InfiniteVGGT: Visual Geometry Grounded Transformer for Endless Streams
Abstract: The grand vision of enabling persistent, large-scale 3D visual geometry understanding is shackled by the irreconcilable demands of scalability and long-term stability. While offline models like VGGT achieve inspiring geometry capability, their batch-based nature renders them irrelevant for live systems. Streaming architectures, though the intended solution for live operation, have proven inadequate. Existing methods either fail to support truly infinite-horizon inputs or suffer from catastrophic drift over long sequences. We shatter this long-standing dilemma with InfiniteVGGT, a causal visual geometry transformer that operationalizes the concept of a rolling memory through a bounded yet adaptive and perpetually expressive KV cache. Capitalizing on this, we devise a training-free, attention-agnostic pruning strategy that intelligently discards obsolete information, effectively ``rolling'' the memory forward with each new frame. Fully compatible with FlashAttention, InfiniteVGGT finally alleviates the compromise, enabling infinite-horizon streaming while outperforming existing streaming methods in long-term stability. The ultimate test for such a system is its performance over a truly infinite horizon, a capability that has been impossible to rigorously validate due to the lack of extremely long-term, continuous benchmarks. To address this critical gap, we introduce the Long3D benchmark, which, for the first time, enables a rigorous evaluation of continuous 3D geometry estimation on sequences about 10,000 frames. This provides the definitive evaluation platform for future research in long-term 3D geometry understanding. Code is available at: https://github.com/AutoLab-SAI-SJTU/InfiniteVGGT


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
InfiniteVGGT: A simple explanation
What is this paper about?
This paper is about teaching computers to understand 3D scenes from video in real time, for as long as the video keeps going. Imagine a robot or AR glasses watching the world through a camera and building a 3D map on the fly, without pausing, crashing, or slowly forgetting what it already saw. The authors introduce a new method called InfiniteVGGT that makes this possible using a smarter “memory” system.
What questions are the researchers asking?
The paper focuses on three big questions:
- How can a model watch an endless video stream and keep building a stable 3D map without running out of memory?
- How can it avoid “drift,” where small mistakes slowly add up and the 3D map becomes crooked or messy over time?
- How can we fairly test these abilities when most public tests are too short? (Their answer: make a new benchmark called Long3D with very long videos.)
How does it work? (In everyday terms)
Think of the model like a person taking notes while watching a very long movie:
- Every frame (image) of the video is broken into many small “tokens” (like tiny notes).
- A Transformer (a powerful type of AI) uses “attention” to decide which past notes matter for understanding the current frame.
- Normally, storing all past notes makes the notebook grow forever, which eventually fills up memory. Some methods try to store everything (they run out of memory), while others squash the history into a tiny summary (they forget important details and drift).
InfiniteVGGT introduces a better way to keep notes:
- Rolling memory: Keep the memory the same size by smartly swapping out old, unhelpful notes as new frames arrive. It’s like using a small whiteboard: you erase the most repetitive scribbles to make room for new, useful ones.
- Diversity-based filtering: Instead of looking at “attention weights” (which would be slow), the method checks how similar the new notes are to what’s already stored. If a token is too similar to others, it’s probably redundant and can be dropped. If it’s different, it’s valuable and should be kept. This is measured with a simple “cosine similarity” score—think of it as “how much do these two arrows point in the same direction?” Lower similarity means more unique information.
- Anchor frame: The very first frame is kept completely, like a permanent reference map. This prevents the whole 3D world from slowly shifting over time.
- Layer-wise budgeting: The Transformer has many layers. Some layers need more memory than others. The method automatically gives more memory to layers that show more “variety” in their information and less to those that are more repetitive. This keeps the memory well-balanced.
- Works with fast attention: The method is compatible with FlashAttention, a speed-up trick for Transformers. This matters because it keeps the system fast even with long video streams.
In short, InfiniteVGGT keeps the “right” parts of the past and throws away duplicates, so it never runs out of space and stays stable over time.
What did they find, and why is it important?
