- The paper presents BARGAIN, which employs adaptive sampling and a betting-based estimator to achieve strong, finite-sample guarantees while cutting expensive oracle calls.
- It demonstrates up to 86% reduction in oracle usage and significant improvements in recall and precision compared to prior cascaded models like SUPG.
- BARGAIN dynamically selects cascade thresholds through data-aware sampling, enabling scalable, cost-efficient LLM-powered data processing in real-world applications.
Cost-Efficient LLM-Powered Data Processing with Guarantees: An Analysis of BARGAIN
Introduction and Motivation
The paper "Cut Costs, Not Accuracy: LLM-Powered Data Processing with Guarantees" (2509.02896) addresses the challenge of deploying LLMs for data processing at scale, where the high cost of top-tier models (e.g., GPT-4o) is prohibitive for large datasets. The central problem is to minimize inference costs by judiciously using cheaper proxy models (e.g., GPT-4o-mini) while providing rigorous guarantees on output quality—specifically, accuracy, precision, or recall—relative to the oracle model. The work critiques prior model cascade approaches, particularly SUPG, for their weak (asymptotic) guarantees and suboptimal utility, and introduces BARGAIN, a method that leverages adaptive sampling and modern statistical estimation to provide strong, non-asymptotic guarantees with significantly improved cost savings.
The model cascade paradigm is formalized as follows: Given a dataset D, an expensive oracle model O, and a cheap proxy model P, the system must decide for each record whether to use P or O, based on a proxy confidence score S(x). The decision is parameterized by a cascade threshold ρ; records with S(x)≥ρ are handled by the proxy, others by the oracle. The goal is to set ρ to maximize utility (e.g., cost savings, recall, or precision) while ensuring, with high probability 1−δ, that the output meets a user-specified quality target T (accuracy, precision, or recall).
Three query types are considered:
- Accuracy Target (AT): Minimize oracle calls while ensuring output accuracy ≥T.
- Precision Target (PT): Maximize recall under a fixed oracle budget, ensuring precision ≥T.
- Recall Target (RT): Maximize precision under a fixed oracle budget, ensuring recall ≥T.
Limitations of Prior Work
Existing methods, notably SUPG [kang2020approximate], use importance sampling and central limit theorem (CLT)-based estimation to set cascade thresholds. However, these approaches:
- Provide only asymptotic guarantees, failing to control the probability of missing the target at finite sample sizes.
- Rely on worst-case union bounds and data-agnostic estimation, leading to conservative thresholds and poor utility.
- Do not adapt sampling to the quality target or the empirical distribution of proxy scores and labels, resulting in inefficient use of the oracle budget.
The BARGAIN Framework
BARGAIN introduces a principled, data- and task-aware approach to model cascade threshold selection, with the following key innovations:
1. Adaptive Sampling
Rather than sampling uniformly or by fixed importance weights, BARGAIN adaptively samples records based on the current candidate threshold and observed labels. For each candidate threshold ρ, it samples from Dρ (records with S(x)≥ρ), focusing the oracle budget on the region most relevant for threshold estimation. Sampling continues until the estimation procedure is confident about whether ρ meets the target.
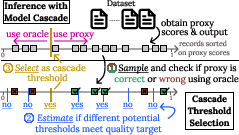
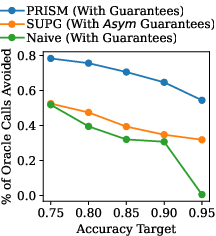
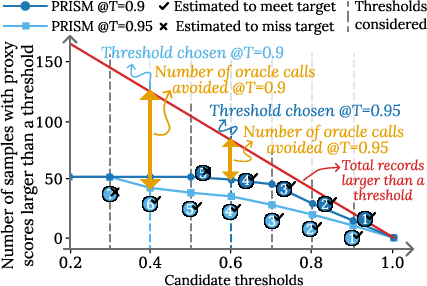
Figure 1: Overview of Model Cascade. The cascade threshold ρ partitions records for proxy or oracle processing; BARGAIN adaptively samples to estimate the optimal ρ.
2. Modern Statistical Estimation
BARGAIN replaces classical concentration inequalities (e.g., Hoeffding, Chernoff) with a hypothesis-testing approach based on the betting framework of Waudby-Smith and Ramdas [waudby2024estimating]. This estimator leverages both the empirical mean and variance of observed labels, yielding tighter, data-dependent confidence bounds, especially when the variance is low (i.e., when the proxy is highly accurate at high scores).
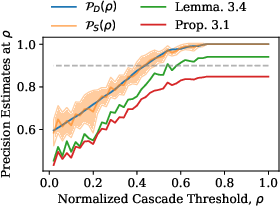
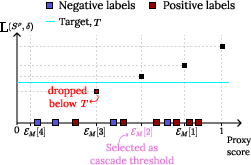
Figure 2: Comparison of lower bounds on true precision at fixed sample sizes. BARGAIN's estimator (betting-based) is significantly tighter than Hoeffding or Chernoff, especially at high precision.
