- The paper presents a unified mathematical framework that organizes first, second, and zeroth-order optimizers using four key operators for gradient estimation, adaptation, accumulation, and preconditioning.
- It systematically benchmarks 23 optimizers across architectures, revealing critical trade-offs in hyperparameter sensitivity, stability, and scalability.
- The study outlines scenario-specific adaptations, integrating privacy, memory constraints, and distributed training to guide future optimizer design in deep learning.
Evolution and Empirical Benchmarking of Optimization Algorithms in Deep Learning
The paper "Evolution of Optimization Methods: Algorithms, Scenarios, and Evaluations" (2604.12968) presents an exhaustive, technically rigorous survey of optimization algorithms in deep learning, spanning first-order (FO), second-order (SO), and zeroth-order (ZO) paradigms, alongside detailed empirical analysis. The work advances a unified mathematical taxonomy of state-of-the-art optimizers, systematically delineates scenario-oriented adaptations, and rigorously benchmarks cross-architecture efficacy, hyperparameter sensitivity, and long-term stability using standardized testbeds.
Unified Mathematical Framework for Optimization Paradigms
Central to the paper is a generalized discrete-time dynamical systems view of modern optimizers. The optimization update is formalized as the orchestration of four operators: stochastic gradient estimation E, scenario-aware transformation T (e.g., distributed, privacy-preserving, or memory-constrained), accumulator ϕ (e.g., momentum), and preconditioned/projection update via P. This abstraction enables systematic mapping across algorithmic families and explicit decoupling of the core design axes—gradient estimation fidelity, noise/constraint injection, memory scaling, and structural adaptation.
This formulation encompasses:
- First-order methods: updates based on stochastic (mini-batch) gradients, employing accumulators or preconditioners derived from history or variance (e.g., Adam, Momentum, Muon)
- Second-order approaches: explicit (or low-rank/traced) approximations to local curvature (Hessian or Fisher Information Matrix) for more isotropic, invariant updates (e.g., K-FAC, Shampoo)
- Zeroth-order methods: gradient estimation using random perturbations and finite difference schemes, thus obviating backpropagation and offering memory footprints akin to pure inference
- Scenario-oriented operators: communication compression, gradient privacy, memory-efficient projections, and federated/distributed adaptations for large-scale, real-world systems
First-Order Algorithms: Adaptive, Preconditioned, and Robust Variants
First-order optimizers are dissected along several critical axes:
- Momentum and Acceleration: From Polyak’s heavy ball and Nesterov’s lookahead to dual-momentum (e.g., MARS [181], YOGI [153]) and angular-aligned updates (e.g., AngularGrad [216]), capturing both velocity and historical congruence with present gradients.
- Adaptive Learning Rates: Adam [287], AdamW [148], Lion [167], and layer/parameter-wise schemes (LAMB [227], AdaAct [237]) integrate moving averages of historical moments, with decoupled or adaptive epsilon corrections, to enable scalar and structural adaptivity. Methods such as Muon [173] orthogonalize updates at the matrix level, yielding high robustness to hyperparams.
- Curvature and Variance Adaptation: Structural (Shampoo [170], Kron [306]), low-rank (ASGO [176]), and single-metric preconditioners (4-bit Shampoo [172]) target noise decorrelation and ill-conditioned loss surface traversal.
- Stabilization and Gradient Clipping: From fixed and dynamic gradient norm clipping (DP-SGD [59], AdaGC [30]) to per-parameter and spike-aware schemes, these guarantee bounded updates under heavy-tailed regime, privacy constraints, or catastrophic gradient spikes.
- Scalable, Memory-Efficient Extensions: Factorized (Adafactor [154]), quantized (4-bit Shampoo [172]), and stateless (AlphaGrad [204], SWAN [49]) variants are critical for resource-constrained model training (e.g., LLMs).
Second-order methods systematically compensate for the geometric limitations of first-order updates:
- Hessian and Fisher Approximations: Full matrix (Newton [280]), block-diagonal, and diagonal estimators (AdaHessian [258], Sophia [264]), stochastic sketching (SketchySGD [263]), and Kronecker-factored blocks (K-FAC [255], AdaFisher [273]) yield variable trade-offs between computational cost and curvature fidelity.
