Magentic Marketplace: An Open-Source Environment for Studying Agentic Markets
Abstract: As LLM agents advance, they are increasingly mediating economic decisions, ranging from product discovery to transactions, on behalf of users. Such applications promise benefits but also raise many questions about agent accountability and value for users. Addressing these questions requires understanding how agents behave in realistic market conditions. However, previous research has largely evaluated agents in constrained settings, such as single-task marketplaces (e.g., negotiation) or structured two-agent interactions. Real-world markets are fundamentally different: they require agents to handle diverse economic activities and coordinate within large, dynamic ecosystems where multiple agents with opaque behaviors may engage in open-ended dialogues. To bridge this gap, we investigate two-sided agentic marketplaces where Assistant agents represent consumers and Service agents represent competing businesses. To study these interactions safely, we develop Magentic-Marketplace -- a simulated environment where Assistants and Services can operate. This environment enables us to study key market dynamics: the utility agents achieve, behavioral biases, vulnerability to manipulation, and how search mechanisms shape market outcomes. Our experiments show that frontier models can approach optimal welfare -- but only under ideal search conditions. Performance degrades sharply with scale, and all models exhibit severe first-proposal bias, creating 10-30x advantages for response speed over quality. These findings reveal how behaviors emerge across market conditions, informing the design of fair and efficient agentic marketplaces.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
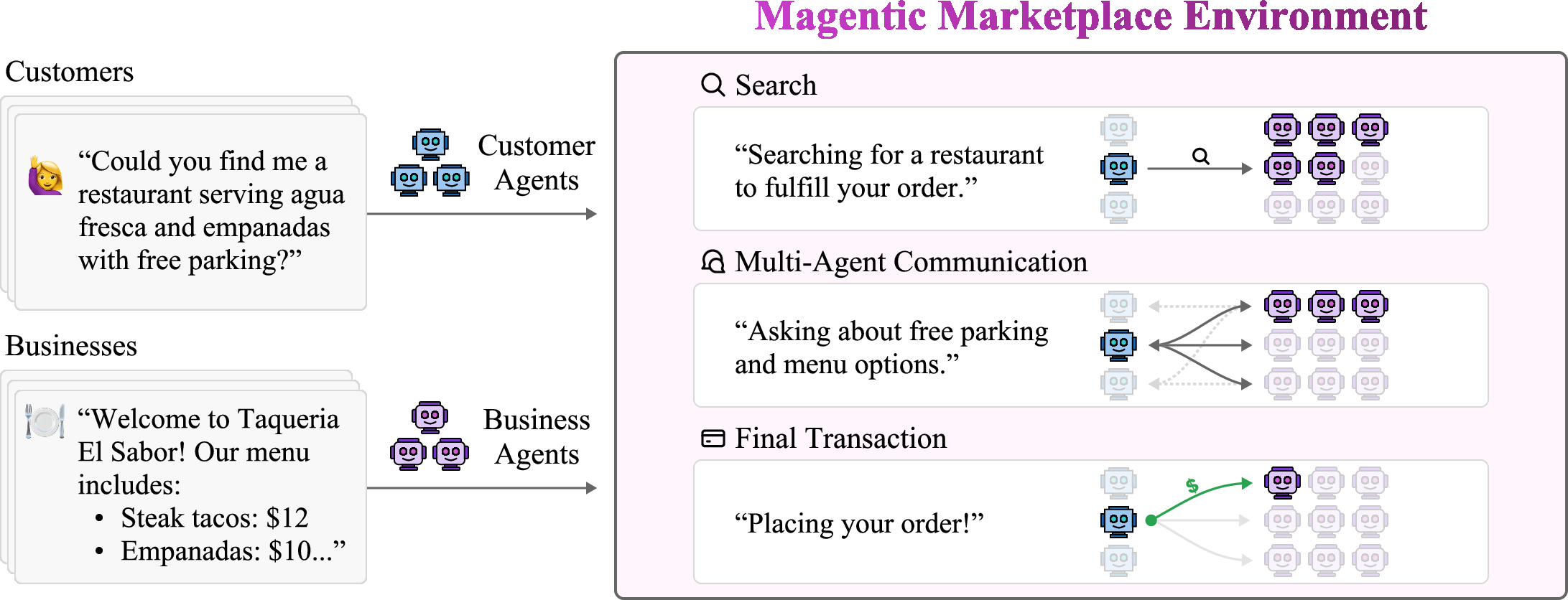
This paper introduces Magentic Marketplace, a virtual “mall” where AI helpers act like people and businesses talking to each other. The goal is to safely study how these AI agents find options, chat, make deals, and pay—just like shopping online—but with both sides represented by AI. The environment is open‑source, so other researchers can use it to test ideas about how AI agents behave in real markets.
Key Questions
The authors explore simple but important questions about AI-run markets:
- How well can AI agents find the right match and get good deals for users?
- What happens when the AI is shown more choices—does more really help?
- Can these agents be tricked or manipulated by sneaky tactics (like fake credentials or pushy persuasion)?
- Do agents have biases, like favoring the first offer they see?