- Infinite horizon without overflow: The system can process extremely long videos (thousands to nearly ten thousand frames) without running out of memory.
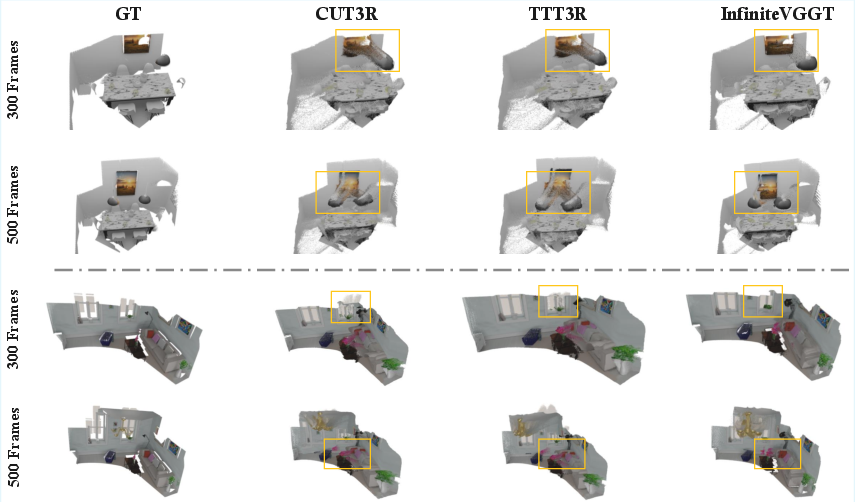
- Less drift: Because it keeps the most informative history and a strong anchor from the first frame, errors don’t pile up as quickly. The 3D maps stay more accurate over time.
- Strong results across tasks: It improves long-sequence 3D reconstruction, video depth estimation, and camera pose estimation compared to previous streaming methods that either blow up memory or forget too much.
- Training-free: This is a plug-in strategy—you don’t need to retrain the whole model to use it. That makes it practical to adopt.
To make testing fair and realistic, the authors also made the Long3D benchmark:
- Long3D contains continuous video sequences up to about 10,000 frames, from indoor and outdoor scenes.
- It allows researchers to measure stability and quality over truly long periods, which older datasets couldn’t do.
Why does this matter?
- Real-time 3D for robots and AR: Robots, drones, and AR glasses need steady, accurate 3D understanding over long stretches. This method gives them a reliable “memory” that doesn’t crash or fade.
- Scales to real-world use: Instead of being great on short clips and failing in the wild, InfiniteVGGT is designed for continuous, real-world streams.
- A new testbed for the field: Long3D sets a higher standard for what “long-term” really means, pushing future research to build systems that last.
Key takeaways
- The core idea is a smart, rolling memory that keeps the most diverse and useful bits of the past while discarding repetition.
- It stays fast and memory-safe, even with endless input.
- It reduces long-term mistakes (drift) and improves 3D reconstruction quality on long videos.
- The new Long3D benchmark helps everyone test these claims fairly on very long sequences.
Knowledge Gaps
Below is a concise list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research:
- Validate the diversity-based pruning beyond StreamVGGT/VGGT-like backbones: does key cosine similarity remain a reliable redundancy proxy for other encoders (e.g., non-DINO backbones, different patch embeddings, varying tokenization schemes)?
- Robustness to challenging motion regimes: how does the rolling memory behave under rapid viewpoint changes, low overlap, motion blur, abrupt camera jumps, or long stretches of visually dissimilar frames where token redundancy is minimal?
- Dynamic and non-rigid scenes: the method is evaluated primarily on static geometry; how does token pruning impact tracking and reconstruction when objects move or deform, and can the cache adapt to temporally salient but transient tokens?
- Anchor-frame design and recovery: what are failure modes when the first frame is poorly exposed, blurred, or non-representative, and how should re-anchoring, keyframe updates, or multi-anchor strategies be triggered to maintain global consistency?
- Loop closure and long-term re-localization: can the rolling memory reliably support revisits to earlier areas and correct accumulated drift without explicit loop-closure mechanisms or global optimization?
