- The paper introduces a simulation framework that models information access agents in dynamic, competitive marketplaces to mirror real-world interactions.
- It demonstrates that static evaluation metrics miss critical interaction effects, as adaptive user behavior and path dependencies can invert agent rankings.
- The study provides actionable metrics like market share, customer retention, and concentration indices to enhance system evaluation and fairness.
Introduction
"Evaluation of Agents under Simulated AI Marketplace Dynamics" (2604.14256) reframes the evaluation of information access (IA) agents, emphasizing simulation-based paradigms that incorporate real-world factors such as competition, adaptation, and operational constraints within AI marketplaces. The work formalizes a framework grounded in agent-based simulation, capturing feedback-driven dynamics among users, generators, retrievers, and routers. The authors critically analyze the limitations of static evaluation approaches and propose comprehensive marketplace-level metrics, expanding the toolkit for assessing system efficacy in contemporary deployment settings.
Limitations of Static Evaluation
Prevailing evaluation protocols (Cranfield paradigm, pairwise A/B testing) treat IA agents as isolated entities, thereby ignoring critical interaction effects that emerge in marketplace scenarios. These settings overlook user behavioral adaptation, routing fluctuations, and the cascade effects of agent competition. Benchmark-centric rankings fail to predict actual deployment success, as they do not encode compositional effects, winner-take-all dynamics, network effects, or portfolio optimization exhibited in real-world AI ecosystems.
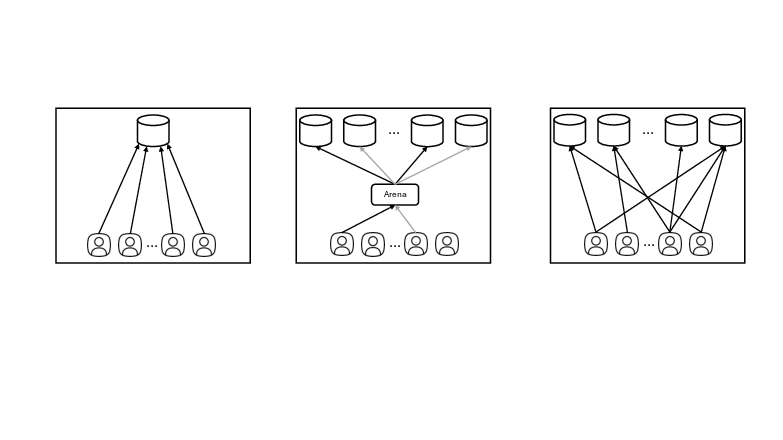
Figure 1: Comparison of Cranfield, Arena, and Marketplace paradigms; only the Marketplace paradigm models user choice, system competition, and evolving market share.
Marketplace Evaluation Framework
The proposed framework models the IA ecosystem as a directed acyclic governance graph, comprising diverse stakeholders (users, generators, retrievers, routers), each characterized by its selection, adaptation, and utility update mechanisms. Interactions unfold as sampled trajectories among agents, evaluated to yield utility signals, which in turn update agent state and preferences, inducing a stochastic dynamical system.
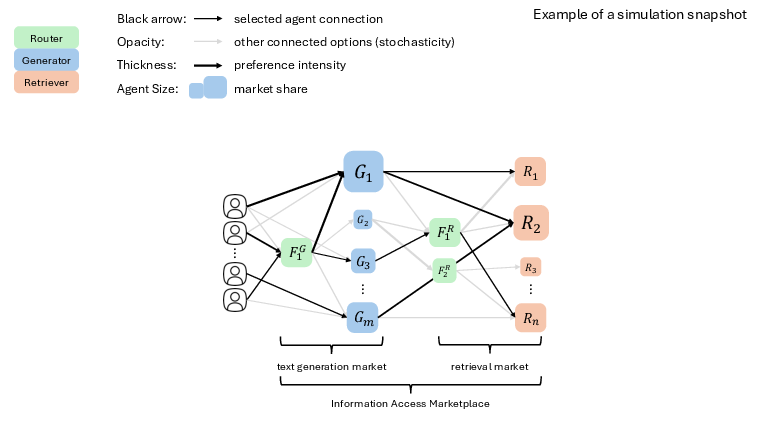
Figure 2: An example RAG marketplace simulation snapshot, where node size encodes market share and arrow thickness reflects selection strength among users, generators, and retrievers.
Agent-based simulation is essential, given the combinatorial complexity of stakeholder action spaces, feedback, and path dependence. This approach enables fine-grained examination of longitudinal adaptation, emergent market dominance, and robustness of agent strategies under various competition models.
Empirical Illustration: Emergent Marketplace Dynamics
A core experiment contrasts static evaluation with marketplace simulation. Seven LLMs (DeepSeek V3.2, Kimi K2.5, Gemini 2.5, GPT-OSS, Grok 4.1, Qwen3, Llama 3.3) are evaluated on a 500-question QA benchmark. Static scoring produces a standard ranking.
In marketplace simulation, 10 adaptive users iteratively select among agents, updating their preferences based on per-response correctness. Notably, agent rankings diverge from the static setting, revealing that competitive dynamics can invert positionings solely due to adaptive traffic allocation. When a high-performing model (Qwen3) enters a low-concentration market, it rapidly accumulates share, compressing rivals' shares and signaling strong dominance; however, when a moderate agent (DeepSeek V3.2) enters a concentrated market, even strong static performance fails to secure commensurate share due to delayed entry and path-dependent loyalty.
