- The paper presents ARuleCon, an autonomous SIEM rule conversion pipeline featuring intermediate representation normalization, retrieval-augmented generation, and Python-based consistency checks.
- The paper demonstrates significant gains in conversion accuracy, with CodeBLEU improvements of 9-10% and embedding similarity boosts of around 10-11% across multiple SIEM platforms.
- The paper shows practical benefits in reducing manual rule conversion effort and preserving semantic fidelity, crucial for effective threat detection in diverse security environments.
ARuleCon: Agentic Security Rule Conversion for Heterogeneous SIEM Rule Translation
Introduction and Motivation
Security Information and Event Management (SIEM) platforms remain foundational in Security Operation Centers (SOCs), providing real-time intrusion detection via vendor-specific rule engines. The landscape of SIEM solutions—including Splunk SPL, Microsoft KQL, IBM AQL, Google YARA-L, RSA ESA—is characterized by non-standardized, heterogeneous query languages with variable semantics, operator sets, and schema conventions. With organizations frequently migrating SIEMs or running multiple vendors in parallel due to mergers, acquisitions, or evolving operational requirements, rule portability and semantic fidelity become imperative for operational continuity and effective threat detection.
Manual rule conversion is laborious and error-prone, while static vendor-provided tools only support limited dialects (e.g., SPL2KQL for Splunk to Sentinel). LLM-based conversion via prompt engineering typically yields poor accuracy, failing in nuanced semantic mapping due to limited exposure to SIEM corpora and lack of vendor-specific constraints. The paper introduces ARuleCon to address these deficiencies with an agentic, IR-driven SIEM rule conversion workflow.
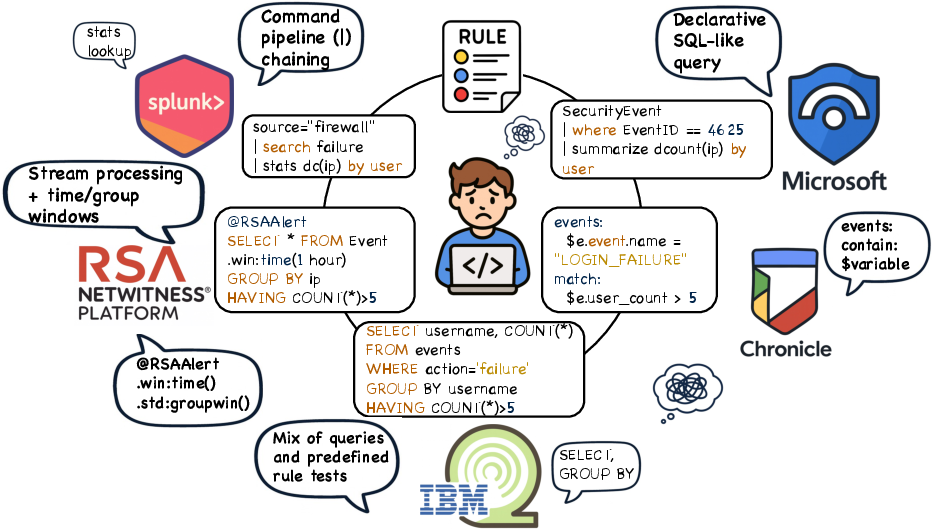
Figure 1: Motivation scenarios: industrial SOCs face heterogeneous SIEM rule languages sharing logical backbones but differing on realizations.
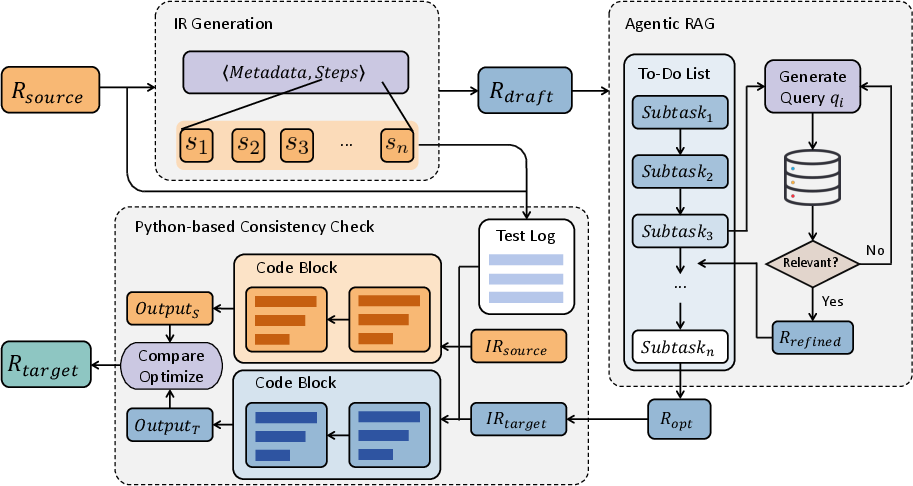
Figure 2: Overview Pipeline of ARuleCon.