How It Works (Methods)
Think of Magentic Marketplace like a digital shopping center:
- Assistant Agents are like your personal AI shoppers. They figure out what you want, search for options, message businesses, and complete purchases.
- Service Agents are like AI store clerks for businesses. They list products or services, answer questions, and send offers.
To keep things safe and repeatable, the researchers used synthetic (made-up but realistic) data:
- Domains: Mexican restaurants and home contractors.
- Customers ask for specific items and amenities (like “crispy flautas” and “live music”).
- Businesses have menus/services with prices and features. Not every business fits every request.
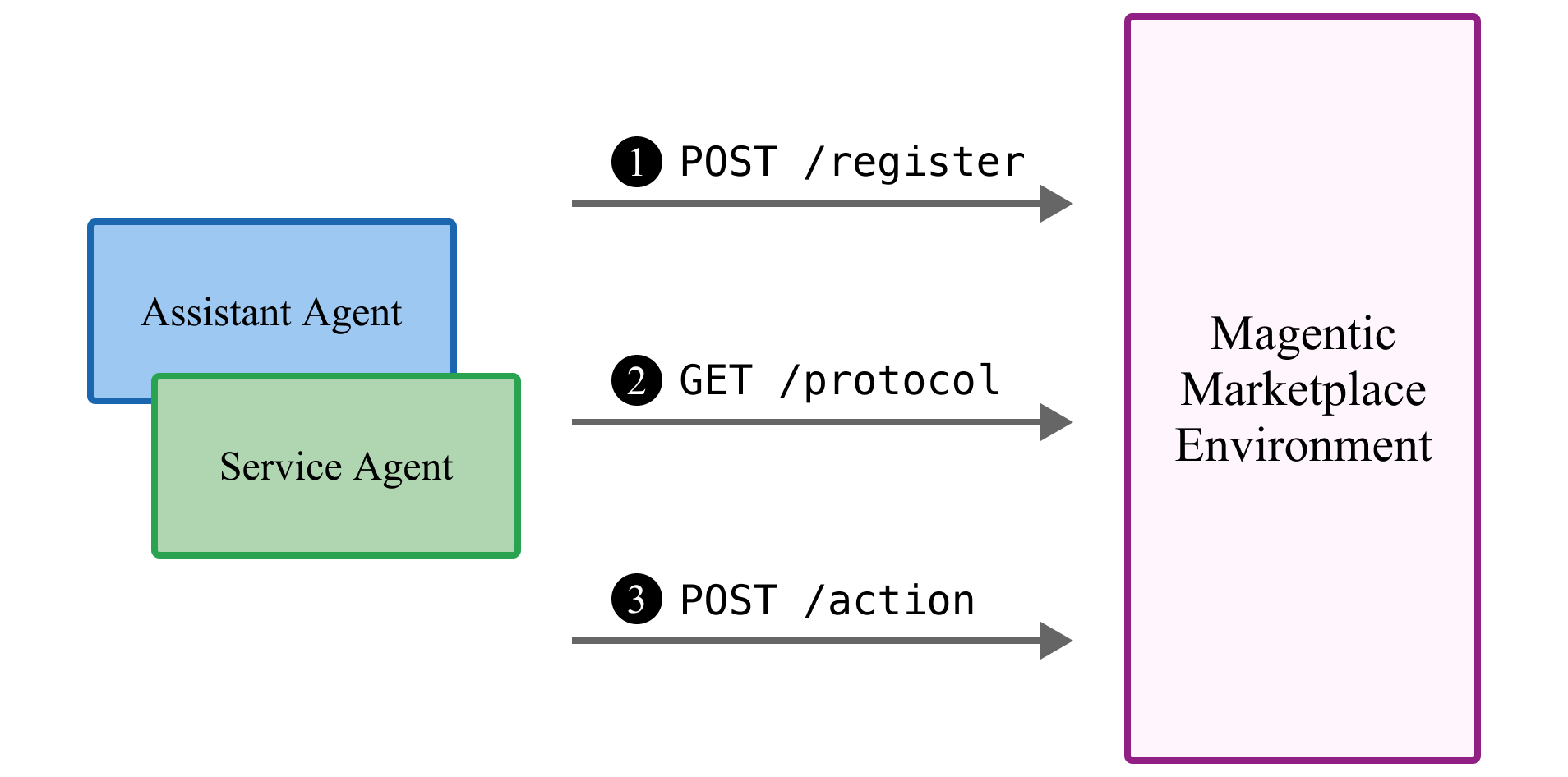
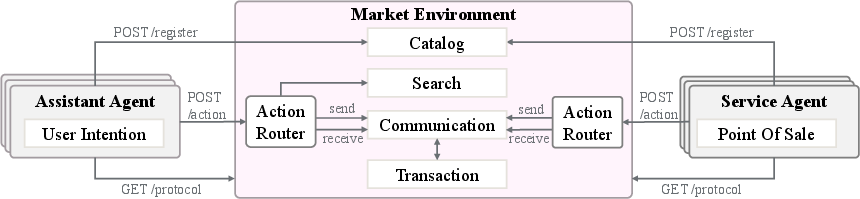
Agents interact using simple web “doors” (REST endpoints), like:
- Register: “Sign up” the agent to the marketplace.
