AdaSplash-2: Faster Differentiable Sparse Attention
Abstract: Sparse attention has been proposed as a way to alleviate the quadratic cost of transformers, a central bottleneck in long-context training. A promising line of work is $α$-entmax attention, a differentiable sparse alternative to softmax that enables input-dependent sparsity yet has lagged behind softmax due to the computational overhead necessary to compute the normalizer $τ$. In this paper, we introduce AdaSplash-2, which addresses this limitation through a novel histogram-based initialization that reduces the number of iterations needed to compute $τ$ to typically 1--2. The key idea is to compute a coarse histogram of attention scores on the fly and store it in on-chip SRAM, yielding a more accurate initialization that enables fast forward and backward computation. Combined with a sparsity-aware GPU implementation that skips zero blocks with low overhead, AdaSplash-2 matches or improves per-step training time relative to FlashAttention-2 when block sparsity is moderate-to-high (e.g., $>$60\%), which often occurs at long-context lengths. On downstream tasks, models trained with our efficient $α$-entmax attention match softmax baselines at short-context lengths and achieve substantial gains in long-context settings.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
AdaSplash-2: Faster Sparse Attention, Explained Simply
What is this paper about?
This paper is about making a key part of LLMs—attention—both faster and smarter when reading long pieces of text. Usual attention (called softmax) looks at every word a little bit. A newer version (called entmax) can focus only on the important words and ignore the rest, which is helpful for very long inputs. The problem: entmax used to be slower to compute. This paper introduces AdaSplash-2, a way to make entmax fast enough to compete with the best existing methods, especially when inputs are long and most attention weights should be zero.
What goals are the researchers trying to achieve?
In simple terms, the paper aims to:
- Make entmax attention run fast on GPUs without losing accuracy.
- Cut down the “guess-and-check” steps entmax needs to compute its internal threshold (a number called tau).
- Take advantage of the fact that many attention weights are exactly zero, so the model can skip useless work.
- Show that this faster entmax keeps up with softmax on short texts and works even better on very long texts.
How does their method work?
Think of attention like shining a spotlight across words. Softmax spreads the light everywhere a little bit. Entmax can shine on just the few important spots and turn others completely off (becoming sparse).
The challenge is figuring out the exact “brightness cutoff” (the threshold tau) so the spotlight adds up correctly. Older methods had to scan the data several times to find this cutoff.
AdaSplash-2 speeds this up with two big ideas:
- A “fast tally” (histogram) to start with a good guess
- Imagine you’re sorting test scores into buckets: 0–10, 10–20, and so on. Instead of remembering every score, you just count how many fall into each bucket.
- AdaSplash-2 does this with attention scores: it quickly builds a small histogram (bucket counts) on the GPU’s small, super-fast memory (like using a backpack instead of running back and forth to a locker).
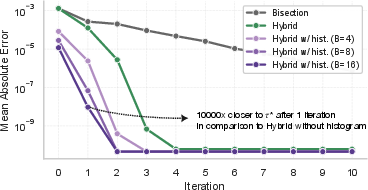
- From that histogram, it gets a near-perfect first guess for the threshold tau—so good that it usually needs only 1–2 quick refinements to be exact.
- Skip the zeros efficiently
- Because entmax produces many zero weights, there’s no reason to compute math for those parts.
- AdaSplash-2 divides the big attention matrix into chunks (“blocks”), marks which blocks are actually non-zero using a tiny bitmask (like a map that says “don’t bother here”), and then only computes the parts that matter.
- This saves a lot of time, especially for long inputs where most blocks are zero.
A few more helpful details:
- The “refinement” step for tau uses safe, reliable guess-and-improve methods (like adjusting a thermostat and checking the temperature), with a built-in safety net so it never goes off track.
- The whole design fits how GPUs like to work: in tiles/chunks, using fast on-chip memory, and minimizing trips to slower memory.
What did they find, and why does it matter?
Main results:
- Computing the entmax threshold tau becomes so accurate from the histogram that the model typically needs only 1–2 refinement steps. This is much faster than before.
