- The paper introduces a novel meta-reviewing framework that models the process as an interactive, decision-centric dialogue, leveraging fine-tuned agents.
- ReMuSE, the proposed multi-reward self-editing method, significantly improves dialogue metrics, with K-Precision up by 105% and Q2-F1 by 88%.
- Empirical evaluations confirm the approach enhances meta-review efficiency and preserves human judgment, reducing review time by nearly 50%.
Traditional approaches to meta-reviewing in peer review processes predominantly treat the meta-review as a multi-document summarization task, abstracting reviewer reports into a condensed evaluation. However, this perspective neglects the inherently deliberative and decision-driven nature of meta-reviewing, which requires dynamic weighing of reviewer arguments and contextualizing opinions within the broader research field. This work reconceptualizes meta-reviewing as a document-grounded, decision-making dialogue, proposing and empirically validating interactive dialogue agents to support meta-reviewers through iterative, evidence-driven conversation. The central thesis is that dialogue agents, if appropriately grounded and fine-tuned, can enhance both the efficiency and quality of meta-reviewing, while preserving reviewer autonomy.

Figure 1: Meta-reviewing as a dialogue: the agent assists in summarizing, weighting, and contextualizing reviewer opinions via interactive conversation.
Reward-Based Multi-Aspect Self Editing (ReMuSE): Synthetic Data for Dialogue Agent Training
The core technical innovation is the Reward-based Multi-aspect Self Editing (ReMuSE) method for synthetic dialogue generation. Fine-tuning dialogue agents tailored to meta-reviewing is hampered by a dearth of high-quality annotated dialogues. ReMuSE operationalizes self-refinement: after zero-shot LLM generation of dialogues (conditioned on the paper and reviews), outputs are iteratively refined based on multiple explicit reward signals measuring groundedness (K-Precision, Q2-score) and specificity.
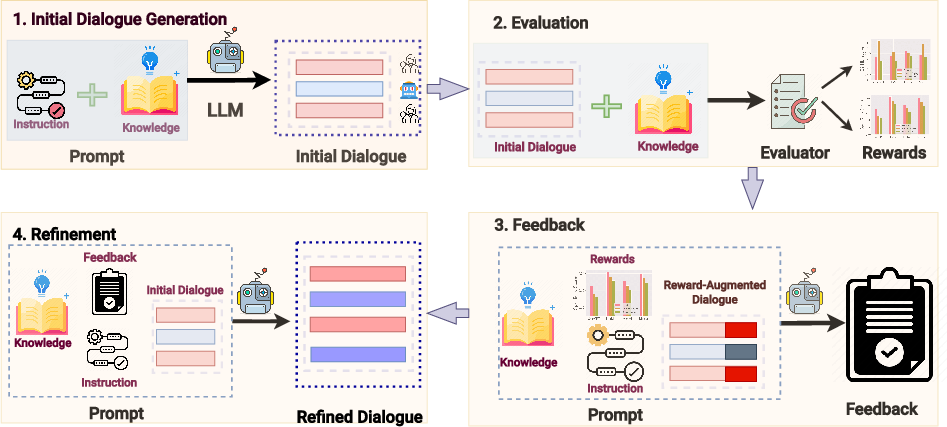
Figure 2: Pipeline for ReMuSE: Initial dialogue generation, automatic evaluation with multiple reward signals, natural language feedback generation, and iterative refinement for improved technical quality and grounding.
Empirical results show that dialogues produced by ReMuSE—particularly when using Mixtral—achieve marked improvements in all reward dimensions (e.g., K-Precision improved by 105%, Q2-F1 by 88%, specificity by 72%) compared to zero-shot and single-aspect self-refinement baselines. Mixtral with ReMuSE yielded the strongest numerical performance (K-Precision: 0.78, Q2-F1: 0.32, specificity: 0.72), outperforming human benchmarks on faithfulness, though with slightly lower token diversity.
Both human and automated evaluations confirm the superiority of ReMuSE-generated dialogues. Human expert raters judged ReMuSE outputs as the most co-operative, coherent, plausible, and engaging. Quantitative analysis revealed strong correlations between automated groundedness/objectivity scores and perceived helpfulness, underscoring the reliability of these reward-metrics as optimization targets.
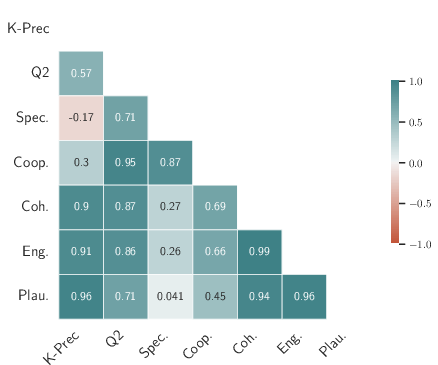
Figure 3: Comparison of human and automated evaluation metrics shows strong alignment, validating reward-based automatic metrics for dialogue quality.
Cross-comparisons against real expert-human meta-reviewing dialogues (using the Dagstuhl dataset) further showed ReMuSE-generated agents rank at parity or higher in co-operativeness, coherence, and plausibility, with human dialogues remaining more engaging due to broader topic wandering and higher lexical diversity.
Ablation studies substantiate that multi-reward, actionable-feedback refinement yields substantive improvements over single-aspect or purely generic feedback. Further, performance gains exhibit rapid saturation with data scale, indicating efficiency of the approach.
