- The paper introduces a unified architecture that interleaves single-model inference with role-prompted multi-agent deliberation.
- It employs online threshold optimization to dynamically route ambiguous queries and achieve superior cost-accuracy tradeoffs.
- Experiments show CascadeDebate outperforms baselines, improving accuracy by up to 18-26% on challenging medical and scientific tasks.
Multi-Agent Deliberation for Cost-Aware LLM Cascades: A Detailed Analysis of CascadeDebate
Introduction
CascadeDebate introduces a unified architecture for LLM deployment that fuses multi-agent deliberation with the established model cascade paradigm. In contrast to cascaded systems that employ a sequence of single-model stages routed by confidence, this work identifies a critical inefficiency: ambiguous queries that surpass the base model's confidence threshold are prematurely escalated to costlier models or even to human experts without intra-tier resolution, leading to overuse of computational resources. CascadeDebate attacks this failure mode by incorporating multi-agent deliberation at escalation boundaries. The architecture alternates between single-model inference and lightweight agent ensembles, invoking multi-agent consensus only for uncertain cases. This confidence-driven activation enables efficient internal resolution of ambiguity, reserving expensive compute for genuinely hard cases and yielding strong cost-accuracy Pareto tradeoffs.
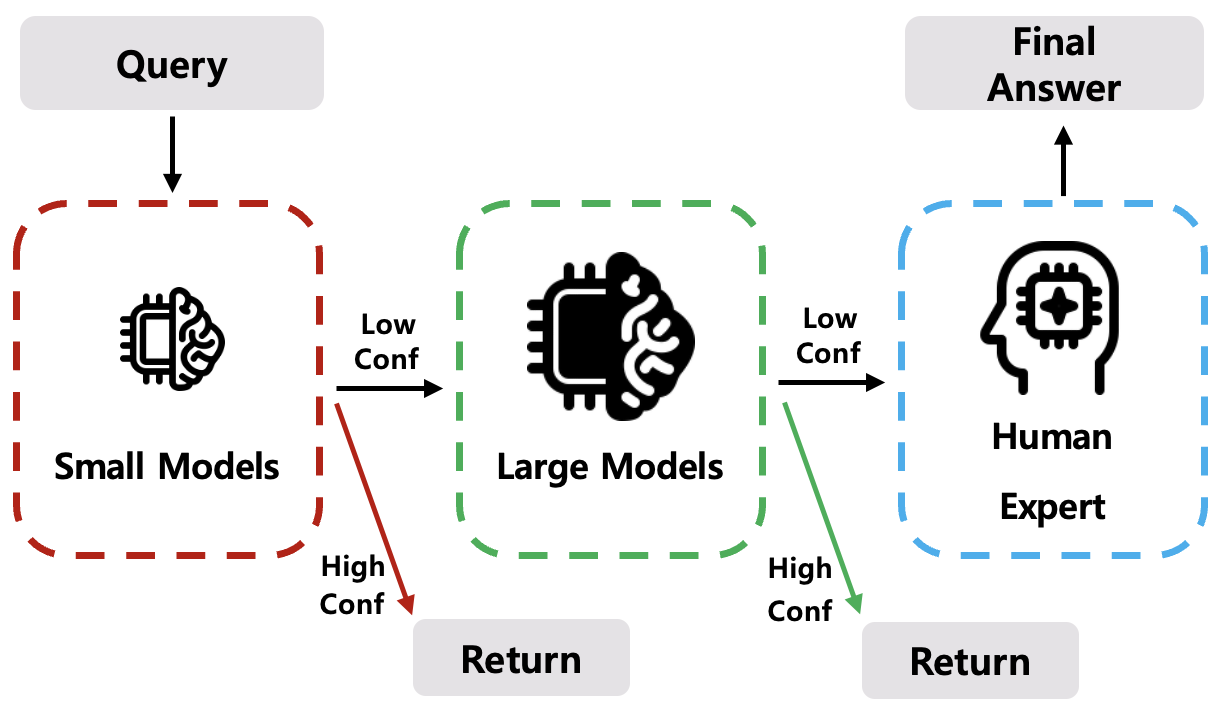
Figure 1: Overview of the adaptive cascade framework—queries advance through a model hierarchy, escalating only when uncertainty persists.
