UMI-on-Air: Embodiment-Aware Guidance for Embodiment-Agnostic Visuomotor Policies
Abstract: We introduce UMI-on-Air, a framework for embodiment-aware deployment of embodiment-agnostic manipulation policies. Our approach leverages diverse, unconstrained human demonstrations collected with a handheld gripper (UMI) to train generalizable visuomotor policies. A central challenge in transferring these policies to constrained robotic embodiments-such as aerial manipulators-is the mismatch in control and robot dynamics, which often leads to out-of-distribution behaviors and poor execution. To address this, we propose Embodiment-Aware Diffusion Policy (EADP), which couples a high-level UMI policy with a low-level embodiment-specific controller at inference time. By integrating gradient feedback from the controller's tracking cost into the diffusion sampling process, our method steers trajectory generation towards dynamically feasible modes tailored to the deployment embodiment. This enables plug-and-play, embodiment-aware trajectory adaptation at test time. We validate our approach on multiple long-horizon and high-precision aerial manipulation tasks, showing improved success rates, efficiency, and robustness under disturbances compared to unguided diffusion baselines. Finally, we demonstrate deployment in previously unseen environments, using UMI demonstrations collected in the wild, highlighting a practical pathway for scaling generalizable manipulation skills across diverse-and even highly constrained-embodiments. All code, data, and checkpoints will be publicly released after acceptance. Result videos can be found at umi-on-air.github.io.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to use their “hands” in the real world, even if their bodies are very different. The authors focus on aerial robots (flying drones with a small arm and gripper) that can pick things up or press things while flying. They use a simple handheld tool called UMI (Universal Manipulation Interface) to let people show robots what to do. Then they add a smart way to adjust those learned actions so different robots—especially flying ones—can actually perform them safely and reliably.
What questions did the researchers try to answer?
The paper asks:
- How can we train a general “see and move” policy from human demonstrations that works across many robot types (“embodiments”)?
- Why do some robots fail to follow those learned actions, and how can we fix that without retraining?
- Can we make aerial robots complete precise and long tasks in messy, real-world environments using this approach?
How did they do it?
To make this work, the team combined a simple way to collect demonstrations with a smart guidance system during robot execution. Here’s the idea in everyday terms:
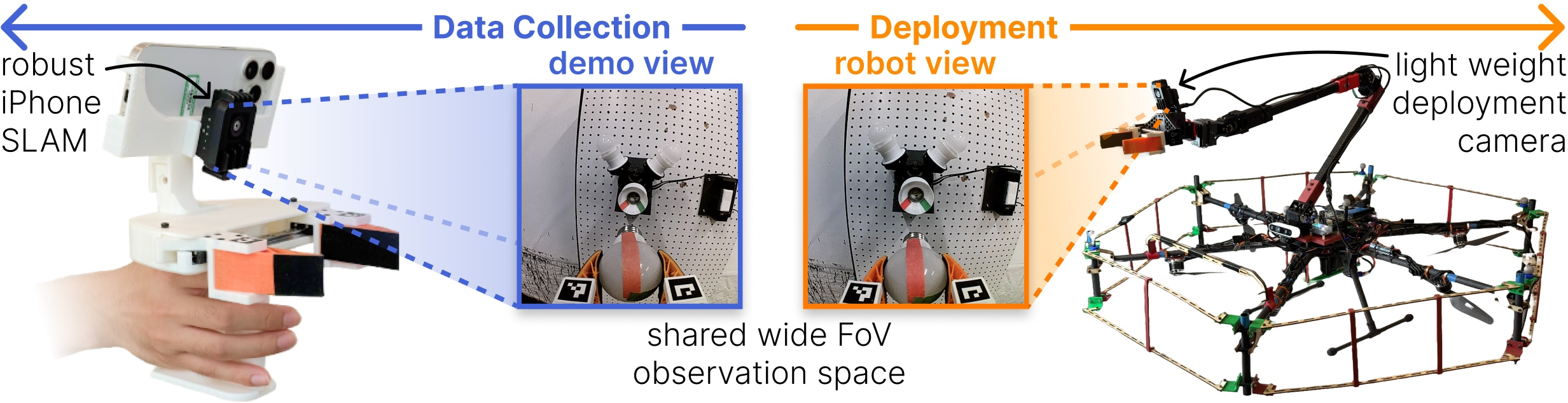
Collecting demonstrations with UMI (the handheld gripper)
- A person uses a small handheld gripper with a camera attached (like a robot’s “hand + eyes”).
- As they complete tasks (like picking up a lemon or inserting a peg), the system records what they see and how the gripper moves.
