- The paper introduces Group Fine-Tuning, unifying imitation and reward-based fine-tuning to overcome SFT limitations.
- It employs Group Advantage Learning and Dynamic Coefficient Rectification to stabilize updates and boost model performance.
- Experiments reveal that GFT achieves robust results on math reasoning tasks with only one-tenth of the SFT training data.
Group Fine-Tuning (GFT): A Unified Approach to Post-Training LLMs
Motivation and Training Dynamics Diagnosis
The paper critically examines supervised fine-tuning (SFT) and reinforcement learning (RL) as principal post-training methods for LLMs. SFT's efficiency in knowledge injection contrasts with its susceptibility to catastrophic forgetting and entropy collapse, which are manifested as regression in generalization and degraded out-of-distribution performance. This is empirically shown by cases where SFT not only fails to improve but actively degrades model performance relative to pre-trained baselines (Figure 1).
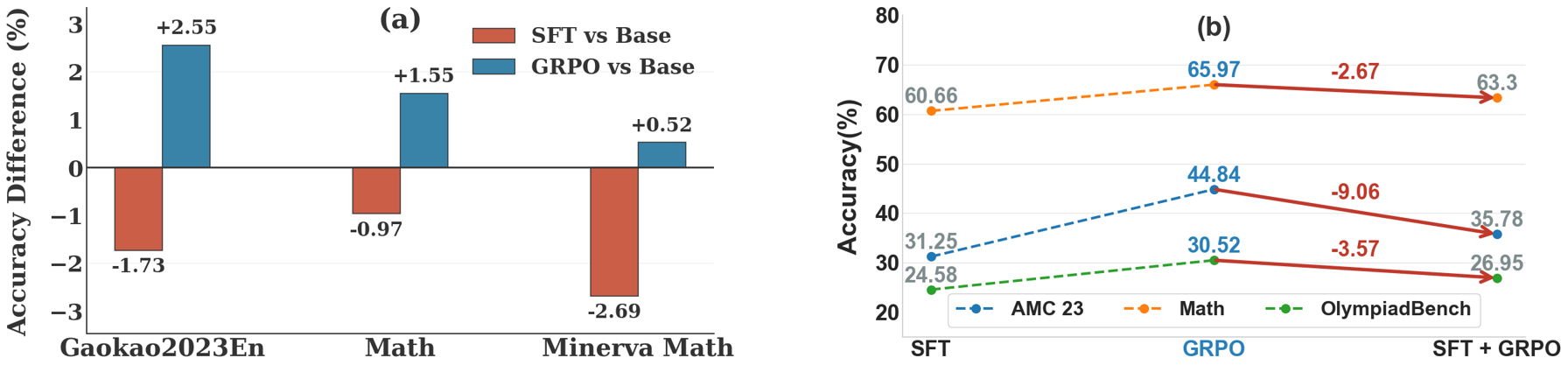
Figure 1: SFT training often induces catastrophic forgetting, causing accuracy regressions relative to the base model, and exhibits poor synergy in sequential SFT+GRPO pipelines.
Through a formal analysis, the authors recast SFT as an RL paradigm with a highly sparse reward and unstable importance weighting. The reward signal r(x,y)=I[y=y∗] strictly limits learning to expert trajectories, enforcing single-path dependency, while the inverse probability weight 1/πθ(y∣x) is prone to gradient explosion. These dynamics foster mechanical memorization and undermine generalization.
Methodology: Group Fine-Tuning Framework
GFT introduces two synergistic mechanisms:
1. Group Advantage Learning (GAL): This mechanism forms hybrid response groups per input, comprising expert demonstrations, teacher distillations, and model-generated rollouts. Each candidate response is evaluated with standardized, group-level advantage scores, producing a normalized, contrastive learning signal that encourages exploration and mitigates path dependency.
2. Dynamic Coefficient Rectification (DCR): DCR addresses gradient instability by bounding the inverse-probability weight via adaptive, per-token gradient clipping. Extreme update coefficients arising from low-probability tokens are suppressed, while informative gradients for moderately novel tokens are preserved, stabilizing optimization and enabling efficient knowledge transfer.
