Every agent uses regular expressions"
- semantic layer: An intermediate abstraction that encodes business logic and concepts to simplify queries and planning. "semantic layers can reduce the planning burden on the agent."
- semantic mapping: Mapping between semantically equivalent but differently represented concepts or identifiers. "require a semantic mapping between full stock exchange names and abbreviated index symbols"
- semantic operators: LLM-powered row-level text operations such as classification, extraction, clustering, summarization, and semantic search. "semantic operators—i.e., LLM-powered transformations applied to individual rows of a table"
- SQL dialects: Variants of SQL syntax and features across different database systems. "SQL dialects and MongoDB's query language"
- stratified: Averaging or analysis performed within defined groups (strata) before aggregating, to prevent disproportionate weighting. "All reported averages are stratified"
- Table-QA: Table question answering; tasks where answers are derived from tables, often provided directly in context. "table question-answering (i.e., Table-QA) benchmarks"
- text-to-SQL: Translating natural-language questions into executable SQL queries. "text-to-SQL benchmarks"
- thematic analysis: A qualitative research method for identifying patterns (themes) in data. "thematic analysis, a widely used qualitative method in HCI research"
- tool calling: LLM capability to invoke external functions/tools by emitting structured function calls from prompts. "Modern LLMs support tool calling"
- unstructured text transformation: Converting free-form text into structured data (e.g., extracting fields) for downstream querying and analysis. "unstructured text transformation: answers may be embedded in text fields that the agent must parse into structured values"
Collections
Sign up for free to add this paper to one or more collections.