- This creates a dataset of “what the camera saw” and “how the hand moved” over time—perfect for teaching a robot.
They made three practical tweaks for flying robots:
- A lighter camera (so the drone doesn’t carry too much weight).
- Smaller gripper fingers (less inertia, easier to control in the air).
- Better tracking using an iPhone’s visual-inertial SLAM (so the hand’s position is recorded accurately).
Training a “diffusion policy” (turning images into action sequences)
- A “visuomotor policy” is a rule that maps camera images to movements.
- They use a diffusion model to learn these rules. Think of diffusion like starting with noisy, blurry ideas for what to do, and then gradually “denoising” them into a clean, detailed plan of actions.
- This policy predicts a future sequence of hand (end-effector) positions and gripper openings.
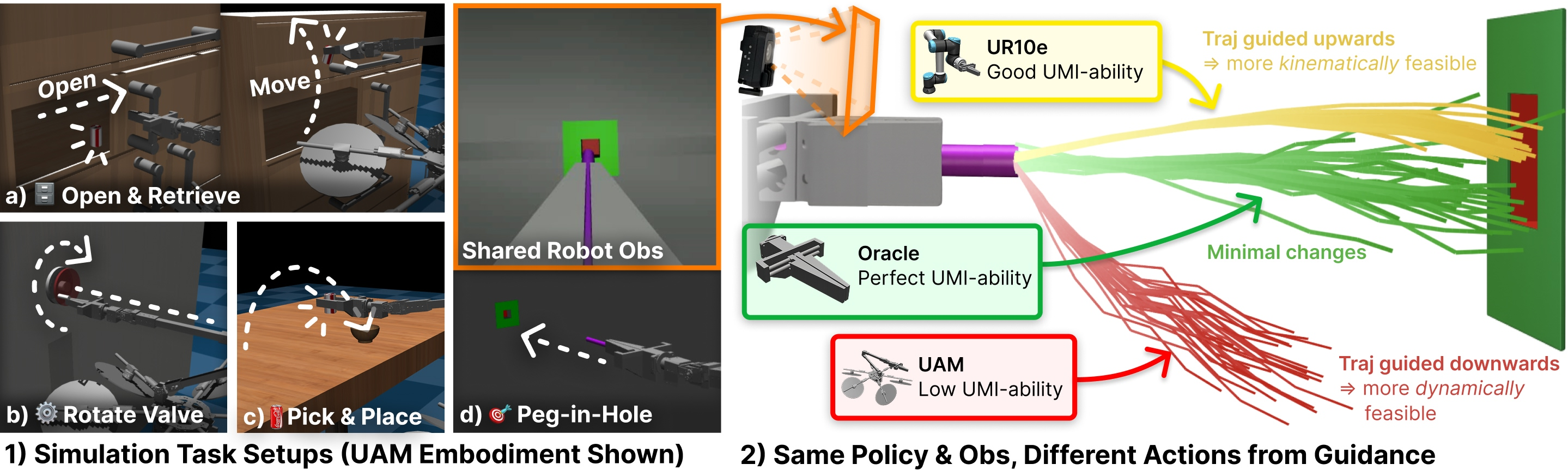
Making different robot bodies succeed (Embodiment-Aware Guidance)
Different robot bodies (embodiments) have different limits. A table robot arm can stop quickly and move precisely. A flying drone is affected by wind, momentum, and stability. So a plan that looks good for a handheld gripper might be risky or impossible for a drone.
The authors add a “two-way communication” step during execution:
- The high-level policy proposes a trajectory (a path for the robot’s hand).
- A low-level controller (which knows the robot’s physical limits) checks how hard this trajectory would be to follow. This is measured as a “tracking cost” (low cost = easy/safer to follow; high cost = hard/unsafe).
- The controller then sends back advice (a “gradient”) telling the policy how to nudge the trajectory toward something more feasible for this specific robot.
- The policy adjusts its plan step-by-step, making it more suitable for the current robot.
Analogy: Imagine giving driving directions. If you’re guiding a bicycle, you might take narrow paths. If you’re guiding a truck, you stick to wide roads. Here, the controller is like a coach saying, “That turn is too sharp for a truck—choose a gentler curve.” The policy listens and updates the route.
Controllers used (simple and advanced)
To translate hand trajectories into robot motions, they use:
- Inverse Kinematics (IK) with speed limits: good for normal robot arms. It maps desired hand poses into joint angles while respecting how fast the joints can move.