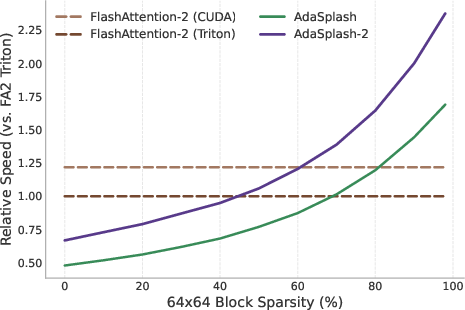
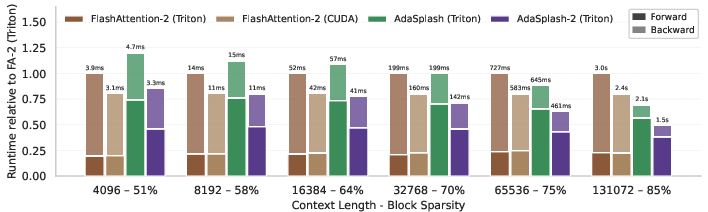
- When there’s moderate to high sparsity (for example, more than about 60% of attention blocks are zero), AdaSplash-2 matches or beats the speed of a top softmax system (FlashAttention-2). At very high sparsity, it can be more than 2× faster.
- In training LLMs:
- On short texts, models with entmax attention perform about as well as softmax.
- On long texts, entmax often does better. It’s especially strong on tasks that need tracking information over long distances (like following variables or finding repeated words).
- The backward pass (used to compute gradients during training) is noticeably faster, which is important because training spends much of its time there.
Why it matters:
- Faster, sparser attention means we can train models on longer documents more efficiently.
- Models can focus better, avoiding the “attention spread” problem where attention gets diluted across many irrelevant tokens.
- This can save time, compute, and energy—key for scaling up AI responsibly.
What are the bigger implications?
- Better long-context understanding: AdaSplash-2 helps models handle long stories, logs, code, or conversations by focusing sharply on what matters.
- Lower training cost: Skipping useless work (zeros) means less computation and potentially less energy use.
- Practical impact: Researchers and developers can choose entmax without worrying it will be too slow, unlocking both efficiency and accuracy for long inputs.
- Future directions: The method plays nicely with newer GPU tricks and could be extended further. The paper focuses on training; a fully optimized inference path could be the next step.
- Responsible use: Faster models are powerful, but the usual cautions still apply—models can reflect biases in their training data, so careful evaluation remains important.
In short: AdaSplash-2 turns entmax—an attention method that naturally ignores unimportant stuff—into a practical, fast tool for modern AI, especially when dealing with very long inputs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, stated concretely to guide future work:
- Inference kernel and KV-cache support: No optimized autoregressive decoding path; unclear how to update the entmax normalizer τ incrementally when appending keys, how to avoid multiple key scans per token, and how to support KV caching efficiently for low-latency inference.
- α beyond {1.5, 2.0}: Empirical convergence, stability, and accuracy are only demonstrated for α ∈ {1.5, 2.0}; behavior for α > 2 (where derivatives become unbounded) is not evaluated, nor are robust refinement strategies validated experimentally for these regimes.
- Learnable or adaptive α: The paper fixes α (typically 1.5); it does not explore making α learnable per head/layer, scheduling α during training, or targeting a desired sparsity level explicitly (and the resulting impacts on speed, stability, and quality).
- Refinement iteration guarantees: While τh has a bounded error |τ* − τh| < 1/B, there is no theoretical bound on the number of refinement iterations required to reach a given tolerance as a function of B, n, and score distribution.
- Adaptive histogram binning: Bin count B is fixed; no method is provided to adapt B per row or per batch to balance SRAM use, overflow risk, and target error, nor is there a principled way to auto-tune B to meet a latency/accuracy budget.
- Overflow handling overhead: The periodic “flushing” strategy to avoid histogram overflow for very long sequences is described but not quantitatively analyzed; its runtime overhead and correctness implications at ≥128K–1M tokens remain unmeasured.
- Safety of block-skipping mask: There is no formal proof or stress-test showing that the constructed block mask never drops nonzero attention entries under finite precision (bf16) and after refinement (i.e., absence of false negatives), nor a fallback strategy if violations occur.
- Numerical stability in backward: Gradients at non-smooth points (support boundaries) and for α ≥ 2 (where f″ is unbounded) are not analyzed; effects on gradient correctness and training stability across dtypes (bf16/fp16/fp8) need validation.
- Cross-attention and non-causal masks: The method and guarantees are presented mainly for causal self-attention; extensions to cross-attention, bidirectional encoder attention, and complex masks (e.g., mixture of sliding-window + globals) are not evaluated.
- Low-sparsity regimes: Break-even analysis is limited; there is no runtime controller to detect low sparsity and automatically fall back to dense kernels (e.g., FlashAttention) to prevent slowdowns when sparsity is insufficient.
