- The paper introduces the innovative SAEA framework to detect and quantify hidden risks such as hallucinations and adversarial exploits in financial LLMs.
- It evaluates risk through a three-level framework addressing model, workflow, and system vulnerabilities using real-time data verification and adversarial testing.
- The study emphasizes the necessity of risk-aware benchmarks to enhance model reliability and prevent systemic failures in high-stakes financial applications.
Standard Benchmarks Fail -- Auditing LLM Agents in Finance Must Prioritize Risk
Introduction
The financial domain demands precision, safety, and trust in applications. As LLMs integrate into financial systems, existing benchmarks such as InvestorBench and Pixiu prioritize task performance, neglecting fundamental safety risks like hallucinations and adversarial vulnerabilities. This paper reveals these gaps and establishes the Safety-Aware Evaluation Agent (SAEA) to assess risk comprehensively.
Limitations of Current Benchmarks
Current benchmarks emphasize metrics such as accuracy and F1 scores but fail to address risks inherent in financial settings. These metrics overlook the fragility of financial systems, where minor errors can lead to systemic failures.
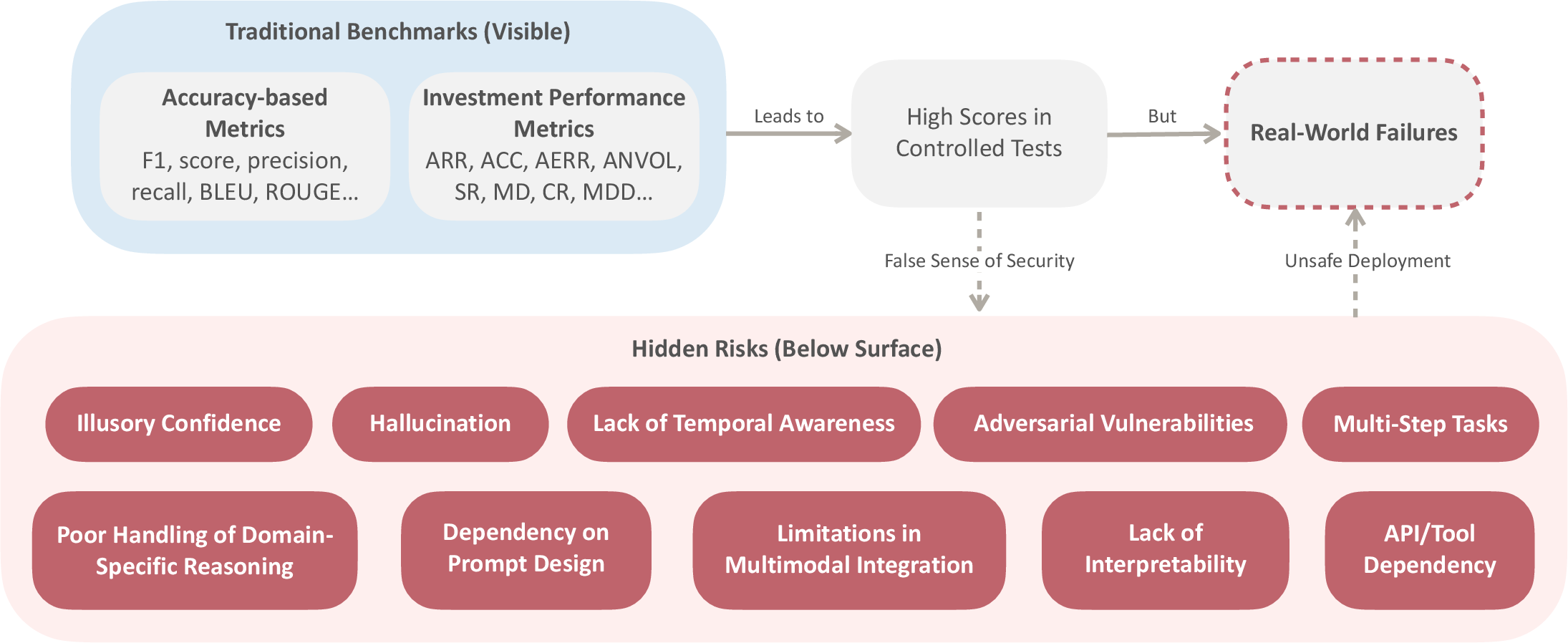
Figure 1: The limitations of traditional benchmarks for LLM agents in the financial domain. While accuracy-based metrics and investment performance metrics yield high scores in controlled tests, they fail to capture critical safety risks hiding beneath the surface. These hidden risks can lead to unsafe development and real-world failures.
Safety Challenges of LLM Agents
Intrinsic Risks
LLMs exhibit risks like illusory confidence and hallucination, which can result in incorrect financial predictions or decisions. Another critical limitation is the lack of temporal awareness, essential for adapting to financial market changes.
Adversarial Vulnerabilities
LLMs are susceptible to manipulation through adversarial prompts, affecting market analysis and decision-making. Dependency on prompt design and a lack of interpretability generate additional challenges in financial applications.
External Interactions
Financial LLMs rely on APIs and external tools, which can fail or provide inaccurate data, leading to cascading errors in multi-step financial workflows.
