Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter
Abstract: Prefill-decode (PD) disaggregation has become the standard architecture for large-scale LLM serving, but in practice its deployment boundary is still determined by KVCache transfer. In conventional dense-attention models, prefill generates huge KVCache traffics that keep prefill and decode tightly coupled within a single high-bandwidth network domain, limiting heterogeneous deployment and resource elasticity. Recent hybrid-attention architectures substantially reduce KVCache size, making cross-cluster KVCache transport increasingly plausible. However, smaller KVCache alone does not make heterogeneous cross-datacenter PD serving practical: real workloads remain bursty, request lengths are highly skewed, prefix caches are unevenly distributed, and inter-cluster bandwidth fluctuates. A naive design that fully externalizes prefill can therefore still suffer from congestion, unstable queueing, and poor utilization. We present Prefill-as-a-Service (PrfaaS), a cross-datacenter serving architecture that selectively offloads long-context prefill to standalone, compute-dense prefill clusters and transfers the resulting KVCache over commodity Ethernet to local PD clusters for decode. Rather than treating reduced KVCache as sufficient, PrfaaS combines model-side KV efficiency with system-side selective offloading, bandwidth-aware scheduling, and cache-aware request placement. This design removes the requirement that heterogeneous accelerators share the same low-latency RDMA fabric, enabling independent scaling of prefill and decode capacity across loosely coupled clusters. In a case study using an internal 1T-parameter hybrid model, a PrfaaS-augmented heterogeneous deployment achieves 54% and 32% higher serving throughput than homogeneous PD and naive heterogeneous baselines, respectively, while consuming only modest cross-datacenter bandwidth.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper explains a new way to run big AI LLMs faster and more flexibly by splitting their work across different datacenters. The idea is called “Prefill-as-a-Service” (PrfaaS). It sends only the right kind of work (the heavy “reading” part) to a remote cluster that’s really good at it, then ships a compact “memory” to a nearby cluster that’s great at the “writing” part. The paper shows how to do this safely and efficiently over normal datacenter networks, without needing ultra-fast specialized cables everywhere.
Key terms in plain words
- Prefill: When the model “reads” your long prompt and builds up its internal memory.
- Decode: When the model “writes” its answer, word by word, using that memory.
- KVCache: The model’s short-term memory—like a set of notes it keeps so it doesn’t have to re-read everything every time it writes the next word.
- Datacenter: A big building full of computers.
- RDMA vs. Ethernet: Think “private superhighway” (RDMA) versus “regular fast roads” (Ethernet). Superhighways are faster but harder and more expensive to set up between distant places.
What questions the paper asks
In simple terms, the paper asks:
- Can we split LLM work so that the “reading” happens in one place and the “writing” happens in another, even across different datacenters?
- Can we send the model’s memory (KVCache) over ordinary fast networks (Ethernet) without causing traffic jams?
- If we don’t send everything, which requests should we send to get the most benefit?
- How do we schedule and route requests so the system stays fast and stable even when traffic is bursty?
How they approached the problem
Think of this like a school project with two teams:
- Team A is excellent at quickly reading long articles and making concise notes (prefill).
- Team B is excellent at turning those notes into polished paragraphs (decode).
- The challenge: sharing the notes between teams across different buildings without clogging the hallways.
Here’s what the authors built:
- A smart split of work (PrfaaS):
- Only long, heavy “reading” jobs are sent to the special “Prefill” clusters (Team A) in another datacenter.
- Short or already-cached jobs stay local and get handled in the usual way.
- After reading, Team A sends a compact set of notes (the KVCache) over Ethernet to Team B to finish the writing.
- Models that produce smaller “notes”:
- Newer model designs (called “hybrid attention”) organize their memory so it’s much smaller than before.
- Smaller notes are easier to ship across datacenters without overwhelming the network.
- A “hybrid prefix cache”:
- The system keeps and reuses notes (prefixes) so it doesn’t redo work it already did. It stores different kinds of notes (some fixed-size, some growing with length) in a shared pool so they can be matched and reused efficiently.
- Bandwidth-aware scheduling:
- The system continuously watches the network and adjusts which requests get offloaded.
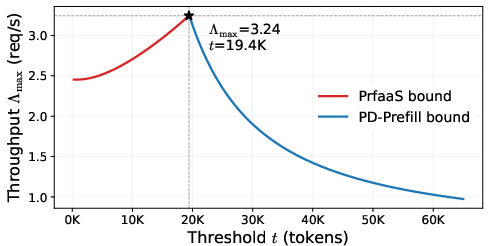
- It uses a simple rule: only send requests longer than a certain threshold (because long reads benefit most from fast “readers” and produce more useful notes per unit of network).