- Hardware portability: Benchmarks focus on NVIDIA Ampere with Triton; there is no implementation or evaluation on Hopper (with TMA/WGMMA), AMD/ROCm, Apple, or TPUs, nor an analysis of portability issues (e.g., bitpacking intrinsics, fns/popc equivalents).
- Multi-GPU/distributed training: No evaluation of data/tensor/pipeline parallel training, inter-GPU communication effects, or interaction with ZeRO/activation checkpointing; it is unclear how well sparsity-induced compute imbalance impacts scaling.
- Precision and quantization: Only bf16 is evaluated; support and stability for fp8, int8/int4 weight-quantized LLMs, and mixed-precision accumulation (including histogram precision) remain open.
- Tiling and block-size sensitivity: The impact of attention block size (e.g., 64×64), query/key tile sizes (Br, Bc), and SRAM blocking choices on both speed and model quality is not systematically ablated; no autotuner is provided.
- Comparison to alternative sparse attention training: No head-to-head comparisons with input-dependent sparse baselines (e.g., differentiable/top-k softmax, learned gating/routing, fixed+global sparse patterns) under matched sparsity and quality.
- Larger-scale models and longer contexts: Language modeling results top out at 1B parameters and 32K tokens; it remains unknown whether speed and quality gains persist at 7B–70B and at ≥128K contexts with real workloads.
- Task coverage: Long-context evaluation is limited to RULER and HELMET; broader, real-world tasks (retrieval-augmented QA, multi-document summarization, code, long-horizon agent traces) and end-to-end application metrics are missing.
- Energy and cost metrics: Results focus on per-step time; energy efficiency (J/token), throughput to target quality, and end-to-end training cost comparisons to dense baselines are not reported.
- Positional encoding synergy: NAPE + entmax shows consistent gains, but the causal mechanisms are not analyzed; it is unclear how other schemes (e.g., YaRN, NTK-aware RoPE, ALiBi variants) interact with entmax sparsity and whether best practices generalize.
- Sparsity dynamics and interpretability: There is no analysis of per-layer/head sparsity patterns, their evolution during training, or whether sparsity harms/helps specific roles (local vs global heads); potential need for sparsity regularization is unexplored.
- Robustness and worst-case behavior: Behavior under adversarial or high-entropy inputs that collapse sparsity (i.e., near-uniform scores) is not studied; worst-case runtime and accuracy degradation and mitigation strategies are unspecified.
- Integration with existing frameworks: Interoperability with FlexAttention and mainstream transformer libraries (mask composition, custom score transforms, dropout) is not demonstrated; practical drop-in guidance is absent.
- Reproducibility details: While code is released, exact training configs (seeds, data preprocessing, optimizer hyperparameters, schedule) for all reported runs are not fully enumerated, limiting exact reproducibility of LM results.
Practical Applications
Immediate Applications
Below are deployable applications that can be implemented with the methods and findings in the paper today.
- Efficient training of long-context LLMs using differentiable sparse attention
- Sectors: software, cloud/ML infrastructure, education, legal, finance, healthcare
- Tools/products/workflows: integrate AdaSplash-2 (Triton kernels from the provided repo) into PyTorch training pipelines for transformer pretraining/fine-tuning at 8K–128K contexts; use α-entmax with α≈1.5 and NAPE positional encoding for long-context gains; instrument sparsity heatmaps to monitor block-sparsity emergence during training
- Value: per-step training time matches or exceeds FlashAttention-2 in moderate-to-high block sparsity regimes; improved long-context accuracy (RULER, HELMET)
- Assumptions/dependencies: speedups require moderate-to-high block sparsity (often >~60%)—more common at long contexts; current kernels target NVIDIA Ampere; benefits are largest in backward pass; training with α-entmax typically done from scratch or with dedicated finetuning; inference not yet fully optimized
- Cost and energy reduction for long-context training
- Sectors: cloud providers, enterprise ML teams, sustainability/Green AI initiatives
- Tools/products/workflows: swap softmax attention with AdaSplash-2 in long-context runs; track energy/token and wall-clock/token; right-size context windows where natural sparsity is high
- Value: lower GPU hours and electricity consumption for long-context training regimes
- Assumptions/dependencies: gains depend on sparsity and context length; limited by hardware (on-chip SRAM capacity) and kernel maturity on target GPUs
- Better long-context document assistants (batch/offline workflows)
- Sectors: legal (e-discovery, contract analysis), finance (10-K/earnings call analysis), healthcare (EHR summarization), research (literature review), compliance