ARuleCon comprises a multi-stage autonomous conversion pipeline:
- Intermediate Representation (IR) Normalization: Source rules are parsed into a layered, vendor-agnostic IR encoding metadata and ordered behavioral steps, each step specifying a functional keyword, parameters, and descriptive intent. This abstraction bridges syntactic and semantic gaps, enabling fine-grained mapping and preserving core detection logic.
- LLM Draft Generation: The IR is transformed to the target vendor rule syntax using chain-of-thought (CoT) prompts designed for semantic fidelity and structural correctness.
- Agentic Retrieval-Augmented Generation (RAG): An iterative, adaptive retrieval loop dynamically consults official vendor documentation, decomposing optimization into atomic subtasks and refining the candidate rule based on authoritative evidence—effectively emulating expert reasoning and correcting schema/operator mismatches.
- Python-based Consistency Check: Both source and target rules are executed as compositional Python pipelines over synthetic logs, comparing outputs to detect subtle semantic drifts, missing filters, aggregation discrepancies, and guiding further optimization.
This closed-loop generation, reflection, and verification cycle ensures semantic preservation across heterogeneous SIEM dialects and provides actionable repair suggestions for functional inconsistencies.
Evaluation: Numerical Results and Ablation
Conversion Accuracy
ARuleCon outperforms baseline LLM conversion (without IR, agentic RAG, or Python self-checks) across all SIEM platforms and evaluated models (GPT-5, DeepSeek-V3, LLaMA-3):
- CodeBLEU: Average gain of +9.1% (GPT), +8.4% (DeepSeek), +9.7% (LLaMA).
- Embedding Similarity: +10.3% (GPT), +11.1% (DeepSeek), +10.8% (LLaMA).
- Logic Slot Consistency: +11.6% (GPT), +13.0% (DeepSeek), +12.1% (LLaMA).
Conversions involving Splunk and RSA NetWitness yield the highest alignment, whereas IBM QRadar presents greater challenges in stateful/stateless separation and regex handling.
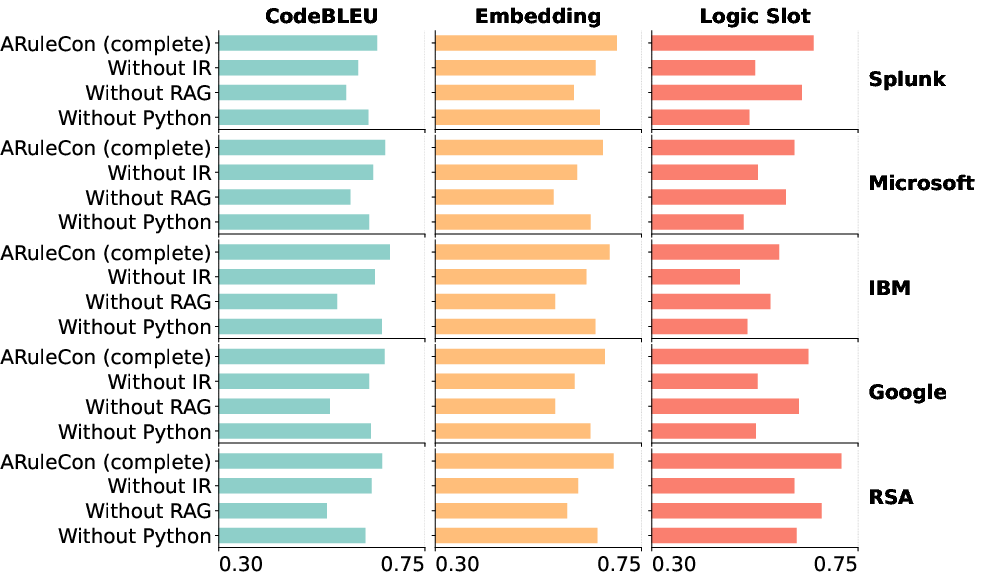
Figure 3: Each component contributes to the performance.
(Ablation results indicate removal of IR or RAG leads to degraded logic alignment and operator mapping; excluding execution validation reduces preservation of alert semantics.)
Semantic Evaluation
ARuleCon not only improves structural and lexical metrics but also achieves superior semantic fidelity on six dimensions: event scope/schema mapping, predicate boolean logic, temporal windowing, aggregation/thresholding, correlation/joins, and alert outcome. LLM-as-a-judge evaluation confirms strong human-LLM agreement (κ>0.885), with pronounced gains in predicate alignment and alert semantics.
