Matrix-3D: Omnidirectional Explorable 3D World Generation (2508.08086v1)
Abstract: Explorable 3D world generation from a single image or text prompt forms a cornerstone of spatial intelligence. Recent works utilize video model to achieve wide-scope and generalizable 3D world generation. However, existing approaches often suffer from a limited scope in the generated scenes. In this work, we propose Matrix-3D, a framework that utilize panoramic representation for wide-coverage omnidirectional explorable 3D world generation that combines conditional video generation and panoramic 3D reconstruction. We first train a trajectory-guided panoramic video diffusion model that employs scene mesh renders as condition, to enable high-quality and geometrically consistent scene video generation. To lift the panorama scene video to 3D world, we propose two separate methods: (1) a feed-forward large panorama reconstruction model for rapid 3D scene reconstruction and (2) an optimization-based pipeline for accurate and detailed 3D scene reconstruction. To facilitate effective training, we also introduce the Matrix-Pano dataset, the first large-scale synthetic collection comprising 116K high-quality static panoramic video sequences with depth and trajectory annotations. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance in panoramic video generation and 3D world generation. See more in https://matrix-3d.github.io.
Collections
Sign up for free to add this paper to one or more collections.
Summary
- The paper introduces Matrix-3D, a framework that leverages panoramic representations to generate omnidirectional, explorable 3D worlds from minimal input.
- It employs trajectory-guided panoramic video diffusion and mesh-based conditioning to overcome geometric inconsistencies and reduce artifacts.
- Experimental results demonstrate that Matrix-3D outperforms existing models in visual fidelity, camera controllability, and reconstruction efficiency using the Matrix-Pano dataset.
Matrix-3D: Omnidirectional Explorable 3D World Generation
Introduction
Matrix-3D introduces a unified framework for generating omnidirectional, explorable 3D worlds from a single image or text prompt. The approach leverages panoramic representations to overcome the limited field-of-view and geometric inconsistencies inherent in perspective-based methods. By integrating trajectory-guided panoramic video diffusion and advanced 3D reconstruction pipelines, Matrix-3D achieves high-quality, wide-coverage scene synthesis with precise camera controllability and robust geometric consistency.

Figure 1: Matrix-3D can generate omnidirectional explorable 3D world from image or text input.
Panoramic Representation and Its Advantages
Traditional 3D scene generation methods rely on perspective images, which restrict the scope of generated scenes and introduce boundary artifacts when viewed from novel angles. Matrix-3D adopts panoramic images as the intermediate representation, capturing a full 360∘×180∘ view from a single viewpoint. This enables seamless omnidirectional exploration and supports the synthesis of large-scale, immersive 3D environments.
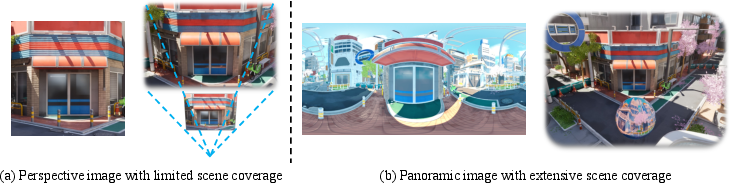
Figure 2: Comparison between perspective and panoramic images. Panoramic images can capture a significantly wider field of view than perspective images.
Framework Overview
The Matrix-3D pipeline consists of three main stages:
- Panorama Image Generation: Converts input text or perspective image to a panorama image using LoRA-based diffusion models, with depth estimated via monocular methods.
- Trajectory-Guided Panoramic Video Generation: Trains a conditional video diffusion model to generate panoramic videos that follow user-defined camera trajectories, using scene mesh renderings as conditioning signals.
- 3D World Reconstruction: Lifts the generated panoramic video into a 3D world via either a feed-forward large panorama reconstruction model or an optimization-based pipeline.
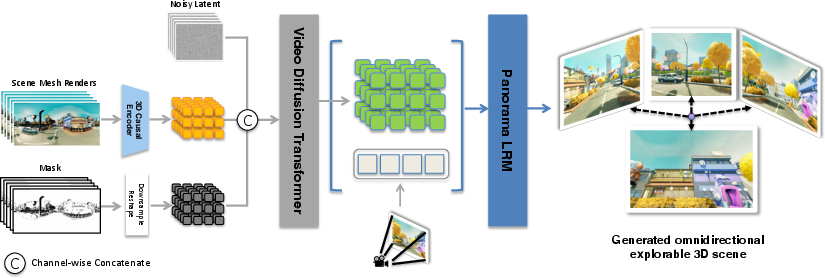
Figure 3: Core components of the framework: trajectory-guided panoramic video generation and panoramic 3D reconstruction.
Trajectory-Guided Panoramic Video Generation
Matrix-3D introduces a novel conditioning mechanism for video diffusion models: instead of point cloud renders, it utilizes scene mesh renderings derived from the initial panorama and its depth. This approach effectively mitigates Moiré artifacts and occlusion errors, resulting in improved geometric and textural consistency.

Figure 4: Comparison of trajectory guidance derived from mesh and point cloud representations. Mesh-based guidance yields fewer artifacts and superior generation quality.
The video diffusion model is built upon Wan 2.1, with LoRA modules for efficient training. Conditioning inputs include mesh renderings, binary masks, and global semantic embeddings from CLIP and text prompts. The model is trained to generate panoramic videos that precisely follow the specified camera trajectory, ensuring both visual fidelity and camera controllability.
3D World Reconstruction
Matrix-3D provides two distinct pipelines for reconstructing the 3D world from generated panoramic videos:
Optimization-Based Pipeline
- Keyframes are selected from the panoramic video and cropped into multiple perspective images.
- Depth is estimated for each keyframe, and 3D Gaussian Splatting (3DGS) optimization is performed, initialized with registered point clouds.
- Super-resolution is applied to perspective crops before optimization, and L1 loss is used for photometric supervision.
Feed-Forward Large Panorama Reconstruction Model
- Directly predicts 3DGS attributes from video latents and camera trajectory embeddings using a Transformer-based architecture.
- Employs a two-stage training strategy: first for depth prediction (using a DPT head), then for Gaussian attributes (color, scale, rotation, opacity).
- Supervision is provided via randomly sampled perspective crops from panoramic frames, with both MSE and LPIPS losses.