- Tools/products/workflows: train domain-specific LLMs with α-entmax + NAPE at 32K+ tokens; deploy for batch document QA, extraction, and summarization where throughput (not latency) is critical
- Value: improved variable tracking, frequent/common word extraction, and ICL at long contexts; higher accuracy on long-doc tasks
- Assumptions/dependencies: inference kernels are not yet latency-optimized (multiple key scans), making this most suitable for offline/batch processing; requires training or fine-tuning with α-entmax
- Stronger in-context learning with longer exemplars
- Sectors: education (tutoring, grading), customer support, analytics
- Tools/products/workflows: construct prompt-heavy pipelines (e.g., 8–32K tokens) leveraging α-entmax + NAPE models for few-shot tasks (HELMET ICL)
- Value: material ICL accuracy gains at longer contexts; better use of relevant exemplars in prompts
- Assumptions/dependencies: models must be trained with α-entmax; latency constraints may limit real-time applications without further optimization
- Short-context parity with long-context readiness
- Sectors: general-purpose LLMs (chat, code, content), MLOps
- Tools/products/workflows: adopt α-entmax + NAPE training to match short-context performance (e.g., OLMES core_9mcqa) while unlocking long-context upside
- Value: retain or slightly improve short-context quality while enabling future long-context features without retraining from scratch
- Assumptions/dependencies: requires training recipe changes (positional encoding and α); performance can vary by dataset
- Dynamic sparsity-aware training instrumentation
- Sectors: ML tooling/MLOps
- Tools/products/workflows: log block-sparsity heatmaps during training; schedule context growth when sparsity increases; trigger kernel selection (α-entmax vs softmax) dynamically in research settings
- Value: operationalizes sparsity-driven efficiency; helps choose context sizes that give the best cost-quality trade-off
- Assumptions/dependencies: requires custom logging hooks; dynamic kernel switching is an engineering task
- Reusable GPU patterns: bitpacked block masks and histogram-on-SRAM
- Sectors: ML systems/compilers (Triton, CUDA), research labs
- Tools/products/workflows: apply the lightweight bitpacked masks and on-chip histogram accumulation to other block-sparse ops (e.g., block-sparse matmul, attention variants) to skip zero work cheaply
- Value: broadly useful GPU building blocks for dynamic sparsity
- Assumptions/dependencies: requires kernel engineering; correctness depends on robust overflow handling and careful packing
- Academic benchmarking and analysis of attention dispersion/representational collapse
- Sectors: academia/research
- Tools/products/workflows: use AdaSplash-2 to study how sparse attention changes behavior on long-context tasks and ICL; validate entmax smoothness regimes (Halley/Newton/Bracketing)
- Value: accelerates research into sparse attention, positional encodings, and long-context generalization
- Assumptions/dependencies: results may depend on α choices and dataset/domain specifics
Long-Term Applications
These applications require further research, engineering, scaling, or ecosystem adoption.
- Low-latency production inference for α-entmax attention
- Sectors: software products (chatbots, copilots), mobile/edge
- Tools/products/workflows: CUDA/Hopper-optimized kernels (TMA, WGMMA, warp specialization), fewer passes over keys, caching; integration with FlashAttention-3-like optimizations
- Dependencies: nontrivial kernel engineering; need to eliminate extra scans or amortize them; hardware-specific tuning
- Feasibility risks: current method prioritizes training; inference latency must be competitive with softmax kernels
- Framework-level integration and automatic kernel selection
- Sectors: ML frameworks (PyTorch/JAX), training stacks (DeepSpeed, Megatron), compilers (Triton/TVM)
- Tools/products/workflows: APIs that automatically select entmax vs softmax based on measured sparsity, context length, and target latency/throughput
- Dependencies: standardized telemetry on sparsity; robust fallbacks and mixed-mode training support
- Cross-modal and long-horizon transformers
- Sectors: vision (video transformers), speech/audio, reinforcement learning, robotics
- Tools/products/workflows: apply α-entmax attention to video sequences, audio streams, or trajectories where long-horizon dependencies cause softmax dispersion
- Dependencies: need to validate sparsity patterns in these domains; adapt positional/bias schemes (e.g., NAPE variants)
- Retrieval-augmented generation with larger context windows
- Sectors: enterprise search, knowledge management, customer support
- Tools/products/workflows: combine α-entmax with RAG to admit more retrieved chunks while keeping attention focused; dynamically adjust α to control dispersion