Safety-Aware Evaluation Agent (SAEA)
SAEA introduces a three-level evaluation framework: model-level, workflow-level, and system-level, focusing on identifying vulnerabilities and ensuring robustness.
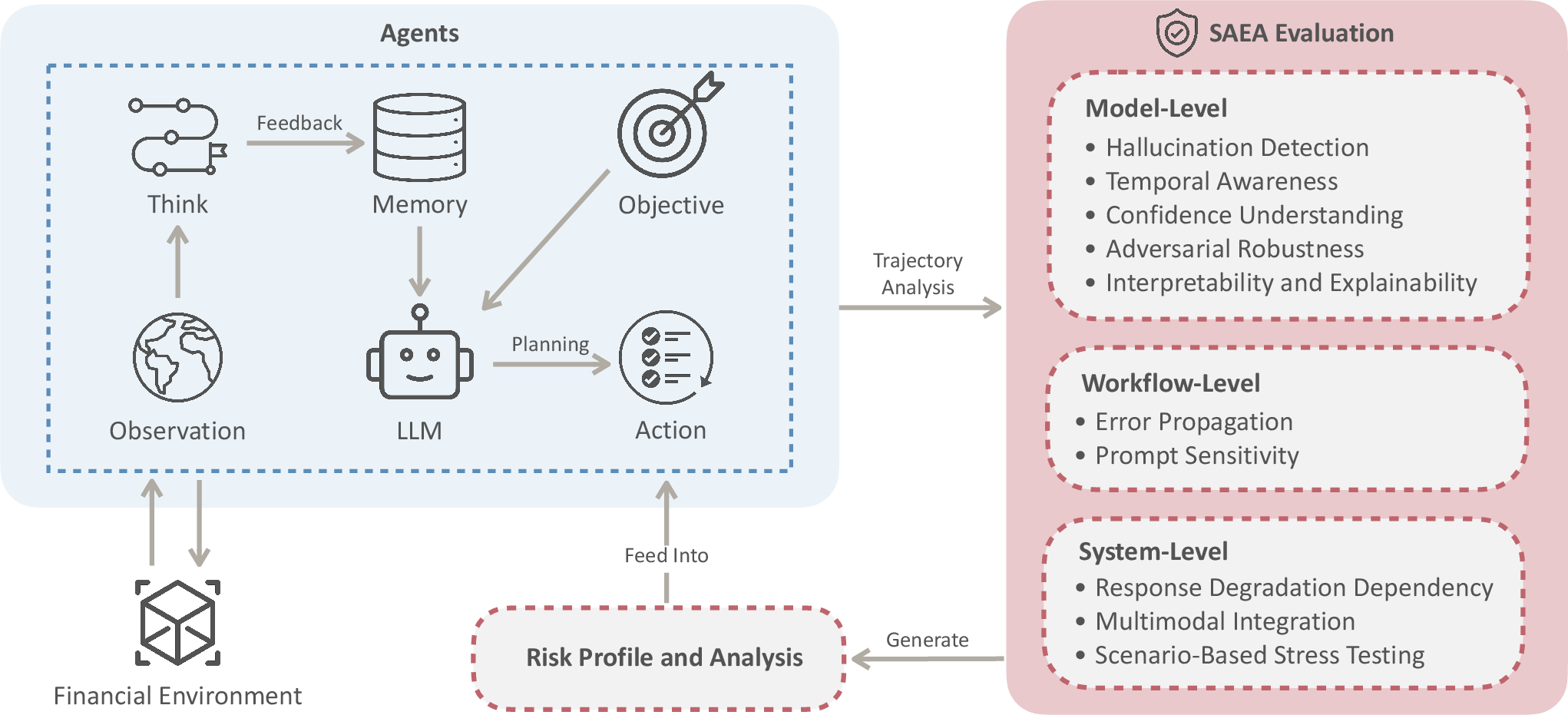
Figure 2: An overview of the Safety-Aware Evaluation Agent (SAEA) for financial LLM agents. The SAEA Evaluation conducts three-level audits: model-Level (intrinsic LLM capabilities), workflow-level (multi-step process reliability), and system-level (integration robustness). SAEA is designed to identify vulnerabilities and ensure safer, more reliable LLM agents in financial domains.
Evaluation Dimensions
SAEA evaluates metrics such as hallucination detection, temporal awareness, confidence understanding, and adversarial robustness. It aggregates these scores to provide a comprehensive risk profile.
Implementation Details
SAEA utilizes real-time data verification, adversarial scenario testing, and continuous logging to audit LLM decision trajectories, maintaining stringent checks against common vulnerabilities.
Implications and Future Work
The introduction of risk-aware evaluation is imperative for responsible deployment of LLM agents in finance. Future LLM systems must incorporate explicit mechanisms to address scenario-driven risks, providing a blueprint for safer AI in finance and other high-stakes domains.
Conclusion
Benchmarking financial LLM agents solely on performance metrics poses substantial risks. The proposed SAEA framework prioritizes safety, setting new standards for evaluating LLM robustness in financial applications. This approach not only enhances reliability but also safeguards against the systemic risks associated with AI-driven financial decision-making.