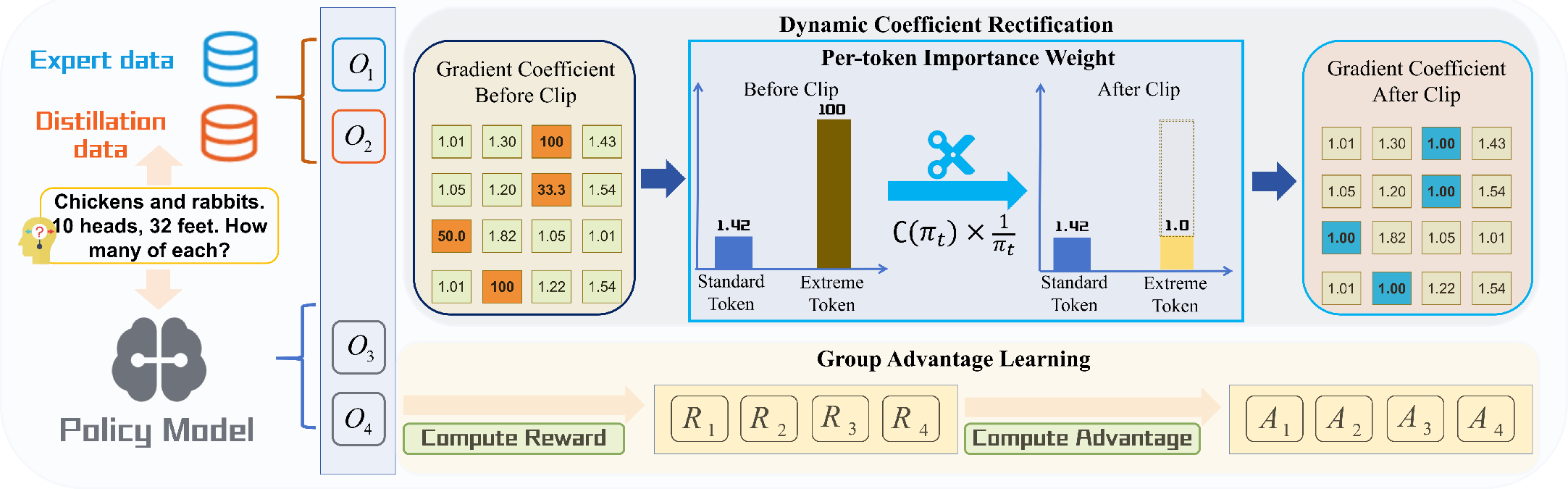
Figure 2: GFT combines group advantage computation from diverse response types (expert, teacher, rollout) and dynamic coefficient rectification for bounded updates.
Learning Dynamics: Component Impact
Ablation experiments highlight component contributions. Removing GAL leads to slower convergence and lower maxima, especially on high-difficulty tasks. Excluding DCR exacerbates training volatility and instability. The synergy of both mechanisms is necessary for uniformly optimal results, as evidenced by model training curves.
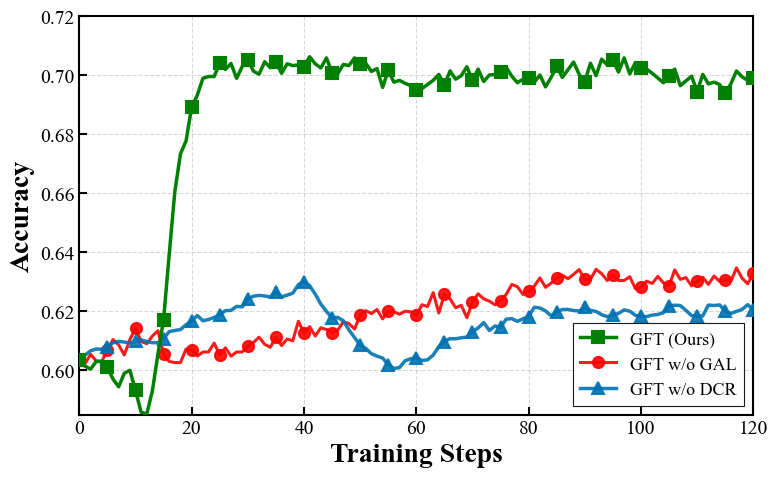
Figure 3: Exclusion of DCR causes volatile learning, whereas absence of GAL results in slow, suboptimal convergence.
