- The paper establishes a precise equivalence between transformer self-attention in the zero-temperature limit and Power Voronoi diagrams, quantifying input space partitioning.
- It derives sharp asymptotic bounds on the number of linear regions as a function of sequence length, head count, and depth, proving exponential gains in multi-head architectures.
- The study introduces a tropical algebraic framework to model self-attention and demonstrates its stability under finite softmax temperatures with implications for architectural tuning.
Introduction and Motivation
The expressivity and theoretical capacity of Transformer architectures have been extensively debated in deep learning theory, yet most prior work addresses functional expressivity (e.g., universality or Turing completeness) without a quantified geometric theory of how transformers partition their input spaces. This paper, "Expressivity of Transformers: A Tropical Geometry Perspective" (2604.14727), develops a rigorous geometric analysis of transformer expressivity by leveraging tropical (max-plus) geometry. Central results include a precise equivalence between self-attention in the zero-temperature limit and Power Voronoi diagrams, detailed combinatorial analysis of the geometric complexity explosion induced by sequence length N, number of heads H, and depth L, and sharp asymptotic and constructive bounds on the number of linear regions implemented by deep transformer networks.
Linear Regions and Piecewise-Linear Partitioning
The study adopts a geometric expressivity measure from the theory of continuous piecewise-linear (CPWL) functions: the count N of maximal linear regions in the input space, generalizing existing results for ReLU-based MLPs [montufar2014number, serra2018bounding, hanin2019complexity]. Each region corresponds to a distinct affine map prescribed by the network, providing a meaningful quantification of nonlinearity and local function complexity.
For MLPs, the combinatorial growth of regions via recursive space folding is classical (Figure 1):
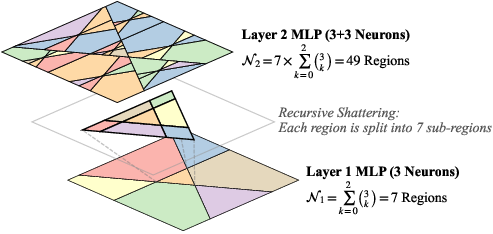
Figure 1: Recursive spatial partitioning in a 2-layer MLP with d=2; Layer 2 recursively shatters the space through affine composition, multiplying the region count.
However, the softmax-based self-attention in transformers is not piecewise-linear, complicating standard hyperplane arrangement analysis. The paper resolves this by mapping attention's log-sum-exp operations to the tropical semiring through Maslov dequantization.
Tropical Algebraic Framework for Self-Attention
In the max-plus semiring (⊕=max, ⊗=+), tropical polynomials naturally model CPWL maps. The authors rigorously demonstrate that, under the τ→0 (zero-temperature) limit, softmax attention reduces to maximizing inner products: every attention module then implements a piecewise-constant map, with hard boundaries determined by the arrangement of key vectors in representation space.
The key insight is to analyze self-attention as a vector-valued tropical rational map, employing log-lifting to avoid metric collapse and allow asymptotic analysis. This leads to the identification of geometric routing boundaries with the normal fan of a Newton polytope corresponding to the set of keys.
Self-Attention and Power Voronoi Diagrams
The principal geometric result is a precise equivalence: in the zero-temperature limit, transformer self-attention partitions projected query space Rdk exactly according to a Power Voronoi diagram, where sites are key vectors and weights are their squared norms. This not only elucidates the boundary geometry—affine, possibly empty or degenerate cells—but also provides a foundation for further combinatorial analysis (Figure 2):
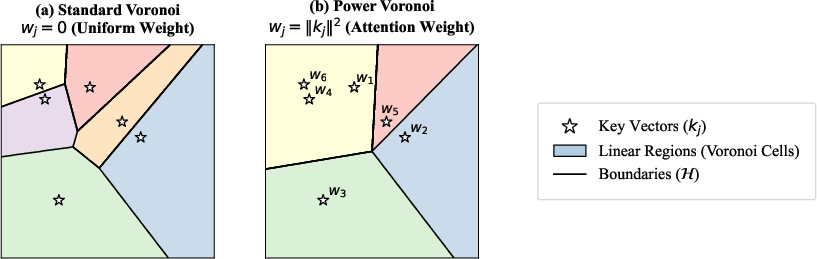
Figure 2: Partitioning of the query space Rdk, showing transformation from standard Voronoi to Power Voronoi under dot-product attention.