- When the link is busy, it keeps more work local; when the link is free, it can move more work (or even share cached notes across clusters).
- A simple throughput model to pick good settings:
- The authors built a math-based guide to choose:
- The length threshold for offloading,
- How many machines to assign to reading vs. writing in the local cluster,
- So the whole pipeline stays balanced and fast.
What they found and why it matters
Here are the main takeaways from their case study with a very large (1-trillion-parameter) model that uses the newer, smaller-memory design:
- It’s practical to send the model’s memory across datacenters over Ethernet:
- Because hybrid models produce much smaller KVCache, the cross-datacenter traffic stays modest (small enough that it doesn’t clog the network).
- Smart selection beats “send everything”:
- By offloading only long, uncached requests and keeping short ones local, the system avoids congestion and keeps both clusters busy in the best way.
- Big performance gains:
- Compared to a traditional single-cluster setup, their design achieved about 54% higher throughput (serving more requests per second).
- Compared to a naive “heterogeneous” setup that offloads everything without smart selection, it still improved throughput by about 32%.
- Time to first token (how fast you see the model start responding) improved a lot for long requests because those got priority treatment on faster “reading” hardware.
Why this matters:
- Better user experience for long prompts: Faster start and faster overall responses.
- More flexible and cost-effective deployments: You don’t need every kind of specialized hardware in the same place or on the same ultra-fast network.
- Easier scaling: You can grow prefill and decode capacity independently and place them where they make sense (e.g., near cheap power or available space).
- More resilient systems: Scheduling adapts to traffic spikes and changing network conditions.
What this could mean going forward
This work shows that new model designs (which create much smaller memory to send around) plus smart system design (which requests to offload, where to store and reuse notes, and how to schedule around bandwidth) can make cross-datacenter LLM serving practical. That means:
- Companies can mix different types of accelerators (some great at reading, some great at writing) even if they’re in different places.
- It reduces costs and increases flexibility as workloads change.
- It sets the stage for broader, more elastic AI services that can tap capacity across multiple regions without needing exotic networking everywhere.
In short, Prefill-as-a-Service turns a neat idea—splitting reading and writing across clusters—into a real, stable, and efficient way to serve very LLMs at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper. Each point is framed to enable concrete follow‑up work.
- Lack of end-to-end, real-network evaluation: results rely largely on a model-based case study; there’s no systematic measurement across varying inter-datacenter RTTs, loss rates, jitter, or shared-link contention.
- Tail latency behavior under burstiness: no queueing-theoretic or empirical analysis of P95/P99 TTFT and end-to-end latency when arrivals and link capacity fluctuate or during incast events.
- Stability and optimality of threshold-based routing: the dual-timescale scheduler lacks formal stability guarantees and convergence proofs under non-stationary traffic and bandwidth; no online auto-tuning method with regret bounds.
- Bandwidth sharing and multi-tenant isolation: how to allocate inter-cluster egress fairly among tenants, enforce QoS/SLOs, and prevent noisy-neighbor effects on the commodity Ethernet links is not addressed.
- Failure handling and correctness: no concrete protocol for mid-prefill/mid-transfer failures, retries, exactly-once/at-least-once semantics, or deduplication of partially transferred KVCache.
- Data security and privacy: encryption of KVCache in transit and at rest, key management, authentication/authorization between clusters, and the overhead of these mechanisms are unquantified; data residency and cross-border compliance are not discussed.
- KV integrity and tamper resistance: mechanisms to detect or prevent KV corruption/poisoning (e.g., integrity checksums, signatures) and their runtime costs are unspecified.
- Global KVCache metadata consistency: the design of the global KVCache manager (e.g., replication, leader election, failure recovery, consistency model, and scalability limits) is not detailed.
- Prefix cache management policies: eviction, deduplication, fragmentation control, and lookup latency in the hybrid cache pool (DRAM/SSD) are not quantified; impact on hit rates under realistic traces is unknown.
- Cross-cluster cache transfers: when and how to move cached prefixes across clusters, the algorithms used, associated bandwidth costs, and net benefits remain unspecified.
- Compatibility across heterogeneous hardware/software: ensuring binary/numeric compatibility so KV produced on one accelerator/stack decodes identically on another (e.g., kernels, precision, fused ops) is not validated.
- Determinism and output fidelity: impact of cross-hardware numerical differences on model outputs (e.g., drift in logits due to different BLAS/attention kernels) is not studied.
- Decode step-time modeling: decode throughput is treated as constant per step, but hybrid models can have context-length-dependent decode costs; the effect on scheduler decisions and capacity planning is not analyzed.