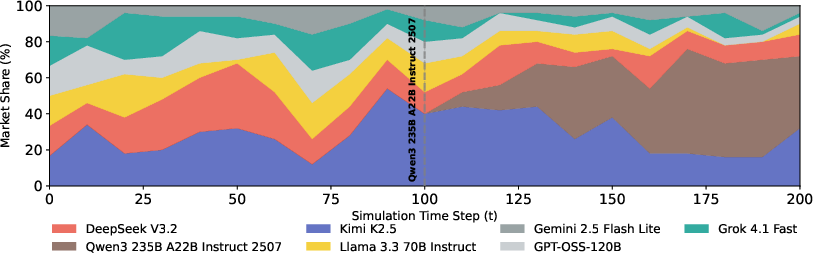
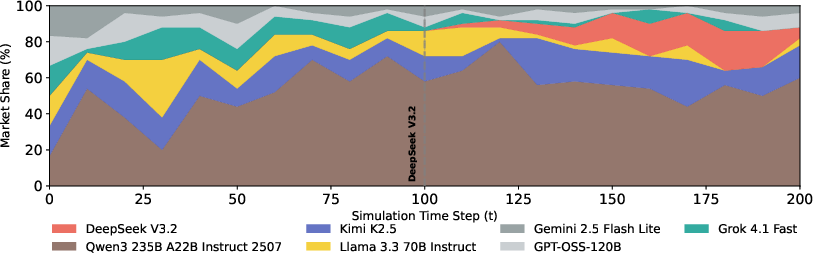
Figure 3: Market share evolution as Qwen3 is introduced into a lightly concentrated market at t=100, showcasing the shock-like redistribution of traffic and shift in dominance.
These results demonstrate that static metrics like correctness are not reliable proxies for post-deployment market outcomes under competition, underscoring the necessity for dynamic, longitudinal evaluation paradigms.
Marketplace Stakeholder Models
Stakeholders are formalized according to their roles and adaptation strategies:
- Users: Model demand-side adaptation by updating selection probabilities based on historical utility (quality, latency, cost, trust). User models must encode heterogeneity in utility sensitivity and topic dependence.
- Generators: Compete to maximize user demand under operational constraints, updating internal protocols, retrieval strategies, and model configurations.
- Retrievers: Compete for selection by generators, adapting via specialization, efficiency, or robustness.
- Routers: Allocate queries among suppliers, mediating exposure, diversity, and regret, potentially adjusting policies in response to observed agent performance.
Marketplace simulations support both single-market analyses (e.g., user-to-generator interaction) and multi-market setups (full RAG pipelines with compositional coupling of generators, retrievers, and routers).
Marketplace Metrics
The paradigm introduces agent-level and marketplace-level metrics that explicitly measure competitive efficacy, retention, and concentration:
- Market Share (MS): Fraction of query traffic allocated to each agent in a sliding time window, revealing both cumulative and transient dominance.
- Customer Retention (CR): Probability that a user, after initial adoption, continues selecting the same agent within a window, separating widespread adoption from loyalty.
- Herfindahl–Hirschman Index (HHI): Captures market concentration; higher HHI implies lower competitiveness and higher risk of monopoly.
- Dominance Gap (Δ): Difference between realized and expected (fair or merit-based) shares for the top agent.
- Expected Exposure Difference (EE, EE-D): Measures allocation fairness and exposure disparity, extensible to multi-level compositional analyses.
These metrics enable nuanced diagnosis of system robustness, gaming susceptibility, market health, and fairness—dimensions not captured by scalar correctness or NDCG.
Integration with Evaluation Campaigns
The framework paves the way for reimagining traditional evaluation campaigns, proposing axes along which marketplace-based protocols can be instantiated:
- Peer vs. Benchmark Competition: Direct inter-system competition vs. evaluation against fixed baselines.
- Run Submission vs. Agent Submission: Static output evaluation vs. live, adaptive agents within shared simulations.
Task design can incorporate multi-agent, retrieval-augmented, or interactive scenarios, extending the paradigm to TREC-like campaigns emphasizing robustness, adaptivity, and compositional workflow.
Validation of Simulation-Based Evaluation
Market simulation outcomes demand validation through:
- Query Distribution Verification: Ensuring simulated queries reflect real demand via distributional alignment or expert review.
- Stakeholder Model Calibration: Testing metric sensitivity to controlled agent properties or deliberate perturbations (e.g., increased latency).
- Meta-Evaluation of Metrics: Analyzing power, discrimination, and gaming resistance via bootstrap tests, rank correlations with real-world leaderboards, and adversarial stress-testing.
These steps ensure construct and convergent validity, positioning simulation-based evaluation as both reliable and actionable.
Implications and Research Agenda
The marketplace evaluation perspective reveals several theoretical and practical research avenues:
- Agent Competition and Economic Modeling: Application of classic economic concepts (dominance, entry, equilibrium) to digital agent markets.
- Behavioral User Modeling: Incorporation of framing, constructed preferences, and network effects into user state spaces.
- Adversarial Robustness: Analysis of reward hacking and metric exploitation under dynamic competition.
- Multi-Market Extensions and Compositional Diagnostics: Decomposition of attribution and strategic interaction across workflow components.
- Agent Optimization in Adversarial Environments: Development of online, cost-sensitive, and regret-minimizing agent selection algorithms under competitive pressure.
The release of the marketplace-eval Python package offers a foundation for systematic study, enabling reproducibility and extensibility.
Conclusion
"Evaluation of Agents under Simulated AI Marketplace Dynamics" advocates for a paradigm shift: from static, isolated evaluation to ecosystem-level, simulation-driven assessment that captures the true competitive landscape encountered by deployed IA agents. The proposed framework, metrics, and research agenda provide a robust foundation for both academic study and practical deployment optimization, aligning evaluations with the realities of modern AI marketplaces and informing the design of resilient, adaptive, and fair information ecosystems.