Experimental Results
GFT demonstrates superior performance and data efficiency across a spectrum of math reasoning benchmarks and model architectures, consistently outperforming SFT, advanced SFT variants (DFT, ASFT, PSFT), and RL baselines (GRPO). With only 10k examples—one-tenth of the data used by SFT—GFT achieves comparable or better accuracy, highlighting its efficiency.
Mixing distillation data yields marginal gains, indicating that the principal improvements stem from GFT's training dynamics rather than dataset augmentation. The improvements are stable across all evaluated model scales.
Compatibility and Post-Training Synergy
Conventional SFT followed by RL (e.g., GRPO) results in suboptimal synergy, owing to SFT-induced policy rigidity and entropy loss. GFT, when combined with GRPO, provides a stronger initialization and yields higher final ceilings via stable optimization. Sequential SFT+GFT+GRPO pipelines maximize both alignment and exploration, producing the most robust performance.
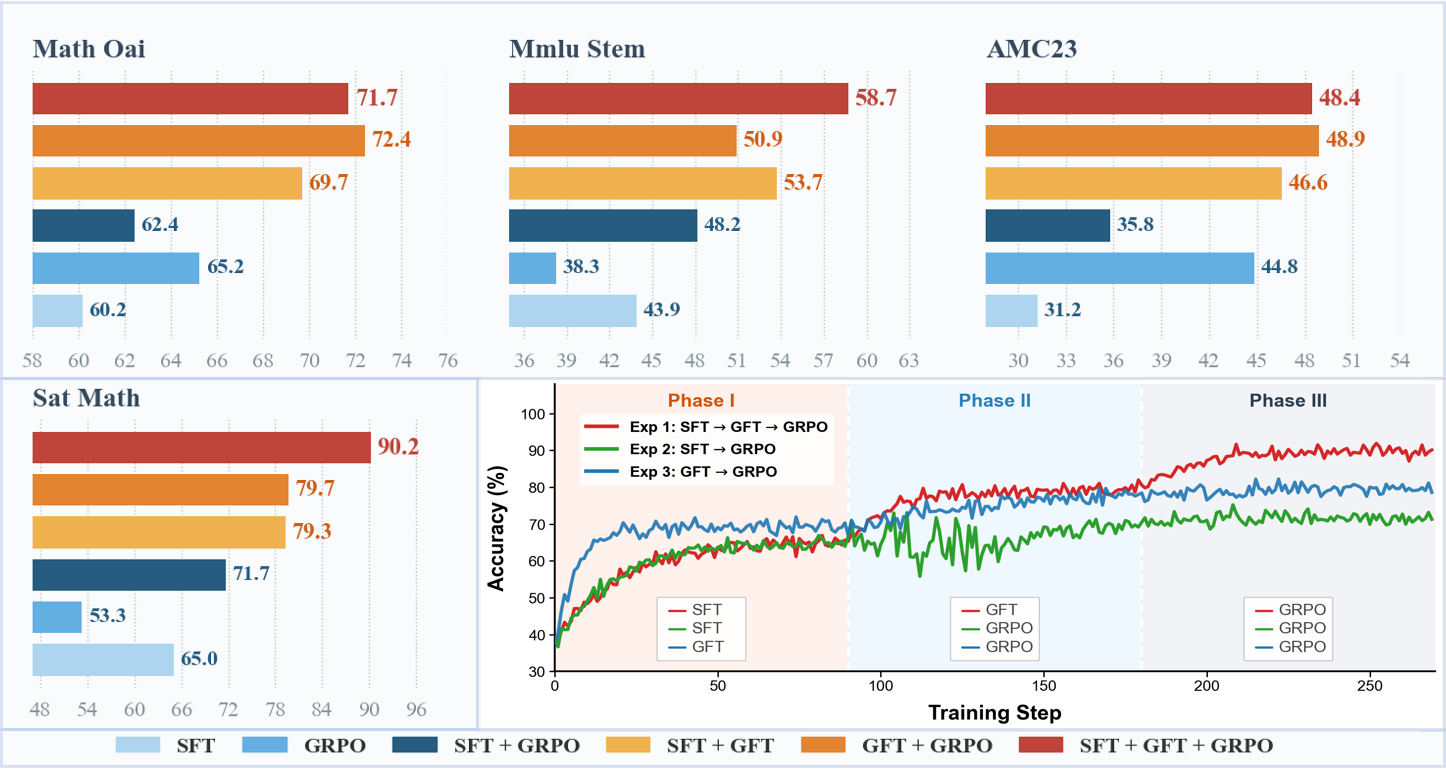
Figure 4: GFT exhibits high compatibility and synergy between SFT and GRPO, attaining top performance and stable training dynamics.
