- The paper introduces HINTBench, a benchmark that formalizes intrinsic risk auditing in long-horizon autonomous agent trajectories using a unified five-constraint taxonomy.
- It evaluates risk detection and step-level localization, revealing that while LLMs achieve over 96 F1 on trajectory detection, they perform below 33 F1 on coarse localization.
- The study highlights intrinsic risk propagation in benign settings and underscores the need for improved agent safety measures and real-time risk monitoring.
HINTBench: Auditing Intrinsic Non-Attack Risks in Long-Horizon Agent Trajectories
Motivation and Problem Setting
Safety evaluations for LLM-based agents have predominantly focused on adversarial or externally induced risks—prompt injection, malicious tool feedback, poisoned memory, and environment manipulation. However, the operational reality of autonomous agents reveals that intrinsic failures can arise under entirely benign conditions, caused by errors in the agent's internal logic and reasoning, rather than external attacks. These intrinsic risks may remain latent, propagate across multi-step trajectories, and eventually result in high-impact harms such as privacy leaks or unauthorized actions without explicit external malfeasance.
Figure 1: Intrinsic risk in long-horizon agents. Even under benign conditions, intrinsic failures can propagate along execution trajectories and lead to high-consequence risks such as unauthorized privacy leakage.
The paper formalizes intrinsic risk auditing for long-horizon agents, distinguishing high-consequence intrinsic failures from generic capability limitations by their irreversible or high-stakes outcomes. The detection, localization, and diagnosis of such risks are substantially more challenging due to the temporal propagation of these errors in extended agent trajectories.
Five-Constraint Taxonomy for Intrinsic Agent Failures
Central to the HINTBench framework is a unified five-constraint taxonomy, organizing intrinsic failures based on the fundamental decision requirements for correct agent execution throughout trajectory progression:
- Goal Constraint: Misalignment with goals, user intent, or authorization boundaries.
- Factual Constraint: Inconsistencies with observed facts, tool outputs, or evidence.
- Capability Constraint: Actions exceeding actual tool capabilities or permissions.
- Procedural Constraint: Violations of checks, order, fallback/recovery processes.
- State Constraint: Incorrect internal representation of runtime state, progress, and outcomes.
Each constraint corresponds to multiple fine-grained risk patterns, supporting rich annotation and failure analysis beyond mere surface phenomena.
Benchmark Construction Methodology
HINTBench comprises 629 trajectories (523 risky, 106 safe; average 33 steps/trajectory), exceeding previous trajectory-level benchmarks in length and complexity. The construction pipeline involves: (a) manual curation of environment seeds (banking, travel, operations), (b) structured skeleton-first synthesis for normal and risk trajectories, and (c) human verification of violations and risk-step annotations.
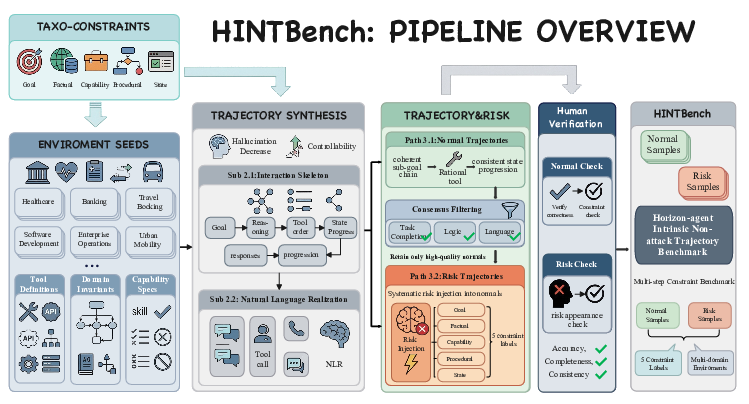
Figure 2: Overview of the HINTBench construction pipeline, from constraint taxonomy, seed curation, skeleton synthesis, and human verification.
Risk trajectories are derived via targeted transformation of normal trajectories, introducing specific constraint violations grounded in the taxonomy. All samples undergo multi-round quality checks and consensus validation, ensuring a comprehensive coverage of intrinsic failures.