The practical import is twofold:
- Piecewise-constant mapping: Within each Voronoi cell, the output of self-attention is a fixed value vector, and transitions only occur at affine boundaries, formalizing the discrete routing nature of attention at low temperature.
- Robustness to key normalization: Under H0-normalized keys, the partition degenerates to a standard Voronoi diagram, i.e., boundaries are only influenced by relative key positions, not their magnitudes.
Combinatorial Complexity: Sequence Length, Heads, and Depth
A major contribution is the derivation of asymptotic and constructive bounds on the number of linear regions as a function of model hyperparameters. The analysis proceeds via careful study of Newton polytopes associated with each attention head and their Minkowski sums during multi-head aggregation.
Single-Head vs Multi-Head Attention
For a single attention head, the corresponding Newton polytope is simply the convex hull of the H1 key vectors, admitting at most H2 vertices. This imposes an expressivity bottleneck.
However, with H3 heads, the output is governed by the Minkowski sum of H4 independent Newton polytopes. When these are in generic position, the combined polytope exhibits a combinatorial explosion in vertices, scaling as H5 (Figure 3):
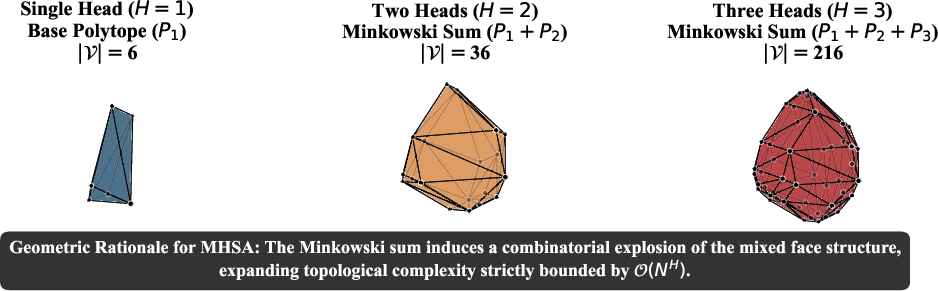
Figure 3: Geometric rationale for Multi-Head Self-Attention via Minkowski sums; aggregation of polytopes enables an exponential increase in the number of regions.
This exponential gain demonstrates the geometric necessity and utility of MHSA for transformer expressivity, in contrast with SHA architectures.
Depth Composition and Tight Scaling Laws
Key bounds are established for deep transformers via recursive composition:
- Upper Bound: With H6 layers, H7-dimensional embeddings, and H8-region capacity per attention block, the maximal region count is
H9
provided L0 and sufficient FFN width.
- Constructive Lower Bound: Explicit weight constructions are shown to realize this bound via surjective, affine grid-like shattering (avoiding degeneracy by leveraging sawtooth ReLU maps and non-overlapping partitions). This establishes L1 as asymptotically tight.
This scaling is empirically confirmed via log-log plots of observed region and vertex counts (Figure 4):
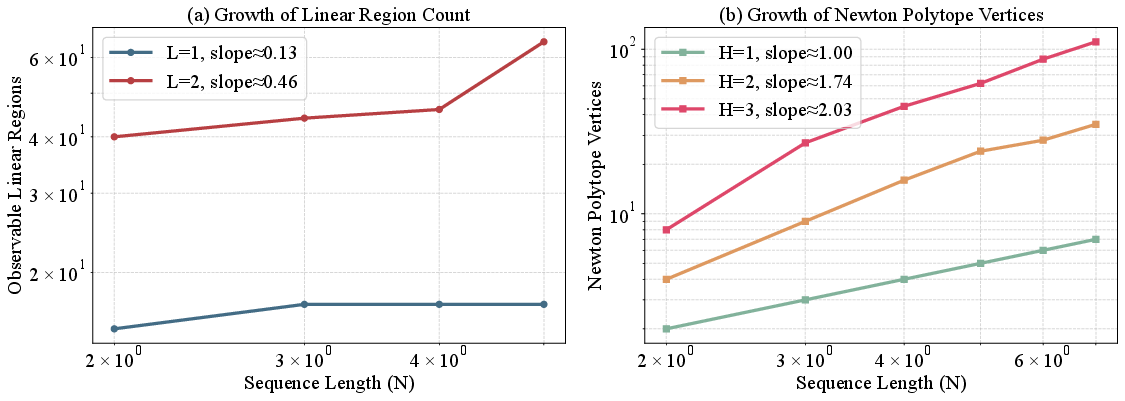
Figure 4: Empirical log–log scaling: (a) linear region counts via Monte Carlo; (b) exact vertex counts for Minkowski sums, rapidly increasing with L2 and L3.