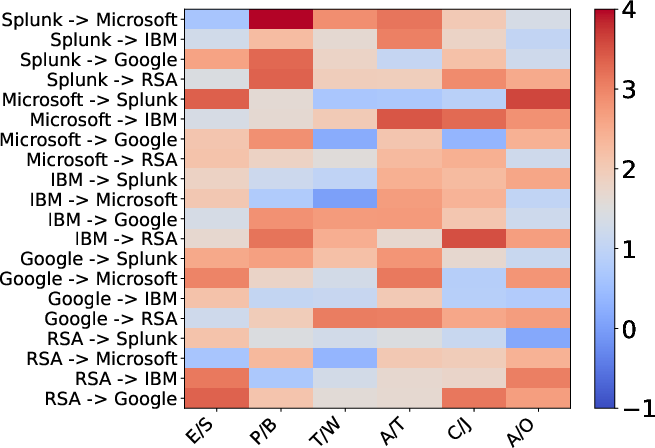
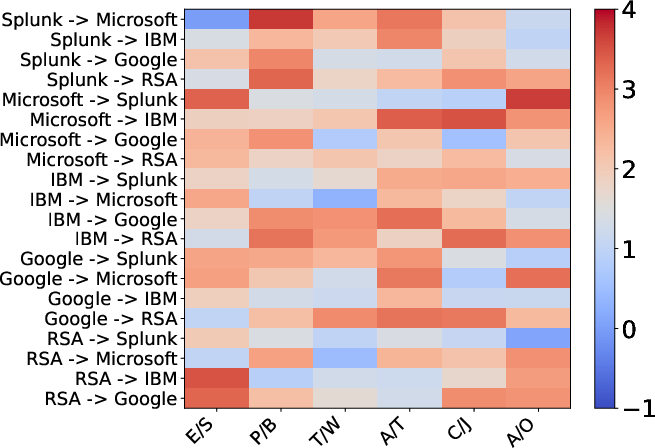
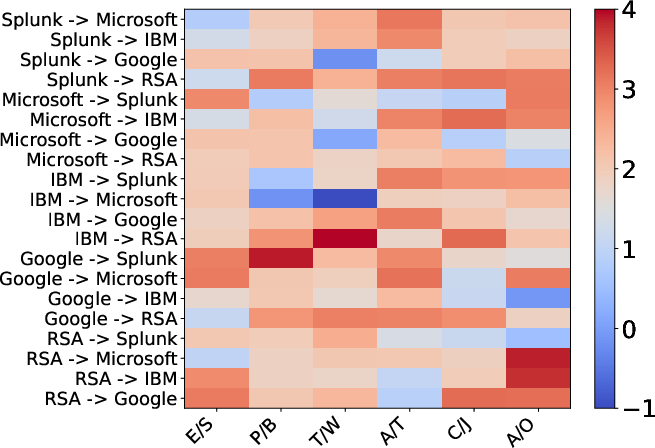
Figure 4: Fine-grained conversion evaluation on semantic-level: redder regions highlight systematic improvements, and blue cells indicate challenges in schema mapping.
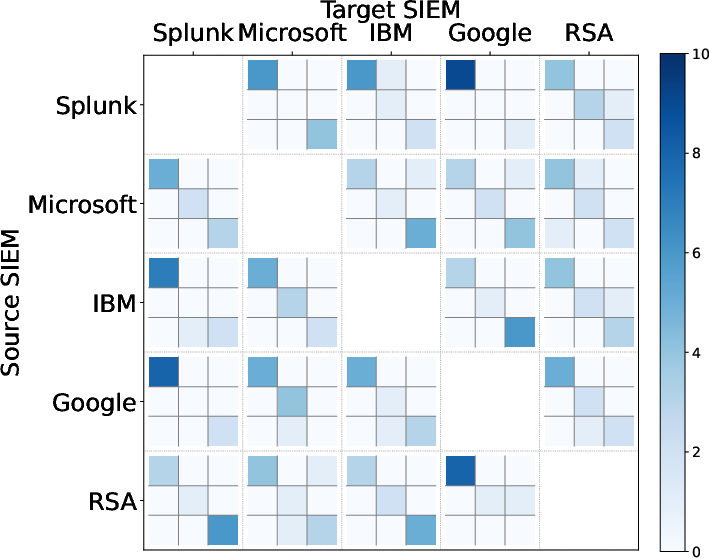
Figure 5: Consistency between LLM-as-a-Judge and human evaluation for heterogeneous SIEM rule conversions.