- Quasi-Newton Techniques: Memory-efficient L-BFGS [288], S-BFGS [278] with variance correction, and momentum-enhanced mL-BFGS [262] address the instabilities and cost of full-matrix approaches.
- Moment Fusion and Noise-Robustness: Algorithms like SGDHess [261] integrate local curvature into momentum, balancing acceleration with robustness under high minibatch variance.
Zeroth-Order Optimization: Memory-Constrained and Gradient-Free Training
For extreme memory and privacy constraints—or in non-differentiable settings—ZO methods are increasingly pivotal:
- Adaptive ZO Algorithms: Momentum and variance-reduced variants (ZO-AdaMM [285], R-AdaZO [147]) mitigate the detrimental scaling of estimation variance with dimensionality.
- Low-Rank, Sparse, and Quantized Directions: By exploiting subspace structure (LOZO [24], TeZO [38]) or restricting perturbation support (Sparse-MeZO [23], QZO [36]), modern ZO methods achieve practical scaling in LLM fine-tuning scenarios.
- Hybrid ZO/FO Schemes: Spatially or temporally scheduled fusions (ElasticZO [146], Addax [52]) allow for selective use of exact gradients, marrying memory savings with convergence speed.
- Distributed and Privacy-Preserving ZO: ZO-PRO [93] extends these approaches to communication-limited and federated settings, with explicit control for noise calibration and consensus formation.
Scenario-Oriented Frameworks: Large-Scale, Distributed, and Privacy-Sensitive Optimization
Optimization for practical deployment transcends algorithmic structure, demanding tailored systems co-design:
- Communication Compression and Quantization: 1-bit and low-precision gradient transmission (1-bit Adam [84], PowerSGD [74], LQ-SGD [100]), adaptive error correction, and layer/rank-aware scheduling mitigate bandwidth and latency in multi-node training regimes.
- Federated Learning and Adaptive Consensus: Techniques such as momentum correction (FedLion [110]), curvature aggregation (FedSophia [265]), statistical stratification (FedSTaS [117]), and topology/phase-aware synchronization (Kuramoto-FedAvg [122]) ensure stability across heterogeneous clients.
- Privacy-Preserving Mechanisms: DP-SGD variants, adaptive DP noise injection (TOP-DP [58]), geometric perturbations (GeoDP-SGD [65]), and privacy-aware gradual noise scaling offer rigorous guarantees for sensitive data while maintaining utility.
Empirical Benchmarking: Cross-Architecture, Scalability, and Hyperparameter Robustness
The work presents one of the most comprehensive empirical evaluations to date:
- Experimental Setup: 23 representative optimizers are benchmarked on ImageNet-1K (ResNet-50, ViT-Small) and WikiText-103 (Llama-60M) under controlled regularization, augmentation, and learning rate grid search protocols.
- Hyperparameter Sensitivity and Stability: Detailed analyses (see Figure 1) expose that Muon [173], MARS [181], and Lion [167] combine both high peak Top-1 accuracy and broad hyperparameter robustness on ViT-S, starkly contrasting with the fragile tuning of many Adam-derivatives.
- Cross-Architecture Generalization: Layer-wise, matrix preconditioned, and sign-based optimizers (e.g., Muon [173], AdamW [148], Lion [167], MARS [181]) consistently transfer strong performance to Llama-60M, while canonical FO optimizers (e.g., SGD) collapse in anisotropic LLM landscapes (see Figure 2).
- Training Scalability: SGD-based methods retain a strong scaling regime with epoch extension, whereas advanced adaptive methods rapidly saturate, reflecting inherent limitations and advantages in over-parameterized regimes.
- Optimization Trajectory Correlations: Correlation heatmaps (see Figure 3) reveal clustering of optimizer behavior by adaptation family (e.g., adaptive moment vs. preconditioned vs. sign-based) rather than solely by learning rate or aggregation technique, underlining that optimizer choice can dominate global convergence dynamics, especially in unconstrained architectures.