3. Data-Aware Threshold Selection
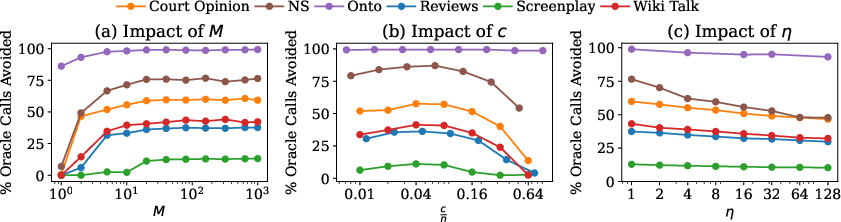
BARGAIN's threshold selection algorithm incorporates a tolerance parameter η to exploit empirical monotonicity in real-world datasets (i.e., precision/accuracy typically decreases monotonically with decreasing proxy score). This allows the method to avoid unnecessary union bounds over all candidate thresholds, further tightening guarantees and improving utility.
Figure 3: Overview of Model Cascade. BARGAIN iterates over candidate thresholds, adaptively sampling and estimating until the optimal threshold is found.
4. Query-Specific Variants
BARGAIN instantiates the above principles for each query type:
- BARGAINA (AT): Adaptive sampling with accuracy estimation; supports both single and per-class thresholds.
- BARGAINP (PT): Adaptive sampling with precision estimation; maximizes recall.
- BARGAINR (RT): Adaptive sampling with recall estimation; maximizes precision. For highly imbalanced datasets, BARGAINR introduces a positive density parameter β to relax guarantees in a controlled manner, as strict guarantees are impossible when positives are rare.
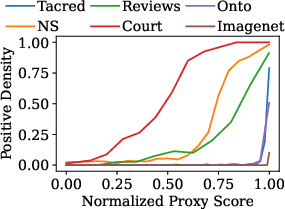
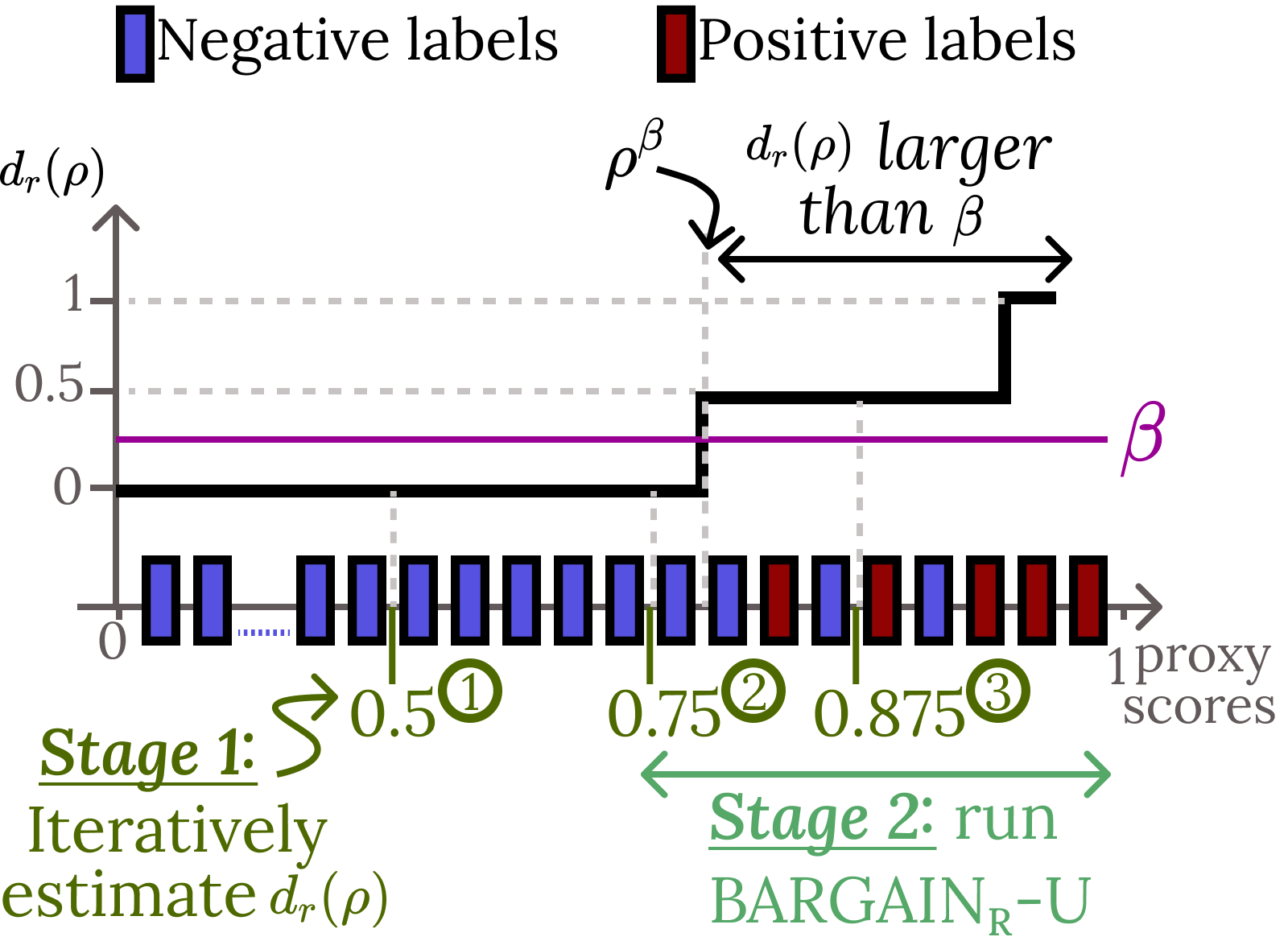
Figure 4: Positive density in real-world datasets. Most positives are concentrated at high proxy scores, motivating BARGAINR's density-based pre-filtering.
Theoretical Guarantees
BARGAIN provides non-asymptotic, finite-sample guarantees: For any user-specified δ, the probability that the selected threshold fails to meet the target is at most δ. This is achieved by:
- Using anytime-valid hypothesis tests for mean estimation [waudby2024estimating].