Catastrophic Forgetting Mitigation
GFT substantially mitigates catastrophic forgetting observed in SFT, preserving base model capabilities across general reasoning benchmarks. KL divergence analyses confirm that GFT induces minimal policy drift relative to the base model, with divergence levels comparable to GRPO and substantially lower than SFT.
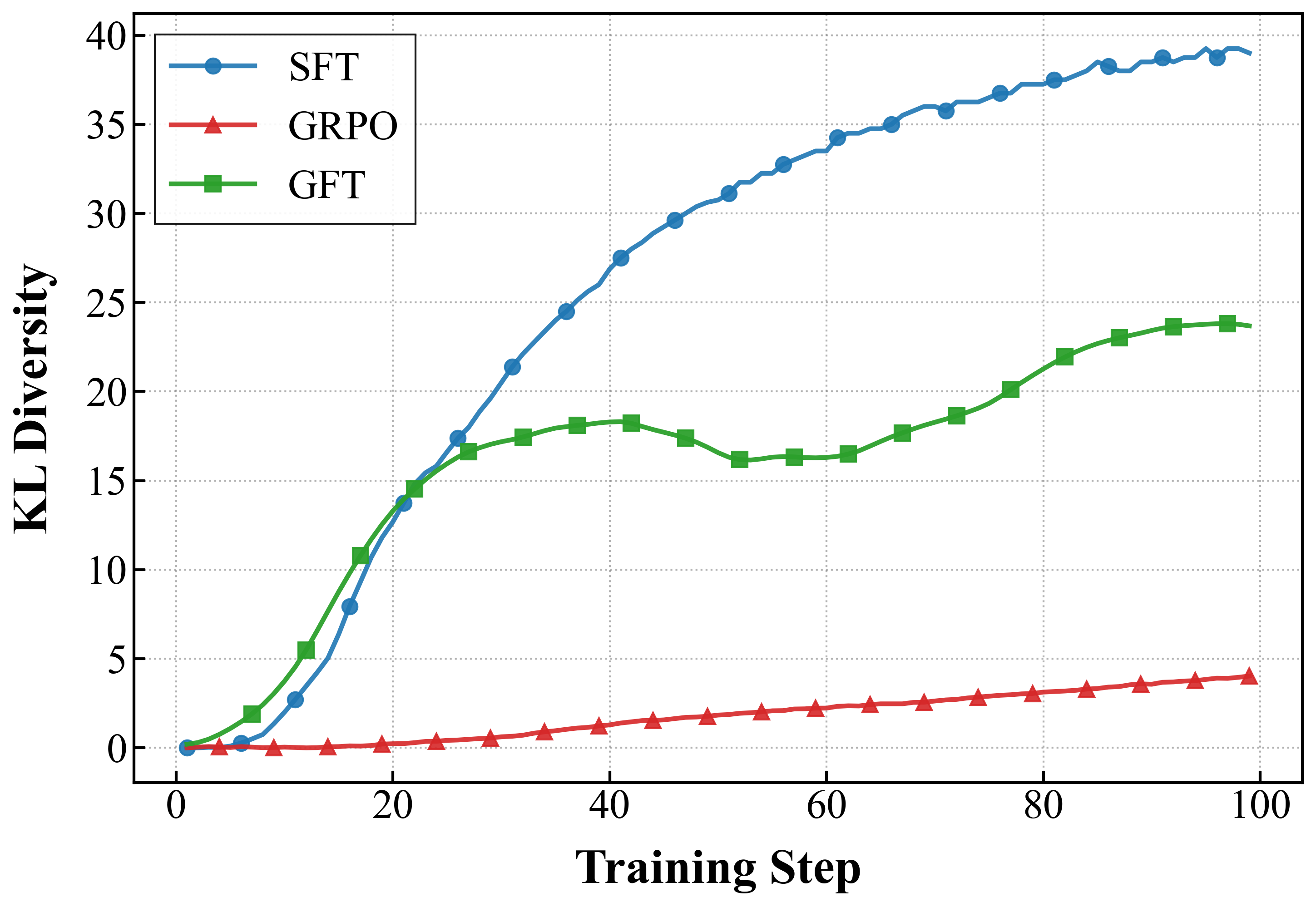
Figure 5: GFT maintains low KL divergence, effectively limiting catastrophic forgetting and preserving general purpose reasoning.