- Budget tuning and sensitivity: provide principled methods or online adaptation for selecting total budget, per-layer budgets, and temperature τ; quantify sensitivity and automatic tuning strategies based on scene complexity and observed redundancy.
- Token selection criterion: the negative cosine to the layer-head mean may favor outliers/noise; compare against alternative subset selection strategies (e.g., k-center/coreset, submodular maximization, reservoir sampling, temporal decay, coverage-based heuristics) and define theoretical guarantees.
- Online computational profile: quantify per-frame latency, amortized cost of diversity scoring and TopK, and VRAM usage over 10k+ frames under different budgets; evaluate real-time viability on embedded/edge hardware and non-A100 GPUs.
- Attention-kernel generality: verify compatibility and performance with attention implementations other than FlashAttention (e.g., xFormers, Triton kernels) and under mixed precision or quantization.
- Value pruning consistency: detail how value pruning mirrors key selection across layers/heads and its effect on stability; explore whether decoupled K/V pruning or V-aware selection improves reconstruction.
- Completion metric degradation: investigate why the method underperforms on mean completeness and design geometry-aware retention (e.g., spatial coverage, surface track density) to improve point cloud coverage.
- Camera pose evaluation: provide quantitative long-horizon pose metrics (ATE/RPE, drift curves) on datasets with ground-truth trajectories, including closed-loop sequences; current results focus largely on reconstruction and depth.
- Evaluation alignment via ICP: assess whether ICP alignment masks trajectory or scale errors; include metrics independent of post hoc alignment and report failure cases where ICP cannot reliably converge.
- Long3D scope and diversity: expand beyond the current five sequences to include more environments, higher frame rates, dynamic content, challenging lighting/weather, and longer horizons; release detailed calibration (intrinsics/extrinsics/timestamps) for rigorous benchmarking.
- Sensor fusion opportunities: exploit the collected IMU/LiDAR signals to improve memory retention, drift correction, and loop closure; quantify gains over RGB-only streaming.
- Handling repetitive/textureless regions: examine retention policies in scenes with low discriminative appearance and propose region-aware or structure-aware selection that avoids cache saturation by redundant tokens.
- Mean estimation dynamics: specify and analyze the online update rule for the key-space mean (e.g., exponential moving average vs. cumulative mean), its responsiveness to distribution shift, and stability implications.
- Drift detection and adaptive recovery: develop monitoring of reconstruction/pose error and policies to temporarily expand budgets, refresh anchors, or trigger re-localization on detected failure.
- Scalability vs. scene complexity: characterize how budget requirements scale with scene size/complexity and provide guidelines for selecting budgets to avoid map under-representation under strict memory bounds.
- Fair-memory baselines: compare against sliding-window and pointer-memory methods under matched VRAM and latency budgets to disentangle algorithmic advantages from resource differences.
- Stride/frame-rate effects: study how sampling stride, frame rate, and temporal redundancy influence pruning effectiveness and reconstruction quality; provide recommendations for streaming configurations.
- Integration into training: explore learned pruning/retention policies (e.g., reinforcement learning or distillation) and co-training the backbone to produce keys better aligned with diversity-aware caches.
Practical Applications
Immediate Applications
The following use cases can be deployed today by leveraging InfiniteVGGT’s training-free, bounded-memory streaming 3D reconstruction and the Long3D benchmark for evaluation.
- Real-time monocular 3D mapping for mobile robots
- Sectors: Robotics, Logistics, Manufacturing
- What: Integrate InfiniteVGGT as a ROS2 node to provide continuous depth, point clouds, and camera pose for AMRs, drones, and inspection robots without memory growth over time.
- Tools/products/workflows: ROS2 package with CUDA + FlashAttention; on-robot inference pipeline; warehouse/delivery navigation maps updated on-the-fly; monitoring dashboards.
- Assumptions/dependencies: GPU with FlashAttention support; calibrated monocular cameras; adequate lighting/texture; anchor-frame global reference must be stable; performance validated at 10 Hz, 800×600 (may need tuning for other rates/resolutions).