- Model Predictive Control (MPC): a more advanced controller for drones. It plans ahead over a short time horizon, considering forces, torques, and stability, so the drone and its arm move smoothly and safely.
The key is that these controllers compute a tracking cost and its gradient, which are used to guide the diffusion policy’s sampling process toward feasible actions—without retraining the policy.
What did they find?
The authors tested their approach in both simulation and the real world.
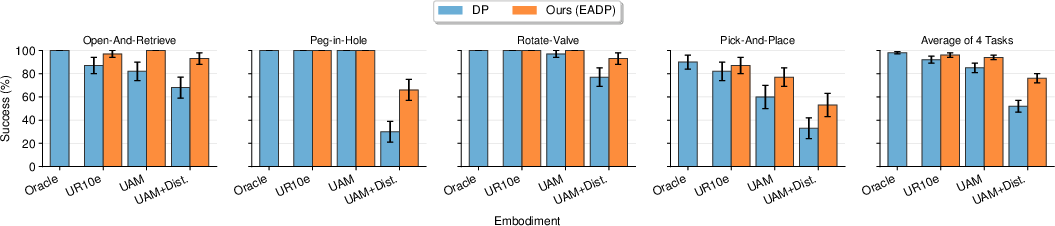
In simulation:
- They trained the policy from human UMI demonstrations and deployed it on:
- An “Oracle” flying gripper (perfect tracker, no limits) to set the upper bound.
- A UR10e robot arm (typical lab manipulator).
- A real-like Aerial Manipulator (UAM), both with and without disturbances (small base movement errors like those seen on hardware).
- Tasks included long and precise actions: opening a cabinet and placing a can, peg-in-hole, rotating a valve, and pick-and-place.
- Result: Embodiment-Aware Diffusion Policy (EADP) consistently beat the baseline (unguided diffusion). Gains were small on easy embodiments (the UR10e) but large on the drone, especially under disturbances—often recovering 9–20% in average success rates on tougher setups.
In the real world (on a fully actuated hexarotor drone with a 4-DoF arm and gripper):
- Peg-in-hole: EADP succeeded in all trials (5/5), avoiding issues like dropping the peg or missing the hole.
- Lemon harvesting (pick-and-place): 4/5 successes; one failure was choosing an unripe lemon (vision/selection issue), not manipulation failure.
- Light bulb insertion: 3/3 successes on a long, multi-minute task that needs stability and precision.
- Generalization to new environments: On peg-in-hole in different settings, EADP succeeded in 4/5 trials, showing it can handle changes without retraining.
Why is this important?
- It shows that human demonstrations collected with a simple handheld tool can scale to challenging robots (like drones) when paired with embodiment-aware guidance.
- It reduces failures caused by physical limits (like dynamics and control saturation) by adapting trajectories on the fly.
What’s the impact?
This research is a step toward making learned manipulation skills “plug-and-play” across many robots:
- It lowers the cost and risk of data collection by using a handheld UMI rather than expensive or fragile robots.
- It avoids retraining for each new robot—controllers inject robot-specific limits during execution.
- It boosts reliability for difficult robots (like aerial manipulators) and enables long, precise tasks in real-world settings.
In simple terms: teach once with a human-held tool, and then let each robot body “coach” the plan as it runs, so it performs safely and well. This could help robots do useful work in places that are hard for humans to reach—like inspecting tall structures, harvesting fruit, or performing repairs—while keeping training simple and scalable.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The following points summarize what remains missing, uncertain, or unexplored in the paper. They are phrased to be concrete and actionable for future research.
- Formalizing “UMI-ability”: The paper uses the Oracle–DP performance gap as a proxy, but lacks a formal, task-agnostic metric (e.g., normalized feasibility index incorporating controller limits, dynamics, and disturbance profiles) and standardized benchmark to compare embodiments.
- Guidance for black-box controllers: EADP assumes access to a differentiable tracking cost. Many real controllers (industrial, safety-certified, learned) are non-differentiable or opaque. Methods for gradient-free guidance (e.g., score estimation, finite differences, REINFORCE-style estimators) or learned surrogate costs remain unexplored.
- Coverage of embodiment diversity: Validation is limited to a fixed-base arm (UR10e) and a fully actuated hexarotor. Generalization to underactuated UAVs (standard quadrotors), soft aerial manipulators, mobile bases, humanoids, and robots with different kinematic/topological constraints is not studied.
- Onboard perception dependence: Real-world deployment relies on motion capture for drone state; robustness with only onboard sensing (VIO, IMU, RGB/Depth) and no external tracking is not evaluated, especially under fast motion, occlusions, motion blur, and poor lighting.