Dialogue Agent Fine-Tuning and Deployment
LLMs fine-tuned with ReMuSE data (e.g., Flan-T5, Mixtral) outperform closed, zero-shot LLMs like ChatGPT in both faithfulness and decision-making utility. Fine-tuned agents provide more relevant, factual, and objective responses, crucial for deliberative support in expert settings.
In a controlled within-subject study, meta-reviewers using the deployed agent generated meta-reviews with higher content relevance and coverage, achieving comparable decision correctness to traditional processes but reducing total review time by nearly 50%. These findings were consistent for both expert and non-expert participants, with the latter group showing even larger efficiency gains.
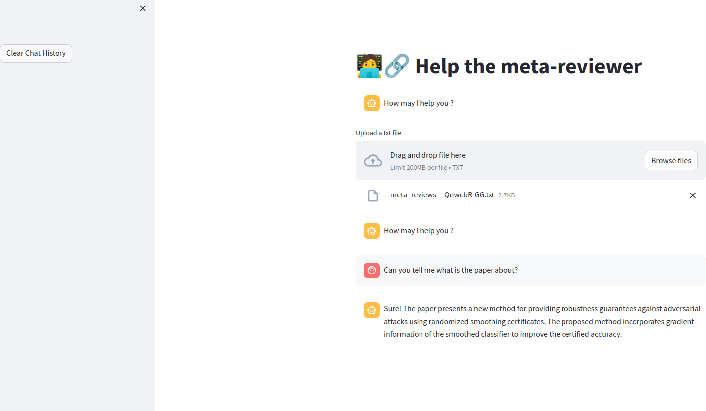
Figure 4: Interface snapshot for meta-reviewer and dialogue agent interaction during the user study.
Modeling the Decision-Making Process: Structured Multi-Phase Dialogues
ReMuSE-generated dialogues convincingly model the real-world deliberative structure of meta-reviewing. Annotation and analysis reveal high coverage of evidence gathering, conflict resolution, and consensus phases, with a significant proportion of dialogues containing all three phases in the correct order—reflecting realistic, expert-like reasoning.
Cross-Domain Generalization
The ReMuSE paradigm exhibits robust generalization, delivering parallel improvements across other decision-making scenarios such as product purchase and debate resolution, albeit with different distributional emphases (evidence gathering vs. conflict resolution). This demonstrates the effectiveness of reward-guided generation beyond the meta-reviewing domain.
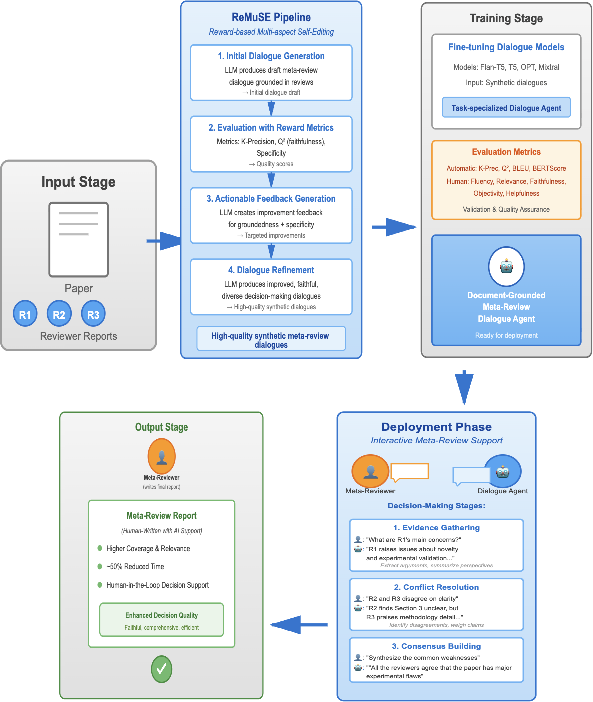
Figure 5: End-to-end workflow, from synthetic dialogue generation to agent fine-tuning and real-world deployment.
Implications and Prospective Directions
The formalization of meta-reviewing as a decision-oriented, document-grounded dialogue fundamentally reshapes how AI can assist domain experts in complex, high-stakes judgment tasks. Practically, this framework highlights that LLM-based dialogue agents—when fine-tuned for groundedness and specificity using reward-centric self-refinement—can:
- Substantially reduce cognitive and temporal burden for expert decision-makers.
- Provide faithful, transparent support without supplanting human agency, aligning with field policies resisting AI "ghostwriting."
- Generalize to other deliberative domains requiring nuanced, multi-evidence reasoning.
Theoretically, these results suggest that multi-aspect, reward-driven generation strategies can induce structurally realistic, domain-aligned dialogue behaviors in LLMs, even with modest synthetic datasets.
Conclusion
This work establishes a novel methodological and practical foundation for AI-assisted meta-reviewing by shifting from static summarization to interactive, evidence-grounded dialogue. ReMuSE—a multi-reward, iterative refinement system—enables efficient synthetic data generation for fine-tuning high-quality, technically competent dialogue agents. These agents demonstrably enhance the efficiency and deliberative rigor of expert decision-making in peer review, with strong implications for wider adoption in other knowledge-intensive, collaborative tasks. Future directions include extending to cross-lingual and interdisciplinary settings, modeling more diverse domain biases, and enhancing interpretability and traceability of agent suggestions to further ensure responsible human-AI collaboration.
Reference:
"Decision-Making with Deliberation: Meta-reviewing as a Document-grounded Dialogue" (2508.05283)