- The paper introduces CAL2M, a framework that eliminates calibration needs by using an assistant-eye camera for scale rectification.
- It leverages epipolar-guided intrinsic and pose correction along with TPS-based non-linear sub-map alignment to ensure global consistency.
- Experimental evaluations on KITTI and Argoverse datasets demonstrate state-of-the-art localization accuracy and drift-free mapping.
CAL2M: Calibration-Free Kilometer-Level SLAM using Visual Geometry Foundation Models and an Assistant Eye
Motivation and Contributions
Visual Geometry Foundation Models (VGFMs) demonstrate robust zero-shot 3D reconstruction capabilities, yet their deployment in long-term, kilometer-scale SLAM remains problematic. Conventional approaches rely on linear alignment methods (e.g., Sim3, SL4) for incremental sub-map merging, which fail to account for the non-linear distortions and scale ambiguities characteristic of VGFM outputs. This results in geometric misalignment, map divergence, and persistent scale drift—especially noticeable in open-loop, long trajectory scenarios.
To address these constraints, CAL2M is introduced as a plug-and-play, calibration-free SLAM framework, compatible with any VGFM backbone. CAL2M leverages an assistant-eye camera, employing the geometric prior of constant physical spacing for scale rectification, decoupled from pre-calibration or rigid synchronization. The framework includes an epipolar-guided intrinsic and pose correction mechanism grounded in feature matching and fundamental matrix decomposition, obviating residual geometric errors arising from affine ambiguity and intrinsic uncertainties. A global mapping strategy founded on anchor propagation and non-linear (TPS-based) sub-map alignment further ensures global consistency and eliminates structural distortions inherent in deep models.

Figure 1: Comparison of VGFM-based incremental mapping, highlighting global divergence and drift with linear alignment, and stable mapping with CAL2M.
System Architecture and Technical Innovations
CAL2M comprises sequential sub-map construction with both primary and assistant eye image streams. Keyframes are determined via optical flow disparity to guarantee sufficient parallax. Submaps are processed using VGFM inference, generating local intrinsics, poses, and dense depth. The assistant-eye physical baseline—constant but unknown—rectifies scale ambiguity, unifying metric scale globally. Pose graph optimization (PGO) is performed jointly for both camera streams, with assistant trajectory implicitly parameterized relative to primary via a static extrinsic.
Epipolar-guided correction aligns intrinsics by constructing a feature-matching test bank and analyzing essential matrix spectral properties. This facilitates robust intrinsic selection and subsequent pose rectification, using analytical models derived from fundamental matrix decomposition for both translation and rotation corrections. Adaptive damping is introduced, modulating correction strength based on geometric confidence.
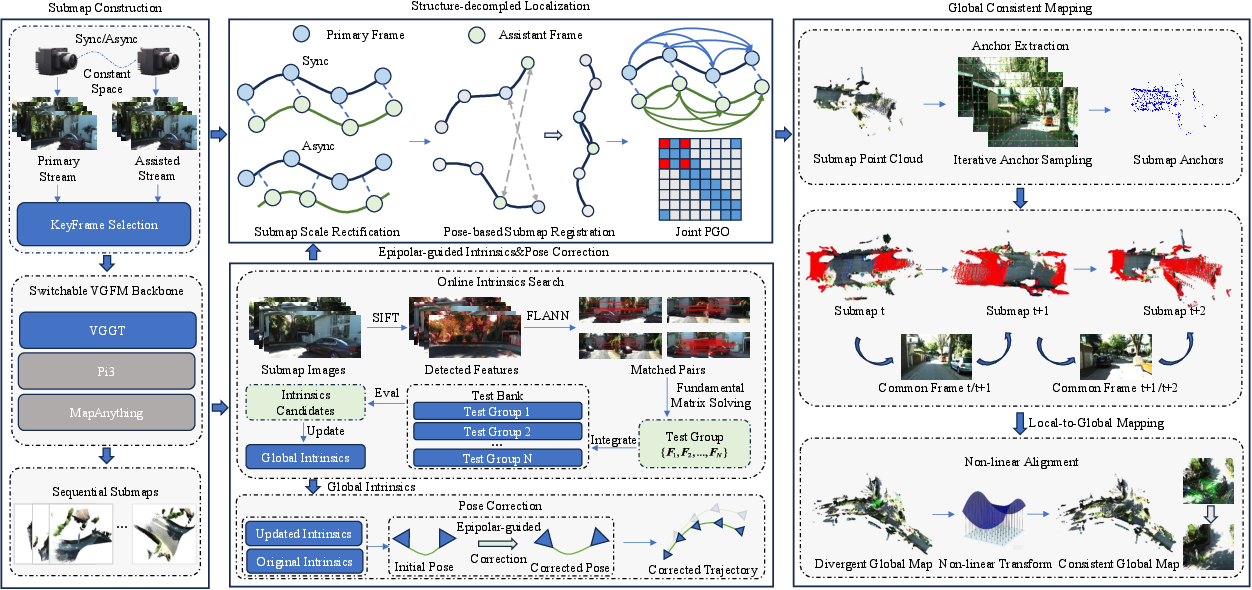
Figure 2: CAL2M system architecture with sub-map generation, intrinsic and pose correction modules, anchor-based global mapping, and nonlinear transformation.