- Carefully accounting for multiple testing across thresholds via the tolerance parameter η and union bounds only where necessary.
- Ensuring that, for each threshold, estimation is performed on an i.i.d. sample from the relevant subset, even under adaptive sampling.
Empirical Evaluation
BARGAIN is evaluated on eight real-world datasets, including both LLM-based and classical ML tasks, and compared to SUPG and a Naive (Hoeffding-based) baseline. Key findings:
- AT Queries: BARGAIN reduces oracle usage by up to 86% more than SUPG, with both BARGAINA-A (single threshold) and BARGAINA-M (per-class thresholds) outperforming baselines.
- PT/RT Queries: BARGAINP-A and BARGAINR-A achieve up to 118% higher recall and 19% higher precision, respectively, than SUPG, especially on imbalanced datasets.
- Robustness: BARGAIN maintains guarantees under adversarial and noisy proxy score settings, whereas SUPG frequently fails to meet the target when δ is small or the data is adversarially constructed.
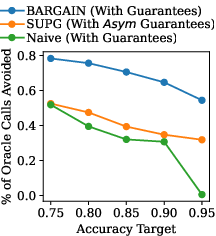
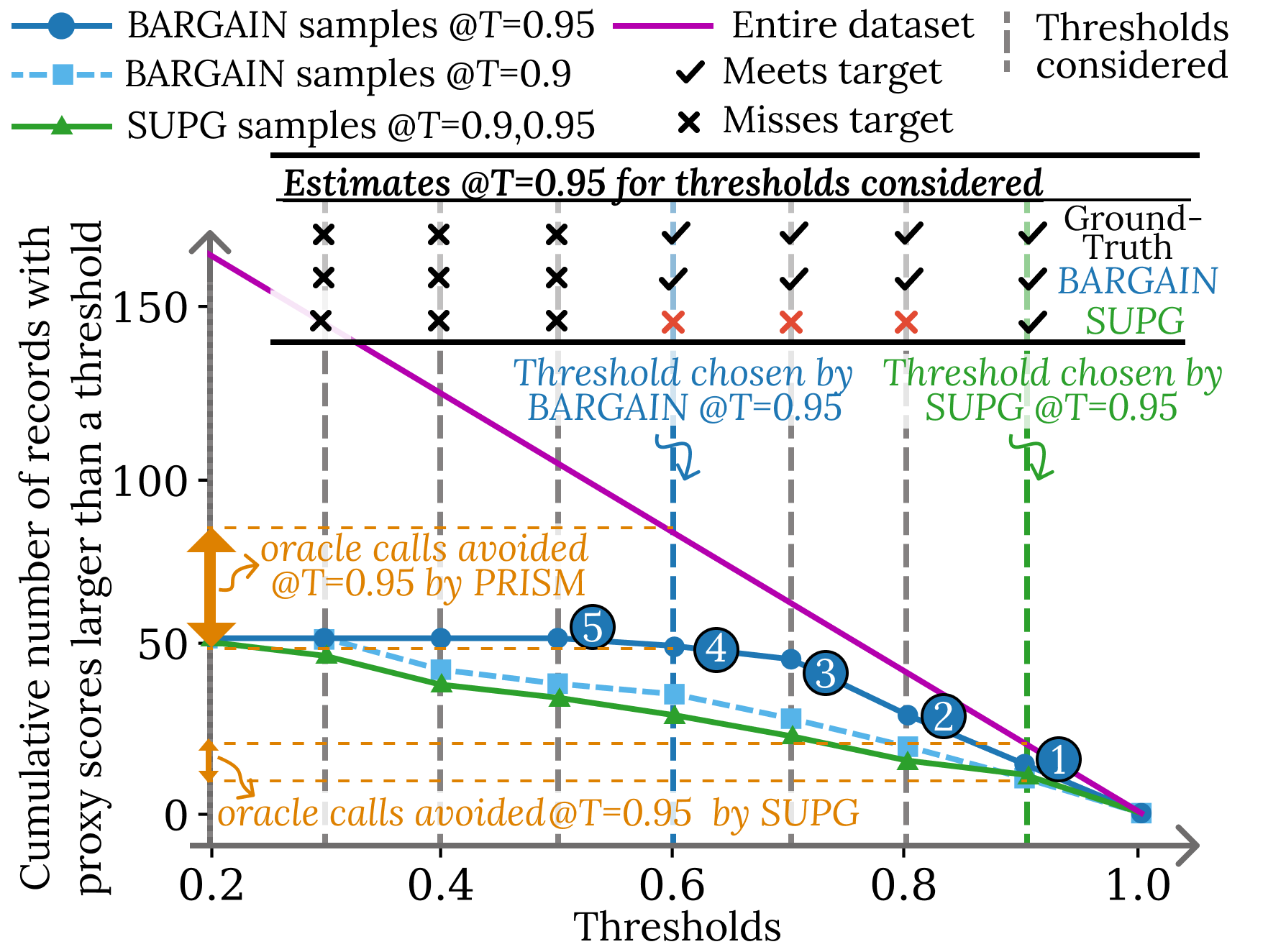
Figure 5: Summary of AT Query Results. BARGAIN achieves substantially higher cost savings than SUPG and Naive baselines.
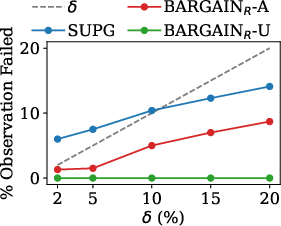
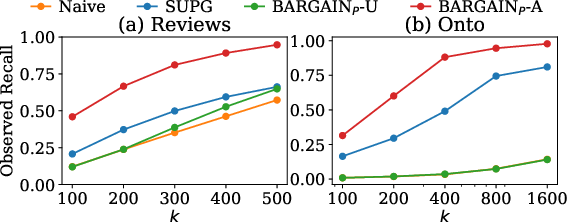
Figure 6: Meeting target in Onto Dataset. BARGAIN consistently meets the required target, while SUPG fails as δ decreases.
Implementation Considerations
Trade-offs and Limitations
- Strictness of Guarantees: BARGAIN's guarantees are non-asymptotic and hold for any finite sample size, in contrast to SUPG's asymptotic guarantees. However, for extremely imbalanced datasets (very low positive rates), strict recall guarantees are impossible without sacrificing utility; BARGAINR-A allows for controlled relaxation via β.
