Enhancing LLM Efficiency: Targeted Pruning for Prefill-Decode Disaggregation in Inference
Published 29 Aug 2025 in cs.CL and cs.AI | (2509.04467v1)
Abstract: LLMs demonstrate exceptional capabilities across various tasks, but their deployment is constrained by high computational and memory costs. Model pruning provides an effective means to alleviate these demands. However, existing methods often ignore the characteristics of prefill-decode (PD) disaggregation in practice. In this paper, we propose a novel pruning method for PD disaggregation inference, enabling more precise and efficient block and KV Cache pruning. Our approach constructs pruning and distillation sets to perform iterative block removal independently for the prefill and decode stages, obtaining better pruning solutions. Moreover, we introduce a token-aware cache pruning mechanism that retains all KV Cache in the prefill stage but selectively reuses entries for the first and last token sequences in selected layers during decode, reducing communication costs with minimal overhead. Extensive experiments demonstrate that our approach consistently achieves strong performance in both PD disaggregation and PD unified settings without disaggregation. Under the default settings, our method achieves a 20.56% inference speedup and a 4.95 times reduction in data transmission bandwidth consumption.
The paper introduces a stage-aware pruning strategy that iteratively removes redundant blocks in prefill and decode stages using cosine similarity.
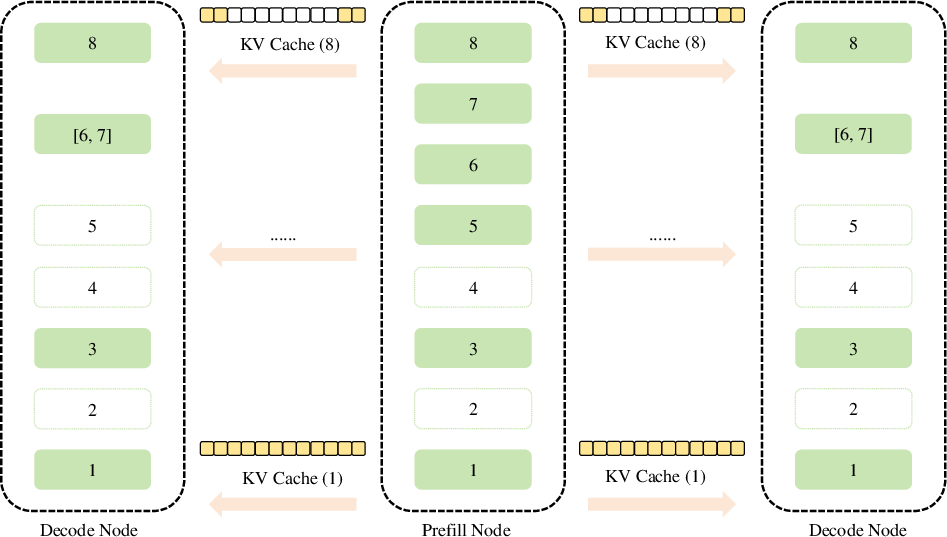
It leverages token-aware cache pruning to reduce significant KV Cache transmission overhead and optimize resource usage.
Experimental evaluations across multiple LLMs and benchmarks confirm that the targeted pruning method enhances inference efficiency with minimal performance loss.
Enhancing LLM Efficiency: Targeted Pruning for Prefill-Decode Disaggregation in Inference
The paper "Enhancing LLM Efficiency: Targeted Pruning for Prefill-Decode Disaggregation in Inference" (2509.04467) addresses two critical challenges in deploying LLMs with prefill-decode (PD) disaggregation: handling heterogeneous pruning sensitivities in the prefill and decode stages and managing significant bandwidth overhead arising from KV Cache transmission. Presenting a novel strategy, the authors propose stage-aware pruning and a token-aware cache pruning mechanism aimed at achieving computational efficiency while maintaining model performance.
Stage-Aware Strategy for Optimal Block Removal
The core innovation lies in the introduction of a pruning approach that leverages the intrinsic characteristics of PD disaggregation (Figure 1). This is achieved through the implementation of a stage-specific pruning strategy allowing for independent, iterative block removal tailored to both the prefill and decode stages.
Figure 1: Overview of our pruning method combined with PD disaggregation...
Iterative Block Removal
The proposed iterative block removal approach is executed separately for prefill and decode stages. By leveraging stage-specific iterative optimization, this strategy identifies optimal combinations of k blocks to prune such that performance loss is minimized. Using cosine similarity between block inputs and outputs, the most redundant blocks are earmarked for removal.
The pruning set Pinitial initially includes the Top⌈2k⌉ blocks with highest redundancy as assessed by cosine similarity:
Pinitial={blockiri∈Top⌈2k⌉({r1,r2,…,rL})}
Concomitantly, a distillation set D is created by filtering pairs of consecutive blocks meeting the criterion di≥dT and are not present in Pinitial. Here di is calculated by:
Iterative optimization refines the removal set to minimize performance impacts across both stages, employing temperature-controlled randomness to approach globally optimal solutions.
Performance Evaluation
Extensive experiments with several LLMs, including LLaMA3.1-8B, LLaMA2-13B, Qwen2.5-7B, and Qwen2.5-14B across benchmarks like MMLU, CMMLU, PIQA, and more revealed that the proposed method consistently achieves higher performance relative to existing techniques. This can be seen in key benchmarks, where the proposed pruning method demonstrates marked innovations (Table 3).
Note: Results for additional large models, datasets, and metrics which demonstrate this robustness are detailed in the supplementary material provided (Appendix \ref{Larger Model, More Datasets and Additional Metric}).
Implications and Future Work
The proposed methodology offers considerable improvements in inference efficiency for LLMs deployed with PD disaggregation, demonstrating both theoretical significance and practical utility. It aligns the pruning approach with stage specific resource demands, thereby optimizing not just for reduced model size but also for bandwidth efficiency, crucial in large scale distributed environments. However, challenges remain, particularly in fully exploring the complex interplay between attention heads in the stacking layers for even more effective pruning strategies. Future research may explore incorporating MoE pruning into the current PD disaggregation framework. The presented method lays the groundwork for future developments in model compression, offering insights that could extend to memory optimization techniques within PD disaggregation as evidenced by contemporary works such as DistServe and MemeServe.
Conclusion
This paper expounds on a novel pruning method that has emerged as a meaningful contribution to the ongoing improvements in LLM inference efficiency through its strategic integration with PD disaggregation. By utilizing its stage-specific iterative block removal strategy and selective KV Cache mechanism, the approach effectively mitigates two critical challenges in PD disaggregation: heterogeneous pruning sensitivity and substantial bandwidth overhead. Future research can further integrate this targeted pruning method with advanced management techniques to optimize broader applications in distributed LLM systems.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.