- Persistent AR scene understanding on edge devices
- Sectors: AR/VR, Mobile Software
- What: Use rolling-memory depth and point maps to enable long sessions in AR apps (occlusion, stable anchors, room-scale persistence) without drift accumulation or memory spikes.
- Tools/products/workflows: Unity/Unreal plugins; ARCore/ARKit bridge; mobile inference with bounded KV cache; session persistence manager.
- Assumptions/dependencies: Mobile GPU/NPUs may require quantization/pruning; camera motion continuity; limited robustness under extreme motion blur or low texture.
- Continuous site scanning in AEC (Architecture, Engineering, Construction)
- Sectors: Construction, Facilities Management, Digital Twins
- What: Handheld continuous video capture to produce large-scale, consistent 3D point clouds of construction sites or buildings in a single pass.
- Tools/products/workflows: Field scanning app; cloud post-processing for alignment/export to BIM; progress tracking workflows.
- Assumptions/dependencies: Camera intrinsics/extrinsics known; environment coverage and lighting; export pipelines (e.g., IFC) and QA procedures.
- Live volumetric capture for virtual production and VFX
- Sectors: Media & Entertainment
- What: Use InfiniteVGGT to generate on-set proxy geometry and depth from long camera takes for rapid previsualization and environment capture.
- Tools/products/workflows: Ingest from camera feeds; pipeline to DCC tools (Unreal, Nuke); real-time mesh/point cloud previews.
- Assumptions/dependencies: Multi-cam synchronization optional but beneficial; quality depends on scene texture and motion; may require later refinement.
- Infrastructure inspection from video (without LiDAR)
- Sectors: Energy, Utilities, Transportation
- What: Drones or handheld cameras stream long video for 3D reconstruction of assets (turbines, solar farms, bridges) to detect deformation or anomalies.
- Tools/products/workflows: Field app + cloud dashboard; change detection against baseline meshes; maintenance ticketing.
- Assumptions/dependencies: Stable capture paths; environmental variability (glare, repetitive structures) can impact reconstruction; regulatory permissions for drone flights.
- Video depth estimation with long-term consistency
- Sectors: Robotics, Mapping, Content Creation
- What: Deploy InfiniteVGGT’s video depth outputs in pipelines needing temporally consistent depth (e.g., view synthesis, navigation, AR occlusion).
- Tools/products/workflows: Depth stream API; temporal smoothing optional; integration with SLAM backends or NeRF-like renderers for improved stability.
- Assumptions/dependencies: Camera rig calibration; scene dynamics may reduce consistency; benchmarks show improved metrics on long sequences but may need post-filters.
- Academic evaluation of long-horizon 3D systems
- Sectors: Academia, R&D
- What: Adopt Long3D to evaluate and compare streaming 3D reconstruction methods over 2,000–10,000 frames.
- Tools/products/workflows: Benchmark harness; standardized metrics (Acc., Comp., CD, NC) with ICP alignment; leaderboards and ablation protocols.
- Assumptions/dependencies: Access to dataset and code; alignment to ground truth (LiDAR scans) for fair comparisons.
- KV-cache pruning for streaming vision Transformers
- Sectors: Software Infrastructure, ML Platforms
- What: Use the attention-agnostic, key-cosine similarity pruning strategy as a drop-in optimization for Transformer-based streaming perception models.
- Tools/products/workflows: Library/plugin for causal attention layers; FlashAttention-compatible pruning; layer-wise budget allocation utilities.
- Assumptions/dependencies: Architectures expose KV caches; cosine-similarity proxy generalizes to target model; profiling to tune per-layer budgets.
- Security/surveillance 3D situational awareness
- Sectors: Security, Smart Buildings
- What: Build 3D reconstructions from long CCTV video streams to support change detection and incident analysis without offline batch processing.
- Tools/products/workflows: Edge inference appliance; privacy controls (masking, access policies); alert pipelines.
- Assumptions/dependencies: Privacy/legal constraints; interior lighting and camera placement; dynamic scenes may require foreground–background separation.