- Dependencies: latency-sensitive RAG pipelines need optimized inference; scheduler to tune α and context size based on retrieval quality
- Energy and policy reporting for long-context training
- Sectors: policy/regulatory, sustainability reporting, public sector HPC
- Tools/products/workflows: standardized metrics for energy/token and cost/token at long contexts; procurement and grant criteria encouraging sparse attention where effective
- Dependencies: community consensus on benchmarks and methodologies; tooling for reliable energy accounting
- Curriculum and adaptive α/encoding schedules
- Sectors: academia/research, advanced training pipelines
- Tools/products/workflows: train with schedules for α, bin count B, and positional encoding (e.g., gradual shift to NAPE) to mitigate attention dispersion and stabilize optimization
- Dependencies: requires large-scale ablations to establish best practices; risks of catastrophic forgetting or instability if schedules are poorly tuned
- Generalizing histogram-based normalization to other operators
- Sectors: optimization/OT, graphics, scientific computing
- Tools/products/workflows: extend on-chip histogram lower/upper bound initialization to other root-finding normalizations (e.g., Tsallis/Sinkhorn variants, projections onto probability simplices)
- Dependencies: theoretical guarantees must be re-established; hardware-aware solvers needed per operator
- Hardware co-design for dynamic sparsity
- Sectors: semiconductor, accelerator design
- Tools/products/workflows: ISA features for histogram accumulation, bitcount/fns/popcount, block-sparsity traversal, and SRAM-friendly reductions; memory systems that favor dynamic sparse patterns
- Dependencies: vendor adoption and ecosystem support (drivers, compilers); ROI depends on widespread sparse workloads
- Privacy-preserving and on-prem long-context analytics
- Sectors: healthcare, finance, government
- Tools/products/workflows: on-prem long-context models processing sensitive corpora with lower compute/energy budgets; improved explainability via exact-zero attention supports
- Dependencies: low-latency inference kernels; audits showing improved interpretability and consistent quality across domains
- Federated/edge training with long-context inputs
- Sectors: edge AI, IoT
- Tools/products/workflows: use of α-entmax to keep compute in check as context grows on-device; aggregation across nodes with variable context statistics
- Dependencies: memory and compute limits on edge hardware; robust sparse kernels across diverse devices
- Safety and interpretability tooling leveraging exact zeros
- Sectors: regulated industries, model auditing
- Tools/products/workflows: visualize and audit the sparse attention support to explain decisions on long documents; detect diffusion of attention mass as a risk factor
- Dependencies: robust UI and logging; empirical links between sparse patterns and human-interpretable rationales must be established
- Block-sparse ecosystems beyond attention
- Sectors: MoE systems, recommender systems, graph ML
- Tools/products/workflows: adopt bitpacked masks and fns/popcount traversal for dynamic block-sparse compute across layers (e.g., sparse experts, graph blocks)
- Dependencies: integration with high-level libraries; correctness and performance tuning per operator/model
Glossary
- AdaSplash-2: A hardware-aware method for efficient differentiable sparse attention based on entmax, designed to reduce normalization cost and exploit sparsity on GPUs. "In this paper, we introduce AdaSplash-2, which addresses this limitation through a novel histogram-based initialization that reduces the number of iterations needed to compute to typically 1--2."
- ALiBi: A positional bias scheme (Attention with Linear Biases) that encodes distance via linear penalties, improving extrapolation to long contexts. "the other half use ALiBi~\citep{press2022train}."
- bfloat16 (bf16): A 16-bit floating-point format with wider dynamic range than FP16, commonly used to speed up training with minimal accuracy loss. "set head dimension to and use bf16 precision."
- bisection: A bracketing root-finding method that iteratively halves an interval containing the root; robust but linearly convergent. "a bracketing method such as bisection~\citep{blondel2019learning}"
- bitpacking: A compact encoding technique that packs multiple small counters/bits into fixed-width integers to save memory and accelerate operations. "The bitpacking scheme naturally limits capacity since each bin can count up to items before overflow."
- block sparsity: A sparsity pattern where contiguous blocks in a matrix are zero, enabling block-level skipping on GPUs. "when block sparsity is moderate-to-high (e.g., 60\%)"
- causal attention: Attention constrained to past tokens (lower triangular), used in autoregressive models. "Runtime (forward + backward) as a function of input sparsity for causal attention."