- Safety and hard-constraint handling: The tracking cost guides position/orientation errors but does not encode hard constraints (collision avoidance, joint/torque limits, forbidden regions, contact stability, force/torque bounds). Integrating barrier functions, signed-distance fields, or constraint-aware guidance is an open problem.
- Force/contact modeling: Tasks like peg-in-hole and lightbulb insertion involve contact mechanics; the guidance and cost ignore contact and force profiles. Extending EADP to include contact dynamics, compliance, and force objectives (or tactile feedback) is unaddressed.
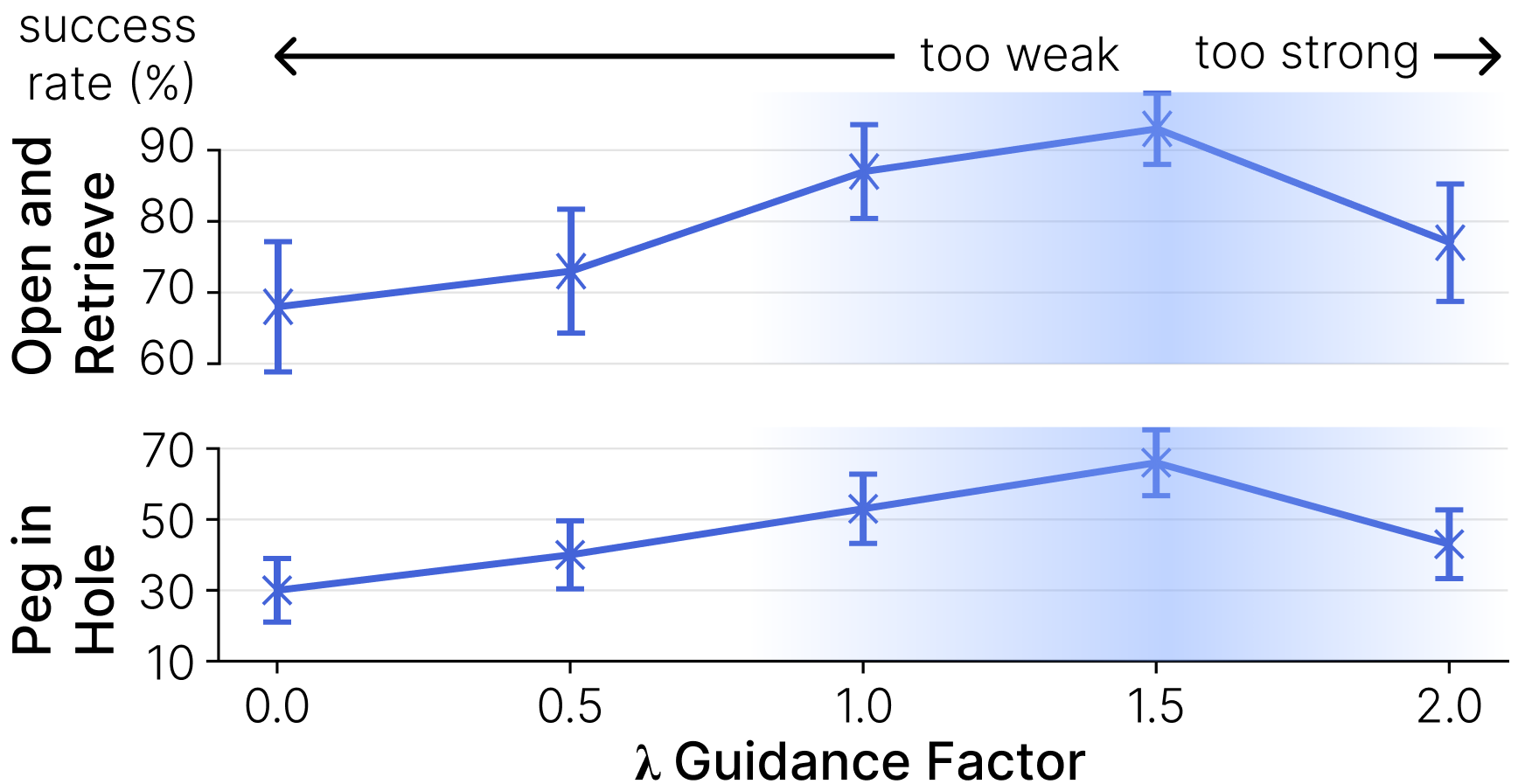
- Guidance hyperparameter tuning: Success depends on guidance scale λ and scheduling; there is no principled, adaptive tuning across tasks/embodiments or auto-selection strategies (e.g., dual control, Bayesian optimization, risk-sensitive tuning).
