- The paper introduces a two-stage framework that leverages semantic cognitive enhancement and dual-path fallback to improve executable decompiled code.
- It employs rationale-guided training and dynamic output selection, achieving a 50% average and 70.73% re-executability at no optimization.
- The approach reduces semantic loss and logical hallucinations, enabling robust code recovery even for long-context and optimized binaries.
Semantic Refinement of Decompiler Output via LLMs: The CoDe-R Framework
Introduction
Binary decompilation, central to reverse engineering and software security, involves reconstructing high-level source code from executable binaries. Despite advances with classical rule-based tools and the recent entry of LLMs into neural decompilation, the field faces persistent challenges rooted in irreversible semantic loss during compilation. This semantic gap often results in generated code that, while syntactically plausible, does not re-execute correctly—a manifestation of logical hallucination and semantic misalignment. "CoDe-R: Refining Decompiler Output with LLMs via Rationale Guidance and Adaptive Inference" (2604.12913) introduces a principled two-stage framework to directly address these deficits in lightweight LLMs, focusing on explicit semantic recovery and robust inference selection.
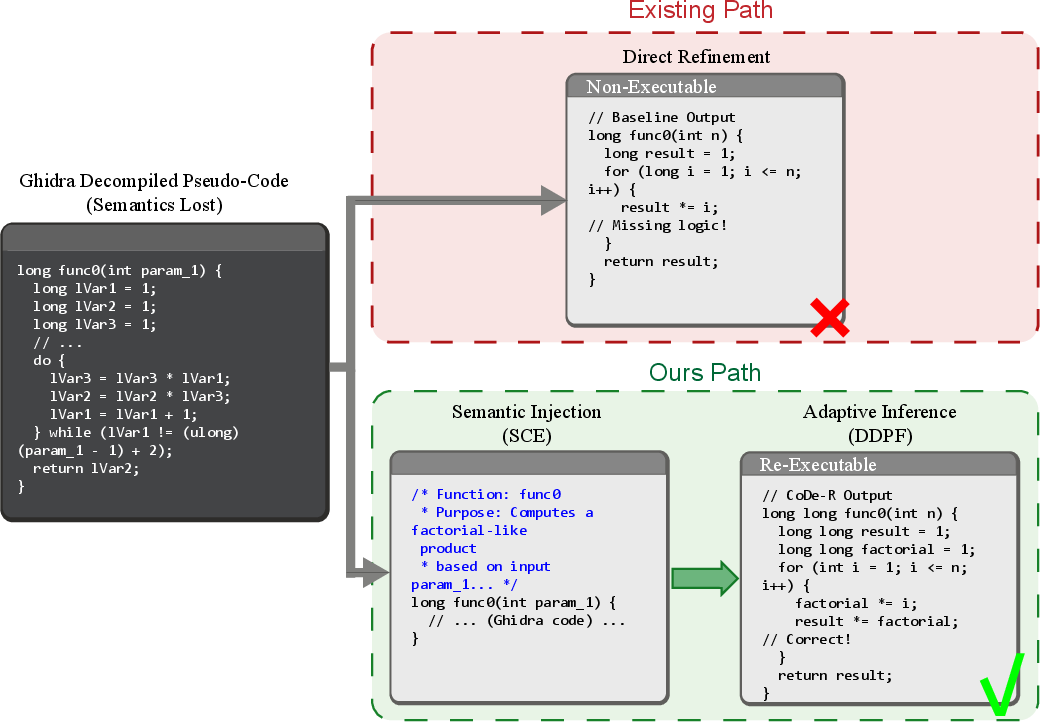
Figure 1: Comparison between existing methods and CoDe-R: While existing methods suffer from semantic loss, CoDe-R employs SCE to inject rationale, guiding the refinement of re-executable code.
Traditional neural decompilation approaches have explored both direct mapping (assembly-to-source) and structurally augmented pipelines (e.g., control flow graphs, intermediate representations). However, they are hampered by the ill-posed nature of recovering source semantics solely from binary forms. Recent augmentation strategies—including structural intermediaries and post-processing refiners—often fail to bridge the functional intent gap, exhibiting high failure rates on control flow and resource management when evaluated on benchmarks such as HumanEval-Decompile.
A quantitative analysis reveals non-uniform error patterns, with control-heavy constructs and scaling in input length exacerbating the re-executability drop. These findings motivate two requirements: (1) explicit semantic anchoring through high-level rationales, and (2) adaptive inference mechanisms to balance between logical recovery and syntactic validity.
The CoDe-R Framework
CoDe-R establishes a two-stage cognitive refinement architecture tailored for lightweight LLMs (~1.3B parameters), enabling expert-level logic recovery without brute-force scaling.