CascadeDebate Architecture
The architecture is instantiated as an alternating sequence: single-model inference (Ssingle), followed by multi-agent deliberation (Smulti) using several role-prompted agent instances per model scale, capped by human experts as ultimate fallback. At each escalation boundary, confidence-based routers dynamically activate agent ensembles for marginal cases, enabling consensus-driven ambiguity resolution.
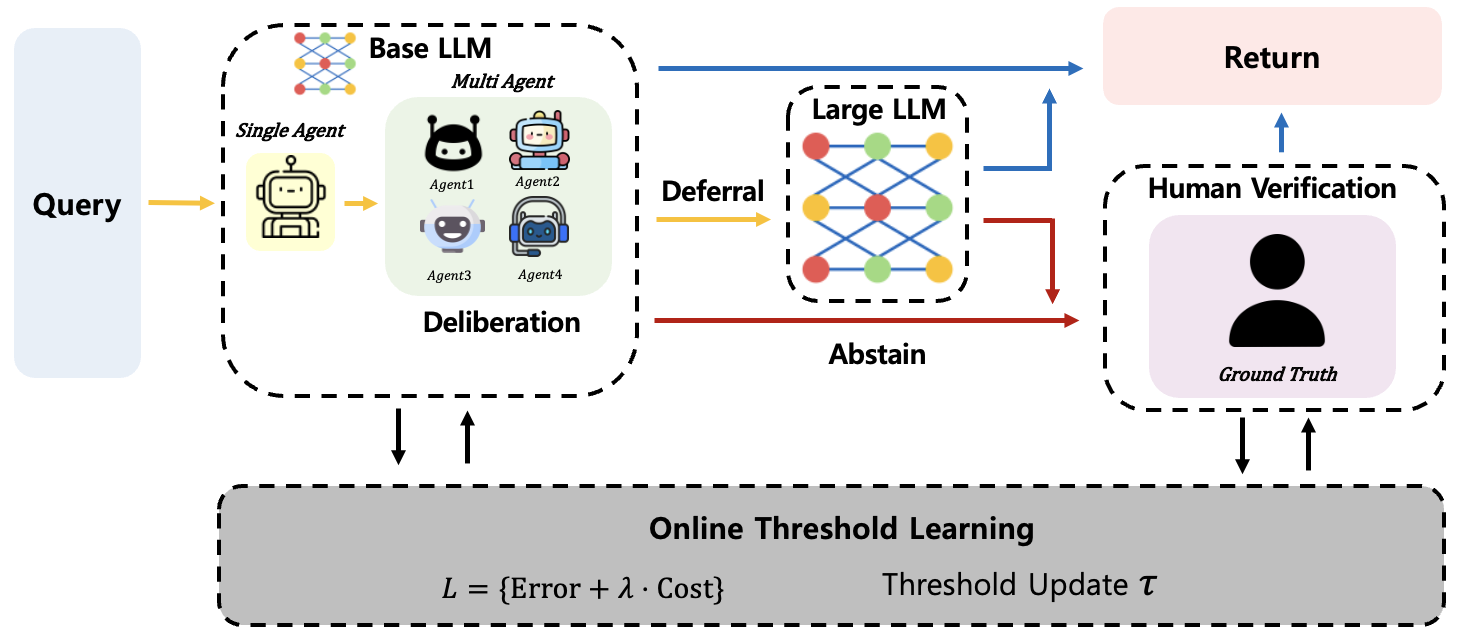
Figure 2: The CascadeDebate architecture interleaves single-model inference with selective multi-agent deliberation at each escalation boundary; online threshold optimization ensures elastically adaptive routing.
Key to the framework is the online threshold optimizer, continuously adapting deferral boundaries τ based on streaming human feedback. Thresholds are parameterized and updated via soft relaxation and Bayesian-calibrated confidence metrics, enabling gradient-based mini-batch training post-deployment.
The design guarantees test-time compute elasticity—trivial queries are routed quickly via single models, while only ambiguous cases incur additional deliberative computation, with inter-tier escalation strictly contingent on internal agent consensus failure.
Experimental Results
Extensive benchmarking was performed on five representative multiple-choice datasets—ARC-Easy, ARC-Challenge, MMLU, MedQA, and MedMCQA. Both Llama-3.2 and Qwen2.5 instruction-tuned models served as backbone, with two model scales per framework. The base and large models were paired in order to maximize the granularity of cost-accuracy allocation. Each agent ensemble comprised four role-prompted LLMs, contributing to robust majority-vote aggregation.