- Rate mismatch and latency: Policy runs at 1–2 Hz while control runs at 50 Hz. The impact on stability, delay-induced errors, and responsiveness under disturbances is not quantified. Streaming diffusion, incremental sampling, or receding-horizon denoising remain open directions.
- Computational footprint: The paper does not report end-to-end inference time (diffusion denoising + guidance + controller solve), compute budgets, or scalability to embedded platforms. Profiling, acceleration (distillation, fewer steps), and compute–performance trade-offs are missing.
- Differentiating through MPC: The “tracking cost” for MPC appears as a quadratic error on references; gradients may not reflect solver outcomes, active constraints, saturations, or dynamics coupling. Differentiable MPC, adjoint-based sensitivity, or implicit gradients through the solver are not explored.
- Robustness to real disturbances: Simulated disturbances (≈3 cm base noise) underrepresent wind, contact shocks, vibrations, and sensor drift. Stress tests with stronger, time-varying disturbances, gusts, and contact-intense tasks are absent.
- Sample size and statistical rigor: Real-world trials are few (3–5 per task), without confidence intervals, statistical tests, or failure taxonomy. Larger-scale evaluation and consistent metrics across varied environments are needed.
- Dataset scale and composition: The size, diversity, and quality of UMI demonstrations (noise levels, environments, operators) are not detailed. Data curation, augmentation, and the impact of dataset scale on generalization are unexplored.
- Domain gap bridging: The paper replicates camera–gripper configuration but does not address visual domain shifts (UMI-to-robot optics, FOV, latency, motion blur). Techniques like domain adaptation, augmentation, or visual servoing integration are not evaluated.
- Semantic decision-making: The lemon harvesting failure (selecting an unripe fruit) indicates limited semantic reasoning. Integrating object detection/segmentation, attribute recognition (ripeness), or task-aware perception modules is open.
- Multi-modality preservation: Guidance may collapse policy multi-modality or bias toward conservative modes. Measuring and controlling diversity (e.g., entropy, coverage of modes) while maintaining feasibility is not addressed.
- Long-horizon planning: The system produces short-horizon EE trajectories tracked by MPC; global planning for large workspace repositioning, waypoints, and memory of partially observable states is not integrated.
- Continual/test-time adaptation: EADP provides inference-time guidance but does not update the policy/controller from runtime feedback. Methods for online finetuning, meta-learning, or adaptive control using guidance signals remain unexplored.
- Controller weight selection: MPC/IK cost weights (Q matrices, velocity bounds) are hand-tuned. Automatic weight tuning, meta-optimization, task-conditioned weighting, or learning controller preferences from data are not studied.
- Constraint feasibility vs. performance trade-offs: There is no formal analysis of how guidance affects task completion vs. feasibility (e.g., Pareto frontier), nor mechanisms to balance precision vs. speed vs. energy consumption.
- Hard contacts and compliance: Real-world aerial tasks often need compliant control at contact (force tracking, impedance). Extending EADP to impedance/force controllers and encoding compliance objectives in guidance is an open question.
- Generalization to novel tasks: The benchmark covers four simulated tasks and three real tasks; transfer to materially different skills (scraping, cutting, drilling, assembly) and objects with varied dynamics (deformable, fragile) is untested.
- Alternative guidance forms: Beyond gradient guidance, constraint-satisfying generative sampling (e.g., projection, barrier guidance, control-limited samplers, safe set filters) and hybrid planners (sampling + MPC) are not compared.
- Failure analysis and recovery: The paper notes jamming and overshoot failures but lacks systematic failure mode analysis, diagnostics, and recovery strategies (re-planning, dwell, compliance increase, adaptive timing).
- Embodiment-aware training: EADP adds embodiment awareness only at inference. Whether modest embodiment-conditioned training (e.g., morphology embeddings, controller-informed augmentation) could reduce reliance on heavy guidance is an open avenue.
- Evaluation without external tracking: Cross-environment peg-in-hole still used motion capture for state. A fully “in-the-wild” deployment (unstructured lighting, wind, no MoCap, onboard pose estimation) remains to be demonstrated.
- Code/data reproducibility: Code, data, and checkpoints are promised post-acceptance; reproducibility, ablation details (H, network size, denoising steps), sensor calibration pipelines, and controller parameters are presently unavailable.
