- The paper introduces CTD, a model cascade that uses a delegation value probe and rigorous calibration to control expert escalation.
- It demonstrates significant improvements, achieving up to +11% AUROC and +19% accuracy over uncertainty-based delegation methods.
- The framework enables adaptive budget allocation and group-level risk estimation, ensuring safe and cost-efficient monitoring of LLMs.
Calibrate-Then-Delegate: Safety Monitoring with Risk and Budget Guarantees via Model Cascades
Introduction
Safety monitoring for deployed LLMs is fundamentally constrained by the tradeoff between inference cost and predictive reliability. Latent-space probes, which operate on internal model activations, yield low-latency safety scores but are susceptible to miscalibration and adversarial obfuscation. Model cascades—where a cheap probe defers high-stakes instances to a more capable but costly expert—address these vulnerabilities, but effective routing is complex: common uncertainty-based delegation mechanisms are agnostic to whether escalation actually improves prediction.
This paper introduces Calibrate-Then-Delegate (CTD), a cascade framework that leverages a Delegation Value (DV) probe to predict instance-level benefit from expert escalation. CTD instantiates finite-sample delegation-rate control via Learn-then-Test (LTT) calibration, enabling streaming decisions with PAC-style guarantees and Pareto-filtered thresholding to avoid harmful over-delegation. Empirical results on four safety benchmarks demonstrate that CTD consistently outperforms uncertainty-based delegation, especially when the expert is weaker than the probe.
Delegation Value Probes and Calibration
Probe confidence has been widely used as the escalation signal in cascades, but it fails to align with expert correctness, often delegating cases where the expert also errs or missing those where delegation would correct a probe-induced error. The key innovation in CTD is the delegation value v(x,y)=Pϵ(y∣x)−Pρ(y∣x), quantifying, for each input (x,y), the marginal improvement from invoking the expert. This signal is learned as a regression probe d(x) on latent representations, trained on labeled examples where ground-truth delegation benefit v(x,y) is computed offline.
Delegation policies in CTD are threshold-based: input x is escalated if d(x)>λ. LTT calibration (using fixed-sequence multiple hypothesis testing) selects λ to formally bound the delegated fraction to a prescribed budget level α, maximizing empirical cascade performance while controlling family-wise error rate.
Pareto filtering further restricts candidates to those non-dominated in both budget and performance risk, empowering cascades to adaptively select thresholds that avoid over-delegation—particularly crucial when the expert underperforms the probe.
Empirical Results
CTD was evaluated across four safety-relevant benchmarks—Anthropic-HH, MTSamples, MTS-Dialog, and ToolACE—using both strong and weak expert models. Comparisons included calibrated and batch top-k routing with uncertainty and DV signals.
For strong experts (e.g., Gemma-3-27B-IT), CTD achieves up to +7.9% gains in AUROC and (x,y)0 accuracy over uncertainty-based delegation, closely tracking performance of batch DV top-(x,y)1 across budget levels and plateauing beyond effective delegation capacity, while uncertainty-based cascades degrade due to compulsory over-delegation.
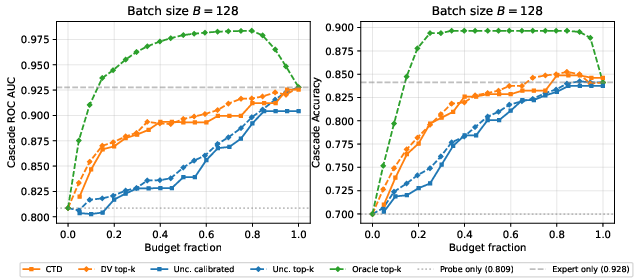
Figure 2: Cascade performance versus delegation budget with strong expert, showing that DV probe-based delegation dominates uncertainty and avoids harmful over-delegation at high budgets.
For weak experts (e.g., Llama-3.2-1B-Instruct), CTD isolates the sparse cases where delegation is beneficial, capping the delegation rate adaptively and maintaining performance above the probe-only baseline at high budgets. Gains here are even more pronounced: up to (x,y)2 AUROC and (x,y)3 accuracy.