CascadeDebate systematically outperformed all baselines—including the strongest single-scale multi-agent systems and standard two-stage cascades—across all tasks (see Table 1 in the source). Improvements against the best baseline ranged up to +18.24 percentage points on Llama-3.2 (MedQA task; 86.44% versus 68.20%) and up to +26.75% in relative terms over single-cascade policies. On challenging medical and scientific reasoning tasks, the accuracy differential was most pronounced, confirming that internal debate is most beneficial precisely where ambiguity is prevalent.
Cost-accuracy curves demonstrate that CascadeDebate not only achieves higher accuracy but does so at considerably reduced computational cost relative to "always-on" multi-agent or large-model policies. The system dominates the Pareto frontier, with online learned thresholds consistently outperforming fixed thresholds.
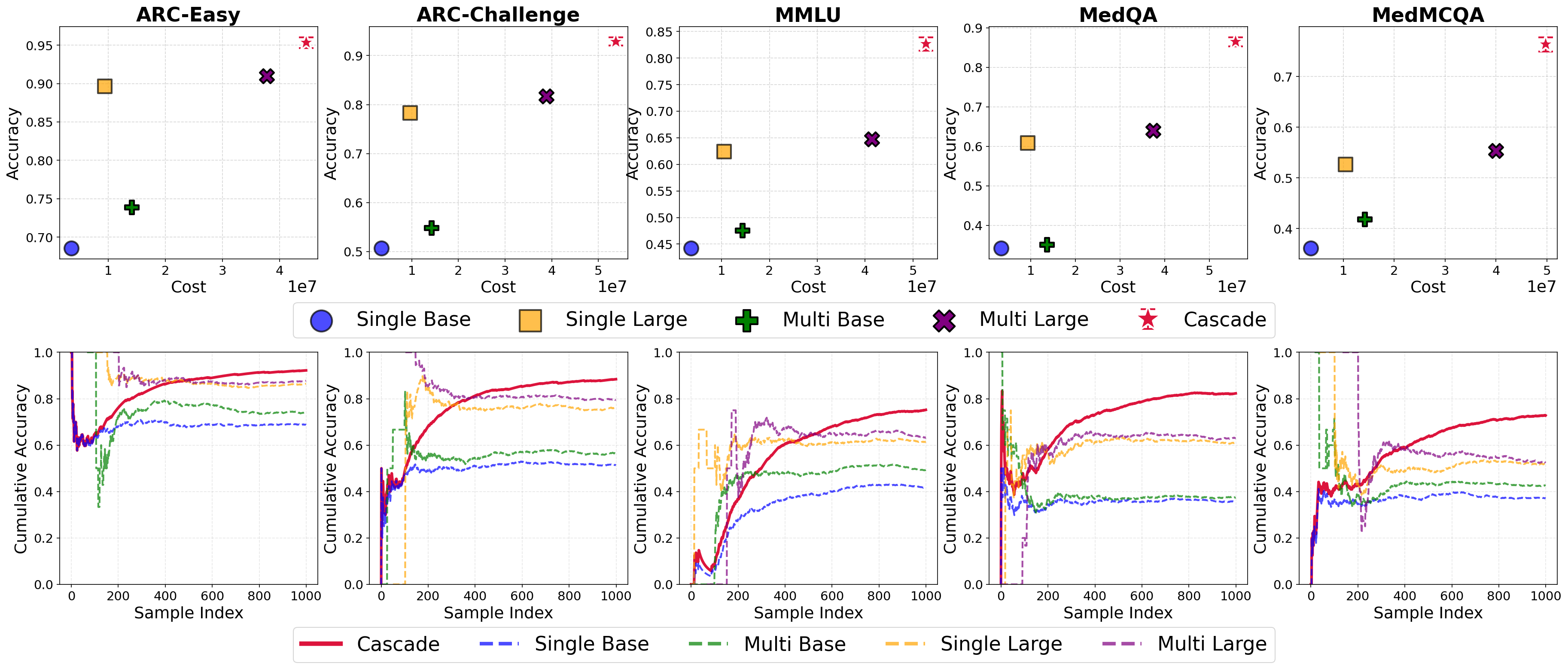
Figure 3: CascadeDebate (red star) dominates the cost-accuracy Pareto frontier across all benchmarks; online threshold adaptation induces rapid task-specific performance gains over fixed policies.