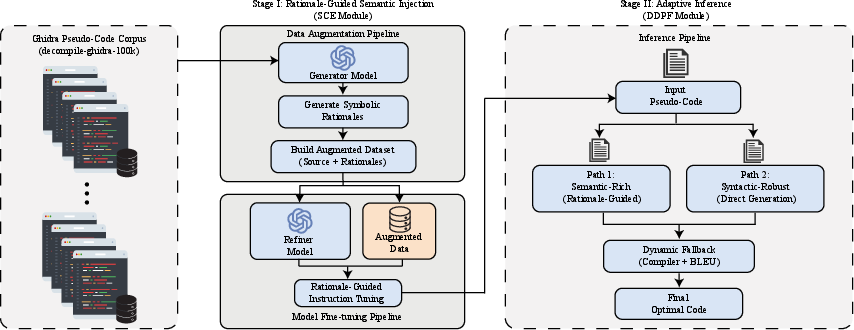
Figure 3: The overview of CoDe-R. The framework operates in two stages: Stage I employs SCE to train the model via rationale-conditional generation; Stage II utilizes DDPF to dynamically select between semantic-rich and syntactic-robust paths via a hybrid verification strategy.
Stage I: Semantic Cognitive Enhancement (SCE)
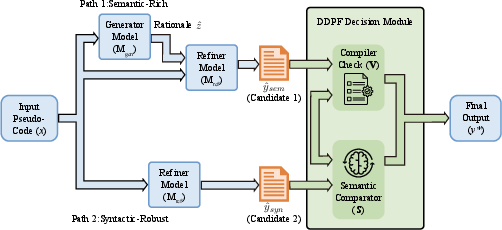
SCE leverages Rationale-Guided Semantic Injection at training time. Given decompiler pseudo-code x, a powerful generator Mgen produces a functional rationale z, encoding high-level algorithmic intent (e.g., function objective, domain-specific structure). The refinement model Mref is tuned with concatenated pseudo-code and rationale pairs (x,z), optimizing the objective P(y∣x,z;θ). This approach draws on Chain-of-Thought (CoT) paradigms but avoids their runtime inefficiencies by injecting distilled offline rationales as semantic anchors, transforming the ill-posed inverse mapping into a rationale-conditional translation task.
Stage II: Dynamic Dual-Path Fallback (DDPF)
At inference, semantic recovery must be robust to rationale imperfections and code degeneracies. DDPF solves this by producing two candidate outputs per input:
A hybrid verification mechanism—prioritizing successful compilation, followed by BLEU-based assembly similarity to the original binary—selects the final output, ensuring that code is both executable and semantically faithful. This dual-path architecture operationalizes Test-Time Compute allocation and semantic cycle-consistency within decompilation.
Numerical Results and Error Analysis
Extensive evaluation on the HumanEval-Decompile benchmark—spanning various compiler optimization levels—shows that CoDe-R achieves an average re-executability rate of 50.00%, the highest recorded in the lightweight model regime and marking the first instance of exceeding the 50% threshold in this class. At O0 (no optimization), the model achieves 70.73% re-executability, outperforming structure-aware and general-purpose LLMs in both average and robust-case settings.
Crucially, error pattern analysis indicates significant reductions in top-failure constructs requiring deep semantic recovery (e.g., if-conditions, memory management), while also revealing that gains correspond to code structures where semantic anchoring is most critical. In contrast, code patterns such as bitwise operations—where local syntax dominates—show muted improvements, reinforcing the targeted value of rationale injection.
Further analysis on code complexity demonstrates superior long-context performance for CoDe-R. The re-executability rate deteriorates gracefully as input length increases, compared to sharp breakdowns in direct-mapping baselines, confirming the information-theoretic role of injected rationales as semantic landmarks.
Ablation and Design Studies
Component subtraction and architectural ablation studies clarify the contribution of each element:
- Removing rationale conditioning reduces average re-executability by over 2%.
- Isolating DDPF shows that its dynamic selection boosts both semantic fidelity and syntactic validity, with dual-path ensembling outperforming either path in isolation.
- Injecting concise, high-density rationales surpasses verbose, detailed annotations, validating the importance of minimizing semantic noise.
- Ablating rationale distillation confirms that fixed-context rationale utilization—rather than forcing the LLM to re-synthesize rationales—yields optimal results, consistent with recent findings in rationale-augmented model distillation.
Implications and Future Prospects
The introduction of explicit rationale guidance and adaptive inference overcomes legacy pitfalls in neural decompilation pipelines, providing a replicable strategy for surmounting the semantic gap using small LLMs. Practically, CoDe-R facilitates high-fidelity program comprehension for real-time security diagnostics, obfuscated code analysis, and automated maintenance in resource-constrained settings.
Theoretically, this work strengthens arguments for hybrid architectures—blending offline reasoning and runtime verification—as a new optimum in code-centric LLM workflows. The demonstrated robustness in long-context and high-optimization settings suggests potential for extending rationale-guided cognitive refinement beyond classical C decompilation to modern compiled languages and more adversarial binaries.
Conclusion
CoDe-R establishes a discipline-shifting paradigm by integrating Symbolic Rationale Anchors and Dynamic Dual-Path Fallback into lightweight LLM-based decompilation. Empirical results confirm that explicit semantic recovery closes the gap between LLM scale efficiency and expert-level code logic restoration. Although dual-path inference introduces non-negligible overhead, the practical gains in semantic correctness recalibrate design trade-offs for neural reverse engineering tools. Anticipated future directions include parallelizing dual-path decoding and extending rationale-guided refinement to other compilation targets.
The CoDe-R framework demonstrates that integrating explicit reasoning signals and adaptive decoding policies is essential for robust program synthesis from semantically degraded artifact domains.