Submap alignment eschews dense point cloud registration (which is prone to non-linear warping) in favor of pose-based alignment.
Anchor-Based Global Consistent Mapping
Dense, locally warped sub-maps are aligned via anchor propagation. Robust feature correspondences across frames are used to extract geometric anchors—control points distributed using a spatial grid strategy and verified across sequence frames. These anchors are propagated bi-directionally across sub-maps using overlapping frames, yielding global anchors with fused coordinates determined by weights reflecting multi-view confidence and spatial distribution.
Active anchors (with high observation counts) are selected via local suppression to preserve topology, preventing anchor tearing and geometric distortion. Final global mapping is achieved via a TPS-based non-linear deformation aligned to anchor control points, separating rigid body transformation from internal sub-map warping.
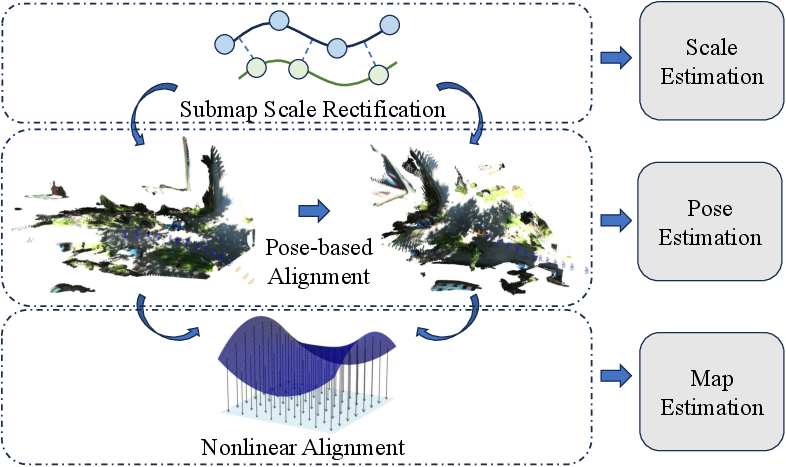
Figure 3: Paradigm comparison; sub-map coupling in standard methods (left) accumulates errors, decoupling and anchor alignment in CAL2M (right) preserves global consistency.
Experimental Evaluation and Numerical Results
CAL2M was assessed on KITTI Odometry, KITTI-360 (open-loop), and Argoverse datasets. On KITTI Odometry, CAL2M produced the lowest ATE among calibration-free methods and was competitive with fully calibrated systems. In open-loop KITTI-360, it significantly outperformed all other calibration-free dense mapping approaches, achieving stable long-term localization. The approach is robust to synchronization errors; asynchronous stream configurations yielded comparable accuracy to synchronous setups.
Dense mapping experiments on Argoverse demonstrated that CAL2M offers the best Chamfer distance, accuracy, and completeness, with qualitative results indicating structurally coherent and drift-free reconstructions.
Intrinsic estimation was more stable using the intrinsic search module than either raw VGFM outputs or naive means. Scale drift, quantified via sliding window analysis, was negligible with CAL20M compared to standard VGFM alignment methods.
Ablation studies showed that assistant-eye-based scale rectification was critical for kilometer-scale accuracy. Pose correction, especially rotation adjustment, substantially improved localization and structural quality, and anchor suppression plus non-linear alignment yielded the best mapping scores.

Figure 4: Qualitative reconstruction on KITTI-360, demonstrating superior global and local alignment with CAL21M.


Figure 5: Dense reconstruction on Argoverse, illustrating CAL22M's structural consistency compared to other VGFM-based methods.
Backbone Generalization and Practical Implications
The plug-and-play design enables CAL23M to operate with VGGT, Pi3, and MapAnything backbones. Across all backbone combinations and datasets, CAL24M outperformed linear alignment baselines in both localization and mapping datasets, demonstrating architecture-agnostic enhancement of deep geometry models.
CAL25M obviates the historical requirement for rigid calibration and synchronization, offering deployment flexibility with minimal compromise in accuracy, thus facilitating real-world SLAM in arbitrary, loosely coupled camera configurations.