Robustness and Generalizability
The superiority of CascadeDebate and its online learned thresholds was not limited to the Llama backbone. On Qwen2.5, the same architecture and optimization strategy replicated performance gains, and the system reliably achieved optimal Pareto frontier positioning on every benchmark. These results generalize the paradigm's effectiveness across architectural families and domain complexities.
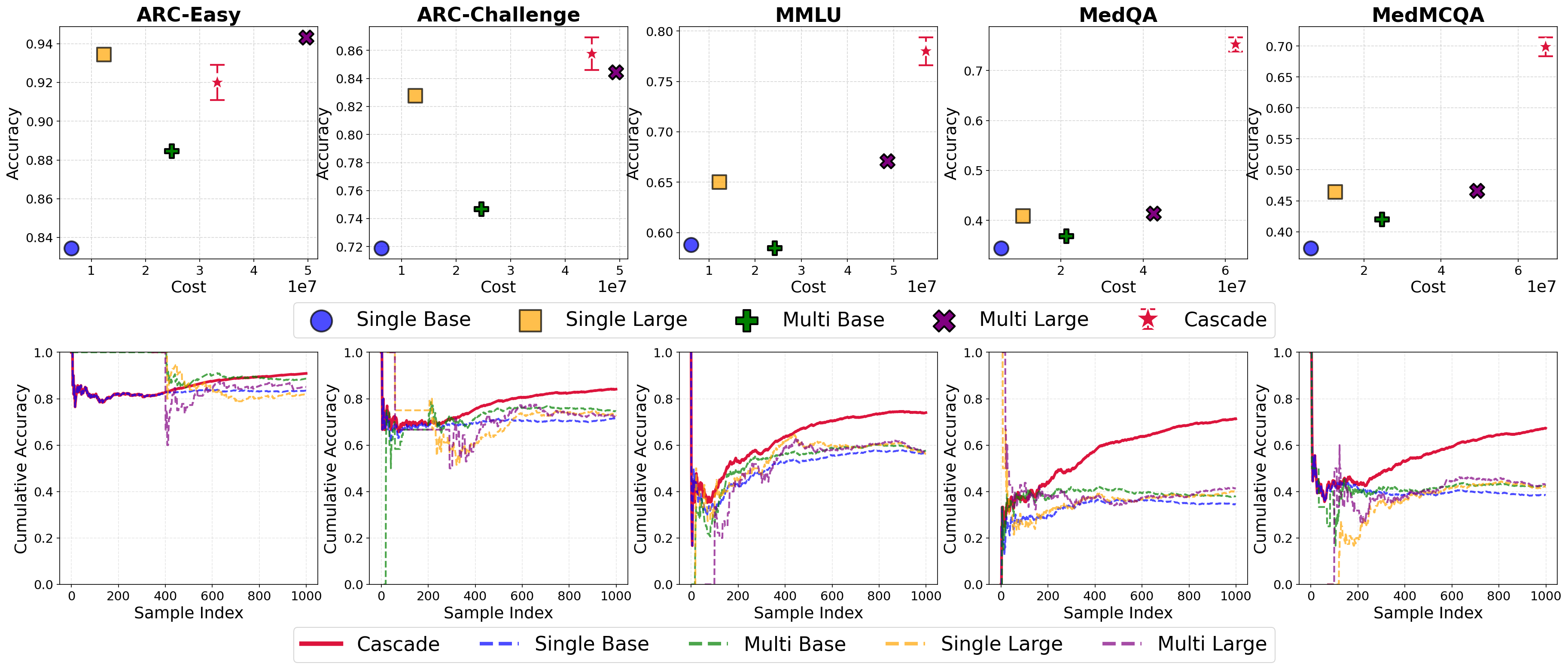
Figure 4: Pareto-optimality and online adaptation persist when ported to Qwen2.5—robust and backbone-agnostic cost-accuracy gains.
Ablations: The Effect of Online Threshold Learning
Static, manually-tuned deferral thresholds perform notably worse than online-adapted ones. Analysis revealed rigid resource allocation under fixed thresholds, resulting in unnecessary escalation for easy queries and underutilization of deliberative power on hard queries. Online learned thresholds improved accuracy by 16–26 percentage points, confirming that threshold adaptation is essential for real-world deployment across heterogeneous domains.