Long-Term Applications
These opportunities will likely require further research, systems integration, regulatory validation, or scaling beyond current hardware limits.
- City-scale AR cloud and persistent spatial anchors
- Sectors: AR/VR, Mapping, Smart Cities
- What: Continuous, multi-user, multi-session mapping with bounded-memory streaming models to maintain a living city-scale 3D map.
- Tools/products/workflows: Crowd-sourced capture apps; cloud fusion of multiple streams; anchor sharing and conflict resolution.
- Assumptions/dependencies: Robustness to dynamic scenes; multi-camera/device calibration; large-scale backend for fusion and versioning; privacy protections.
- Vision-centric autonomous navigation with long-horizon mapping
- Sectors: Automotive, Robotics
- What: Fuse InfiniteVGGT outputs with IMU/LiDAR and semantics for robust navigation over hours of driving, reducing dependence on HD maps.
- Tools/products/workflows: Sensor fusion stack (factor graphs); continual map updates; redundancy checks; fleet-scale evaluation.
- Assumptions/dependencies: Safety-critical validation; handling adverse weather/night; integration with V2X and map priors; real-time constraints on embedded hardware.
- Lifelong digital twins and asset management
- Sectors: Manufacturing, Facilities, Utilities
- What: Maintain continuously updated 3D models of factories/campuses over months, enabling predictive maintenance and layout optimization.
- Tools/products/workflows: Scheduled capture routes; change detection and version control; integration with CMMS/PLM systems.
- Assumptions/dependencies: Persistent identifiers for assets; drift-free fusion across sessions; policies for data retention and access control.
- General-purpose KV-cache management for streaming Transformers
- Sectors: ML Infrastructure, Speech, Video Analytics
- What: Extend the rolling-memory + cosine-similarity pruning to other domains (e.g., ASR, video-LLMs) to bound memory and latency for long inputs.
- Tools/products/workflows: Cross-domain libraries; autotuning of layer-wise budgets; benchmarks akin to Long3D for speech/video.
- Assumptions/dependencies: Validation that key-space diversity correlates with token utility in each domain; careful impact analysis on accuracy.
- On-device/edge hardware co-design
- Sectors: Semiconductors, Edge AI
- What: Co-design FlashAttention-style kernels with hardware support for pre-attention KV pruning and layer-wise budgets for mobile/AR glasses SoCs.
- Tools/products/workflows: Compiler support for token pruning; hardware instructions for cosine similarity and TopK; power/perf benchmarks.
- Assumptions/dependencies: Vendor collaboration; memory bandwidth constraints; thermal budgets; model quantization.
- Dynamic 4D scene understanding with semantics
- Sectors: Robotics, Media, Research
- What: Extend InfiniteVGGT to handle non-rigid and moving objects with persistent identities and 4D geometry over long streams.
- Tools/products/workflows: Joint geometry+tracking+segmentation models; per-object memory budgets; long-sequence evaluation datasets.
- Assumptions/dependencies: New training or hybrid modules (currently training-free); occlusion handling; memory allocation per instance.
- Clinical navigation and robotic endoscopy
- Sectors: Healthcare
- What: Deploy long-horizon, consistent depth and geometry in endoscopic/laparoscopic navigation and robotic guidance.
- Tools/products/workflows: OR-integrated systems; cross-modality fusion (US/CT); safety monitors and failover.
- Assumptions/dependencies: Regulatory approvals (e.g., FDA/CE); rigorous clinical validation; sterility and real-time guarantees; domain adaptation to low-texture tissues.
- Standards and policy for long-term streaming 3D evaluation
- Sectors: Policy, Standards Bodies, Public Sector
- What: Use Long3D-like protocols to certify performance and robustness of long-horizon 3D perception systems in public spaces and infrastructure.
- Tools/products/workflows: Evaluation suites; procurement specs; compliance reporting.
- Assumptions/dependencies: Stakeholder alignment; privacy-by-design requirements for 3D reconstructions; dataset governance.
- Consumer-grade persistent home scanning and AR remodeling
- Sectors: Consumer Apps, Real Estate
- What: Turn smartphones into continuous, bounded-memory room/house scanners for remodeling, furniture placement, and insurance documentation.
