Safety Guarantees in Zero-Shot Reinforcement Learning for Cascade Dynamical Systems
Published 12 Apr 2026 in cs.AI | (2604.10429v1)
Abstract: This paper considers the problem of zero-shot safety guarantees for cascade dynamical systems. These are systems where a subset of the states (the inner states) affects the dynamics of the remaining states (the outer states) but not vice-versa. We define safety as remaining on a set deemed safe for all times with high probability. We propose to train a safe RL policy on a reduced-order model, which ignores the dynamics of the inner states, but it treats it as an action that influences the outer state. Thus, reducing the complexity of the training. When deployed in the full system the trained policy is combined with a low-level controller whose task is to track the reference provided by the RL policy. Our main theoretical contribution is a bound on the safe probability in the full-order system. In particular, we establish the interplay between the probability of remaining safe after the zero-shot deployment and the quality of the tracking of the inner states. We validate our theoretical findings on a quadrotor navigation task, demonstrating that the preservation of the safety guarantees is tied to the bandwidth and tracking capabilities of the low-level controller.
The paper establishes a framework that certifies zero-shot safety transfer for RL policies by quantifying how inner-loop tracking errors affect safety.
It utilizes a CMDP formulation with Lagrangian relaxation to optimize reduced-order models under safety constraints, ensuring probabilistic safety during deployment.
Empirical validation on a planar quadrotor demonstrates a clear link between increased tracking error and higher safety violation probability, confirming the theoretical bounds.
Safety Guarantees in Zero-Shot Reinforcement Learning for Cascade Dynamical Systems
Problem Formulation and Motivating Context
The paper addresses the challenge of providing formal probabilistic safety guarantees for policies derived via reinforcement learning (RL) on reduced-order models of high-dimensional cascade dynamical systems when those policies are deployed in the original, full-order system. Cascade systems—prevalent in robotics and control—feature an architecture in which "outer" task variables evolve based on "inner" states, but not vice versa (e.g., quadrotor translational dynamics are modulated by attitude variables, which can be actuated independently). The RL paradigm is leveraged to learn policies on reduced-order models where inner dynamics are collapsed into reference commands. Nevertheless, when these policies are transferred "zero-shot" to the original system, safety guarantees established during training often do not carry over due to unmodeled transfer effects, particularly inner-loop tracking errors.
This work provides a theoretically principled framework to analyze and guarantee safety properties of such transferred policies, integrating trajectory-level probabilistic safety with bounds on tracking error and reference trajectory properties.
Reduced-Order Policy Training under Safety Constraints
The approach begins with RL policy training in a reduced-order model that abstracts away the inner state dynamics and instead treats them as controllable references. To ensure safety, the RL policy, parameterized as π:S→Δ(A×X), is optimized via a CMDP formulation:
πR⋆=argπmaxJrR(π)s.t.JcR(π)≤δ,
where JrR and JcR represent the expected reward and expected cumulative safety cost, respectively, over finite horizon T. Safety cost is defined as the expected number of violations of the system's safe set.
Practical policy optimization is conducted through Lagrangian relaxation, producing an RL objective modified by a dynamically updated dual variable. The resulting policy is certified to satisfy the safety constraint in the reduced-order training MDP.
Transfer to the Full-Order System and Main Theoretical Guarantee
The core challenge investigated is quantitative transfer of safety: when πR⋆, trained with high-probability safety on a reduced-order model, is deployed with a hierarchical two-layer architecture (RL-based reference generator plus inner-loop controller), under what conditions are safety guarantees preserved?
The inner-loop controllerK is assumed ISS (input-to-state stable in expectation), enabling the derivation of a bound on the one-step total variation (TV) distance between the transition kernels of the actual closed-loop system and the reduced-order model. This discrepancy is shown to depend on:
Tracking error: Exponential decay term and cumulative variation of the inner reference.
Boundedness and regularity of the reference trajectory generated by the policy.
Lipschitz regularity of the reduced model's transition in the reference argument.
The main safety result provides a finite-horizon lower bound for the probability that the deployed trajectory remains in the safe set:
PK(t=0⋂T{St∈Ssafe}πR⋆)≥1−δ−1−αL(e0+βD)
where L is the model-dependent Lipschitz constant, α,β encode inner-loop tracking error decay and input sensitivity, πR⋆=argπmaxJrR(π)s.t.JcR(π)≤δ,0 is the initial tracking error, and πR⋆=argπmaxJrR(π)s.t.JcR(π)≤δ,1 bounds cumulative variation of the reference. Degradation in safety is strictly dictated by inner-loop tracking performance and reference variability. Thus, safe transfer can be ensured by calibrating training constraints and controller design to dominate these terms.
Analytical Techniques
The proof strategy leverages:
Recursive unrolling of TV distance between reduced and transferred systems over finite trajectories.