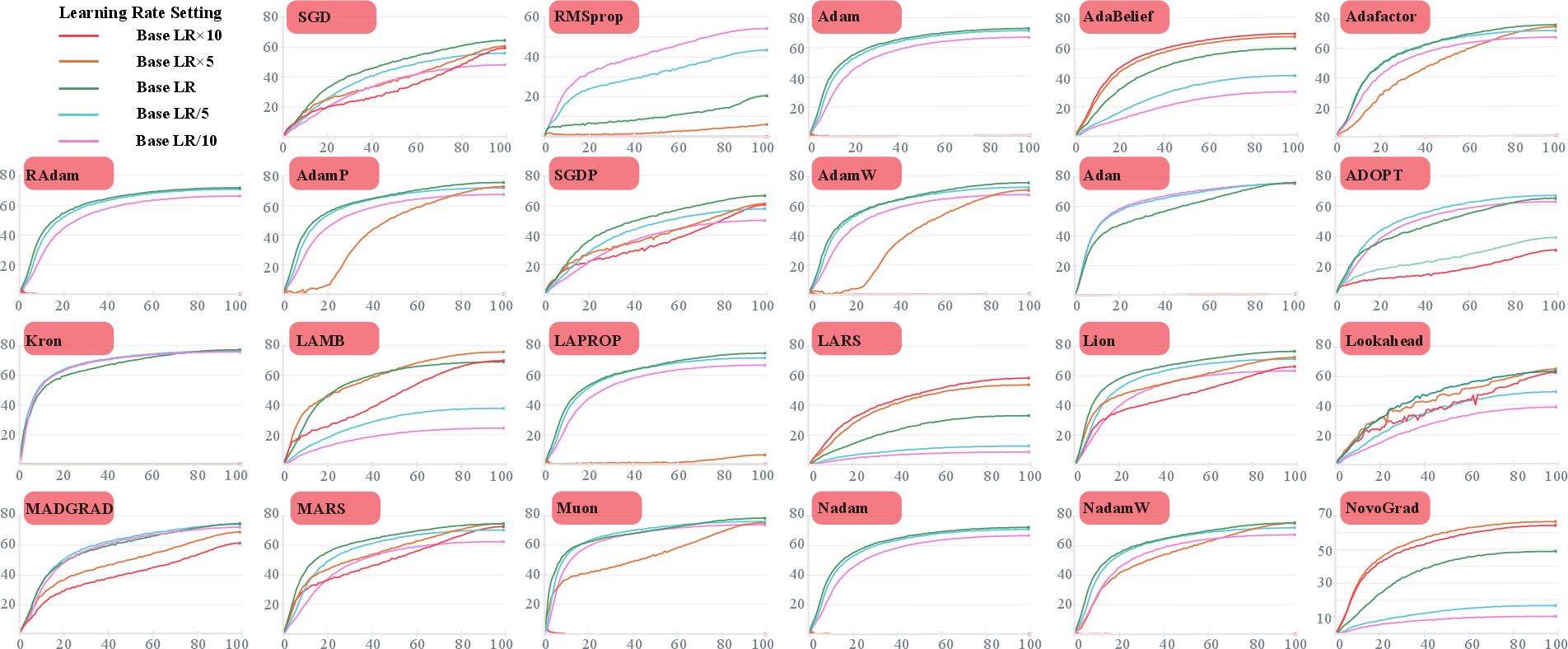
Figure 1: Top-1 accuracy and sensitivity plots for leading optimizers on ViT-S, demonstrating that convergence and peak accuracy are a joint function of learning rate choice and inherent method robustness.
