- The paper introduces UMI-3D, a LiDAR-centric extension that overcomes vision-only SLAM limitations by integrating LiDAR, camera, and IMU for accurate metric-scale pose estimation.
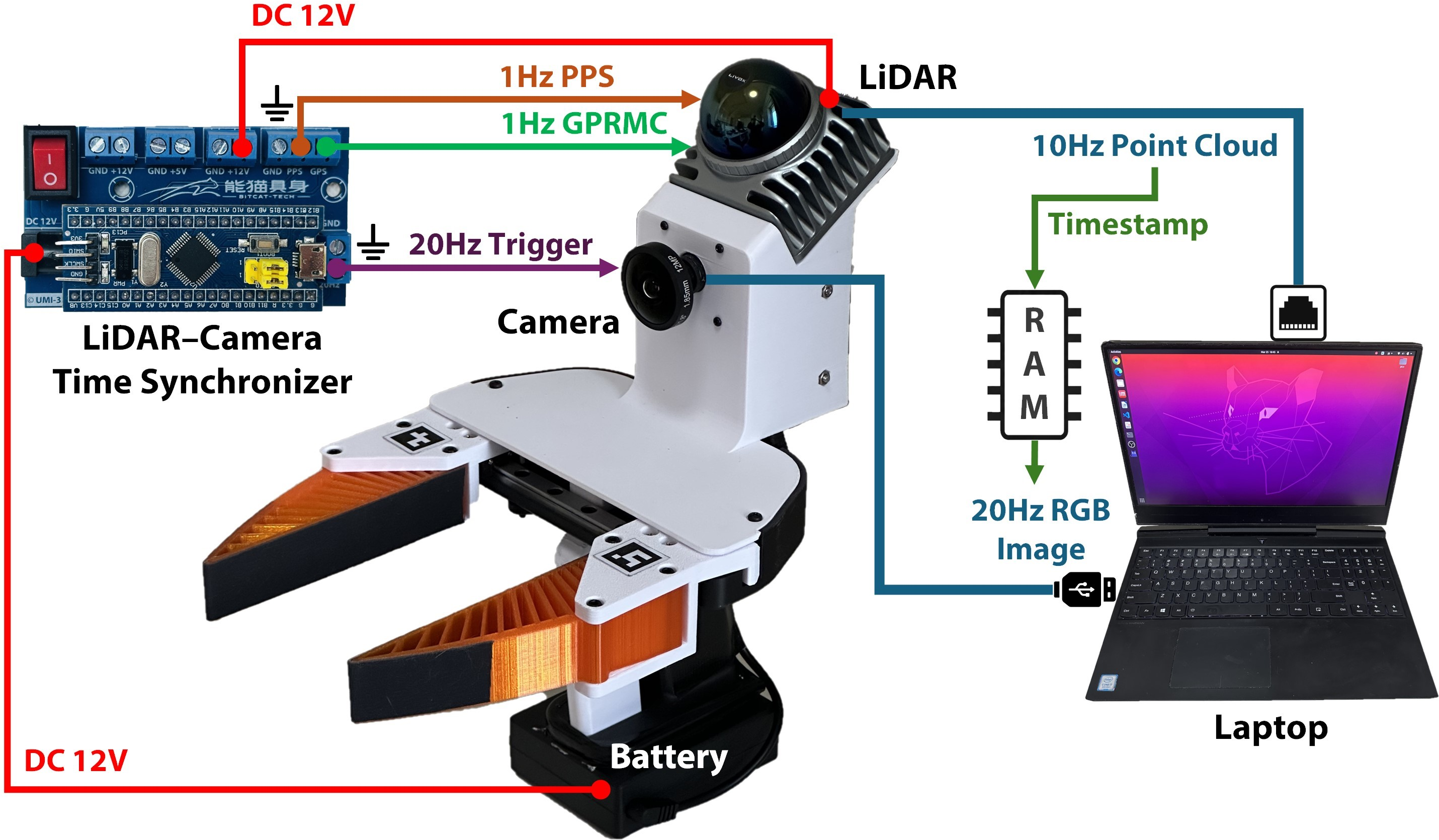
- It features a hardware-synchronized, multimodal sensor suite and a unified calibration pipeline, ensuring robust spatiotemporal alignment for varied manipulation tasks.
- Experimental validations demonstrate high SLAM robustness and reliable policy generalization, even under challenging conditions like occlusion, dynamic illumination, and deformable object manipulation.
UMI-3D: Extending Universal Manipulation Interface with LiDAR-Centric 3D Spatial Perception
Motivation and Problem Statement
The Universal Manipulation Interface (UMI) system has facilitated scalable embodied robot data collection via a portable, wrist-mounted vision-centric interface, bridging the gap between human demonstrations and robotic control. However, its dependency on monocular visual SLAM for pose estimation imposes critical limitations: SLAM failures emerge in textureless regions, occluded scenes, dynamic environments, and under photometric disturbances, restricting robust operation and scalable data acquisition. UMI-3D addresses this by integrating a lightweight, wrist-mounted multimodal sensor suite—incorporating LiDAR, camera, and IMU—enabling robust LiDAR-centric SLAM, accurate metric-scale pose estimation, and consistent 3D perception in unconstrained real-world environments.