Batch-size sensitivity analyses confirm qualitative robustness across various batch regimes.
Quality of DV Probe Signal
DV probes exhibit strong ranking capability: for both strong and weak experts, the mean ground-truth delegation value of the top-(x,y)4 inputs selected by (x,y)5 is consistently greater than those selected by uncertainty, indicating superior targeting of beneficial escalation.
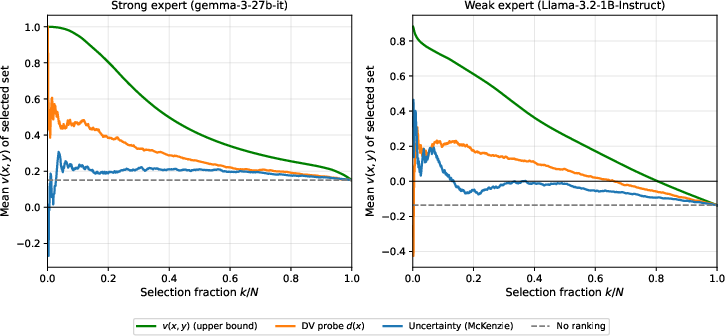
Figure 4: Mean delegation value of top-(x,y)6 examples ranked by DV versus uncertainty signals, evidencing that the DV probe more effectively targets cases with positive expert correction.
Continuous delegation value targets outperform binary flip indicators (appendix), especially at higher budgets and with weaker experts, by providing more granular ranking.
Group-Level Analysis
Without explicit group supervision, the DV probe recovers the correct inter-group ordering of delegation benefit across the benchmarks. At low budgets, CTD over-represents groups with highest (x,y)7, dynamically adjusting allocation as budget grows. In contrast, uncertainty-based delegation fails to align budget allocation with expert value, often delegating to groups where delegation is harmful.
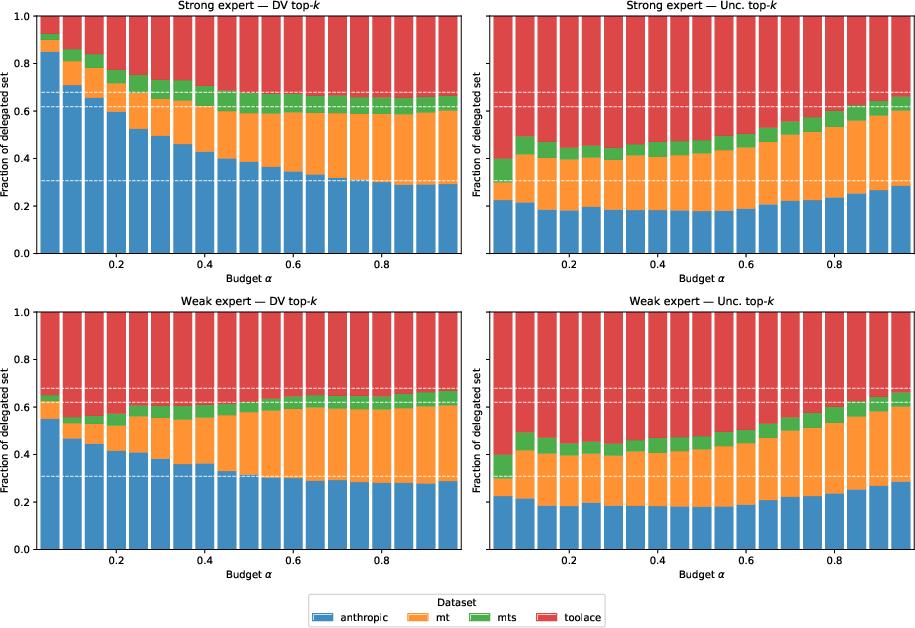
Figure 1: Composition of delegated sets by dataset group; DV signal adaptively concentrates budget on high-benefit groups and shifts allocation as budget increases.