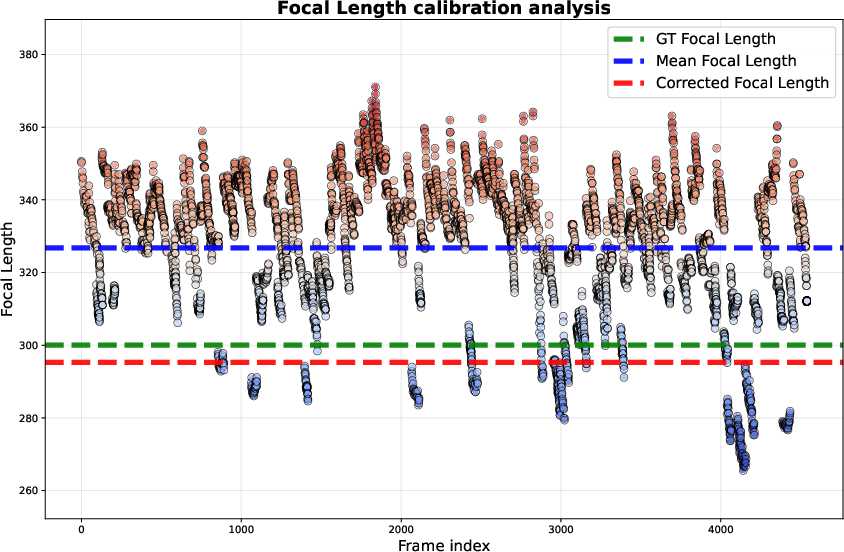
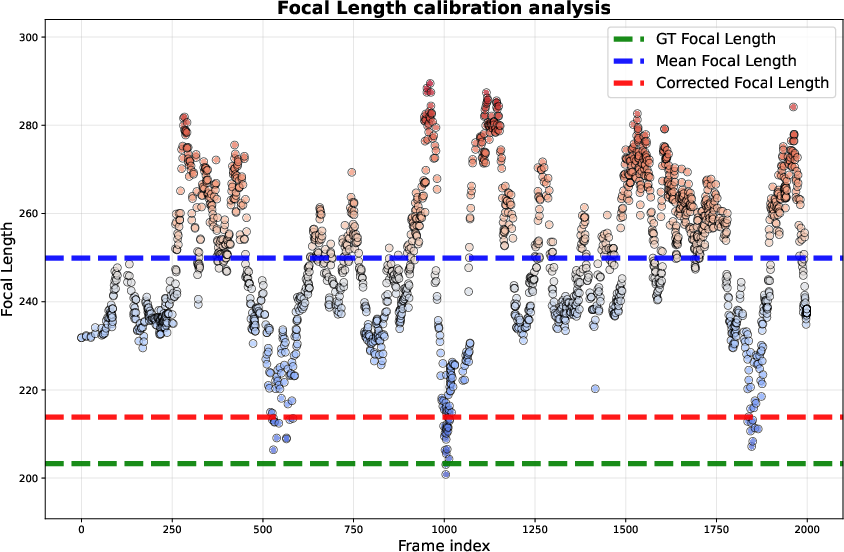
Figure 6: Temporal stability of intrinsic estimation, with CAL26M yielding values closely aligned with ground truth.
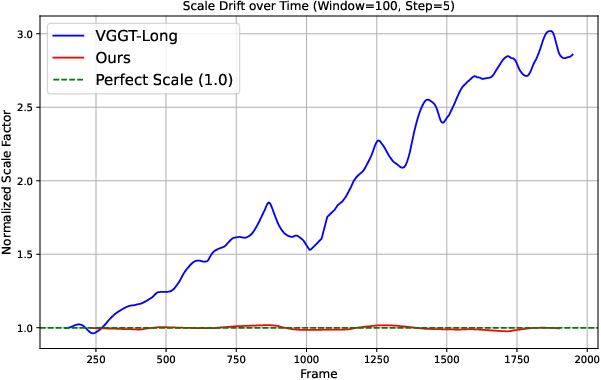
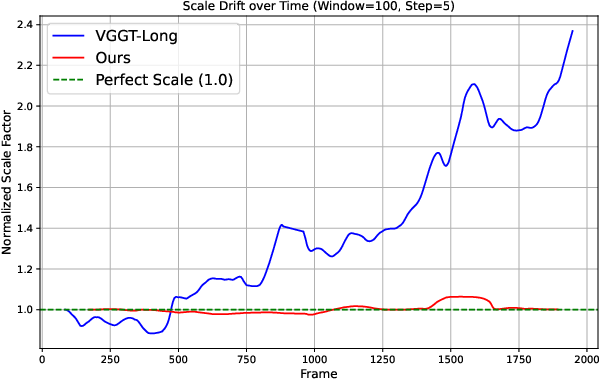
Figure 7: Scale drift analysis on KITTI-360; CAL27M maintains scale constancy while VGGT-Long exhibits substantial drift.
Limitations and Future Directions
The intrinsic search module currently assumes fixed-focus cameras. Future development should accommodate dynamically varying intrinsics (e.g., zoom optics) via temporal modeling of test banks. Although CAL28M narrows the gap with calibrated stereo systems, a residual performance difference remains, which could be mitigated by exploiting advances in VGFM model architectures or by further refining geometric priors.
Conclusion
CAL29M systematically addresses the fundamental challenges in employing VGFMs for kilometer-scale SLAM by eliminating scale ambiguity, correcting affine and intrinsic errors, and achieving globally consistent mapping. The assistant-eye mechanism and anchor-based, non-linear alignment transform calibration-free SLAM into an accurate, robust process. CAL20M advances the practical deployment of foundation models in large-scale autonomous navigation and 3D reconstruction applications.


Figure 8: Ablation studies on mapping strategies, highlighting the effect of anchor suppression and TPS alignment on reconstruction fidelity.