Diversity and Solution Coverage
Evaluations using Pass@k metrics show that GFT achieves superior solution diversity compared to pure distillation and RL. This is attributed to GFT's explicit contrastive advantage signal, which encourages exploration without sacrificing precision.
Hyperparameter Analysis
Optimal group composition is achieved with minimal demonstrations and abundant model samples (2:6 ratio), maximizing informative contrast for advantage computation. DCR threshold selection follows an inverted U-shaped accuracy curve: insufficient clipping risks instability, while excessive clipping hampers learning efficiency.
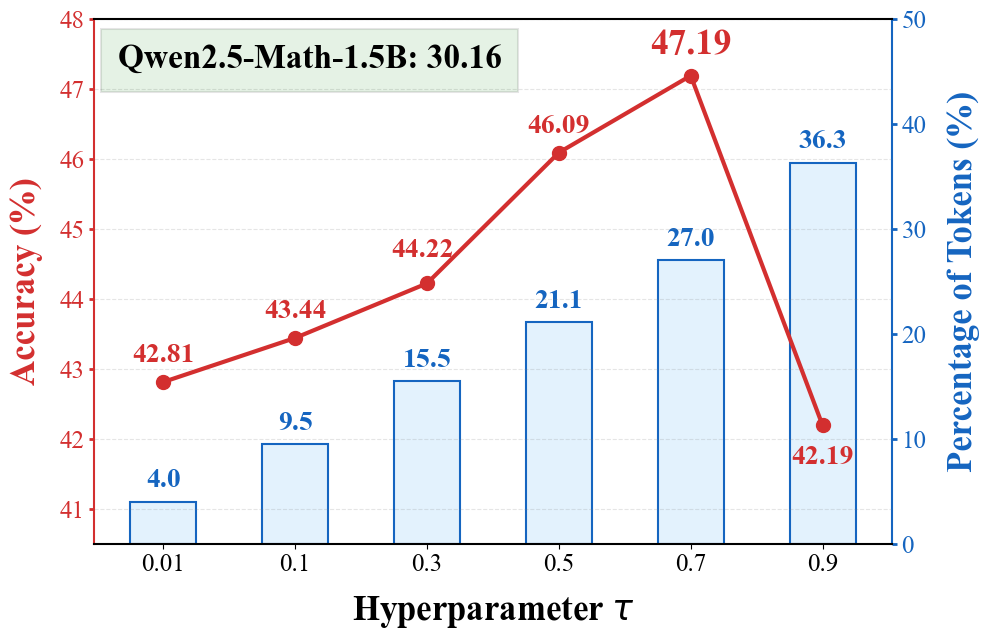
Figure 6: Tuning the clipping threshold τ affects the fraction of rectified tokens and accuracy; τ≈0.7 optimizes stability and learning.
Theoretical and Practical Implications
GFT formally unifies supervised and RL-driven post-training as a policy-gradient-based paradigm with stabilized, group-normalized updates. Theoretical implications include improved understanding of SFT's limitations in terms of reward sparsity and sample dependence. Practically, GFT extends LLM post-training capabilities by balancing knowledge injection, stability, generalization, and exploration. It offers a robust foundation for hybrid pipelines and exposes new trade-offs between plasticity and stability.
Future Directions
Further research is required to adapt GFT for open-ended tasks and subjective rewards, optimize response group construction, and validate scalability for models with 70B+ parameters. Extensions to broader domains beyond mathematical reasoning and integration with new preference modeling techniques are anticipated.
Conclusion
Group Fine-Tuning (GFT) presents a unified post-training framework for LLMs that overcomes SFT's intrinsic limitations through group-level advantage signals and dynamic update stabilization. Experimental and theoretical analyses establish GFT as an effective, principled paradigm for post-training, offering substantial gains in data efficiency, generalization, and synergy between imitation and reward-based fine-tuning (2604.14258).