- Calibration Dependence: While BARGAIN's guarantees do not require well-calibrated proxy scores, utility is maximized when proxy confidence is well-aligned with true correctness. Poor calibration can reduce the fraction of records eligible for proxy processing.
- Extension to Open-Ended Tasks: The current framework is tailored to classification tasks; extending to open-ended generation or semantic joins requires further research on proxy score definition and estimation.
Practical Implications and Future Directions
BARGAIN provides a practical, theoretically sound solution for cost-efficient LLM-powered data processing in production systems, enabling substantial cost savings without sacrificing output quality. Its modular design allows integration into existing LLM orchestration and data management frameworks. Future work includes:
- Extending BARGAIN to open-ended tasks and entity matching, where proxy score calibration and transitivity properties may be leveraged for further optimization.
- Investigating adaptive candidate threshold selection and more sophisticated proxy routing in multi-model cascades.
- Exploring tighter integration with uncertainty calibration techniques [krishnan_improving_2020, kapoor2024calibration] to further improve utility.
Conclusion
BARGAIN advances the state of the art in LLM-powered data processing by combining adaptive, task-aware sampling with modern statistical estimation to deliver strong, non-asymptotic guarantees and superior empirical utility. Its principled approach addresses the limitations of prior work and provides a robust foundation for scalable, cost-effective deployment of LLMs in data-centric applications.