Geometric Context Transformer for Streaming 3D Reconstruction
Abstract: Streaming 3D reconstruction aims to recover 3D information, such as camera poses and point clouds, from a video stream, which necessitates geometric accuracy, temporal consistency, and computational efficiency. Motivated by the principles of Simultaneous Localization and Mapping (SLAM), we introduce LingBot-Map, a feed-forward 3D foundation model for reconstructing scenes from streaming data, built upon a geometric context transformer (GCT) architecture. A defining aspect of LingBot-Map lies in its carefully designed attention mechanism, which integrates an anchor context, a pose-reference window, and a trajectory memory to address coordinate grounding, dense geometric cues, and long-range drift correction, respectively. This design keeps the streaming state compact while retaining rich geometric context, enabling stable efficient inference at around 20 FPS on 518 x 378 resolution inputs over long sequences exceeding 10,000 frames. Extensive evaluations across a variety of benchmarks demonstrate that our approach achieves superior performance compared to both existing streaming and iterative optimization-based approaches.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper presents a new way for a computer to build a 3D map of the world while watching a live video, like a robot’s camera feed. The method is called the Geometric Context Transformer (GCT). Its goal is to figure out, on the fly, where the camera is (its position and direction) and what the scene looks like in 3D, quickly and accurately, even for very long videos.
What questions did the researchers ask?
The researchers focused on a simple idea: can we make a system that:
- Works like a careful traveler—keeping just the most useful memories from a video—to build a 3D map continuously and fast?
- Stays accurate over very long videos (thousands of frames) without getting “lost” or drifting off the correct path?
- Runs in real time (around 20 frames per second) without using too much memory or needing slow, repeated optimization steps?
How does their method work (in everyday terms)?
To explain the approach, imagine you’re walking through a building while making a map. You can’t remember everything, so you keep three kinds of notes that help you stay oriented, add details, and correct mistakes:
The three kinds of “memory” the model keeps
- Anchor frames: These are like fixed landmarks you set at the start—think “the front door” or “the first hallway.” They help set your overall scale and coordinate system so you know what “one meter” means and where “north” is.
- Local window (recent frames): This is your short-term memory—what you just saw in the last few steps. It gives you lots of detail and overlap with the new view, which helps you place the next camera position precisely and estimate depth (how far things are).
- Trajectory memory (compact history): This is a lightweight travel diary—very short notes for every past step. It doesn’t store lots of image detail, but it keeps enough information to remind you where you’ve been so you can correct slow, long-term drift.
Together, these three context types give the model a strong sense of “where am I now,” “what’s nearby,” and “where have I been,” without having to remember everything.
What is a “transformer” and “attention” here?
A transformer is a type of AI model that can focus on the most relevant information. Attention is like a spotlight: instead of looking at all past frames equally, the model learns what to focus on—the landmarks, the recent views, and the compact history—to make the best guess of the camera’s pose and the scene’s depth.
Why is this design efficient?
- Most of the heavy, detailed information is kept only for a few anchor and recent frames.
- Older frames are summarized into just a few tiny “tokens” (short notes), so memory use grows very slowly even as the video gets very long.
- This keeps the per-frame cost nearly constant, which is why it runs in real time.
How it’s trained and run
- Progressive training: The model first learns on short clips, then gradually handles longer and longer sequences—like practicing small puzzles before tackling big ones.
- Relative comparisons: It learns not just absolute positions, but also how frames relate to each other locally, which improves stability.
- Real-time tricks: The system uses optimized code to store and reuse intermediate computations (like a neat notebook), making it faster (around 20 frames per second at 518×378 resolution).
Two ways to use it
- Direct mode: Processes the whole sequence straight through—best accuracy if the video isn’t extremely long.
- VO (Visual Odometry) mode: Breaks very long videos into overlapping chunks and stitches them together—lets it handle arbitrarily long sequences, with a small extra alignment error at each chunk boundary.
What did they find?