- Applicability beyond the studied hybrid architectures: generalization to dense-transformer, MoE, and multimodal models (with larger cross-attention states) is untested; KV throughput and transfer feasibility may differ substantially.
- Extreme long-context regimes: feasibility and performance for ultra-long inputs (e.g., ≥1M tokens) and how thresholds should adapt remain unexplored.
- Interaction with speculative decoding and advanced serving tricks: how speculation (and rescoring) alters decode capacity, TTFT, and routing thresholds is not evaluated.
- KV compression beyond architectural reductions: potential for on-the-fly KV compression (quantization, sparsification, entropy coding), the resulting accuracy/latency trade-offs, and decode compatibility are open.
- Transport-layer choices and tuning: multi-connection TCP is mentioned, but alternatives (e.g., QUIC, UDT, RoCEv2 across L3, MPTCP) and their performance under high BDP are not compared; BBR/CUBIC tuning for cross-DC is unexamined.
- Layer-wise prefill pipelining details: concrete implementation (buffering, ordering, backpressure between layers and network), correctness guarantees, and measured benefits are not provided.
- Admission control and overload management: policies for shedding load or degrading gracefully when inter-cluster bandwidth is constrained, and their impact on different SLO classes, are unspecified.
- Session stickiness and multi-turn agents: how to route multi-turn conversations to maximize KV reuse, avoid migrations, and ensure consistent cache locality across turns is not addressed.
- Workload realism and sensitivity: results use a single synthetic length distribution; sensitivity to real production traces (diurnal cycles, agentic loops, prefix-hit variability) is unknown.
- Cost and TCO analysis: there is no economic model incorporating accelerator prices, cross-DC egress fees, dedicated-line costs, operational overheads, and the trade-off with achieved throughput/latency.
- Energy and carbon footprint: net energy impact of added network transfer versus compute savings and its dependence on hardware mix and link utilization is unquantified.
- Regulatory and governance constraints: strategies for region-aware scheduling to comply with data residency and sector-specific regulations (e.g., HIPAA/PCI) are not presented.
- API and operational model for PrfaaS: service interface design, versioning/rollout across clusters, backward compatibility, and handling model/version skew between prefill and decode clusters are not specified.
- Scaling topology and hot-spot risks: behavior with many PrfaaS and PD clusters (N:M flows), contention at egress/ingress gateways, and scheduler strategies to balance across multiple paths are untested.
- Batching interactions: how prefill and decode batching policies interact with threshold routing (e.g., batch formation delays, cross-request coalescing) and their impact on TTFT are not analyzed.
- Multimodal KV/state: handling, sizing, and transport of vision/audio cross-attention states, and whether selective offload remains beneficial for multimodal prompts, is unexplored.
- Observability and telemetry: mechanisms to estimate incremental prefill length and bandwidth in real time without excessive overhead or privacy leakage (e.g., hashing of prefixes) are unspecified.
- Robustness to cloud-network variability: strategies for scheduler adaptation to sudden bandwidth drops, path changes, or noisy underlay (e.g., failover, path diversity) are not evaluated.
- Limits of decode scaling: saturation points for memory bandwidth and attention kernels on PD-D nodes and how they constrain the prefill/decode ratio in larger deployments are not characterized.
Practical Applications
Below is a structured synthesis of practical applications enabled by the paper’s Prefill-as-a-Service (PrfaaS) architecture, its selective offloading strategy, hybrid prefix-cache pool, bandwidth-aware dual-timescale scheduling, and the analytical throughput model. The items are grouped by deployability horizon and map to sectors, workflows, and feasibility considerations.
Immediate Applications
These uses can be deployed with hybrid-attention models and today’s serving stacks, leveraging commodity Ethernet between clusters and RDMA within clusters. The paper’s case study (54% throughput gain, 64% P90 TTFT reduction vs. homogeneous PD) indicates near-term impact.
- Prefill-as-a-Service offerings for long-context workloads — sectors: cloud/AI platforms, software
- What: Managed “prefill pods” hosted on compute-dense hardware; cross-datacenter KVCache streaming into local decode clusters over Ethernet.
- Tools/workflows: Integrations with vLLM/SGLang; Kubernetes operators for PrfaaS clusters; multi-connection TCP transport; layer-wise prefill pipelining; bandwidth-aware autoscaling.
- Assumptions/dependencies: Hybrid-attention models with low KV throughput; RDMA inside clusters; stable inter-cluster Ethernet; KV format compatibility; data governance for KV transfers.