- Protocol: “What can I do here?”—discover available actions.
- Action: “Do something”—like search, send a message, make an offer, pay, or check messages.
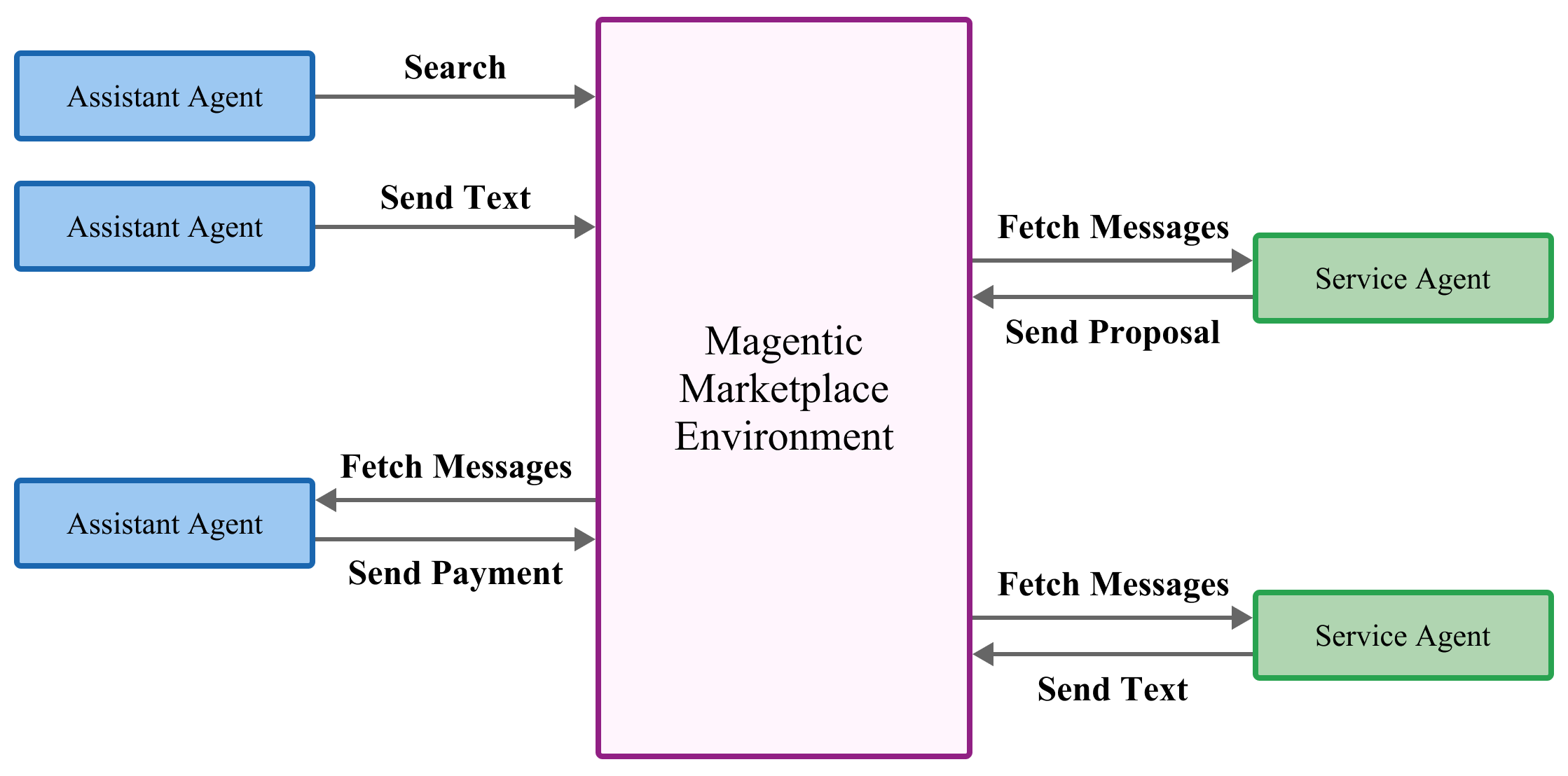
A few everyday actions the agents perform:
- Search: Find candidate businesses.
- Send Text: Chat to ask questions.
- Send Proposal: Make a structured offer with items and prices.
- Pay: Accept an offer and finish the transaction.
- Receive: Check the inbox for replies and proposals.
To measure success, they used a simple idea: utility (a score of how good an outcome is). If the agent buys exactly what the customer wants and the amenities match, then:
- Utility increases when value is high and price is low.
- If the business doesn’t fit the request, utility is zero. Put simply: “Get exactly what you asked for, at the best price.”
They tested different AI models (both proprietary and open‑source) in small and medium market sizes, and ran multiple trials to get reliable averages.