Their experiments show several important results:
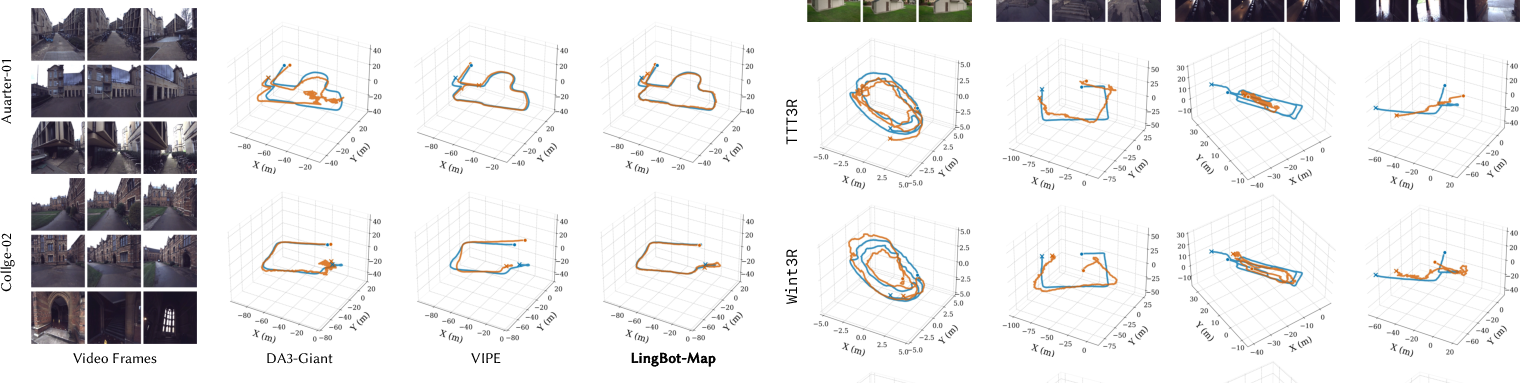
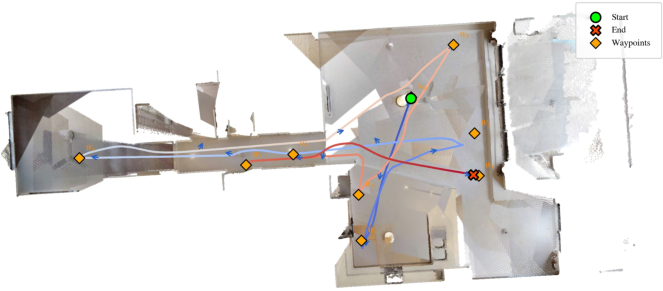
- Accuracy: The method achieves better camera tracking and 3D reconstruction than other streaming approaches, and even beats some offline methods that can see the whole video at once.
- Stability on long videos: It stays consistent over very long sequences (10,000+ frames) thanks to its smart “memory” design that avoids accumulating drift.
- Speed and efficiency: It runs at about 20 frames per second at a moderate resolution (518×378), with nearly constant memory use per frame.
- Broad testing: It performed well on many well-known datasets (Oxford Spires, 7-Scenes, Tanks and Temples, ETH3D, and others), covering both indoor and outdoor scenes.
Why this matters: It shows you can get the best of both worlds—speed and accuracy—by keeping just the right context instead of everything.
Why is this important?
- Robots, drones, and AR/VR devices need to understand their surroundings live, not hours later. This method helps them map spaces and know where they are in real time.
- Because it’s fast and doesn’t need slow, repeated optimization or test-time retraining, it’s practical for real-world use—like navigation, scanning rooms, or exploring large outdoor areas.
- The idea of keeping three types of learned context (anchors, local window, compact history) can inspire other streaming AI systems that need to be both smart and efficient.
Takeaway
The Geometric Context Transformer (GCT) is a clever, real-time system for building 3D maps from video. It works by remembering just the most useful things: a few fixed landmarks, a short recent history for detailed matching, and a compact memory of the whole journey to prevent drift. This balance lets it stay accurate, fast, and stable—even on very long videos—making it a strong step forward for robots and devices that need to see and move through the world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research.
- Absolute scale recovery at inference: The method relies on “anchor frames” for scale/coordinate grounding, but the mechanism to obtain metric scale without external cues (e.g., IMU/LiDAR/GNSS) is unclear. Quantify scale drift in long runs and evaluate strategies for metric scale recovery in purely monocular streaming.
- Anchor-frame strategy robustness: Anchors are the first n frames by design (not learned). Assess failure cases when initial frames are texture-poor, poorly exposed, or dynamic; explore learned/quality-aware anchor selection, re-anchoring, or anchor updates mid-stream.