- Heterogeneous accelerator utilization across clusters — sectors: cloud operations, semiconductors
- What: Run prefill on compute-optimized accelerators (e.g., H200, TPUv5p) and decode on bandwidth-optimized hardware (e.g., GPUs with high HBM bandwidth, Groq LPU), without co-locating on a single RDMA island.
- Tools/workflows: Scheduler plug-ins that map long uncached prefills to compute clusters; per-tenant hardware pools; throughput models guiding ratios (prefill:decode).
- Assumptions/dependencies: Commodity Ethernet suffices for KV transfer; accurate length-based routing; bandwidth monitoring and congestion feedback.
- Cost and latency optimization for enterprise long-context apps — sectors: finance, legal, healthcare, media, education
- What: Faster TTFT and higher throughput for document analysis, RAG, call summarization, code review, and tutoring by offloading only long uncached segments.
- Tools/workflows: Length-threshold routing (tuning via grid search); hybrid cache-aware request placement; policy to keep short requests local.
- Assumptions/dependencies: Significant share of long-context or incremental-prefill traffic; viable prefix-cache hit rates; compliance for cross-datacenter KV streaming.
- Bandwidth-aware routing and scheduling plugins for serving stacks — sectors: MLOps/software infrastructure
- What: Dual-timescale scheduler (short-term bandwidth/caching, long-term resource rebalance) as a drop-in component for vLLM/SGLang/Dynamo-based inference.
- Tools/workflows: Metrics for KV throughput Φ_kv, egress utilization, queue depths; autoscaler adjusting PD-P/PD-D ratios and routing thresholds in near real-time.
- Assumptions/dependencies: Exposed hooks/APIs for routing decisions; reliable telemetry; stable decode SLOs (e.g., tokens/s).
- Hybrid prefix-cache pool for agentic and multi-turn workloads — sectors: software/AI agents, contact centers
- What: Unified cache manager that stores linear-state (request-level) and full-attention KV blocks with block-aligned reuse and cross-cluster awareness.
- Tools/workflows: Unified KVCache metadata service; intra-cluster SSD/RAM cache tiers; policies for prefix- vs. transfer-cache blocks; cache rebalancing.
- Assumptions/dependencies: Serving frameworks supporting hybrid KV types; consistent block sizes and eviction semantics; data privacy for cached prefixes.
- Cross-availability-zone/datacenter capacity bursting — sectors: cloud operations, SRE/FinOps
- What: Opportunistically offload long prefills to underutilized remote clusters during bursts, keeping decode local to maintain latency guarantees.
- Tools/workflows: Admission control based on egress utilization; inter-cluster bandwidth budgets; failover and fallback policies.
- Assumptions/dependencies: Predictable inter-cluster bandwidth; burst detection; routing dampeners to avoid oscillation.
- Hybrid on-prem + cloud deployment for regulated use cases — sectors: healthcare, finance, government
- What: Keep decode and sensitive state local; offload long prefills to controlled cloud clusters when allowed; transport only KVCache (not full inputs).
- Tools/workflows: Data residency tagging; allowlists for KV-only transfer; per-request routing based on data classification.
- Assumptions/dependencies: Legal clarity on KV material’s sensitivity; encryption in transit; auditable logs.
- Network tuning for KV transfers — sectors: networking, SRE
- What: Use multi-connection TCP, congestion monitoring integrated with scheduler to prevent persistent egress congestion and maintain high utilization.
- Tools/workflows: TCP CC parameter tuning; QUIC trials; pacing/shaping near bandwidth ceilings; loss/retransmission signal feeds to routing.
- Assumptions/dependencies: Cooperation with network teams; link variability monitoring; backpressure hooks to inference servers.
- SLA and pricing models for long-context tiers — sectors: cloud/AI SaaS
- What: Introduce “long-context optimized” tier where long prefills get priority on PrfaaS; price based on cross-cluster bandwidth consumption and compute savings.
- Tools/workflows: Metering of KV bytes transferred, Φ_kv-based cost models; customer-visible SLOs (TTFT bands).
- Assumptions/dependencies: Billing platform support; clear capacity planning; customer segmentation.
Long-Term Applications
These opportunities need additional research, standardization, hardware support, or ecosystem maturity.
- Cross-vendor PrfaaS marketplaces and APIs — sectors: cloud marketplaces, B2B platforms
- What: Standardized PrfaaS endpoints where third parties sell prefill capacity; decoders subscribe to KV streams via open KV formats/APIs.
- Tools/workflows: Open KVCache interchange format; service discovery; secure brokering and settlement.
- Assumptions/dependencies: Interoperability standards; strong authentication; performance isolation guarantees.
