- The paper presents TaiChi, a unified system that combines PD aggregation and disaggregation to optimize LLM serving while balancing TTFT and TPOT constraints.
- It introduces innovative scheduling methods—flowing decode and length-aware prefill scheduling—to dynamically reallocate resources based on real-time SLO needs.
- Experimental results show TaiChi improves goodput by up to 77% and significantly reduces latency, with TTFT and TPOT reductions of up to 13.2× and 1.69× respectively.
Prefill-Decode Aggregation or Disaggregation: A Unified Approach for Optimal LLM Serving
The paper "Prefill-Decode Aggregation or Disaggregation? Unifying Both for Goodput-Optimized LLM Serving" (2508.01989) addresses a critical issue in the deployment of LLMs for real-time applications, specifically focusing on the trade-offs between prefill-decode (PD) aggregation and disaggregation techniques. The authors introduce TaiChi, a novel system designed to unify these approaches, thereby optimizing goodput across varying service level objectives (SLOs) related to time-to-first-token (TTFT) and time-per-output-token (TPOT).
Service-Level Objectives and Current Challenges
LLM deployments are often constrained by SLOs that delineate acceptable limits for TTFT and TPOT, crucial for maintaining user experience in applications like chatbots and summarization services. The PD aggregation places prefill and decode phases on the same hardware to maximize resource utilization, achieving low TTFT but potentially high TPOT due to interference. Conversely, PD disaggregation separates these phases across different hardware resources, optimizing TPOT but often leading to increased TTFT due to queuing delays.
The paper presents evidence that under balanced SLOs, neither approach is wholly satisfactory: PD aggregation violates TPOT constraints due to prefill-decode interference, while PD disaggregation faces TTFT challenges arising from limited prefill processing capacity.
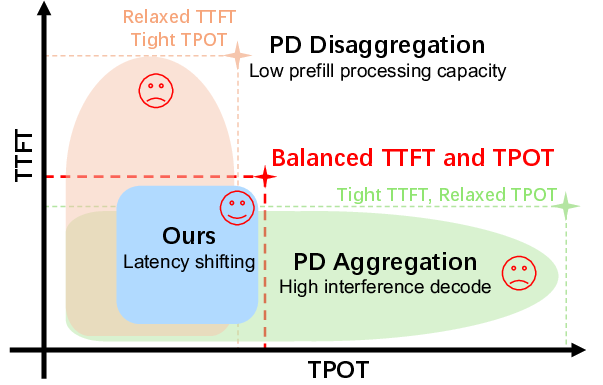
Figure 1: Distribution of requests' TTFT and TPOT under different scheduling approaches, demonstrating the inadequacy of PD aggregation and disaggregation under balanced SLO conditions.
Introduction of TaiChi
TaiChi is proposed as a unified system that integrates the strengths of both PD aggregation and disaggregation. This system is characterized by differentiated-capability GPU instances: prefill-heavy instances (fast prefill with high-interference decode) and decode-heavy instances (low-interference decode with slower prefill). By adjusting the ratio of these instances and their configuration, TaiChi can dynamically adapt to meet various SLO requirements.
The core innovation in TaiChi is its hybrid-mode inference, which enables strategic latency shifting. This approach reallocates resources from requests already satisfying their SLOs to ones at risk of violation, maximizing the number of SLO-attained requests. This fine-grained resource adjustment is managed through two novel scheduling methods: "flowing decode scheduling" for controlling TPOT and "length-aware prefill scheduling" for managing TTFT.
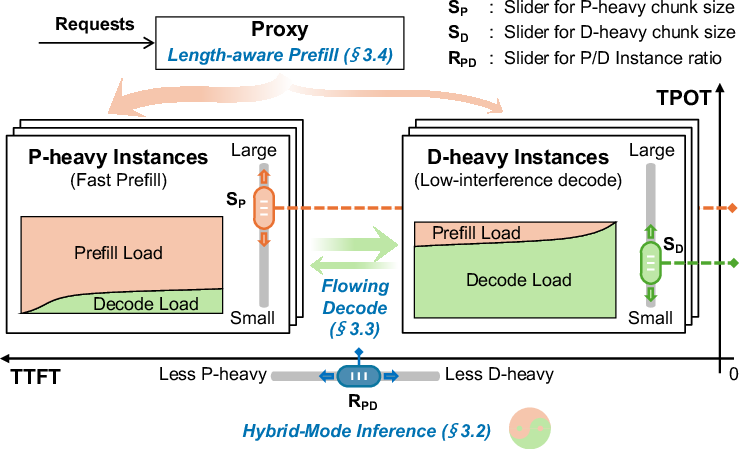
Figure 3: The system overview of TaiChi, highlighting its differentiated-capability instances enabling dynamic SLO adaptability.
Experimental Results
The paper presents extensive experiments demonstrating TaiChi's effectiveness. Under balanced SLO conditions, TaiChi improved goodput by up to 77% compared to state-of-the-art systems by successfully managing the trade-offs between TTFT and TPOT through strategic resource reallocation.
Key metrics from the experiments include significant reductions in TTFT (up to 13.2×) and TPOT (up to 1.69×) relative to traditional PD aggregation and disaggregation approaches. These improvements are attributed to the system's ability to dynamically adjust its instance configurations in response to the precise requirements of different tasks and workloads.
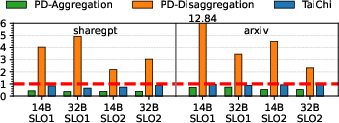
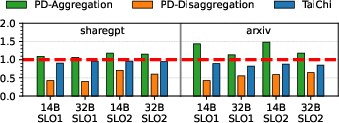
Figure 5: TTFT normalized to the SLO, illustrating TaiChi's efficiency in reducing latency compared to baseline approaches.
Implications and Future Directions
This research suggests that the dichotomy between aggregation and disaggregation in LLM serving systems can be overcome through a hybrid approach that leverages the best aspects of each method. The TaoChi system showcases how architectural flexibility, coupled with intelligent scheduling strategies, can lead to significant improvements in the efficiency of LLM deployments.
Future directions highlighted by the authors include exploring further optimizations in latency shifting strategies and extending the system to accommodate even more diverse workloads and SLO requirements. Additionally, the concepts developed in TaiChi could be applied to other complex, multi-phase computational tasks beyond LLM serving.
Conclusion
The paper concludes by affirming the viability of unifying PD aggregation and disaggregation for enhanced goodput in LLM serving. TaiChi's architecture and scheduling innovations demonstrate substantial improvements over current state-of-the-art methods, pointing the way towards more efficient, adaptable LLM deployment strategies that can effectively meet the complex demands of varied application environments.