- CUDA: NVIDIA’s parallel computing platform and programming model for GPUs. "outperforming a highly-optimized CUDA version of FlashAttention-2"
- dynamic sparsity: Input-dependent sparsity where the support (nonzeros) varies per instance, as induced by entmax. "Importantly, \entmax yields dynamic sparsity, where the pattern of zeros depends on the input ."
- entmax (α-entmax attention): A differentiable transformation generalizing softmax that produces sparse probability distributions for α>1. "A promising line of work is -entmax attention,"
- find-next-set (fns): A GPU instruction that locates the next set bit in a bitmask, enabling fast traversal of sparse blocks. "via GPU-native find-next-set (fns) instructions"
- FlashAttention-2: A highly optimized GPU attention algorithm that fuses and tiles operations to achieve IO-aware, memory-efficient softmax attention. "Later, FlashAttention-2~\citep{dao2023flashattention2} improved the original algorithm"
- Halley method: A higher-order root-finding algorithm using first and second derivatives for faster local convergence than Newton. "we apply Halley steps for "
- HBM (High-bandwidth memory): Off-chip GPU memory with high throughput but higher latency than on-chip SRAM. "High-bandwidth memory (HBM) provides large capacity but higher access latency than the smaller, faster on-chip SRAM~\cite{jia2018dissecting}."
- histogram-based initialization: An approximation that builds a coarse score histogram in SRAM to produce a tight initial estimate of the entmax normalizer. "a novel histogram-based initialization that reduces the number of iterations needed to compute to typically 1--2."
- hybrid solver: A safeguarded root-finding approach that switches among methods (e.g., Halley, Newton, secant, bisection) for robustness and speed. "recover the exact normalizer using a safeguarded hybrid solver"
- IO-aware: An optimization paradigm that accounts for memory movement costs, reducing HBM traffic by maximizing on-chip reuse. "By making the computation IO-aware and by fusing operations over tiles that fit in on-chip fast memory"
- kernel fusion: Combining multiple operations into a single GPU kernel to avoid intermediate memory traffic and improve throughput. "Kernel fusion is a core optimization that merges multiple operations into a single kernel, avoiding intermediate HBM reads/writes by directly producing final outputs."
- log-sum-exp: A numerically stable operation for computing log(∑exp), used here as the additive normalizer in softmax. "where is an additive log-sum-exp normalizer."
- NAPE: A positional encoding scheme mixing NoPE and ALiBi across heads to improve long-context modeling with entmax. "we also evaluate their proposed positional encoding scheme, NAPE"
- Newton updates: Iterative root-finding steps using first derivatives; here preferred over Halley for certain α due to stability. "making Newton updates more robust than Halley in practice."
- NoPE: No positional encoding; using raw content without positional biases in selected heads. "half of the heads use no positional encoding (NoPE; \citealt{kazemnejad2023impact})"
- online softmax: A streaming formulation of softmax that allows stable, single-pass accumulation and tiling. "via a GPU-aware implementation of online softmax~\citep{milakov2018online}"
- popc (population count): A GPU instruction that counts the number of set bits in a word, useful for sparse mask traversal. "make use of native GPU instructions like fns and popc (population count) for efficient traversal."
- RoPE: Rotary positional embeddings; a position encoding scheme used in many LLMs. "softmax baselines with RoPE~\citep{su2024roformer}"
- secant steps: A derivative-free root-finding update using two previous points; used when higher derivatives are unstable. "and secant steps for "
- sparsemax: The α=2 special case of entmax that projects onto the simplex with sparse outputs. "sparsemax (, \citealt{martins2016softmax})"
- SRAM: Fast on-chip GPU memory used to stage tiles/histograms for high-throughput computation. "store it in on-chip SRAM"
- tiling (tiled GPU implementations): Partitioning computation/data into blocks that fit in SRAM, enabling fused, memory-efficient kernels. "makes softmax particularly amenable to single-pass, tiled GPU implementations."
- TMA: Tensor Memory Accelerator; a Hopper-era GPU feature for efficient memory movement used by newer FlashAttention variants. "TMA, WGMMA instructions, warp specialization"
- Triton: A GPU kernel programming language for writing high-performance custom kernels in Python. "Implemented as custom Triton~\citep{triton-paper} kernels"
- warp specialization: Assigning different warps distinct roles (e.g., compute vs. memory) to increase GPU utilization. "TMA, WGMMA instructions, warp specialization"
- WGMMA: Warp-level General Matrix-Multiply Accumulate instructions on NVIDIA Hopper GPUs for fast matmul. "TMA, WGMMA instructions, warp specialization"
Collections
Sign up for free to add this paper to one or more collections.