- Deeper hardware specialization pipelines — sectors: semiconductors, cloud
- What: Dedicated prefill-only clusters (e.g., Rubin CPX-like) paired with decode-only fabrics (e.g., LPU-like) across datacenters, coordinated by bandwidth-aware schedulers.
- Tools/workflows: Hardware-aware routing; model partitioning attuned to hybrid stacks; NIC or DPU acceleration for KV egress/ingress.
- Assumptions/dependencies: Mature heterogeneous accelerator supply; software support for mixed vendors; cross-vendor telemetry.
- KVCache compression, encryption, and NIC/DPU offload — sectors: networking, security
- What: Inline KV compression codecs (lossless or bounded-loss) and transport encryption offloaded to SmartNICs/DPUs to reduce bandwidth and latency overheads.
- Tools/workflows: New codecs tuned to hybrid models; hardware TLS/TCP/QUIC termination; per-layer prioritization.
- Assumptions/dependencies: Acceptable accuracy/latency trade-offs; NIC programmability; compliance with data protection regimes.
- CDN-like KV networks for common prefixes — sectors: cloud/CDN, SaaS
- What: Distribute hot system prompts or shared prefix blocks near decoders across regions to minimize repeated prefill cost.
- Tools/workflows: KV popularity tracking; cache placement algorithms; privacy-preserving multi-tenant sharing.
- Assumptions/dependencies: De-duplication without leaking tenant data; cache invalidation policies; WAN-aware placement.
- Carbon- and cost-aware routing — sectors: sustainability, policy, FinOps
- What: Shift long prefills to regions with cleaner or cheaper energy and sufficient bandwidth; decode remains close to users.
- Tools/workflows: Realtime carbon intensity/cost signals; scheduler objective functions incorporating eco-costs; compliance tagging.
- Assumptions/dependencies: Accurate signals; predictable inter-region links; governance for cross-border KV transfers.
- Edge/MEC prefill with cloud decode — sectors: telecom, consumer devices, robotics
- What: Perform long-context prefill at edge nodes (5G MEC, on-device) and stream KV to cloud decoders for AR/VR assistants, in-vehicle copilots, or industrial robots.
- Tools/workflows: Footprint-optimized hybrid models; intermittent connectivity handling; local caching.
- Assumptions/dependencies: Adequate edge compute; stable uplink; robust failure recovery.
- Training–inference co-design to minimize transferable KV — sectors: AI research, model development
- What: Architectures and training regimes (e.g., higher linear:full ratios, better state sharing) that reduce KV throughput without degrading quality.
- Tools/workflows: Co-optimization loops using Φ_kv in the objective; profiling pipelines; ablation frameworks.
- Assumptions/dependencies: Maintained model quality; reproducibility across tasks; inference frameworks that exploit new state formats.
- Serverless LLM pipelines with function-like prefill — sectors: serverless/MLOps, software
- What: Event-driven PrfaaS invocations with per-request billing and automatic scaling; decoders subscribe to KV streams on demand.
- Tools/workflows: Cold-start mitigation (warm pools); KV stream backpressure; function composition for multi-stage agents.
- Assumptions/dependencies: Fast provisioning; strong multi-tenant isolation; cost-effective egress.
- Regulatory-compliant cross-border serving — sectors: public policy, legal, regulated industries
- What: Define policies and tooling to treat KV as derived/ephemeral state with specific compliance profiles; audit trails for KV transfers.
- Tools/workflows: Data classification for KV; regional allow/deny lists; cryptographic audit logs.
- Assumptions/dependencies: Regulator acceptance of KV classification; standards for retention and deletion.
- Academic benchmarks and simulators for Φ_kv and scheduling — sectors: academia, open-source
- What: Open benchmark suites measuring KV throughput, scheduling under bursty traffic and fluctuating bandwidth; reproducible PrfaaS experiments.
- Tools/workflows: Traffic generators; simulators for dual-timescale policies; shared datasets and scripts.
- Assumptions/dependencies: Community adoption; representative hybrid models; standardized metrics.
- Multi-tenant bandwidth arbitration and fairness — sectors: cloud, enterprise SaaS
- What: Schedulers ensuring tenant-level fairness and SLAs on shared cross-cluster links; congestion-aware isolation and prioritization.
- Tools/workflows: Weighted fair-queuing for KV streams; token buckets per tenant; admission control per tier.
- Assumptions/dependencies: Accurate per-tenant metering; enforceable QoS on WAN; policy frameworks.
- Integration with speculative decoding and advanced inference tricks — sectors: AI systems
- What: Combine PrfaaS with speculative decoding, mixtures of experts, or distillation to further reduce TTFT and compute, while respecting bandwidth ceilings.