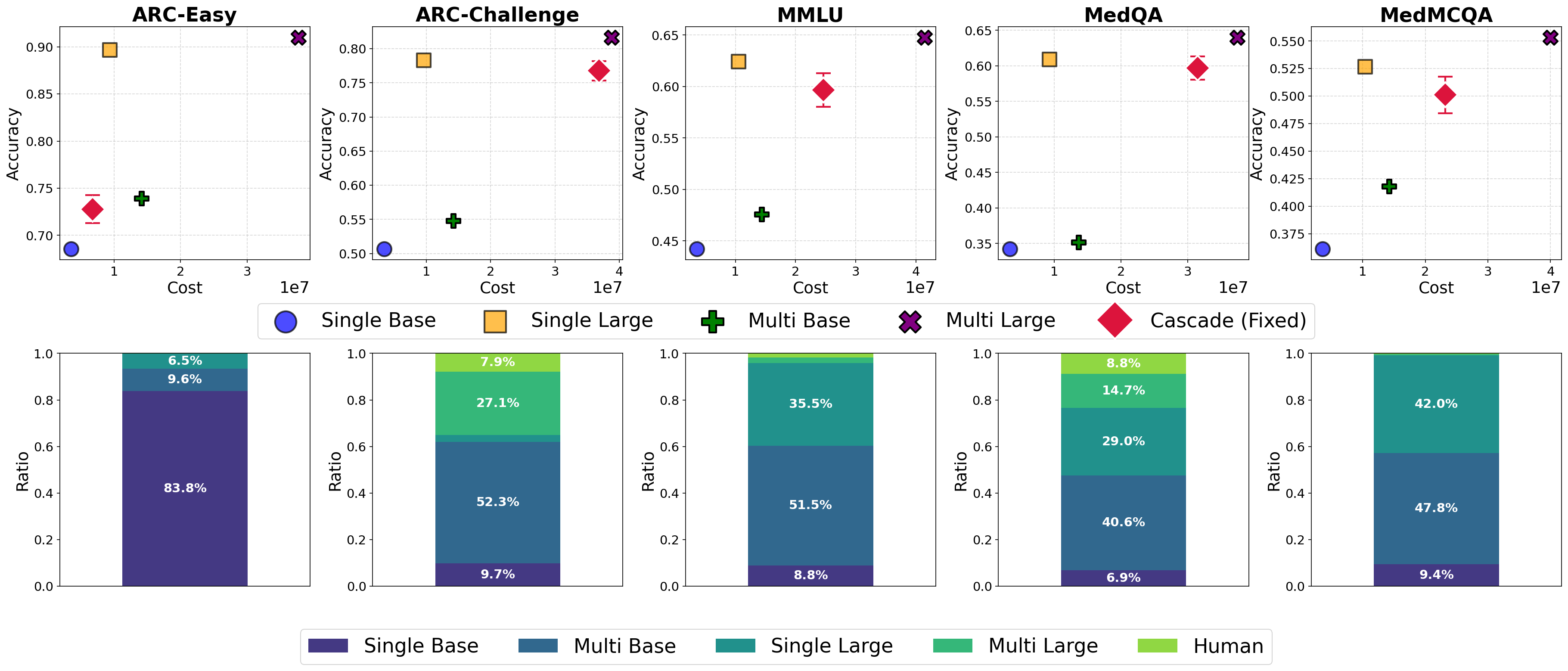
Figure 5: Fixed-threshold baselines yield suboptimal cost-accuracy tradeoffs and inefficient resource allocation compared to the online strategy.