- Tools/products/workflows: Mobile apps with offline/online mapping; cloud sync and sharing; integration with e-commerce catalogs.
- Assumptions/dependencies: On-device acceleration; UX for long sessions; robust relocalization across days; data privacy and security.
Notes on Feasibility and Dependencies Across Applications
- Model and runtime: The approach is training-free but assumes a pretrained StreamVGGT-like model and access to FlashAttention or similar optimized kernels.
- Performance envelope: Results reported on 10 Hz, 800×600 RGB with single-camera inputs; different frame rates, resolutions, and camera types may require tuning.
- Scene conditions: Textureless surfaces, low light, heavy motion blur, and highly dynamic scenes can degrade geometry; anchor-frame stability is critical for global consistency.
- System integration: Accurate camera calibration and time synchronization are essential; for multi-sensor fusion, robust extrinsic calibration and latency handling are required.
- Privacy and compliance: Persistent 3D reconstruction can capture sensitive spaces; applications must incorporate consent, masking, and secure data handling.
- Hardware: Edge/mobile deployments may need quantization, pruning, or co-processors; sustained real-time performance depends on VRAM budgets and kernel availability.
Glossary
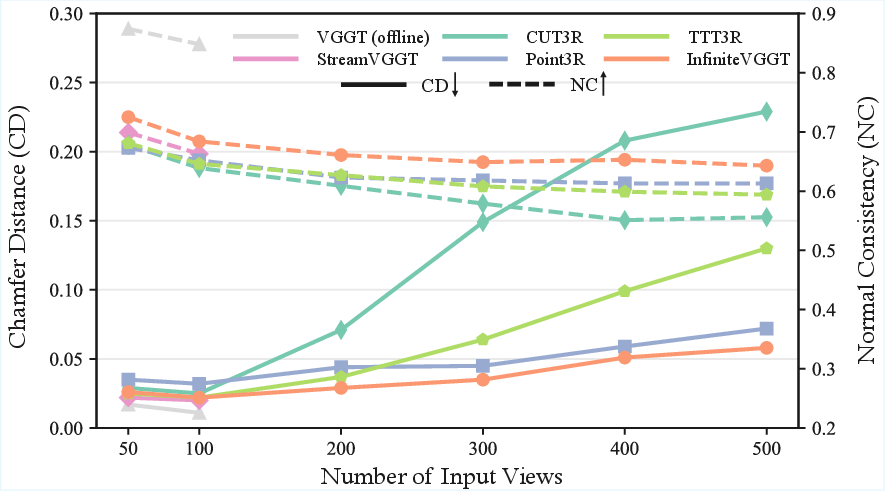
- Accuracy (Acc.): A point-cloud metric measuring how close predicted surfaces are to ground truth surfaces. "including Accuracy (Acc.), Completion (Comp.), Chamfer Distance(CD) and Normal Consistency (NC)."