- Lack of explicit loop closure: Long-range consistency depends on compressed “trajectory memory,” with no explicit place recognition or loop-closure constraints. Evaluate revisits and long loops, and investigate integrating learned place recognition and loop-closure attention within GCA.
- Trajectory memory capacity: The 6-token-per-frame compression may under-represent complex or diverse scenes over very long sequences. Ablate token budgets/structures, study information bottlenecks on loops/relocalization, and explore learned retrieval of richer tokens on demand.
- Window overlap failure modes: Performance when the new frame has low overlap with the local sliding window (e.g., fast motion, dropped frames, abrupt revisits) is not analyzed. Explore adaptive window sizing, view selection, or non-local retrieval to maintain robustness under sparse overlap.
- Keyframe selection is heuristic: The flow-magnitude threshold for adding keyframes to the cache is fixed and not learned; sensitivity and optimality are not studied. Test uncertainty-aware, learned, or task-driven keyframe policies and their effect on accuracy/throughput.
- Long-sequence scaling beyond ~3k frames: Direct mode degrades beyond ~3,000 frames; VO mode introduces Sim(3)-alignment drift at window boundaries. Quantify drift over 10k+ frames, analyze window overlap/size trade-offs, and explore learned cross-window constraints to reduce boundary errors.
- Dynamic scenes and non-rigid motion: The approach assumes static geometry; no motion segmentation or handling of moving objects is included. Evaluate on dynamic benchmarks and develop modules for rigid/non-rigid motion modeling in streaming.
- Camera model assumptions: Handling of unknown/varying intrinsics, distortion, and rolling-shutter effects is not detailed. Assess sensitivity to calibration errors, support per-frame intrinsics (zoom, autofocus), and incorporate rolling-shutter compensation.
- Online mapping/fusion design: The system outputs per-frame depths and poses but does not define a streaming global map representation (e.g., TSDF, mesh, splats) or map management (fusion, pruning, consistency). Specify and evaluate an incremental mapping pipeline with memory and consistency controls.
- Uncertainty-aware reasoning: Depth uncertainty is predicted, but it is not used for attention weighting, keyframe decisions, or drift correction; pose uncertainty is not modeled. Incorporate uncertainty into attention, context selection, and VO alignment.
- Training length vs. generalization: The model is trained on up to 320 views but used on sequences ~10× longer in Direct mode. Systematically study how training sequence length affects long-horizon stability and derive curricula or regularizers that extend the effective range.
- Hyperparameter sensitivity: The effects of anchor count n, window size k, trajectory token count, and keyframe interval m on accuracy, drift, memory, and FPS are not ablated. Provide guidelines and automatic tuning strategies for deployment.
- Domain robustness and adverse conditions: While datasets are diverse, robustness to challenging real-world conditions (night, rain, fog, glare), extreme texturelessness/repetitive patterns, and severe motion blur is not reported. Perform stress tests and domain adaptation studies.
- Resolution and compute scaling: Performance is reported at 518×378 and ~20 FPS; accuracy/latency at higher resolutions and across hardware profiles (desktop vs. edge) are not investigated. Establish scaling laws, memory curves, and potential quantization/pruning strategies.
- Resource footprint and deployability: Parameter count, KV-cache memory growth for ultra-long runs, and power usage are not disclosed. Profile and optimize for embedded/robotics platforms, including mixed-precision, low-rank adapters, or sparsity.
- Relocalization after resets: Handling of camera restarts, hard scene transitions, or multi-scene streams (re-initialization, re-anchoring, state carryover) is not specified. Define and evaluate robust re-initialization and re-localization protocols.
- Retrieval-augmented context: No mechanism retrieves distant but relevant frames (e.g., revisits) into the attention context. Investigate visual place recognition–guided retrieval for anchors or window augmentation without quadratic cost.
- Temporal encoding choices: The specific temporal positional encodings and their impact on drift and long-horizon stability are not ablated. Compare alternative encodings (relative, rotary, neural PE) and their interaction with trajectory memory.
- Integration with auxiliary sensors: Fusion with IMU, wheel odometry, GNSS, or altimeters is not explored. Evaluate multi-sensor GCA variants to stabilize scale and reduce drift in real-world robotics.