Practical Applications
Practical Applications Derived from “UMI-on-Air: Embodiment-Aware Guidance for Embodiment-Agnostic Visuomotor Policies”
Below, we translate the paper’s findings and methods into concrete applications. Each item lists likely sectors, candidate tools/workflows, and key assumptions or dependencies affecting feasibility.
Immediate Applications
- Cross-embodiment deployment of existing manipulation policies (plug-and-play)
- Sectors: robotics, manufacturing, logistics, R&D labs
- Tools/Workflows: EADP as a ROS2 middleware layer that wraps a diffusion policy and a robot-specific controller (IK or MPC); “controller-guided diffusion” node exposing a tracking cost, gradients, and a guidance scale; calibration tools for aligning UMI camera–EE frames across robots
- Assumptions/Dependencies: access to a differentiable or differentiable-approximate tracking cost from the low-level controller; stable state estimation; GPU for inference; consistent EE-centric action representation between UMI demos and target robot
- Aerial pick-and-place in controlled settings (e.g., harvesting prototypes, binning)
- Sectors: agriculture, warehousing, facility operations
- Tools/Workflows: UMI-based data collection in orchards or indoor warehouses; trained diffusion policy + EADP guidance on a fully actuated hexarotor with MPC; perception for object detection (e.g., ripeness classification)
- Assumptions/Dependencies: reliable localization (mocap/VIO), manageable wind/airflow; safe flight envelopes; gripper suitable for the target objects; adequate onboard compute or low-latency offboard link
- Precision contact tasks with aerial manipulators (threading, insertion, flipping switches)
- Sectors: utilities, facility maintenance, light assembly
- Tools/Workflows: EE-centric MPC with tracking cost integrated into policy sampling; “task packs” for peg-in-hole and lightbulb installation; force-aware end-effectors where applicable
- Assumptions/Dependencies: contact-safe control gains, tuned MPC weights; accurate pose estimation; tight camera–EE extrinsic calibration; obstacle maps for collision margins
- Robust autonomy layer for teleoperation and shared control
- Sectors: industrial robotics, inspection/maintenance, defense
- Tools/Workflows: operator sends high-level intents; EADP reshapes policy trajectories to controller-feasible modes before execution (reduces crashes/saturation); UI slider for guidance scale λ
- Assumptions/Dependencies: near-real-time gradient computation; stable comms; operator training on guidance–performance trade-offs
- Retrofitting tabletop and mobile arms to be “more UMI-able”
- Sectors: manufacturing, research labs, integrators
- Tools/Workflows: IK-with-velocity-limits controller exposes tracking cost to EADP; improved recovery near kinematic limits and singularities; drop-in to existing BC/diffusion stacks
- Assumptions/Dependencies: reliable IK and FK; joint velocity/acceleration bounds exposed; sufficient training demos covering local task variance
- Low-cost data pipeline for generalizable skills
- Sectors: robotics startups, academia, internal R&D
- Tools/Workflows: handheld UMI kits (OAK-1 W camera, light gripper, iPhone SLAM) for in-the-wild demonstrations; synchronized image–EE trajectory logging; model training scripts and checkpoints
- Assumptions/Dependencies: demo quality and coverage; consistent EE camera placement at deployment; domain shifts manageable via EADP guidance
- Benchmarking embodiment gaps and controller design choices
- Sectors: academia, OEMs, system integrators
- Tools/Workflows: released MuJoCo benchmark suite and metrics (UMI-ability characterization); ablations over λ (guidance scale), controller fidelity (IK vs MPC), and disturbance models
- Assumptions/Dependencies: simulator–reality gap awareness; standardized action/observation interfaces in tests
- Runtime safety filtering via tracking-cost thresholds
- Sectors: robotics safety, QA, deployment engineering
- Tools/Workflows: use L_track as a gating signal to reject or re-sample infeasible trajectories; logging policy for post-mortems; fallback policies when L_track > τ
- Assumptions/Dependencies: calibrated cost-to-risk mapping; conservative thresholds to avoid unsafe execution; controller stability guarantees
- Education and training modules for controller-in-the-loop learning
- Sectors: education, workforce development
- Tools/Workflows: course labs combining diffusion policies with IK/MPC controllers and two-way guidance; assignments on embodiment-gap analysis
- Assumptions/Dependencies: access to low-cost arms/UAVs or high-fidelity simulation; GPU resources
- Internal policy guidance for safe aerial manipulation in facilities
- Sectors: corporate facilities, universities, test ranges
- Tools/Workflows: site-specific SOPs that mandate controller-guided trajectory generation and environment instrumentation; risk assessments using L_track statistics
- Assumptions/Dependencies: restricted and controlled airspace; trained operators; documented safety envelopes