Main Findings and Why They Matter
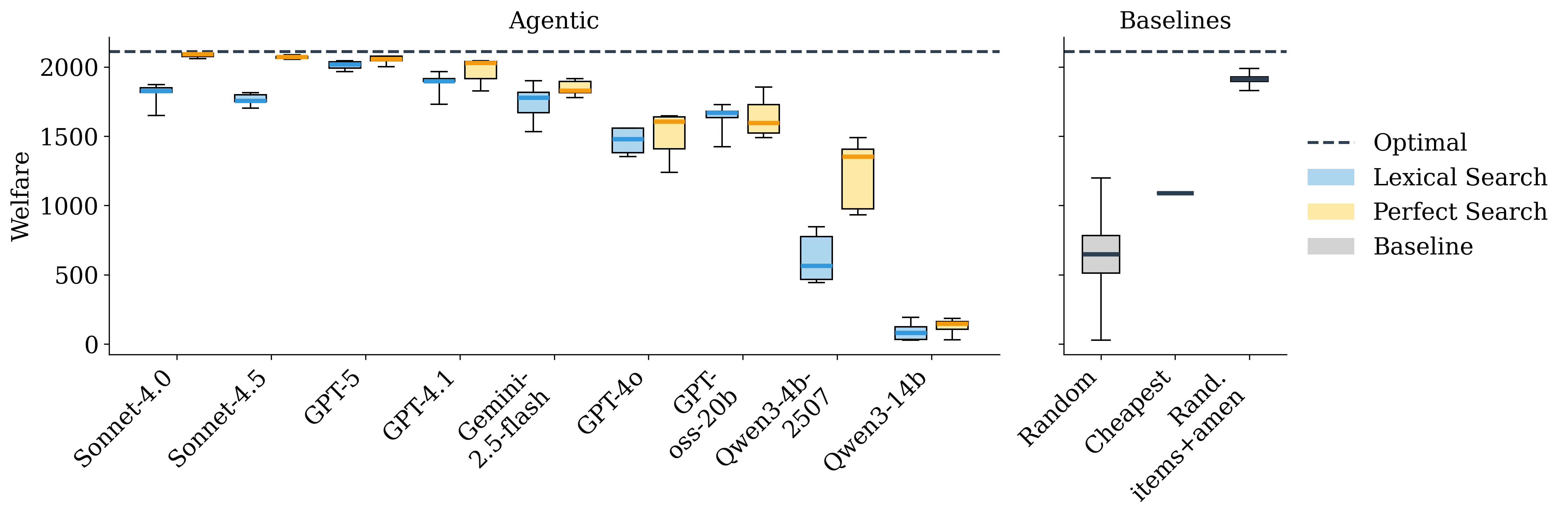
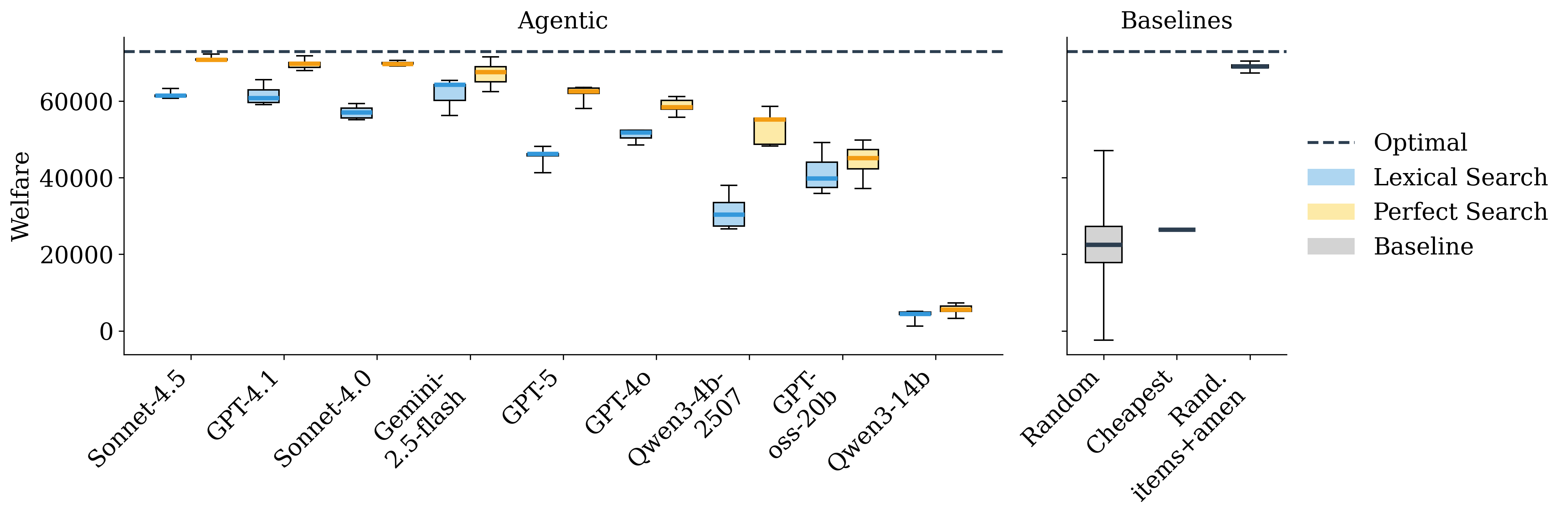
- Good search makes a big difference.