Figure 1: UMI-3D demonstration interface design with wrist-mounted multimodal sensor suite ensuring consistent cross-embodiment observation, wide-FoV visual coverage, and precise action recording.
System Architecture and Multimodal Sensing
UMI-3D retains the ergonomic advantages of UMI’s handheld gripper design while augmenting its observation and spatial perception. The core innovation is the deployment of industrial-grade, hardware-synchronized multimodal sensors directly at the end-effector, ensuring self-contained, infrastructure-free pose tracking, and strict spatiotemporal alignment across sensing modalities.
Calibration and SLAM Pipeline
UMI-3D’s perception pipeline formalizes cross-modal calibration and state estimation, ensuring consistent spatial-temporal geometry.
- Fisheye intrinsic calibration: The equidistant projection model is adopted; parameters are estimated through multi-view checkerboard targets minimizing reprojection error, enabling accurate pixel-to-ray mapping.
- LiDAR-camera extrinsic calibration: A structured target with geometric features is used; 3D correspondences across modalities are aligned via SVD-based rigid transformation, robust to irregular LiDAR sampling and strong lens distortion.

Figure 3: (A) Raw fisheye image; (B) undistorted result. Intrinsic calibration is essential for subsequent marker detection and spatial fusion.

Figure 4: LiDAR-camera extrinsic calibration setup and multimodal feature extraction. Accurate spatial alignment forms the basis for LiDAR-camera fusion.
- LiDAR-inertial odometry: State estimation employs an iterated error-state Kalman filter (ESIKF) on manifolds, fusing IMU and LiDAR scans against voxelized probabilistic map representations. This model delivers drift-resistant, uncertainty-aware pose estimation robust to challenging conditions such as occlusion, non-rigid motion, and illumination variations.
Figure 5: Overview of LiDAR-inertial odometry system based on ESIKF, with scan recombination, residual computation, and map building.
- Unified coordinate system: All pose estimates are referenced to the initial IMU frame as global; LiDAR poses are transformed to camera and TCP frames for consistent policy interfacing.
Figure 6: Unified coordinate system and transformation chains connecting perception and manipulation frames.
Multimodal Data Packaging and Policy Interface
A tightly coupled data processing pipeline transforms temporally synchronized, spatially aligned multimodal recordings into learning-ready trajectories:
- Strict cross-modal synchronization: LiDAR and camera data are aligned with per-frame timestamp gating; ArUco-based gripper states and end-effector poses are extracted with tight temporal tolerances.
- Replay buffer construction: Episodic trajectories are compressed into a Zarr-based buffer for scalable diffusion policy training.
UMI-3D’s policy interface maintains the camera-centric simplicity of UMI while augmenting with latency-aware action observation and relative SE(3) end-effector trajectories, improving robustness and embodiment transfer:
Figure 7: Diffusion policy interface with multimodal observations, explicit latency alignment, and actions parametrized as relative SE(3) trajectories.
Experimental Validation and Quantitative Results
UMI-3D is evaluated across SLAM robustness, manipulation capability, policy generalization in diverse tasks, and cross-embodiment compatibility.
- SLAM robustness: LiDAR-centric SLAM achieves stable, accurate pose estimation and consistent mapping under textureless surfaces, occlusions, non-rigid deformation, and dynamic illumination, surpassing vision-only SLAM applicability.