- Tools/workflows: Joint schedulers aware of speculation acceptance rates; hybrid cache updates; end-to-end latency models.
- Assumptions/dependencies: Stable speculative performance; compatibility with hybrid caches; complexity manageable for operators.
Notes on feasibility across items:
- Many immediate applications presuppose hybrid-attention models (e.g., Kimi Linear, SWA-based) with lower KV throughput; dense models may overwhelm Ethernet.
- RDMA-class networking is assumed within clusters; commodity Ethernet suffices inter-cluster if selective offloading and threshold routing are in place.
- Real gains depend on accurate profiling of Φ_kv, robust congestion monitoring, and adaptive routing; naive externalization risks congestion and poor utilization.
- Compliance, privacy, and regional regulations can constrain cross-datacenter KV streaming; encryption, auditability, and data classification are necessary safeguards.
Glossary
- agentic workloads: Multi-step, autonomous application patterns where an LLM orchestrates tools or sub-requests, often producing incremental prefills. "With the growing adoption of agentic workloads, the majority of requests are incremental prefills with prefix cache hits."
- bandwidth-aware scheduler: A scheduling component that adjusts routing based on current and predicted network bandwidth to prevent congestion and maximize throughput. "a bandwidth-aware scheduler to react to fluctuating link conditions before congestion accumulates"
- bandwidth-imposed throughput ceiling: The maximum processing rate limited by available network egress rather than compute. "The PrfaaS cluster has a bandwidth-imposed throughput ceiling $B_{\text{out} / S_{\text{kv}(l_{\text{long})$."
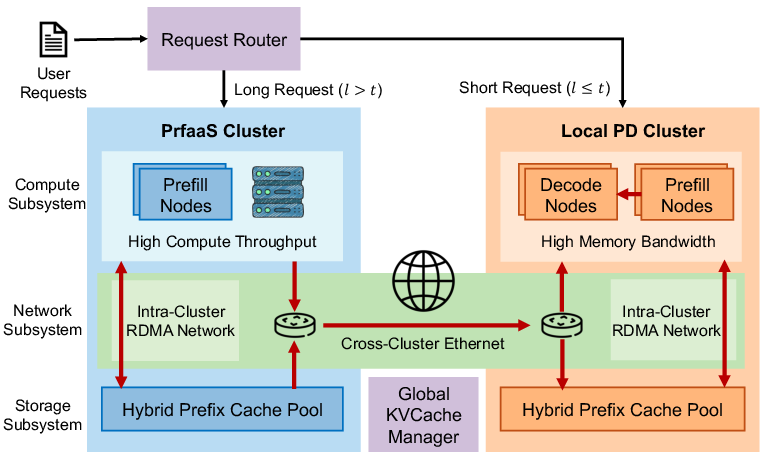
- cache-affine node: A node chosen for execution due to favorable cache locality (e.g., having the needed KVCache/prefix). "the request router uses this information to select the prefill cluster and the cache-affine node within it."
- cache rebalancing: Redistributing cached entries across nodes or clusters to relieve hotspots and improve hit rates. "the KVCache manager also performs cache rebalancing to mitigate hotspots."
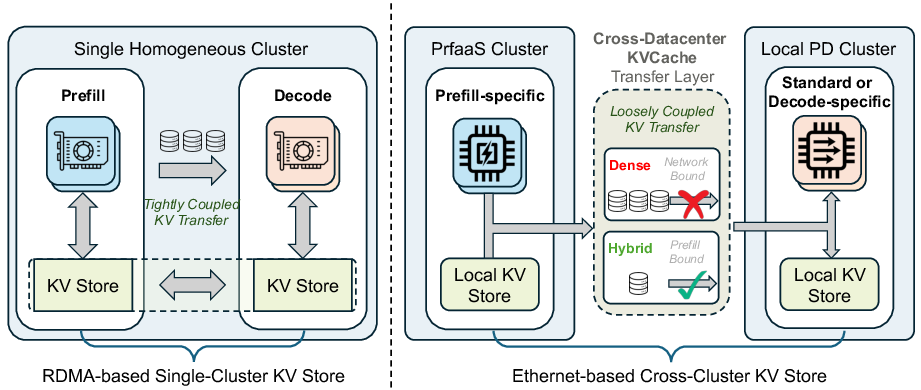
- commodity Ethernet: Standard, non-RDMA datacenter networking used for general-purpose packet transport. "transfers the resulting KVCache over commodity Ethernet to local PD clusters for decode."