Long-Term Applications
- Field-grade aerial maintenance and repair at scale
- Sectors: energy (wind/solar/powerlines), transportation (bridges), heavy industry
- Tools/Workflows: fleets of UAMs executing assembly/repair routines (e.g., torqueing, screwing, valve turning) guided by EADP; online perception and force sensing; autonomous mission planner
- Assumptions/Dependencies: robust on-device SLAM in GPS-denied scenarios; environmental robustness (wind, rain, EMI); regulatory approvals and safety certification
- Universal manipulation services across heterogeneous robot fleets
- Sectors: robotics-as-a-service, OEMs, integrators
- Tools/Workflows: cloud or edge platform hosting “embodiment-agnostic skills” with controller-specific adapters; per-robot EADP plugins providing gradients; standardized EE-centric APIs
- Assumptions/Dependencies: cross-vendor standardization of EE action spaces; secure, low-latency networking; lifecycle management for models and controllers
- Controller-in-the-loop foundation models for manipulation
- Sectors: software, robotics, AI platforms
- Tools/Workflows: pretraining on massive UMI datasets; inference-time and possibly training-time incorporation of controller gradients; multi-embodiment conditioning tokens
- Assumptions/Dependencies: large, diverse datasets; compute scale; careful handling of non-differentiable controllers (surrogates or implicit differentiation)
- Household or commercial service drones for high-reach tasks
- Sectors: daily life, hospitality, retail
- Tools/Workflows: lightbulb replacement, sign changes, inventory tags, ceiling cleaning; human-in-the-loop approvals with EADP safety guidance
- Assumptions/Dependencies: quiet and safe flight systems; reliable onboard perception; strict safety/insurance compliance; human factors and UX
- Disaster response and hazardous environment manipulation
- Sectors: public safety, defense, environmental monitoring
- Tools/Workflows: UAMs performing search-and-access (opening doors/hatches), sampling, valve adjustments; EADP ensures feasible plans under degraded sensing
- Assumptions/Dependencies: resilient comms; ruggedized hardware; training for unstructured environments; liability and governance frameworks
- Hospital and lab facility maintenance with minimal disruption
- Sectors: healthcare, biotech
- Tools/Workflows: non-contact inspections, simple manipulations (switch toggling, filter replacements) after-hours; EADP-guided trajectories to respect strict safety bounds
- Assumptions/Dependencies: stringent privacy and safety requirements; infection control; verified reliability around sensitive equipment
- Streaming/online guidance at control rate
- Sectors: robotics platforms, embedded AI
- Tools/Workflows: streaming diffusion or continuous-time policy sampling with real-time gradient guidance at 50–100 Hz; hardware acceleration on Jetson/Edge TPUs
- Assumptions/Dependencies: efficient models and schedulers; tight integration with controller timing; thermal/power budgets
- Regulatory and certification frameworks anchored in feasibility metrics
- Sectors: policy, insurance, standards bodies
- Tools/Workflows: adoption of L_track-derived metrics in conformance tests; standardized logs and test protocols for “controller-feasible” autonomy; incident analysis linked to feasibility traces
- Assumptions/Dependencies: consensus on metrics and thresholds; access to telemetry; third-party auditing
- Cross-embodiment data standards and ethical data collection in public spaces
- Sectors: policy, academia-industry consortia
- Tools/Workflows: shared schemas for EE-centric observations/actions; privacy-preserving demo capture (on-device anonymization); dataset licensing norms
- Assumptions/Dependencies: multi-stakeholder coordination; legal frameworks for public data capture
- Marketplace for “task packs” (skills + controllers + configs)
- Sectors: robotics ecosystems, app stores for robots
- Tools/Workflows: downloadable UMI-trained skills bundled with EADP profiles per robot (UR arms, mobile bases, UAMs); deployment wizard to tune λ and controller weights
- Assumptions/Dependencies: long-tail device support; QA/certification; revenue and support models for updates and safety patches
These applications hinge on core assumptions highlighted by the paper: the availability of an EE-centric control interface; the ability to compute or approximate gradients of a tracking cost; reliable perception and state estimation; and alignment between training-time UMI configurations and deployment-time robot setups. As controller-guided diffusion matures (e.g., streaming inference, learned controllers, richer sensors), the set of feasible and safe deployments will expand from controlled environments to complex, real-world operations.
Glossary
- Actuation bounds: Limits on the allowable range of control inputs in an optimization-based controller. "and $\bm{u}_{\text{lb}, \bm{u}_{\text{ub}$ the actuation bounds."