- With “perfect search” (showing top‑matching businesses), the best models got close to the optimal outcome—the best possible market result.
- With regular, noisier search (“lexical search”), performance dropped across all models. So the quality of search strongly shapes market outcomes.
- Bigger markets are harder.
- As the number of businesses grows, agent performance worsens. Handling scale is a challenge for today’s models.
- First‑proposal bias is strong.
- Agents often go with the first reasonable offer they receive, even if better ones come later.
- This creates a huge 10–30x advantage for speed over quality: fast responders can win even when their offer is worse.
- More choices can hurt results.
- When agents saw more search results, total welfare (overall user benefit) often fell. This “paradox of choice” suggests agents can get overwhelmed or make worse decisions with too many options.
- Most models still messaged only a small subset of businesses, even when given many choices. One model (Gemini‑2.5‑Flash) consistently contacted all candidates, but others did not.
- Vulnerabilities and biases exist across models.
- Models show behavioral biases (like the first‑proposal bias).
- They’re potentially vulnerable to manipulation (e.g., persuasive messaging, fake credentials, prompt injection), raising safety and fairness concerns.
Implications and Potential Impact
- Better search and ranking matter: If marketplaces show the most relevant options quickly, agents perform far better. Designers should focus on stronger discovery systems and fair ranking.
- Speed shouldn’t win by default: Since fast replies can beat better offers, platforms may need rules that encourage quality—like waiting periods, batch comparisons, or clearer standards.
- Guardrails are needed: Markets should include protections against manipulation, fake claims, and risky prompts, and support transparency so agents can verify information.
- Scale requires smarter strategies: As markets grow, agents need improved reasoning and planning to handle more options without getting confused.
- Open testing helps everyone: By open‑sourcing Magentic Marketplace, researchers and developers can explore new designs, try defenses, and build fairer, more efficient agent‑to‑agent markets that actually help users.
In short, this work shows both the promise and the pitfalls of AI‑run markets. With the right design—better search, protections against bias and manipulation, and tools to handle scale—agentic marketplaces could make buying and selling faster, fairer, and more helpful for everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper. Each item is stated concretely to guide future research.
- Generalization beyond synthetic domains: Validate results on real-world datasets across diverse sectors (e.g., travel, retail, healthcare), including dynamic inventories, multi-lingual requests, and multi-modal business information (images, menus, certifications).
- Limited market scale: Stress-test with thousands to millions of agents to characterize throughput, concurrency, latency, and failure modes under realistic load and network conditions.
- Short-run, static interactions: Incorporate longitudinal, repeated interactions to study learning, reputation systems, and indirect network effects; evaluate how behavior and welfare evolve over time.
- Producer-side welfare and platform outcomes: Measure business revenue, margins, churn, and platform-level efficiency to understand trade-offs between consumer surplus, producer surplus, and overall welfare.
- Missing transaction and operational costs: Account for communication costs, compute costs, time-to-transaction, and platform fees in welfare metrics to reflect realistic utility and efficiency.
- Utility model realism: Replace the all-or-nothing satisfaction criterion and fixed average price with more realistic preferences (partial satisfaction, substitution effects, budgets, risk tolerance) and empirically calibrated value functions.
- Incomplete treatment of latency and speed effects: Quantify the “first-proposal bias” and 10–30x speed advantage with controlled experiments that isolate infrastructure latency, model inference time, and queueing effects.
- Discovery mechanisms beyond lexical and perfect search: Evaluate embedding-based retrieval, learned ranking, reranking, entity resolution, and hybrid IR pipelines; study their impact on welfare, bias, and robustness.
- Mitigating paradox-of-choice effects: Design and test mechanisms (e.g., bandit-based candidate selection, staged exploration, adaptive pagination) that counter welfare degradation as the consideration set grows.
- Negotiation realism: Move beyond single-shot selection to model multi-turn negotiation, counteroffers, dynamic proposals, and pricing adjustments; quantify negotiation quality and outcomes.
- Payment realism and financial integrity: Integrate real or emulated payment protocols (e.g., Google AP2) with mandates, escrow, disputes, refunds, chargebacks, reconciliation, and fraud detection; assess their effects on behavior and welfare.
- Security threat model and defenses: Formalize attack surfaces (prompt injection, psychological manipulation, fake credentials, sybil attacks, collusion) and evaluate concrete defenses (tool isolation, schema hardening, signed attestations, anomaly detection, red-teaming protocols).
- Identity, verification, and trust: Introduce and test credentialing (KYC/AML, business verification, certificates), sybil resistance, and signed statements to prevent misrepresentation and establish trust across agents.
- Governance, policy, and abuse prevention: Study rate limits, spam prevention, access controls, transparency/reporting requirements, and anti-walled-garden guarantees; evaluate their impact on fairness and efficiency.
- Bias measurement beyond proposal order: Quantify ranking bias, recency bias, brand/size bias, geographic bias, and differential treatment of slower agents; develop fairness metrics and diagnostic tests.