Scatter analyses show group-mean DV probe output correlates with ground-truth mean delegation value, demonstrating probe generalization to group-level risk estimation.
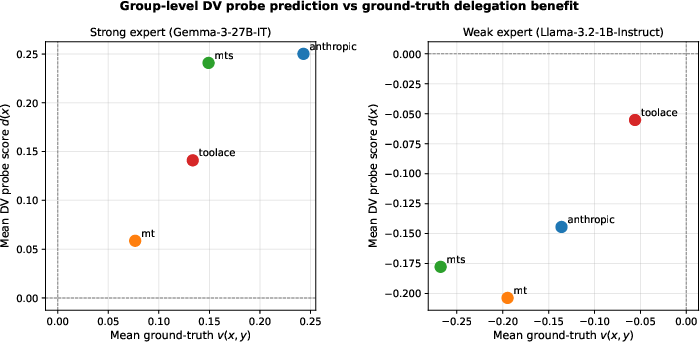
Figure 7: Correlation between group-level mean DV probe output and ground-truth mean delegation value for both expert types.
Finite-Sample Guarantees
Empirical validation confirms that realized delegation rates on held-out data closely fit prescribed budgets, with violation frequencies tracking calibration confidence (x,y)8, and Pareto filtering yielding conservative control.
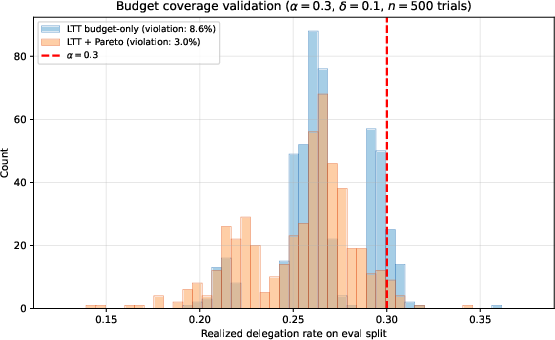
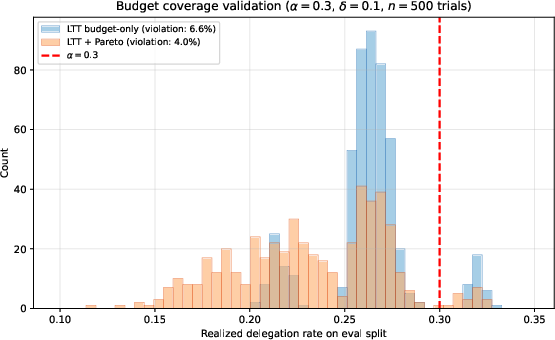
Figure 3: Distribution of realized delegation rates across calibration splits; Pareto filtering ensures stricter control with low violation.
Implications and Future Directions
CTD advances practical, verifiable LLM safety monitoring for real-time and streaming deployment scenarios, providing formal delegation rate bounds and avoiding batch-level constraints. The DV probe, operating at negligible marginal cost, enables dynamic, performance-aligned allocation of expert resources. Theoretical implications include improved cost-risk tradeoff characterization in model cascades and new affordances for online and group-level adaptation.
Future work should integrate richer expert models (e.g., chain-of-thought supervision), extend DV signal learning to multi-class settings, and incorporate adversarial robustness mechanisms for probe-obfuscation resistance. Interaction with broader risk control frameworks—including conformal prediction and dynamic calibration—remains an active direction.
Conclusion
The CTD framework improves safety monitoring cascades by replacing probe uncertainty with a learned, target-aligned delegation value signal, combining rigorous statistical calibration and Pareto filtering to guarantee risk and budget control. Empirical validation demonstrates dominance over uncertainty-based delegation, especially when expert models vary in capability, and showcases adaptive budget allocation with group-level fidelity. The approach is immediately applicable to real-world LLM deployments requiring cost-efficient, transparent escalation policies and represents a significant methodological advance in practical AI safety instrumentation.