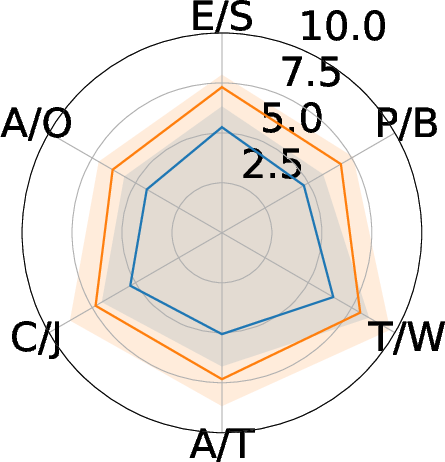
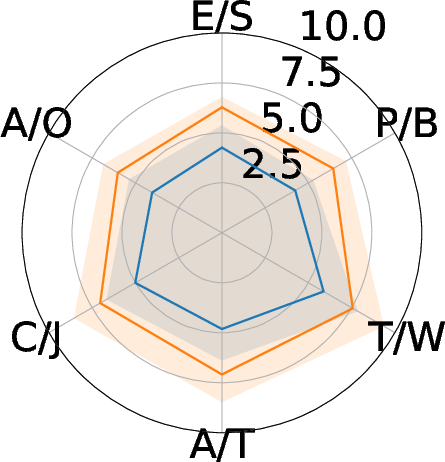
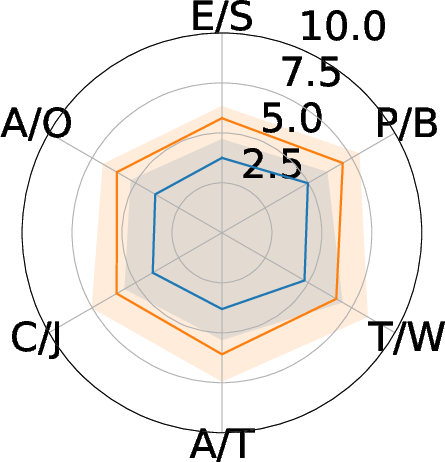
Figure 6: Semantic evaluation of ARuleCon.
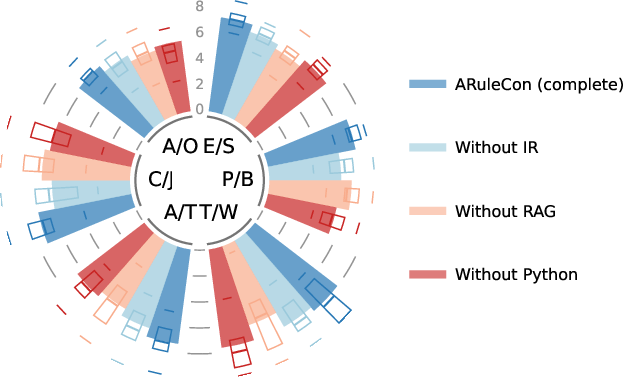
Figure 7: Ablation study of semantic metrics on ARuleCon.
Execution Validity and Efficiency
ARuleCon achieves high execution success rates (≥90%) for most platforms and remains lightweight in syntactic verification. Though the multi-step agentic workflow increases computation time (e.g., ~142s for ARuleCon vs. ~12s for baseline in GPT-5), the accuracy gains justify the additional overhead. For high-stakes detection tasks, semantic drift directly impacts incident response efficacy.
Practical and Theoretical Implications
ARuleCon substantially reduces human expert burden by automating rule migration and preserving detection coverage during SIEM platform transitions. The agentic, reflection-driven design can generalize to any domain involving constraint translation where nuanced semantic mapping and execution fidelity are critical—e.g., programming language translation, log analysis, and policy migration. With comprehensive vendor documentation grounding, ARuleCon enables adaptive, domain-specific corrections unattainable by general LLM workflows.
Theoretically, ARuleCon exemplifies the utility of agentic architectures combining IR-driven abstraction, retrieval oracles, and execution-based reflection—paving the way for highly reliable generative agents in security and other knowledge-intensive applications. Future work may involve large-scale fine-tuning on paired rule corpora, extending agentic pipelines to multi-stage policy translation and adaptive security analytics.
Conclusion
ARuleCon delivers consistent gains in SIEM rule conversion fidelity and reliability via intermediate representation normalization, agentic retrieval reflection, and executable consistency checks. Its autonomous workflow is validated through strong numerical results, robust ablation, and semantic evaluations, demonstrating practical deployment viability and laying groundwork for scalable agentic translation frameworks in security and beyond.