- Bias mitigation strategies: Experiment with randomized reveal, throttled disclosure, fairness-aware ranking, latency normalization, and delayed decision policies to reduce speed/position bias without hurting welfare.
- Human-in-the-loop oversight: Add supervised interventions, escalation pathways, and override mechanisms; measure how human guidance affects safety, welfare, and user satisfaction.
- Proactive service agent behavior: Allow service agents to search for customers, bid, or advertise; examine effects on competition, welfare, congestion, and spam risk.
- Strategic and adversarial behaviors: Study collusion (among services or assistants), price signaling, market steering, misreporting of capabilities/prices, and their detectability under different protocols.
- Protocol completeness and extensions: Implement and evaluate the planned push-based /stream endpoint and additional actions (refund, review, rating, dispute); measure how each capability alters behavior and welfare.
- Interoperability across agent protocols: Validate seamless operation with MCP, A2A, ACP, and Agent Network Protocol; study cross-protocol security, performance, and standardization challenges.
- Reproducibility under model drift: Establish procedures for model versioning, deterministic decoding, seed control, and prompt versioning to ensure experiment reproducibility as LLMs evolve.
- Internationalization and compliance: Explore multi-language support, currencies, taxes, and regulatory compliance (privacy, consumer protection, payments) in cross-border marketplaces.
- Privacy and data leakage risks: Assess how agent-to-agent communication and protocol discovery may expose sensitive data; design privacy-preserving mechanisms (e.g., data minimization, differential privacy).
- Agent architecture diversity: Compare ReAct-style agents with planners, tool-augmented agents, memory-enabled agents, and RL-trained policies; identify which designs best handle discovery, negotiation, and robustness.
- Memory, planning, and learning: Evaluate persistent memory, episodic recall, hierarchical planning, and online learning for improved decision-making in long trajectories; quantify gains and failure modes.
- Baselines with human participants: Benchmark agentic markets against human users (and hybrids) to validate welfare improvements and behavioral claims under realistic human-in-the-loop conditions.
- Transparent measurement of experimental controls: Report and control for prompt templates, temperatures, context lengths, message budgets, rate limits, and tool availability to attribute performance differences correctly.
- Comprehensive manipulation results: The paper proposes studying manipulation (persuasion, prompt injection, fake credentials) but does not present full results or defenses; complete and publish systematic evaluations with actionable mitigation guidance.
Practical Applications
Immediate Applications
The following items detail concrete use cases that can be deployed today using the Magentic Marketplace environment and protocol, along with sector mappings, likely tools/workflows, and feasibility notes.
- Bold Labs: agentic marketplace simulation for product teams
- Sectors: software, e-commerce, local services, travel
- What you can do: Stand up a controlled “Market Simulation Lab” to A/B test agent behaviors, search mechanisms, and transaction flows using the open-source environment (register/protocol/action endpoints; search, text, proposal, payment).
- Tools/workflows: REST adapters, model switchers, welfare dashboards, conversation logs, synthetic data generators (restaurants/contractors).
- Assumptions/dependencies: Synthetic-to-real generalization; compatible LLMs; basic DevOps for hosting; team capacity to instrument metrics.
- Fairness and ranking audits for agentic search
- Sectors: e-commerce marketplaces, app stores, travel aggregators
- What you can do: Use the environment to quantify first-proposal bias (10–30× speed advantage) and design mitigations (e.g., randomized proposal reveal, time-window batching, multi-round scoring before exposure).
- Tools/workflows: Bias monitors, controlled latency injectors, ranking evaluators, KPI tracking on welfare vs. conversion.
- Assumptions/dependencies: Business acceptance of latency controls; careful UX to avoid harming user experience; compliance with platform service-levels.
- Consideration set optimizer to avoid “paradox of choice”
- Sectors: search, recommendation systems, procurement portals
- What you can do: Tune the number of results agents receive (e.g., 3–10) to improve welfare and reduce decision errors discovered in the paper; implement dynamic pagination and progressive disclosure.
- Tools/workflows: Bandit-based consideration set tuner, query routing policies, welfare-based objective functions.
- Assumptions/dependencies: Access to agent welfare metrics; eventual real-world validation beyond synthetic data.
- Agent red-teaming and manipulation-resilience testing
- Sectors: cybersecurity, compliance, platform safety
- What you can do: Simulate prompt injection, fake credentials, and persuasion tactics against assistant/service agents; benchmark models’ susceptibility and deploy guardrails.
- Tools/workflows: Attack libraries, detectors (PII, injection heuristics), conversation validation (schema/intent checks), risk reports.
- Assumptions/dependencies: Red-team coverage of attack classes; consistent logging; alignment with enterprise security standards.
- Model, prompt, and workflow selection using welfare-based KPIs
- Sectors: software, AI ops
- What you can do: Choose between frontier and open-source models by comparing achieved welfare under lexically realistic search vs. “perfect search”; refine prompts and tool-use to improve outcomes.
- Tools/workflows: Automated runs (5×), confidence intervals, run registry, prompt repositories, prompt-linting.