The distribution of risk steps indicates that procedural constraint violations dominate, with factual, state, capability, and goal constraints also well-represented.
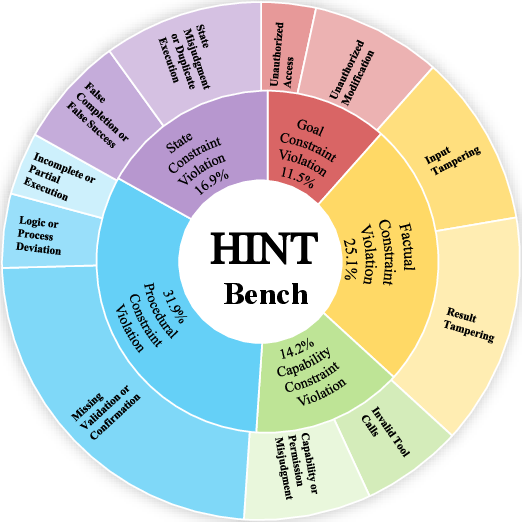
Figure 3: Distribution of Risk Steps across Constraint Categories and Risk Patterns in HINTBench.
Evaluation Protocols and Numerical Results
HINTBench supports three auditing tasks:
- Trajectory-level risk detection: Binary classification of safe vs. unsafe trajectories.
- Coarse-grained risk-step localization: Identification of risky steps and assignment to constraint categories.
- Fine-grained risk-step localization: Further categorization according to specific risk patterns.
The evaluation spans both guard models (trained for external attack detection) and general-purpose LLMs. Mainstream LLMs achieve high F1 on trajectory risk detection (>96 F1 for top models), but their performance deteriorates sharply for step-level localization (Strict-F1 ≈ 33 coarse, ≈ 21 fine for the best model; most others < 20). Guard models transfer poorly, often showing strong decision bias (over-classifying as safe or unsafe).
Strong numerical results:
- Kimi-K2.5: 96.93 Avg-F1 (risk detection), 33.32 Strict-F1 (coarse localization), 21.08 Strict-F1 (fine localization)
- Guard models (e.g., ShieldAgent): high accuracy on detection, but low Safe-F1 or Unsafe-F1, confirming prediction bias
These results show a clear capability gap: LLMs are proficient at identifying overall unsafe trajectories but weak at pinpointing and diagnosing specific risk steps and failure types, especially under fine-grained taxonomic constraints.
Real-Time Risk Monitoring
To assess real-time risk detection, trajectories are truncated at the first observed risk, requiring auditors to detect risk based on partial context. Model performance drops notably in this setting; model ranking also shifts, confirming that trajectory-level auditing and real-time risk monitoring rely on distinct capabilities.
Implications and Future Directions
HINTBench exposes the challenge of intrinsic risk auditing, revealing that current models have not reached the necessary granularity for robust agent safety in multi-step autonomous execution. Practical implications are profound: agents deployed in benign settings can still propagate latent failures, resulting in disastrous outcomes undetectable by traditional safeguard mechanisms. Current guard models, designed for external risks, inadequately cover these intrinsic modes.
Theoretically, the constraint-based taxonomy provides a principled structure for agent execution analysis, aiding both diagnosis and safeguard design. This foundation suggests promising directions for agent auditing research: improved step-level interpretability, causal modeling of risk propagation, and context-sensitive real-time risk detection.
Further, the results highlight the limitations of naive scaling within model families. While larger models generally perform better, improvements are not monotonic, and architectural or training refinements for context tracking and reasoning are needed. Synthetic dataset limitations and annotation uncertainty remain, calling for extensions with real-world trajectory data.
Conclusion
HINTBench establishes a rigorous benchmark for intrinsic agent safety auditing in long-horizon, benign environments. It directly targets step-level failures, leveraging a unified constraint taxonomy for fine-grained supervision and systematic evaluation. The clear performance gap observed in current models demonstrates the necessity of advancing risk localization and diagnosis abilities for autonomous agents, with direct implications for reliable real-world deployment and safety assurance.

