- The paper proposes an adaptive conformal prediction framework that dynamically calibrates LLM outputs for improved factuality.
- It leverages embedding-conditioned quantile regression and selective filtering to achieve robust conditional coverage in both long-form and multi-choice QA.
- Empirical evaluations demonstrate enhanced PR-AUC and consistent coverage across models, ensuring reliable performance in risk-sensitive applications.
Motivation and Background
LLMs exhibit significant proficiency over heterogeneous domains but remain prone to producing factually incorrect outputs. In high-risk applications, the reliability and factuality of LLM generations are paramount. Conformal prediction provides distribution-free coverage guarantees, supporting selective prediction through calibrated uncertainty thresholds. However, legacy conformal approaches apply a uniform calibration across all prompts, disregarding prompt-specific complexity and ambiguity, which substantially impairs conditional coverage. These methods often yield either over-coverage or under-coverage in category-tail distributions, causing inconsistent reliability across prompts.
The paper addresses the above limitation by proposing a prompt-adaptive conformal prediction framework for LLMs. This method leverages embedding-conditioned quantile regression to learn input-dependent score calibrations. The architecture decomposes the calibration pipeline into three stages: conditional quantile regression using prompt embeddings, calibration of transformed scores, and selective filtering at inference. For long-form and multi-choice QA, output atomicity (claims or candidate classes) enables fine-grained factuality quantification.
The process is formally defined as follows. For long-form QA, claim-level uncertainty scores s(c) are evaluated, and factuality is assessed via a binary oracle function w(c,y). The nonconformity score V(x,y) is the maximal threshold ensuring all retained claims are factually correct. For multiple-choice QA, nonconformity is computed using the Least Ambiguous Classifier (LAC) score: V(x,y)=1−[p(x)]y. The adaptive method normalizes scores by division with conditional quantiles τ^(x) inferred from prompt embeddings, preserving marginal guarantees while improving conditional coverage. The theoretical proof establishes finite-sample coverage bounds under exchangeability and strict compatibility conditions.
Empirical Evaluation
The experimental suite utilizes Mistral-7B-Instruct-v0.2, Llama-3.1-8B-Instruct, and Gemma-3-12B-Instruct models. Prompt embeddings are extracted with multi-qa-mpnet-base-dot-v1, subsequently reduced via PCA. The data is partitioned for quantile learning, calibration, and testing, with all experiments repeated over multiple seeds for statistical robustness.
A series of experiments demonstrate the efficacy of the adaptive approach in both long-form and multi-choice QA settings. In long-form QA, adaptive calibration produces empirical coverage closely aligned with target conditional coverage for each semantic category, mitigating the disparities induced by global thresholding.
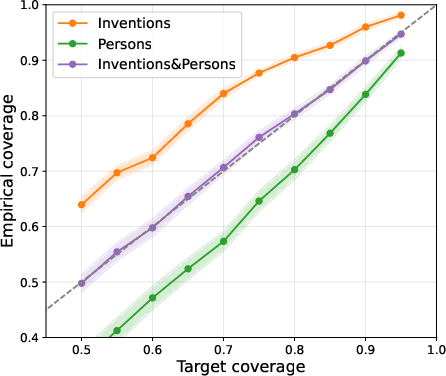
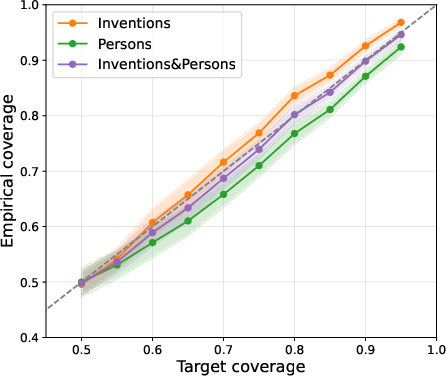
Figure 1: Marginal versus conditional coverage on long-form QA; the adaptive conformal method achieves conditional coverage alignment across heterogeneous prompt categories.
The adaptive method consistently yields improved PR-AUC for claim filtering, with Claim Conditioned Probability outperforming other uncertainty quantification techniques. In multi-choice QA, adaptive calibration resolves category-level misalignment, as evidenced by empirical coverage curves and Dolan-Moré performance profiles.
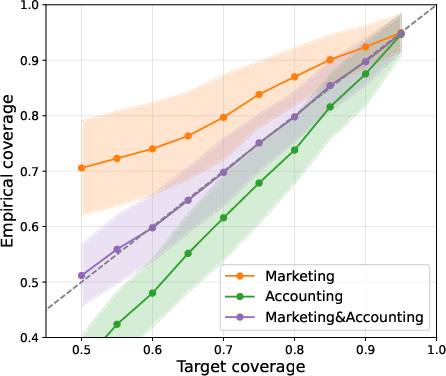
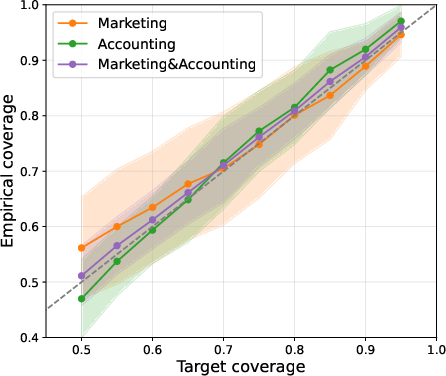
Figure 2: Multi-choice QA: empirical coverage per prompt category for conformal factuality and the adaptive approach.
Moreover, adaptive calibration reduces the fraction of removed items while retaining factuality, achieving optimal trade-offs for selective prediction. T-SNE PCA visualization of prompt embeddings highlights the semantic separation leveraged in the quantile regression phase, further supporting the adaptivity capability.
Figure 3: t-SNE visualization of PCA clustering of long-form QA prompts, demonstrating clear semantic separation leveraged by adaptive calibration.
Theoretical and Practical Implications
The adaptive conformal prediction paradigm introduces prompt-level calibration, moving beyond static global thresholding to statistically rigorous, input-sensitive filtering. The practical outcome is improved claim validation and more consistent reliability across diverse tasks, enabling robust abstention and better coverage trade-offs. The theoretical coverage bounds remain valid under strict exchangeability, and compatibility assumptions, with adaptive normalization mitigating group-wise miscalibration.
This approach is extensible to broader generative tasks, including structured reasoning, document-level summarization, and domain-adaptive filtering. Future directions include enhancing input representations with richer embeddings or fusion strategies, scaling conditional quantile estimation to larger datasets, and further strengthening theoretical validity under distribution shift.
Conclusion
Adaptive conformal prediction as introduced in this paper enables prompt-dependent calibration for LLM factuality assessment, significantly improving conditional coverage while preserving marginal guarantees. Empirical results validate the method's superiority across multiple models and domains. The framework, grounded in embedding-conditioned quantile regression, addresses longstanding calibration deficiencies, and provides a tractable path forward for reliable LLM deployment in risk-sensitive applications. Future research will focus on broadening applicability, optimizing input representations, and refining theoretical underpinnings.