- congestion monitoring: Observing loss, retransmissions, or queue buildup to detect and react to network congestion. "congestion monitoring integrated with the scheduler to detect loss and retransmission signals early and prevent congestion accumulation."
- converging pipeline: A processing topology where parallel upstream stages merge into a single downstream stage. "Together, they form a converging pipeline:"
- cross-cluster cache transfer: Moving cached state between clusters to exploit the best available prefix and reduce recomputation. "cross-cluster cache transfer is feasible as well"
- cross-datacenter KVCache: Transferring attention key-value cache across datacenters to decouple prefill and decode. "PrfaaS: Multi-cluster disaggregated inference via cross-datacenter KVCache."
- datacenter-scale RDMA fabric: A high-throughput, low-latency RDMA network spanning many machines within a datacenter. "a single datacenter-scale RDMA fabric"
- dual-timescale scheduling: A strategy combining fast, reactive routing decisions with slower, periodic resource reallocation. "we design a dual-timescale scheduling algorithm that treats cross-cluster bandwidth and throughput as the primary constraints"
- egress bandwidth: Outbound network capacity available to send data from a cluster or node. "the egress bandwidth $B_{\text{out}$ of a prefill cluster must exceed the aggregate rate at which the cluster produces KVCache."
- egress load: The current outbound traffic volume leaving a cluster or node. "The aggregate PrfaaS egress load is therefore approximately 13\,Gbps"
- global KVCache manager: A system component tracking KVCache metadata and placement across clusters to guide routing and reuse. "A global KVCache manager maintains KVCache metadata across all clusters."
- GQA: Grouped-Query Attention; an attention variant that reduces memory/computation by grouping queries. "MiniMax-M2.5, a representative dense model with GQA, at various input lengths."
- grid search: Exhaustive search over discrete parameter combinations to find an optimal operating point. "a grid search over and efficiently finds the optimal operating point."
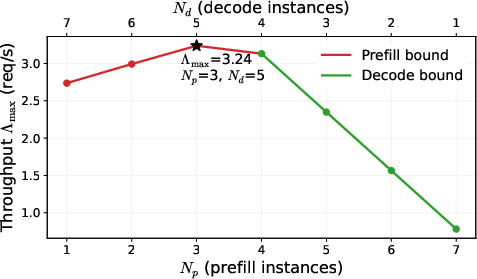
- heterogeneous deployment: Using different hardware types for different inference phases or roles within one system. "a PrfaaS-augmented heterogeneous deployment achieves 54\% and 32\% higher serving throughput"
- heterogeneous serving: Serving architecture where prefill and decode run on distinct, specialized accelerator types. "In principle, PD disaggregation should also unlock a more ambitious goal: heterogeneous serving"
- hybrid-attention architectures: Models mixing full attention layers with linear or bounded-state layers to reduce KV growth. "Recent hybrid-attention architectures substantially reduce KVCache size"
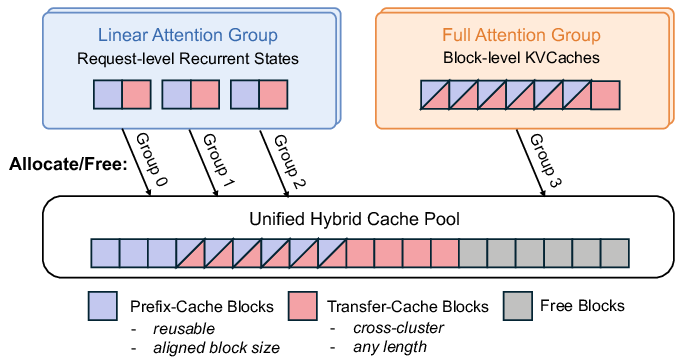
- hybrid models: LLMs that interleave different attention mechanisms (e.g., linear and full attention) for efficiency. "In hybrid models, the recurrent states of linear attention or SWA layers are request-level"
- hybrid prefix cache pool: A shared cache system that manages both fixed-size recurrent states and variable-length full-attention KV blocks. "we build a hybrid prefix cache system tailored for cross-cluster KVCache transfer"
- Kimi Delta Attention (KDA): A linear-complexity attention mechanism used in hybrid architectures to lower KV/state growth. "such as Kimi Delta Attention (KDA)"
- KV throughput: The rate at which prefill produces KVCache, typically measured as size per unit time. "Figure~\ref{fig:kv_throughput_minimax_m25} shows the KV throughput of MiniMax-M2.5"
- KVCache: Cached key and value tensors produced during prefill, reused during decode to avoid recomputation. "the KVCache produced by prefill must be transferred quickly enough to avoid stalling computation."