- Evaluation completeness and fairness: It is unclear whether all streaming baselines use identical keyframe policies or cache constraints. Standardize long-sequence protocols (resets, keyframes, VO alignment) to enable fair comparison.
- Reproducibility details: Key loss coefficients (λ weights), exact loss formulas (some are referenced but not fully specified), and several implementation hyperparameters are missing or ambiguous. Release precise configs/values to ensure replicability.
- Failure analysis and diagnostics: The paper lacks systematic failure cases (e.g., where drift spikes, which scenes break, sensitivity to motion types). Provide diagnostics and benchmarks for characteristic failure modes to guide future improvements.
- Multi-camera/stereo extensions: The approach is monocular; extensions to synchronized multi-camera or stereo rigs (to resolve scale and improve robustness) are not explored. Design and evaluate multi-view streaming variants within the GCA framework.
- Theoretical underpinnings: No analysis bounds the drift/error growth under the proposed compressed memory and attention mask. Develop theoretical or empirical guarantees relating token budgets and attention structure to stability.
Practical Applications
Overview
This paper introduces a feed‑forward, streaming 3D reconstruction model built on a Geometric Context Transformer with Geometric Context Attention (GCA). The model processes video causally to estimate camera poses and depth/point clouds in real time (~20 FPS at 518×378), with nearly constant memory per frame, by maintaining three learned context types: an anchor context (coordinate/scale grounding), a local pose‑reference window (dense local geometry), and a trajectory memory (compact long‑range drift correction). It supports two inference modes: Direct Output (best accuracy for ~up to 3,000 frames with keyframes) and Visual Odometry (VO) mode (arbitrarily long sequences via windowed Sim(3) alignment). Below are practical applications and workflows drawing on these capabilities.
Immediate Applications
- Robotics and Drones (Autonomy, Logistics, Inspection)
- Use cases: On‑board visual odometry and dense mapping for mobile robots/UAVs in warehouses, factories, agriculture, and infrastructure inspection; fallback/redundant localization when GPS is unreliable.
- Tools/products/workflows: ROS2 node that wraps Direct Output mode for short to mid sequences and VO mode for long flights; integration with PX4/ArduPilot; export to ROS map/point cloud topics; fusion with IMU/GNSS in an EKF.
- Dependencies/assumptions: Monocular RGB input (scale anchored via initial frames or a known reference); modest GPU (or edge accelerator) for ~20 FPS at 518×378; dynamic scenes and motion blur can degrade accuracy; safety‑critical use requires additional safeguards and sensor fusion.
- AR/VR and Mobile Computing (Software, Consumer Electronics)
- Use cases: Real‑time room mapping for occlusion and physics, spatial anchors, and occlusion in AR apps on devices without depth sensors; live 3D reconstruction for telepresence and VR previsualization.
- Tools/products/workflows: Mobile SDK or Unity/Unreal plug‑in offering depth+pose from live video; WebRTC pipeline with paged KV-cache; cloud offload option for low‑end devices.
- Dependencies/assumptions: Energy/thermal limits on mobile—may need lower resolution, frame skipping, or server inference; privacy controls for 3D data; initial anchor frames or marker for scale.
- AEC and Facility Management (Construction, Real Estate)
- Use cases: Rapid as‑built capture from walkthrough video; incremental updates to BIM; jobsite progress tracking; generating metrically consistent point clouds and camera trajectories without offline SfM.
- Tools/products/workflows: Field app that runs VO mode for long walkthroughs with periodic anchor resets; automated export to E57/PLY and camera tracks; QA dashboards for drift monitoring.
- Dependencies/assumptions: Scale needs anchoring (e.g., measured markers or known distances); lighting and texture help reconstruction; validation against control measurements for compliance.
- Infrastructure and Asset Inspection (Energy, Transportation)
- Use cases: Utility line, bridge, and rail inspections from video with near‑real‑time 3D; drift‑controlled VO windows for long assets.
- Tools/products/workflows: UAV pipeline that segments flights into VO windows; automatic stitching with Sim(3) overlap; defect detection applied on reconstructed meshes/point clouds.
- Dependencies/assumptions: Scene motion (traffic, vegetation) can confound monocular depth; regulatory flight constraints; safe operations protocols.
- Media Production and VFX (Creative Tech)
- Use cases: On‑set camera tracking and live depth for previz and virtual production, reducing reliance on markers and offline match‑moving.