Use of trajectory-level union bounds to go from expectation constraints to high-probability safety.
Exploitation of cascade structure assumptions for tractable analysis, particularly matching of outer transition probability when tracking is perfect.
Lipschitz regularity to relate tracking error to induced TV distance.
By combining these, the methodology extends classical CMDP guarantees to hierarchical (cascaded) architectures, supporting simulation-to-real transfers with inner-outer controller decoupling.
Empirical Validation
A planar quadrotor navigation task is used for empirical validation. Policies are trained to maximize reward while maintaining a prescribed safety probability in a reduced-order translational model (positions/velocities as states, with pitch angle command as input/reference). Deployment on a full-order system is then realized by tracking the commanded pitch via a PD controller.
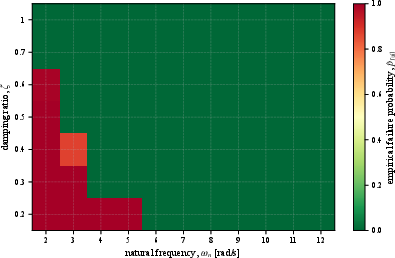
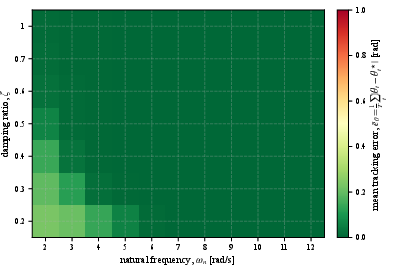
Strong correlation between mean attitude tracking error and empirical safety violation probability is demonstrated over a grid of inner-loop controller gains. Empirical failure probability and mean attitude tracking error both sharply increase with degrading inner controller bandwidth or damping, validating the theoretical link between tracking performance and safety transfer.
Figure 1: Empirical failure probability πR⋆=argπmaxJrR(π)s.t.JcR(π)≤δ,2 maps in πR⋆=argπmaxJrR(π)s.t.JcR(π)≤δ,3 controller parameter space; failures occur only when inner-loop bandwidth and damping are insufficient.
Figure 2: Mean attitude tracking error πR⋆=argπmaxJrR(π)s.t.JcR(π)≤δ,4 across the same controller grid, showing direct correspondence with unsafe regions observed in Figure 1.
Implications and Prospects
Theoretical Implications
This framework quantifies the safety transfer gap for cascade systems—previous literature either considered robust performance bounds or deterministic disturbance tubes, but did not deliver trajectory-level safety certificates with explicit dependency on tracking performance.
Safety-preserving design can now be approached analytically: safety constraints in reduced-order training and controller design can be tightened to explicitly offset deployment risks.
The structure enables modular RL: outer-loop policies can be synthesized on simplified models provided the inner loop can be rigorously specified via ISS-type conditions.
Practical Consequences
Safety in hierarchical RL architectures can be certified for hardware deployment in robotics, aerospace, and general safety-critical domains.
The explicit formalism supports policy transfer pipelines (simulation-to-real, abstraction-to-implementation) without empirical "trust region" heuristics for safety.
Limitations for practical deployment include accurate estimation of constants (πR⋆=argπmaxJrR(π)s.t.JcR(π)≤δ,5, πR⋆=argπmaxJrR(π)s.t.JcR(π)≤δ,6, πR⋆=argπmaxJrR(π)s.t.JcR(π)≤δ,7, πR⋆=argπmaxJrR(π)s.t.JcR(π)≤δ,8), and bounding reference signal variation in closed-loop operation.
Directions for Future Research
Bounding reference variation: While initial theoretical bounds account for the total variation of the reference, in practice, the closed-loop policy/controller interactions may lead to unexpectedly high reference excitation. Designing policies with explicit reference regularization or architectural properties remains necessary.
Generalization to non-cascade or more general partial feedback systems: Extending the described safety transfer machinery to more interconnected or underactuated architectures.
Policy architectures with integrated reference smoothing: Joint training of RL policies with inner-loop-aware regularizers or constraints may enhance transfer safety guarantees.
Integration with sim-to-real domain randomization and uncertainty estimation techniques: The presented framework could serve as a reliability audit atop such approaches.
Conclusion
This paper establishes a rigorous methodology for certified zero-shot safety transfer in RL-based control for cascade systems. By bridging constrained RL with contraction-based tracking analysis, verifiable safety guarantees are produced that quantitatively depend on inner loop tracking precision and reference trajectory variability. Empirical evidence on a quadrotor platform supports these findings, confirming the utility of inner-loop-aware safety certificates for safe RL deployment. This advances the agenda for modular, reliable, and deployable RL in safety-critical, high-dimensional control settings.
References
For more detailed discussion of related transfer frameworks and reinforcement learning safety, see also [11107987], [9718160], (2604.10429).