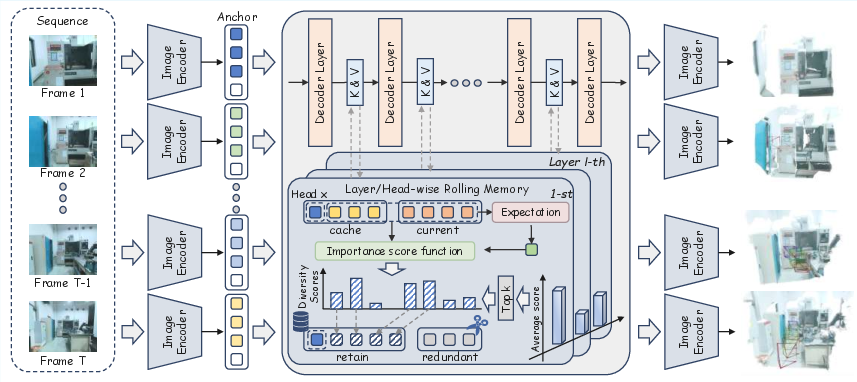
- Anchor frame: The first frame used as a fixed global reference coordinate system for all subsequent predictions. "we design a strategy where the tokens of the first frame are fully retained as an anchor frame"
- Attention matrix: The full matrix of attention scores computed between all queries and keys in a transformer layer. "these kernels achieve their speed by circumventing the materialization of the full attention matrix"
- Attention weights: The normalized scores indicating the importance of each key to a given query in attention. "traditional pruning methods rely on accessing these very weights to gauge token importance"
- Attention-agnostic pruning strategy: A token pruning method that does not require computing attention weights. "a training-free, attention-agnostic pruning strategy that intelligently discards obsolete information"
- Bundle Adjustment (BA): A global optimization that jointly refines camera poses and 3D points to minimize reprojection error. "perform a global Bundle Adjustment (BA)~\cite{2000Multiple} across all views and points"
- Causal attention mechanism: An attention setup where the current token can only attend to past tokens, enabling streaming. "the causal attention mechanism () fundamentally depends on hardware-optimized kernels"
- Causal temporal attention module: A module that applies causal attention across time to process frames incrementally. "substitute the global interaction with a causal temporal attention module "
- Causal visual geometry transformer: A transformer designed for visual geometry tasks that processes data causally over time. "a causal visual geometry transformer that operationalizes the concept of a rolling memory"
- Chamfer Distance (CD): A metric measuring bidirectional closest-point distances between two point clouds. "Chamfer Distance(CD)"
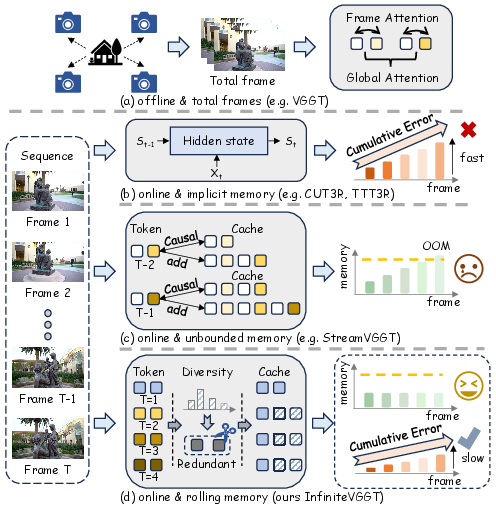
- Catastrophic drift: Accumulating error over long sequences that causes reconstructions to diverge from reality. "Existing methods either fail to support truly infinite-horizon inputs or suffer from catastrophic drift over long sequences."
- Catastrophic forgetting: Loss of previously acquired information due to overly compressed or overwritten memory in sequential models. "catastrophic forgetting caused by transitionally compressed memory remains a fundamental challenge"
- Completion (Comp.): A point-cloud metric measuring how completely the ground-truth surface is covered by predictions. "including Accuracy (Acc.), Completion (Comp.), Chamfer Distance(CD) and Normal Consistency (NC)."