- Tools/products/workflows: Direct mode for accurate short takes; live feed into Unreal/Unity cameras; export camera poses to DCC tools; automated scale alignment using anchors/props.
- Dependencies/assumptions: Consistent lighting/texture; coordinate alignment with stage; careful anchor calibration for metric scale.
- Autonomous Driving R&D (Automotive)
- Use cases: Prototype visual odometry and dense mapping for research; redundancy channel for localization; dataset curation and labeling (poses/depth).
- Tools/products/workflows: VO mode fused with IMU/GNSS; online drift metrics; plug‑ins for open‑source stacks (Apollo/Autoware).
- Dependencies/assumptions: Dynamic objects are common—requires filtering or multi‑sensor fusion; regulatory and safety validation.
- Education and Research (Academia)
- Use cases: Teaching and benchmarking streaming 3D reconstruction; ablation on attention masks and memory designs; open baselines for long‑sequence perception.
- Tools/products/workflows: Reproducible training using progressive view curriculum and context parallel (Ulysses); FlashInfer/torch kernels for paged KV cache; standardized evaluation on Oxford Spires, ETH3D, 7‑Scenes, T&T.
- Dependencies/assumptions: Compute access for training; dataset licenses; careful hyperparameter management for long‑sequence stability.
- Software Infrastructure and ML Systems (Developer Tools)
- Use cases: Generalize GCA and paged KV‑cache to other streaming video transformers (e.g., tracking, action recognition); deployable modules for long‑context inference.
- Tools/products/workflows: A “GCA attention layer” library; FlashInfer‑based runtime with paged KV and sparse masks; context‑parallel training templates; monitoring tools for drift and cache growth.
- Dependencies/assumptions: GPUs with bfloat16 and fast interconnect for context‑parallel training; support in deployment stacks.
- Consumer Scanning and Documentation (Daily Life, Insurance)
- Use cases: Quick capture of interiors for insurance claims, moving/renovation, or real estate listings using a phone; auto‑generated 3D tours.
- Tools/products/workflows: App with Direct mode for short captures; server‑side VO stitching for longer scans; easy export to common formats and sharable viewers.
- Dependencies/assumptions: Connectivity for cloud processing; user guidance for anchor setup; privacy safeguards.
- Assistive Navigation (Healthcare, Accessibility)
- Use cases: On‑device depth and pose for obstacle awareness and spatial audio guidance for visually impaired users in static or mildly dynamic environments.
- Tools/products/workflows: Smartphone app with low‑res streaming depth; wearable camera integration; optional cloud refinement.
- Dependencies/assumptions: Robustness under low light and motion blur may vary; safety requires conservative thresholds and sensor redundancy.
Long‑Term Applications
- Persistent AR Cloud and Crowdsourced Mapping (Software, Telecom)
- Use cases: City‑scale, continuously updated 3D maps from crowdsourced videos; compact trajectory memory tokens uploaded for global fusion.
- Tools/products/workflows: Cloud service aggregating trajectory tokens and anchor contexts; loop‑closure and semantic fusion pipelines; APIs for AR apps.
- Dependencies/assumptions: Privacy/security frameworks for interior/exterior scans; scalable storage/computation; improved loop‑closure without heavy optimization.
- Multi‑Agent Cooperative Mapping (Robotics, Smart Cities)
- Use cases: Robots/phones exchange compact trajectory memory to co‑localize and merge maps in real time for large facilities or disaster response.
- Tools/products/workflows: Token‑level communication protocols; cross‑agent Sim(3) alignment; distributed drift correction.
- Dependencies/assumptions: Reliable networking; consistent time/scale references; research on robust token fusion and conflict resolution.
- Surgical and Medical Navigation (Healthcare)
- Use cases: Streaming 3D reconstruction in endoscopy or microsurgery for guidance overlays where depth sensors are impractical.
- Tools/products/workflows: Sterilizable camera modules; OR‑grade inference systems; integration with navigation platforms.
- Dependencies/assumptions: Highly dynamic, deforming, specular scenes; stringent regulatory approval; domain‑specific training.
- 4D Reconstruction in Dynamic Environments (Sports, Retail, Manufacturing)
- Use cases: Real‑time geometry with moving objects for analytics, teleoperation, or robot safety zones.