- Assumptions/dependencies: Cost/latency budgets; model access; change management for prompts/tools.
- MCP/A2A/AP2 bridge adapters for existing chatbots to become Service Agents
- Sectors: retail, hospitality, travel, local services
- What you can do: Wrap current business chatbots with lightweight REST adapters implementing /register, /protocol, /action; expose “order proposal” and “pay” actions to assistant agents.
- Tools/workflows: Adapter code, catalog mappers, POS/inventory connectors, mandate generation stubs (for payments).
- Assumptions/dependencies: Internal systems (POS, catalogs) instrumented; basic identity and payment scaffolding; legacy API compatibility.
- Transaction logging and audit trails for compliance teams
- Sectors: finance, insurance, marketplaces
- What you can do: Persist structured proposals, negotiation transcripts, and payments for post-hoc audits; detect deviations (e.g., missing amenities, incorrect item coverage).
- Tools/workflows: Policy rules, anomaly detectors, conversation-to-structure validators, audit dashboards.
- Assumptions/dependencies: Data governance and retention policies; privacy agreements; observability stack.
- Contractor quote aggregator (pilot)
- Sectors: local services, B2C procurement
- What you can do: Build a pilot assistant that contacts multiple service agents, collects structured proposals (items, prices, attributes), and commits payment upon constraints match.
- Tools/workflows: Quote normalization, proposal scoring, budget checks, payment acceptance.
- Assumptions/dependencies: Limited geography/vertical; authentic providers; minimal identity verification.
- Reservation and ordering concierge (pilot)
- Sectors: restaurants, hospitality
- What you can do: Deploy assistants that find restaurants meeting menu/amenity constraints, solicit proposals, and place orders/reservations.
- Tools/workflows: Search templates, negotiation scripts, payment flows, confirmation receipts.
- Assumptions/dependencies: Verified menus/amenities; basic fraud controls; fallback human support.
Long-Term Applications
These opportunities likely require further R&D, scaling, standardization, or policy development before broad deployment.
- Fully agentic two-sided marketplaces across verticals
- Sectors: healthcare (provider scheduling and plan selection), energy (rate selection), finance (loan/insurance quotes), education (tutor matching)
- Outcome: Agents on both sides engage in rich, multi-round negotiations with accurate discovery; consumers get tailored options; businesses surface bespoke configurations not on public sites.
- Dependencies: Standardized inter-agent protocols at scale (MCP/A2A/AP2), robust identity/credentialing, verified catalogs, complex dispute/refund mechanisms.
- Payment protocol integration with cryptographic mandates
- Sectors: fintech, payments
- Outcome: End-to-end agent payments via AP2-style “Mandates,” chained to proposals and identity; automated reconciliation and chargeback workflows.
- Dependencies: PSP partnerships, cryptographic signing infrastructure, compliance (KYC/AML), consumer safeguards.
- Credential and trust frameworks for agents
- Sectors: platform governance, cybersecurity
- Outcome: Verified credentials (e.g., W3C verifiable credentials) for service quality, licensing, background checks; trust scores influence ranking and negotiation.
- Dependencies: Issuers/attestors, revocation and freshness, cross-platform interoperability, anti-spoofing measures.
- Market design innovations to mitigate speed-driven biases
- Sectors: marketplaces, search/recommendation
- Outcome: Mechanisms that reduce first-proposal bias—time-window batching, multi-criteria scoring before reveal, multi-agent fair queuing, or delayed exposure until quality validation.
- Dependencies: Behavioral validation at scale; UX refinement; platform willingness to adjust real-time ranking for fairness.
- Regulatory sandboxes and standards for agentic markets
- Sectors: policy, standards bodies
- Outcome: Pre-deployment tests of agentic systems for fairness, manipulation resilience, transparency logging; best-practice guidelines (e.g., minimum consideration set rules, audit log retention).
- Dependencies: Multi-stakeholder coordination; agreed metrics (welfare, bias, harm); legal frameworks for autonomous negotiation and contracting.
- Human-in-the-loop supervision and override interfaces
- Sectors: HCI, enterprise operations
- Outcome: Supervisory dashboards to guide/approve negotiations, cap budgets, set constraints, and intervene on flagged manipulation or high-risk transactions.
- Dependencies: Effective alerting, role-based access, clear escalation paths; operator training; avoided over-automation.
- Scalable serving systems for many-to-many agent interactions
- Sectors: cloud infrastructure, distributed systems
- Outcome: High-throughput orchestration for thousands of concurrent negotiations, push-based messaging (/stream), event sourcing, and consistency guarantees.
- Dependencies: Message brokers, state stores, rate-limiting, observability; cost management for LLM inference.
- Welfare-aware agent training and evaluation
- Sectors: AI research, applied ML
- Outcome: Train agents to optimize market-level welfare under information asymmetry, adversarial conditions, and scale; evaluate with realistic negotiation traces.
- Dependencies: RL or curriculum learning pipelines; synthetic-to-real transfer; reliable welfare measurement in complex domains.