- Cosine similarity: A measure of similarity between vectors based on the cosine of the angle between them. "we introduce an elegant solution by leveraging key cosine similarity as an efficient, attention-independent proxy for token importance"
- DINO backbone: A vision transformer backbone pretrained with the DINO self-supervised framework. "the DINO~\cite{2024DINOv2} backbone being trained as a semantic encoder"
- Diversity score: A scalar measuring how dissimilar a token’s key is from the mean key, used to retain informative tokens. "we define a diversity score for each individual key"
- FlashAttention: A memory- and speed-optimized attention kernel that avoids materializing the full attention matrix. "Fully compatible with FlashAttention, InfiniteVGGT finally alleviates the compromise"
- Global camera-token pool: A persistent set of tokens representing global camera information used beyond the local window. "WinT3R attempts to mitigate this with a global camera-token pool"
- Global point cloud: A unified 3D point set representing the entire scene across all frames. "the data consists of a global ground-truth point cloud"
- Immutable anchor tokens: The unpruned set of tokens from the first frame that remain fixed to preserve global consistency. "establishing an immutable set of anchor tokens, defined as the complete KV cache derived from the initial input frame"
- Iterative Closest Point (ICP) algorithm: An algorithm to align two point clouds by iteratively minimizing distance between paired points. "aligned using the Iterative Closest Point (ICP) algorithm"
- Key cosine similarity: Cosine similarity computed in key space to estimate redundancy and importance of tokens. "by leveraging key cosine similarity as an efficient, attention-independent proxy for token importance"
- Key space: The vector space formed by key embeddings in attention, analyzed to quantify redundancy. "we measure redundancy in the key space"
- Key-Value (KV) cache: Stored key and value tensors from past frames enabling causal attention without recomputation. "a KV cache, , that stores the context from all previous frames"
- Key-Value (KV) stores: The accumulated collection of key-value pairs maintained across time in streaming models. "accumulating unbounded Key-Value (KV) stores"
- Long3D benchmark: A dataset and evaluation suite for continuous 3D geometry on extremely long sequences. "we introduce the Long3D benchmark, which, for the first time, enables a rigorous evaluation of continuous 3D geometry estimation"
- Materialization of the full attention weight matrix: Explicitly constructing the complete attention weights, which is computationally prohibitive at scale. "requires the materialization of the full attention weight matrix"
- Multi-View Stereo (MVS): Methods that reconstruct dense 3D geometry from multiple calibrated images. "Multi-View Stereo (MVS)~\cite{2009Accurate,2020Cascade}"
- Normal Consistency (NC): A metric evaluating alignment of surface normals between predicted and ground-truth point clouds. "including Accuracy (Acc.), Completion (Comp.), Chamfer Distance(CD) and Normal Consistency (NC)."
- Patch-embedded tokens: Tokenized image patches produced by a vision transformer backbone. "extracting the patch-embedded tokens from the backbone of StreamVGGT"
- PCA embeddings: Low-dimensional projections via Principal Component Analysis used to visualize token distributions. "PCA embeddings of query (Q) and key (K) vectors"
- Pointmap regression: Predicting per-pixel 3D points directly from images as a regression task. "formulate reconstruction as a pairwise pointmap regression problem"
- Query (Q) and key (K) vectors: The query and key embeddings used in attention for matching and weighting. "PCA embeddings of query (Q) and key (K) vectors"
- Rolling memory: A bounded, dynamically updated memory that retains salient historical tokens while evicting redundant ones. "a rolling memory paradigm for online 3D geometry understanding"
- RNN hidden state: The internal state vector of a recurrent neural network summarizing past information. "compress history into a simple RNN hidden state"
- Simultaneous Localization and Mapping (SLAM): Online methods that jointly estimate camera trajectory and build a map of the environment. "Simultaneous Localization and Mapping (SLAM), prioritize online performance"
- Sliding-window mechanism: Processing only a recent window of frames to bound computation and latency. "WinT3R~\cite{2025wint3r} employs a sliding-window mechanism"
- Softmax normalization: Exponential normalization used to convert scores into probabilities or proportions. "via a softmax normalization of these scores"
- Structure-from-Motion (SfM): Techniques that reconstruct 3D structure and camera motion from multiple images. "Structure-from-Motion (SfM)~\cite{2010Building,2011Building,2025Robust,2006PhotoTourism,2013LinearTime,2016SfM}"
- Temperature hyperparameter: A scaling parameter controlling the sharpness of a softmax distribution. "where is a temperature hyperparameter."
- Test-time training: Adapting model parameters during inference to improve performance on the current sequence. "TTT3R~\cite{2025ttt3r} introduces test-time training rules to improve length generalization"
- TopK selection: Keeping only the highest-scoring tokens up to a specified budget. "This budget is then enforced via a selection."
- Temporal receptive field: The span of past time steps a model effectively uses for current predictions. "This design inherently limits the temporal receptive field"
- Unbounded memory growth: The unchecked increase of memory usage over time as more history accumulates. "the trade-off between unbounded memory growth and long-term drift"
Collections
Sign up for free to add this paper to one or more collections.