- Tools/products/workflows: Extend GCA with dynamic object separation/tracking; temporal consistency modules; semantic integration.
- Dependencies/assumptions: Additional training on dynamic datasets; compute budget increases; reliability under occlusions.
- Ultra‑Low‑Power and On‑Device Deployment (Edge AI, Consumer Devices)
- Use cases: Running streaming 3D on phone NPUs, AR glasses, or micro‑drones at higher resolutions/longer sequences.
- Tools/products/workflows: Model distillation/quantization; operator fusion; memory‑aware schedulers; hardware co‑design.
- Dependencies/assumptions: Hardware support for paged KV and sparse attention; maintaining accuracy after compression.
- Digital Twins at City/Enterprise Scale (AEC, Energy, Utilities)
- Use cases: Continuous digital twin updates from vehicle/body‑cam video for asset management, predictive maintenance, and planning.
- Tools/products/workflows: Pipeline combining VO windows with GIS and LiDAR priors; automated change detection; governance dashboards.
- Dependencies/assumptions: Data governance and access controls; loop‑closure and semantics; robust long‑term drift management.
- Insurance and Finance Automation (Finance, Insurtech)
- Use cases: Automated claims processing and risk assessment from policyholder‑submitted videos; property valuation updates.
- Tools/products/workflows: Secure ingestion; scale calibration with known objects; integration with underwriting systems.
- Dependencies/assumptions: Regulatory acceptance of AI‑derived measurements; anti‑fraud safeguards; fairness/consistency audits.
- Policy and Standards for Spatial Data (Public Policy)
- Use cases: Guidelines for privacy, retention, and sharing of streamed 3D reconstructions in public/private spaces; procurement specs for real‑time mapping.
- Tools/products/workflows: Standards that define acceptable drift, update rates, and anonymization for interior scans; benchmark suites for certification.
- Dependencies/assumptions: Multi‑stakeholder consensus; evolving legal frameworks for spatial data rights.
- Generalized Long‑Context Video Transformers (AI Research, Software)
- Use cases: Applying GCA and paged KV patterns to other tasks (e.g., video understanding, tracking, multi‑camera fusion) that need compact long‑range memory.
- Tools/products/workflows: Research libraries providing GCA modules; training recipes with progressive view curriculum and context parallelism.
- Dependencies/assumptions: Task‑specific losses and datasets; verification of stability at very long horizons.
Cross‑Cutting Assumptions/Dependencies
- Monocular input is inherently scale‑ambiguous; reliable metric output requires anchor initialization (e.g., first n frames, markers, or known dimensions).
- Reported real‑time performance is at 518×378; higher resolutions and adverse conditions (low light, heavy dynamics) will impact throughput/accuracy.
- Robustness on highly dynamic scenes is limited and may need additional modeling or multi‑sensor fusion.
- Training at scale depends on large, diverse datasets and substantial compute (context parallelism, bfloat16, all‑to‑all communication).
- Deployments should include drift monitoring and, where safety‑critical, fuse with IMU/LiDAR/GNSS and implement fail‑safe behaviors.
Glossary
- Absolute Trajectory Error (ATE): A trajectory-level metric measuring global consistency by comparing estimated and ground-truth camera positions after alignment. "we report the Absolute Trajectory Error (ATE) in meters"
- anchor context: A set of designated reference frames that establish coordinate origin and scale for subsequent streaming inference. "GCA explicitly maintains three complementary types of context: an anchor context for coordinate and scale grounding"
- bfloat16: A 16-bit floating-point format that preserves exponent range for efficient training/inference with reduced memory. "with bfloat16 precision."
- bundle adjustment: An optimization that jointly refines camera poses and 3D points by minimizing reprojection error. "typically centered around optimization-based bundle adjustment for camera pose estimation."
- camera-to-world transformations: A pose parameterization mapping points from camera coordinates into a global world frame. "we supervise the network using camera-to-world transformations rather than world-to-camera ones."
- causal attention: An attention mechanism that restricts tokens to attend only to past context to enable streaming. "using causal attention and caching strategies."