- Aerodynamic disturbances: External airflow-induced forces and torques that destabilize aerial robots. "stability under aerodynamic disturbances"
- Classifier guidance: A diffusion-model technique where gradients from a classifier steer sampling toward desired modes; used analogously with controller cost. "steering the denoising process akin to classifier guidance."
- DDIM (Denoising Diffusion Implicit Models): A deterministic, fast sampling procedure for diffusion models. "We use the standard DDIM update step"
- Degrees of Freedom (DoF): The number of independent coordinates that define a system’s configuration. "6-DoF EE pose"
- Diffusion Policy (DP): A visuomotor control policy that generates actions by iterative denoising in a diffusion model. "embodiment-agnostic Diffusion Policy (DP)"
- Egocentric: First-person viewpoint aligned with the sensor/end-effector frame. "synchronized egocentric RGB images"
- Embodiment gap: The mismatch between policy-generated trajectories and the physical/control constraints of a target robot. "investigation of the embodiment gap"
- Embodiment-Aware Diffusion Policy (EADP): A method that integrates controller gradients into diffusion sampling to make action trajectories feasible for a specific robot. "We propose Embodiment-Aware Diffusion Policy (EADP)"
- End-effector (EE): The tool or gripper at the tip of a manipulator that interacts with the environment. "producing end-effector (EE) trajectories"
- End-effector–centric: A control/design perspective where references and control are expressed in the end-effector frame. "We adopt an EE–centric perspective"
- Finite-horizon: Refers to optimization over a fixed time window in predictive control. "optimizing a finite-horizon cost function"
- Forward kinematics (FK): Mapping robot joint angles to the corresponding end-effector pose. "The forward kinematics $\bm{f}_{\text{FK}(\bm{q})$ reconstructs the trajectory waypoint"
- Graph Neural Networks (GNNs): Neural architectures operating on graph-structured data, used to model robot morphology. "Embodiment-aware policies leveraged graph neural networks (GNNs)"
- Hexarotor: A multirotor aerial vehicle with six rotors; here fully actuated for 6D wrench control. "which is a fully-actuated hexarotor"
- Inverse Kinematics (IK): Computing joint configurations that achieve a desired end-effector pose. "Inverse Kinematics with Velocity Limits"
- Kinematic singularities: Configurations where the manipulator’s Jacobian loses rank, causing poor or undefined motion. "avoiding kinematic singularities."
- Model Predictive Controller (MPC): An optimization-based controller that plans control inputs over a horizon subject to dynamics and constraints. "Model Predictive Controller"
- MuJoCo: A physics engine for accurate, efficient robot simulation. "construct a controlled simulation benchmark in MuJoCo."
- Multi-modality: The presence of multiple plausible action modes in a learned policy’s output distribution. "By leveraging the multi-modality of UMI policies"
- Out-of-distribution (OOD): Data or behaviors that deviate from the distribution seen during training. "pushing trajectories out-of-distribution (OOD)."
- Runge–Kutta scheme: A numerical integration method; the fourth-order variant is common for stable discretization. "using a fourth-order Runge–Kutta scheme for stability."
- SLAM: Simultaneous Localization and Mapping; here visual–inertial SLAM estimates 6D pose from camera and IMU. "visual–inertial SLAM system"
- SO(3): The Lie group of 3D rotation matrices. "orientations "
- Tracking cost: A metric quantifying how well a controller can follow a reference trajectory. "The MPC exposes a tracking cost $L_{\text{track}$"
- UNet: A convolutional encoder–decoder with skip connections, used here for conditional diffusion policies. "A conditional UNet-based~\cite{ronneberger2015u} diffusion policy"
- Universal Manipulation Interface (UMI): A handheld demonstration device that enables embodiment-agnostic policy training. "Universal Manipulation Interface (UMI)"
- Unmanned Aerial Manipulators (UAMs): Aerial robots equipped with manipulators for interaction tasks. "unmanned aerial manipulators (UAMs) hold particular promise."
- Vee-operator: A map from a 3×3 skew-symmetric matrix in so(3) to its 3D vector representation. "the vee-operator that maps a skew-symmetric matrix to "
- Visuomotor policies: Policies that map visual observations to motor actions for control. "visuomotor policies"
- Wrench: A 6D vector of forces and torques applied by the controller. "commanded wrench (forces and torques)"
- Whole-body MPC: MPC that jointly optimizes the motion of the UAV base and the manipulator. "EE–centric whole-body MPC"
Collections
Sign up for free to add this paper to one or more collections.