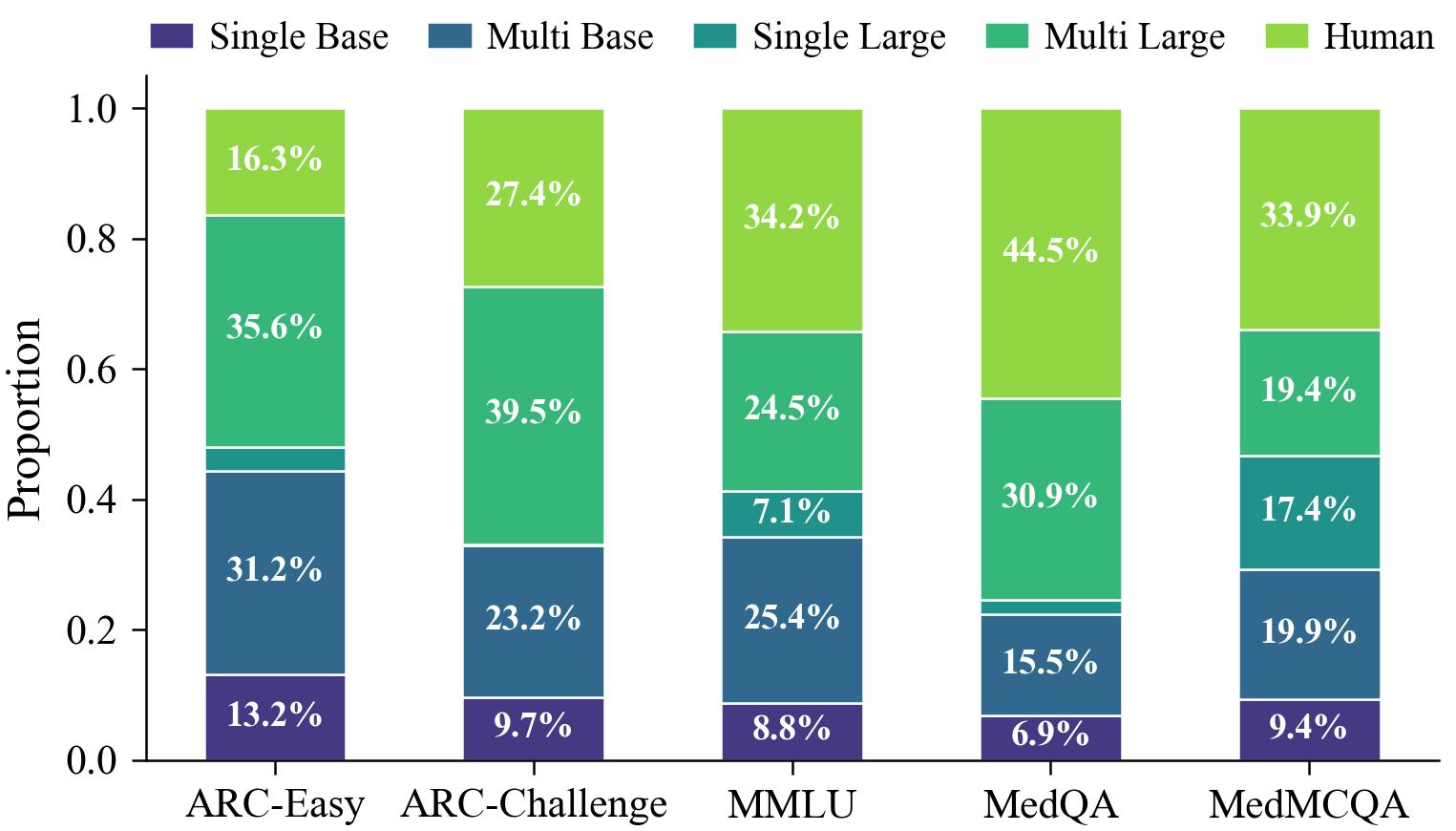
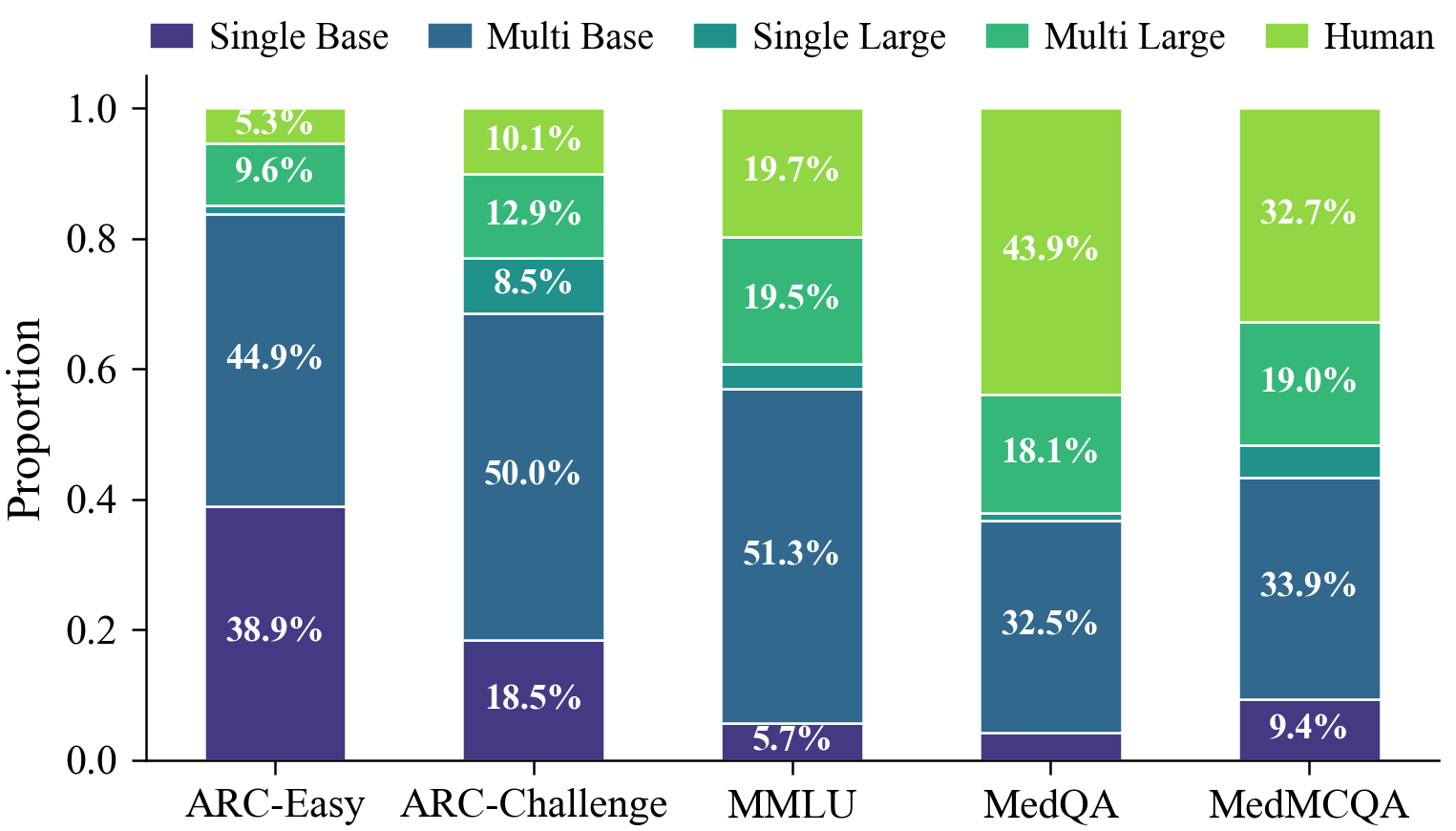
Figure 6: Stage-wise sample termination distribution: adaptive thresholds concentrate computation only as required by task difficulty, with most queries resolved efficiently in earlier stages on easy benchmarks.
Mechanistic Insights and Implications
The architecture leverages inference-time compute in a manner that challenges traditional scaling law orthodoxy. Rather than parameter count alone, selective compute allocation via targeted multi-agent deliberation allows compact models to surpass larger standalone architectures by significant margins.
This formulation establishes a cost-effective blueprint for the deployment of LLMs in production, enabling high-throughput applications to process routine queries parsimoniously while escalating only ambiguous cases to stronger models or expert review. The approach supports robust human-AI collaboration pipelines and realizes elastic, human-like cognitive effort allocation in practical AI systems.
Limitations
The sequential nature of the cascade introduces latency, particularly in complex multi-stage deployments. Premature acceptance due to overconfident but miscalibrated base models can propagate errors, and the reliance on role-prompting for diversity limits ensemble heterogeneity.
Conclusion
CascadeDebate advances the state-of-the-art in cost-aware LLM inference by interposing multi-agent deliberation at cascade escalation boundaries. The alternating single/multi-agent architecture, governed by online threshold optimization, yields superior cost-accuracy tradeoffs and human-like computational elasticity. These mechanisms substantially close the gap between efficient base models and high-capacity solvers, suggesting a practical path forward for scalable, robust, and adaptive AI services. Future directions include parallelizing deliberation, enhancing agent diversity, and extending the framework to open-ended, long-context reasoning tasks.