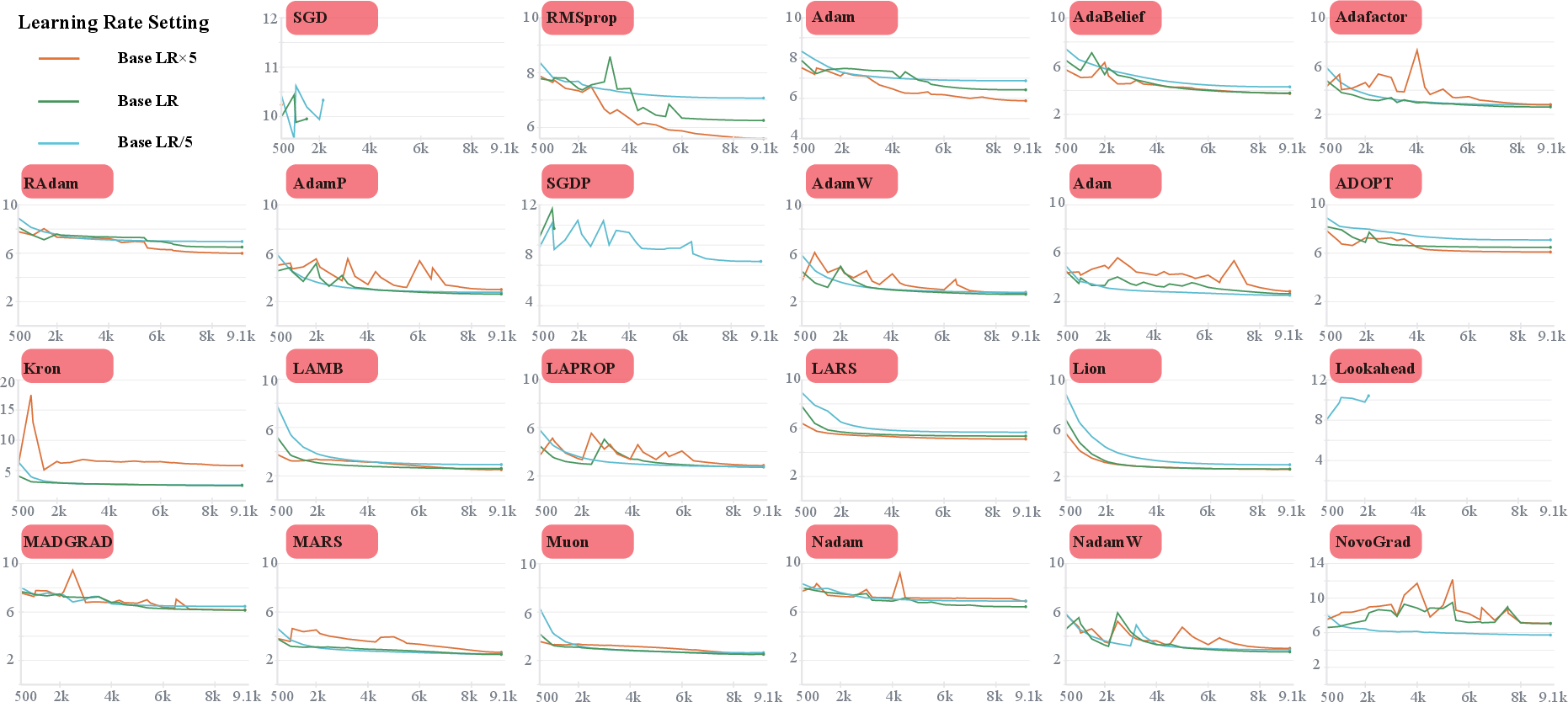
Figure 2: Validation loss dynamics on Llama-60M under varying learning rates; Muon and MARS sustain convergence across all settings while SGD-based methods diverge, highlighting critical cross-architecture instability.
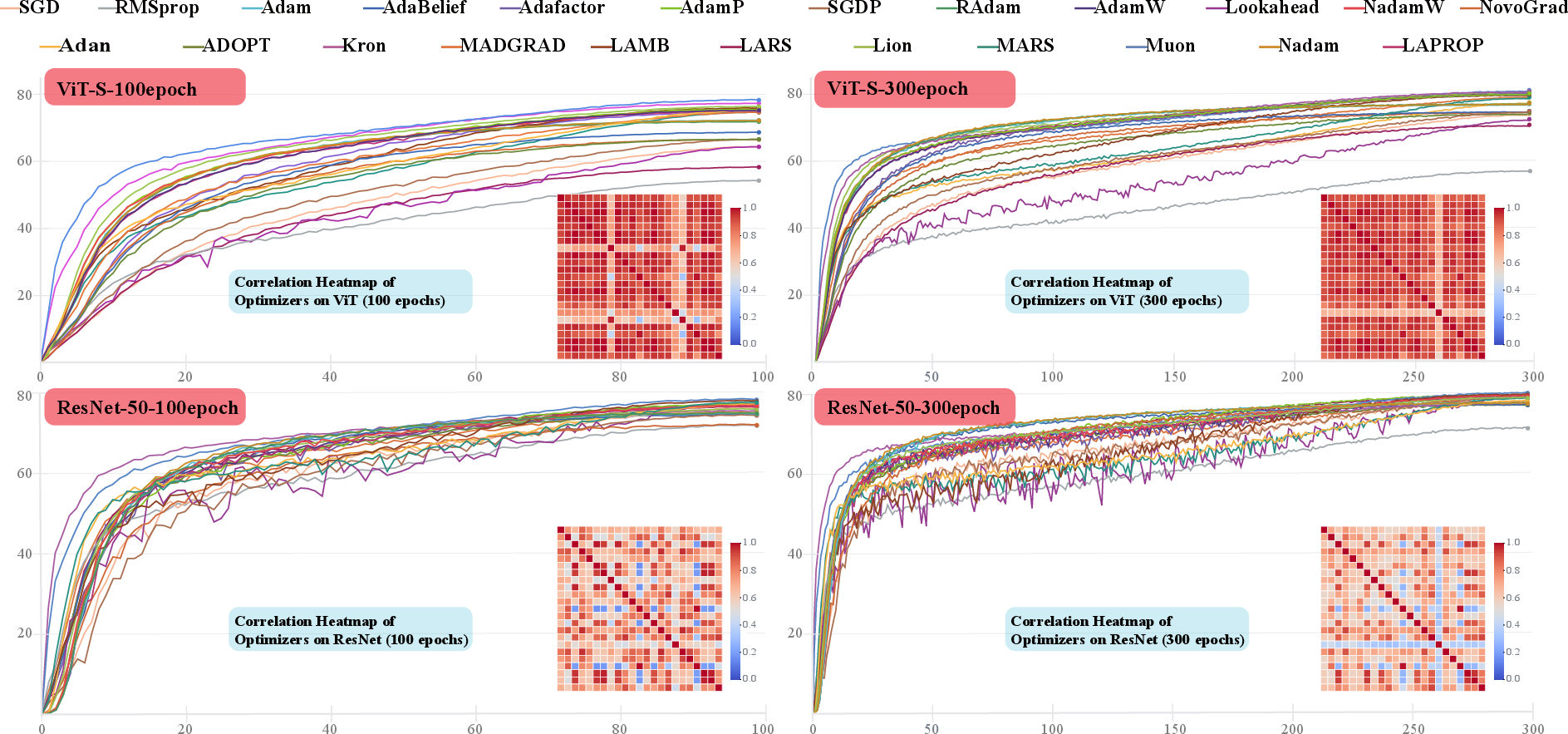
Figure 3: Optimizer performance correlations, visualized as heatmaps of first-differenced validation loss, reveal clustering along method families and clear divergence between structurally distinct optimizers as training horizons extend.
Implications and Future Perspectives
The survey surfaces both practical and fundamental theoretical challenges:
- Hyperparameter sensitivity and instability of FO/Adaptive methods in anisotropic or deep attention models;
- Scaling bottlenecks of SO/curvature-aware optimizers due to memory and per-step computational cost, despite superior conditioning;
- ZO variance explosion in high-dimensional settings, mitigated by low-rank adaptation and hybridization;
- The persistent gap between engineering compromises (e.g., memory- or privacy-preserving) and rigorous, generalizable convergence guarantees.
The authors identify key future directions, including:
- Automated symbolic/structure-aware optimizer discovery (beyond hand-tuned heuristics), potentially via programmatic/ML-based search;
- Hardware-algorithm co-design for dynamic preconditioning, tensor/matrix-level adaptation, and precision scaling to tackle emerging hardware constraints;
- Advanced noise-cancellation and adaptive perturbation schemes in ZO settings;
- Scenario-driven, topologically-aware distributed frameworks that dynamically balance consensus, privacy, communication, and local model drift.
Conclusion
This work provides an authoritative, fine-grained taxonomy and systematic empirical evaluation of optimization algorithms in modern deep learning. The proposed unified mathematical lens enables delineation of evolutionary trajectories, mechanistic equivalences, and structural trade-offs across FO, SO, and ZO regimes. Large-scale empirical benchmarking exposes critical limitations and cross-domain robustness profiles, offering a roadmap for both theoretical innovation and practical engineering in algorithmic optimization for deep neural networks. The survey sets a rigorous foundation for the design, analysis, and deployment of next-generation optimizers in the era of massive, distributed, and trust-sensitive AI systems.