Figure 8: LiDAR-centric SLAM performance under adverse conditions: textureless walls, dynamic curtain motion, and articulated manipulation.
- Cup arrangement (Generalization): On an 8×8 grid of cup-saucer combinations (64 pairs, 10 trials each), policies trained on 3,500 UMI-3D demonstrations attain normalized scores of 0.863 (seen), 0.788 (partially unseen), and 0.736 (fully unseen), evidencing strong generalization and graceful performance degradation under distribution shift.

Figure 9: Quantitative results for cup-saucer pairing: policy generalizes robustly to novel object combinations.
- Deformable manipulation (Curtain pulling): Across three curtain types (120 trials, diverse illumination), normalized scores are 0.88–0.96, demonstrating resilience against challenging lighting and deformable object dynamics.

Figure 10: Robust curtain pulling under challenging material and lighting; consistently high scores despite purely visual policy inference.
- Long-horizon manipulation: Door opening achieves 97.5% success; cup grasping falls to 47.5%; placement to 5.0%. Failure propagation analysis reveals compounding error modes, with embodiment constraints and data diversity as limiting factors.

Figure 11: Sequential manipulation task scores and error propagation; reveals bottlenecks in downstream task completion.
- Cross-embodiment transfer: Policies trained on original UMI hardware generalize to UMI-3D without retraining, achieving normalized scores ≥0.73 across novel mouse-mousepad setups. This demonstrates aligned visual representation space and compatibility, opening pathways for joint dataset scaling.

Figure 12: Direct policy deployment: UMI-trained policies maintain performance on UMI-3D hardware.
Discussion, Implications, and Future Directions
UMI-3D positions geometric SLAM—not merely as an auxiliary tracking module but as a fundamental mechanism aligning perception and action in unified metric space. The enhanced robustness enables broader task distributions, reduced filtering requirements, and scalable data acquisition infrastructures for embodied policy learning. Notably, quality and scale improvements in demonstration data directly reflect in downstream policy generalization and reliability under distribution shifts, as evidenced by experimentally validated scaling laws.
Theoretical implications include the decoupling of visual feature reliance from metric localization, enabling embodied intelligence in unconstrained environments and facilitating large-scale foundation model training. Practically, UMI-3D opens avenues for robust real-world manipulation—involving deformable, articulated, or occluded objects—where classical vision-based SLAM is fundamentally restricted.
Challenges persist. The hardware induces user fatigue due to weight, limiting prolonged operation; single-arm constraints hinder bimanual and complex stabilization tasks. Although policies currently operate with visual inputs, the system captures rich synchronized 3D geometry during demonstrations, motivating the incorporation of 3D spatial representations into policy learning for enhanced robustness and precision.
Prospective research directions include lightweight ergonomic designs, dual-arm system extensions, geometry-aware policy architectures, and unified mobile manipulation pipelines—further bridging the gap between scalable data collection, 3D spatial perception, and embodied decision-making.
Conclusion
UMI-3D introduces a LiDAR-centric, multimodal extension to the Universal Manipulation Interface, overcoming vision-only SLAM limitations and enabling robust, scalable, and metric-consistent demonstration data acquisition in real-world settings. Experimental evaluations across representative manipulation tasks demonstrate superior SLAM robustness, reliable data quality, strong policy generalization, and cross-embodiment compatibility. The system provides open-source hardware and software infrastructure, fostering accelerated research in scalable embodied intelligence and manipulation policy learning (2604.14089).