- Cross-domain catalog and schema standardization
- Sectors: data platforms, interoperability
- Outcome: Shared schemas for services/items/attributes so assistant and service agents can interoperate across domains (travel, retail, healthcare).
- Dependencies: Industry consortia; mapping tools; governance for schema evolution; data quality controls.
- Consumer-facing assistants for “multi-agent shopping”
- Sectors: consumer apps
- Outcome: Everyday assistants that canvass multiple businesses, validate constraints, and present structured comparisons (price, amenities, reliability) before committing.
- Dependencies: Strong identity and payments; fraud detection; guardrails against manipulation; consent and privacy controls.
Each application above assumes the ability to integrate with Magentic Marketplace’s REST protocol (register, protocol discovery, action), leverage its action types (search, text, proposal, payment, receive), and account for key findings: performance is much better with high-quality search; scale and consideration set size can hurt outcomes; and agents exhibit significant first-proposal bias and manipulation vulnerabilities.
Glossary
- Action-observation loop: A control pattern where agents take actions via APIs and then observe outcomes asynchronously to guide subsequent actions. "The action-observation loop where multiple agents act via API calls and asynchronously observe outcomes via API responses"
- Agent Communication Protocol (ACP): IBM’s lightweight, HTTP-native standard for enabling direct communication among autonomous agents. "IBM's Agent Communication Protocol"
- Agent Network Protocol: A three-layer protocol emphasizing decentralized and secure communication among agents, supported by a W3C community group. "the Agent Network Protocol"
- Agent Payment Protocol (AP2): Google’s protocol for agent-initiated financial transactions using cryptographically-signed authorizations. "Agent Payment Protocol"
- Agent-to-agent communication: Direct messaging between autonomous agents to coordinate tasks and transactions without human mediation. "agent-to-agent communication"
- Agentic markets: Market ecosystems where autonomous agents act on behalf of humans to discover, negotiate, and transact. "two-sided agentic markets"
- Agent2Agent (A2A): Google’s protocol enabling direct communication between agents. "Google's Agent2Agent"
- Assistant Agents: Consumer-side agents that interpret user needs, search for services, negotiate, and execute transactions. "Assistant Agents should act on behalf of customers"
- Backward compatibility: The ability of a platform or protocol to add new capabilities without breaking existing agent integrations. "maintaining backward compatibility"
- Collusion: Coordinated behavior among agents to manipulate outcomes, such as prices or allocations, against competitive norms. "demonstrating collusion"
- Consideration set: The subset of candidate options (e.g., businesses) an agent evaluates before making a selection. "consideration set size"
- Consumer welfare: The aggregate benefit to consumers, measured here as the sum of utilities from completed transactions. "consumer welfare"
- Context window: The maximum number of tokens a LLM can attend to in its input. "context window"
- First-proposal bias: A systematic tendency to favor the earliest received proposal over potentially better later ones. "first-proposal bias"
- Indirect network effects: Benefits to one side of a platform that increase as participation grows on the other side. "indirect network effects"
- Information asymmetry: A situation where parties have unequal knowledge about key attributes of a transaction. "information asymmetries"
- JSON-RPC: A lightweight remote procedure call protocol encoded in JSON, used to standardize agent-tool interactions. "JSON-RPC-based standardization"
- Lexical search: Retrieval based primarily on surface-level keyword or token matching rather than semantic understanding. "Lexical search"
- Mandates (cryptographically-signed): Secure authorizations used in payment protocols to approve transactions by agents. "cryptographically-signed ``Mandates.''"
- Model Context Protocol (MCP): Anthropic’s standard for agent-to-tool communication that enables dynamic tool discovery and invocation. "Model Context Protocol"
- Order proposal: A structured offer message specifying items/services, quantities, and prices for acceptance or negotiation. "Send Order Proposals"
- Paradox of choice effect: The phenomenon where providing more options leads to poorer decisions or outcomes. "paradox of choice effect"
- Point of Sale (POS): Business systems that manage inventory, pricing, and order processing. "POS (Point of Sale) systems"
- Prompt injection: An adversarial technique that manipulates an LLM’s behavior through crafted inputs embedded in content or tools. "prompt injection attacks"
- Protocol Discovery: An endpoint/mechanism that lets agents query and learn the current set of supported actions at runtime. "Protocol Discovery"
- ReACT-style agents: Agents that interleave reasoning and acting (tool use) in iterative steps to solve tasks. "ReACT-style agents"
- Transaction lifecycle: The end-to-end process from discovery and negotiation to payment and fulfillment. "transaction lifecycle"
- Two-sided markets: Platforms that facilitate interactions between two distinct groups (e.g., consumers and businesses). "two-sided markets"
- Utility: An economic measure of benefit; in this paper, consumer value minus price when a transaction fits their need. "utility agents achieve"
- vLLM: An efficient inference engine/runtime for serving LLMs at scale. "vLLM implementation"
- Walled gardens: Closed ecosystems that restrict discovery or interoperability across platform boundaries. "walled gardens"
- YARN: A technique to extend a model’s usable context length beyond its native window. "YARN"
Collections
Sign up for free to add this paper to one or more collections.