Figure 5: The network architecture of the large panorama reconstruction model.
Matrix-Pano Dataset
To support training and evaluation, Matrix-3D introduces the Matrix-Pano dataset, comprising 116,759 high-quality static panoramic video sequences with precise camera trajectories, depth maps, and text annotations. The dataset is generated in Unreal Engine 5, with rigorous trajectory sampling, collision detection, and multi-stage quality filtering.

Figure 6: Dataset illustration and data collection process for Matrix-Pano.
Experimental Results
Panoramic Video Generation
Matrix-3D outperforms state-of-the-art panoramic video generation models (360DVD, Imagine360, GenEx) in both visual quality and geometric consistency. Quantitative metrics (PSNR, SSIM, LPIPS, FID, FVD) demonstrate substantial improvements.

Figure 7: Qualitative comparison of panorama video generation methods. Matrix-3D achieves superior visual quality and geometric consistency.
Camera Controllability
Matrix-3D is the first to address controllable panoramic video generation. When compared to leading perspective-based camera-guided models (ViewCrafter, TrajectoryCrafter), Matrix-3D exhibits lower rotation and translation errors, indicating more accurate and flexible camera guidance.
3D World Reconstruction
The optimization-based pipeline achieves the highest visual quality (PSNR, SSIM, LPIPS), while the feed-forward model enables rapid reconstruction with competitive performance. Both methods surpass ODGS in reconstruction quality and efficiency.

Figure 8: Qualitative comparison of 3D world reconstruction.
Comparison with WorldLabs
Matrix-3D generates 3D scenes with greater navigable range than WorldLabs, as demonstrated by rendering at the furthest reached positions under identical field of view.

Figure 9: Comparison with WorldLabs. Matrix-3D produces 3D scenes with greater range.
Endless Exploration
Matrix-3D supports endless exploration by allowing users to generate new scene segments along arbitrary trajectories, enabling continuous navigation in any direction.

Figure 10: Endless exploration enabled by Matrix-3D's trajectory-guided generation.
Ablation Studies
Mesh-based trajectory guidance significantly outperforms point cloud-based guidance in terms of visual quality, geometric consistency, and camera controllability.

Figure 11: Qualitative comparison between trajectory guidance from point cloud and mesh renderings.
The DPT head yields more accurate depth predictions than 3D deconvolution-based upsampling, and the two-stage training strategy is essential for stable optimization and high-fidelity reconstruction.

Figure 12: Comparison between depth predictions from the DPT head and the 3D deconvolution head.
Implications and Future Directions
Matrix-3D establishes a new paradigm for omnidirectional 3D world generation, with direct applications in virtual reality, simulation environments, embodied AI, and digital content creation. The panoramic representation and mesh-based conditioning enable robust geometric consistency and wide-coverage scene synthesis, addressing key limitations of prior methods.
The Matrix-Pano dataset provides a valuable resource for training and benchmarking future models in panoramic video generation and 3D reconstruction.
Future research directions include:
- Generating scenes for unseen areas via advanced trajectory settings or integrated 3D object synthesis.
- Enhancing editability for semantic-level scene modification and user-driven interactions.
- Extending the framework to dynamic scene generation, supporting object motion and interaction for immersive experiences.
Conclusion
Matrix-3D presents a comprehensive solution for omnidirectional, explorable 3D world generation from minimal input. By leveraging panoramic representations, mesh-based trajectory guidance, and advanced reconstruction pipelines, it achieves state-of-the-art performance in both panoramic video generation and 3D world synthesis. The framework and dataset lay the groundwork for future advances in spatial intelligence and generalizable world models, with broad implications for AI, simulation, and content creation.
Follow-up Questions
- How does Matrix-3D overcome the limitations of traditional perspective-based 3D generation methods?
- What advantages do panoramic image representations offer in achieving geometric consistency?
- In what ways does mesh-based trajectory guidance improve upon point cloud conditioning?
- What are the trade-offs between the optimization-based and feed-forward 3D reconstruction pipelines in Matrix-3D?
- Find recent papers about 3D world reconstruction using diffusion models.
Related Papers
- DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting (2024)
- 4K4DGen: Panoramic 4D Generation at 4K Resolution (2024)
- HoloDreamer: Holistic 3D Panoramic World Generation from Text Descriptions (2024)
- Pano2Room: Novel View Synthesis from a Single Indoor Panorama (2024)
- LayerPano3D: Layered 3D Panorama for Hyper-Immersive Scene Generation (2024)
- A Recipe for Generating 3D Worlds From a Single Image (2025)
- Scene4U: Hierarchical Layered 3D Scene Reconstruction from Single Panoramic Image for Your Immerse Exploration (2025)
- 3D Scene Generation: A Survey (2025)
- Voyager: Long-Range and World-Consistent Video Diffusion for Explorable 3D Scene Generation (2025)
- HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels (2025)
Tweets
YouTube
alphaXiv
- Matrix-3D: Omnidirectional Explorable 3D World Generation (29 likes, 0 questions)