- Language Processing Unit (LPU): Groq’s specialized accelerator optimized for high-throughput, memory-intensive language decoding. "Groq's Language Processing Unit (LPU)"
- layer-wise prefill pipelining: Overlapping KVCache generation with transfer by streaming per-layer outputs. "we combine layer-wise prefill pipelining to overlap KVCache generation with transmission"
- length-based threshold routing: Policy that offloads only requests exceeding a length threshold to remote prefill to save bandwidth. "PrfaaS uses length-based threshold routing to offload only sufficiently long requests"
- linear attention: Attention mechanisms with linear-time complexity and bounded state, reducing KV growth with sequence length. "linear attention and SWA maintain linear computation cost"
- MLA: Multi-Head Latent Attention (as used in cited models), a more KV-efficient full-attention variant. "MLA contributes roughly a 4.5 compression over GQA"
- memory-bandwidth-intensive: Workloads dominated by memory transfer rates rather than compute, typical of decode. "decode is primarily memory-bandwidth-intensive."
- multi-connection TCP transport: Using multiple TCP connections in parallel to better utilize available network bandwidth. "multi-connection TCP transport to fully utilize the available bandwidth"
- opportunistic remote capacity: Leveraging available compute in other regions/datacenters as an elastic extension of local capacity. "opportunistic remote capacity"
- PD cluster: A local cluster that can perform both prefill and decode under the PD-disaggregated architecture. "Local PD clusters perform PD-disaggregated serving and can complete inference for a request end to end."
- PD disaggregation: Splitting inference into a compute-heavy prefill phase and a memory-bandwidth-heavy decode phase across nodes. "Prefill-decode (PD) disaggregation has become the dominant deployment paradigm"
- PD-D: The decode nodes within a PD cluster responsible for token generation using cached KV. "PD-D (the decode nodes within a PD cluster)"
- PD-P: The prefill nodes within a PD cluster that execute the initial context computation. "PD-P (the prefill nodes within a PD cluster)"
- prefix cache pool: A storage system that keeps reusable prefixes (KV/state) across requests to reduce repeated computation. "Prefix cache pools allow the serving system to offload KVCache to distributed host memory and SSDs within a cluster"
- prefix matching: Reusing the longest shared prefix of input tokens by matching cached KV/state segments. "support partial prefix matching"
- prefix-cache blocks: Cache blocks containing reusable, fully populated KV or state for prefix reuse. "Prefix-cache blocks must be fully populated before they can be reused across requests."
- PrfaaS: Prefill-as-a-Service; a selective, cross-datacenter prefill service that streams KVCache to local decode. "We present Prefill-as-a-Service (PrfaaS), a cross-datacenter serving architecture"
- RDMA fabric: A high-performance network supporting Remote Direct Memory Access with low latency and high throughput. "share the same low-latency RDMA fabric"
- RDMA island: A tightly coupled cluster boundary sharing an RDMA fabric, often limiting flexible heterogeneity. "forcing heterogeneous hardware into one tightly coupled deployment... behind the same RDMA island"
- recurrent state: Fixed-size, request-level state maintained by linear attention/SWA layers independent of sequence length. "the recurrent states of linear attention or SWA layers are request-level"
- routing threshold: The length cutoff determining whether a request is offloaded to remote prefill or handled locally. "the routing threshold "
- Rubin CPX: NVIDIA accelerator/architecture aimed at high-throughput long-context prefill. "NVIDIA's Rubin CPX explicitly targets high-throughput long-context prefill"
- Service Level Objective (SLO): A performance target (e.g., tokens/sec) used to configure decode and batching. "are treated as SLO-governed constants."
- Sliding Window Attention (SWA): An attention mechanism with a fixed-size local context window that bounds state size. "Sliding Window Attention (SWA)"
- sparse attention: Attention pattern restricting connections to reduce compute while retaining key dependencies. "Sparse attention reduces the amount of computation and can lower prefill latency"
- throughput model: An analytical model capturing compute and bandwidth limits to guide routing and resource allocation. "we construct an analytical throughput model that captures the compute and bandwidth constraints"
- Time To First Token (TTFT): Latency from request arrival to the first generated token. "64\% lower P90 TTFT than a homogeneous PD-only baseline"
- transfer-cache blocks: Temporary cache blocks used for cross-cluster KV transfer and discarded after use. "Transfer-cache blocks hold the KVCache produced at the tail of a prefill request for PD-disaggregated transfer"
- VPC peering: Private interconnection between virtual networks used here for inter-cluster communication. "inter-cluster links rely on VPC peering or dedicated lines"
Collections
Sign up for free to add this paper to one or more collections.