- context parallelism: A distributed training technique that shards long contexts or many views across devices to scale attention efficiently. "we employ the Ulysses~\cite{jacobs2023deepspeed} context-parallelism strategy"
- cross-view attention: Transformer attention across different images/views to aggregate multi-view geometric cues. "includes cross-view attention layers,"
- DINOv2: A self-supervised vision model used to initialize image backbones for stronger feature representations. "We initialize the ViT backbone from DINOv2~\cite{oquab2023dinov2}"
- FlashInfer: An optimized runtime/library providing fast attention kernels and paged KV-cache support for long sequences. "We implement the runtime on FlashInfer~\cite{ye2025flashinfer}"
- geodesic rotation error: The angular difference between rotations computed on the SO(3) manifold, used as a rotation loss/metric. "denote the geodesic rotation error and translation error"
- Geometric Context Attention (GCA): The paper’s structured attention mechanism that maintains anchors, a local window, and trajectory memory for streaming 3D reconstruction. "we introduce Geometric Context Attention (GCA)"
- Geometric Context Transformer (GCT): The overall architecture built on GCA to enable efficient, consistent streaming 3D reconstruction. "built upon a geometric context transformer (GCT) architecture."
- Iterative Closest Point (ICP): An algorithm that aligns two point clouds by iteratively minimizing distances between corresponding closest points. "followed by ICP refinement (threshold 0.1)."
- keyframe selection: Choosing representative frames to retain in memory based on motion/coverage to control cache growth and maintain accuracy. "we employ an adaptive keyframe selection strategy to control KV-cache growth."
- KV cache: The cached key and value tensors in transformer attention used to avoid recomputation over long sequences. "whose features are appended to the KV cache"
- Multi-View Stereo (MVS): A class of methods that reconstruct dense 3D geometry from multiple images with known camera poses. "and Multi-View Stereo (MVS)~\cite{furukawa2009accurate,schonberger2016pixelwise,yao2018mvsnet}."
- paged KV-cache: A paged memory layout for key/value caches that supports efficient appends/evictions without costly reallocations. "a paged KV-cache layout~\cite{kwon2023efficient}"
- pose-graph: A graph of camera poses connected by relative constraints, optimized in SLAM back-ends for global consistency. "pose-graph maintenance"
- pose-reference window: A sliding set of recent frames retained with full tokens to provide dense local cues for accurate pose estimation. "a local pose-reference window that retains dense visual features from recent frames"
- Recurrent Neural Network (RNN): A neural architecture that maintains and updates a hidden state over sequences for temporal modeling. "Recurrent Neural Network (RNN)-based architectures"
- relative pose error: A metric of frame-to-frame pose accuracy measuring rotational/translation errors between consecutive estimates. "the Area Under the Curve (AUC) of the relative pose error at angular thresholds of and ."
- Sim(3) alignment: Estimating a similarity transform (scale, rotation, translation) to align two trajectories or point sets in 3D. "we compute a Sim(3) alignment between the overlapping regions of consecutive windows"
- Simultaneous Localization and Mapping (SLAM): Techniques that jointly estimate a sensor’s trajectory and a map of the environment from sensor data. "Simultaneous Localization and Mapping (SLAM)"
- sliding-window attention: Attention restricted to a fixed-size local temporal window to bound memory and compute. "Sliding-window attention bounds cost but loses long-range context."
- Structure-from-Motion (SfM): A pipeline that recovers camera poses and 3D structure from multiple images, typically offline. "Structure-from-Motion (SfM)~\cite{snavely2006photo, schonberger2016structure, pan2024global}"
- test-time training (TTT): Adapting model parameters during inference on a specific sequence to improve performance. "with test-time training (TTT) for global consistency"
- trajectory memory: A compact per-frame summary of past observations retained to mitigate long-range drift in streaming. "and a trajectory memory to address coordinate grounding, dense geometric cues, and long-range drift correction, respectively."
- Umeyama method: A least-squares algorithm for estimating the best-fit similarity transform between two point sets. "using the Umeyama~\cite{umeyama2002least} method"
- Vision Transformer (ViT): A transformer-based architecture applied to images that tokenizes patches and uses self-attention. "Each input image is first encoded by a Vision Transformer (ViT) backbone"
- Visual Odometry (VO): Estimating camera motion from visual data without maintaining a full global map; often used for very long sequences. "supports two inference modes, Direct Output and Visual Odometry (VO)"
Collections
Sign up for free to add this paper to one or more collections.