In deep, wide, multi-head transformers, the number of linear regions grows polynomially in L4 with degree L5, sharply contrasting the situation in MLPs where region complexity depends solely on depth and width.

Figure 5: Combinatorial explosion of maximal linear regions as a function of transformer depth L6; profound geometric shattering of the query space due to deep composition.
Stability of Polyhedral Structure at Finite Temperature
Although the main framework relies on the L7 limit, the study proves exponential tightness of this polyhedral partitioning for any positive L8 (finite softmax temperature). Via explicit Hessian and gradient bounds, the interiors of Voronoi-like regions are shown to retain affine behavior up to L9 corrections, and the nonlinearity is confined to narrow bands at boundaries (Figure 6):
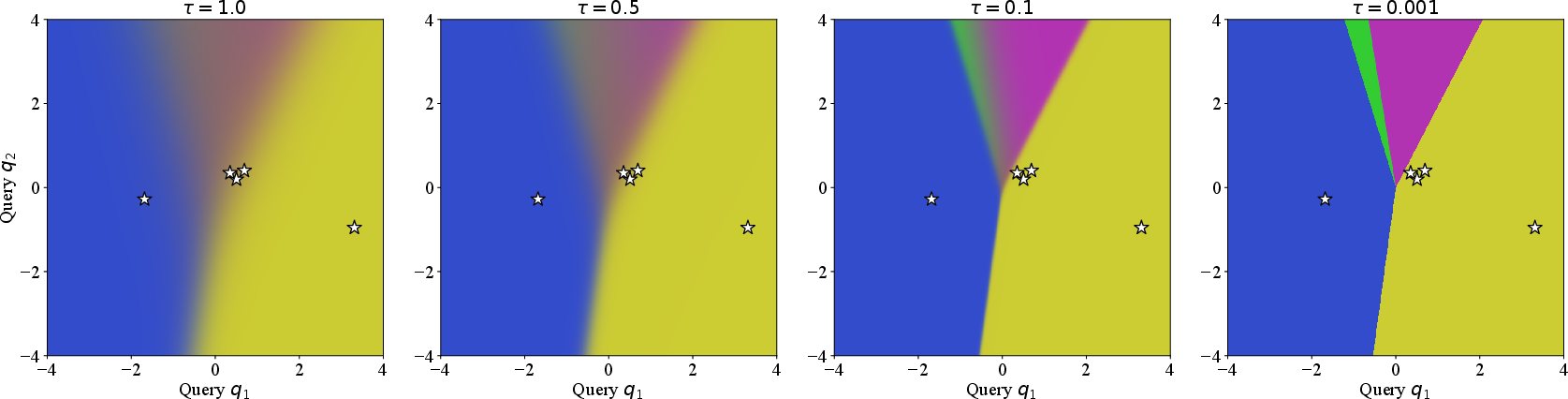
Figure 6: Convergence of attention routing to Power Voronoi partition under decreasing softmax temperature; boundaries sharpen and regions stabilize as N0.
Thus, the geometric complexity results pertain to actual, trainable transformers at typical temperature scalings (e.g., N1).
Implications and Future Directions
The explicit characterization of transformer region complexity has practical implications for both architectural design and theoretical understanding:
- Architectural tuning: Increasing sequence length N2, head count N3, or embedding dimension N4 all directly amplify geometric complexity, with MHSA delivering exponential gain for a fixed parameter budget.
- Theoretical insight: The correspondence between network depth and polynomial growth in region count justifies and quantifies the practical effectiveness of stacking many layers. It also identifies sufficient magnitude and alignment constraints to avoid geometrical collapse in composition.
- Limitations and Open Problems: The analysis omits normalization schemes (e.g., LayerNorm) and optimization dynamics. Future work could extend tropical analysis to stochastic optimization trajectories or study post-training geometry in empirical models. Additionally, tropical descriptions of other architectures (e.g., MoE, graph transformers) provide a broad avenue for further research.
Conclusion
This paper presents a comprehensive geometric framework for transformer expressivity based on tropical geometry, establishing a concrete correspondence between self-attention and Power Voronoi diagrams, and rigorously deriving scaling laws for linear region complexity in terms of N5, N6, N7, and N8. The main claims are both theoretically tight and empirically validated for deep, multi-head architectures. These results constitute a new baseline for the study of compositional nonlinearity in neural attention models and will inform both principled architecture design and foundational theory moving forward.