- The paper presents a neural pipeline that decompiles optimized x86-64 binaries into idiomatic Dart code using fine-tuned small LLMs.
- It contrasts synthetic augmentation with Swift-based cross-lingual transfer, revealing capacity-dependent effects on CodeBLEU and compile@k metrics.
- The work shows that compute-efficient domain-specialized LLMs can rival foundation models while addressing unique decompilation challenges.
LLMs as Idiomatic Decompilers for Dart: High-Level Recovery from x86-64 Assembly
Overview
The paper "LLMs as Idiomatic Decompilers: Recovering High-Level Code from x86-64 Assembly for Dart" (2604.02278) systematically investigates the capacity of specialized LLMs to recover highly readable, idiomatic Dart code from x86-64 binaries. The core contributions are: (1) the first neural pipeline for Dart/Swift decompilation from assembly, (2) an analysis contrasting synthetic augmentation and related-language (Swift) transfer in low-resource contexts, and (3) a comprehensive evaluation using CodeBLEU and compile@k metrics, including uncertainty quantification. Results show small LLMs can closely match outputs from models over two orders of magnitude larger, with subtle behavior in cross-lingual training depending on model capacity.
Background and Motivation
Decompilation—translating machine code to human-readable languages—is critical for reverse engineering. While LLMs have outperformed classical decompilers by generating more semantically faithful and idiomatic C code, adaptation to modern languages such as Dart and Swift has remained unexplored. These languages' advanced features (e.g., null-safety, closure semantics, higher abstraction levels) pose unique challenges due to sparse available training data and more complex idiomatic constructions compared to C.
The paper targets this gap by investigating whether fine-tuned small LLMs can recover high-level idiomatic Dart code from optimized binaries, and whether incorporating related-language (Swift) examples benefits small models under data scarcity.
Methodology
The approach employs a multi-stage pipeline: source code in Dart or Swift is compiled into optimized (Dart: AOT, Swift: -O0) x86-64 binaries, disassembled to assembly code, and then decompiled to the high-level language using custom fine-tuned LLMs. Model performance is evaluated by CodeBLEU for code similarity and idiomaticity, and compile@k for syntactic correctness.
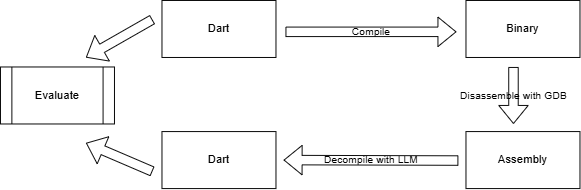
Figure 1: Decompilation pipeline from Dart/Swift source through binary and x86-64 assembly to high-level code, with CodeBLEU and compile@k evaluation metrics.
Data Construction
- Training Data: Two main sets—(1) Dart-only (246 natural + 948 synthetic, total 1,194), and (2) Dart+Swift (246 Dart + 754 Swift, total 1,000)—were constructed. Synthetic examples were generated by leading LLMs (GPT, Claude, DeepSeek, Qwen), and validated for syntactic integrity.
- Augmentation Methods: Compared are (a) expansion via synthetic Dart pairs and (b) including human-written Swift→Dart pairs.
- Assembly Generation: Dart uses production-style AOT compilation with boundary-preserving pragmas; Swift is compiled with -O0 for structural alignment. An observed confound is the mismatch in optimization, potentially impacting patterns learned across languages.
- “Thinking tokens”: Sparse annotation with chain-of-thought traces is introduced to help guide cross-level semantic mapping.
Model Architecture and Training
- Base Models: Qwen3-4B and DeepSeek-R1-8B represent the core architectures, both with state-of-the-art attention and activation mechanisms, extended to 32k context windows via distillation.
- Fine-Tuning: LoRA with DoRA enhancement targets full transformer blocks, with modest compute (single NVIDIA H200, ≤3 hours). Label smoothing and aggressive dropout calibrate for generalization under low data.
Evaluation Protocol
- CodeBLEU: Measures n-gram overlap, AST, and data-flow similarity, with careful decoding parity across models (temperature 0.2, top-p 0.99, beam 1).
- compile@k: Success rate for syntax-valid code, using k=5 decodings per input; statistical significance determined by Wilson intervals and two-proportion z-tests.
- Idiomaticity: Qualitative analysis (single reviewer, preliminary).
Results
Code Similarity (CodeBLEU)
- The 4B Dart-specialized model achieves 71.3 CodeBLEU (95% CI: 65.5–77.1) on a 73-function Dart test set, almost matching Qwen3-Coder-Plus (∼480B, CodeBLEU 73.1).
- Adding Swift to 4B reduces performance (−2.1 points); at 8B, adding Swift improves CodeBLEU by +8.7 points, indicating model capacity threshold effects.
- The 4B specialized model consistently outpaces the base model (66.1).
- Larger models (up to ∼1T) achieve higher scores (Qwen3-Max: 77.4), but small, focused models approach this upper bound at a fraction of the compute budget.
Executability (compile@k)
- For 34 natural Dart functions, the specialized 4B model reaches 79.4% compile@5 (CI: 63.2–89.7), a suggestive +14.7% over base, but not statistically significant at the 0.05 level.
- At k=1, compile rates are uniformly lower, and CIs across models overlap.
- Notably, higher compilation rates for specialized models are accompanied by slightly decreased CodeBLEU for compiled-only samples, suggesting they tackle more challenging cases (i.e., increased coverage with more “difficult” code).
Qualitative/Idiomatic Output
- Preliminary assessment finds the specialized models generate more idiomatic Dart, leveraging null-safety, expressive identifiers, and language-specific control flow, unlike baseline model outputs which often lack semantic structure or meaningful names.
Analysis: Cross-language Transfer vs. Synthetic Augmentation
A central empirical result is the capacity-dependent utility of cross-lingual data:
- At 4B scale, augmenting with Swift impairs Dart performance due to representational bottlenecks and increased cross-lingual interference.
- At 8B, performance benefits emerge, with models exploiting shared idioms without significant interference.
Key contributors to this phenomenon include: (1) capacity saturation in smaller models, (2) negative interference from ambiguous language features, and (3) confounds introduced by mismatched optimization levels in assembly between Dart (AOT) and Swift (-O0).
Limitations
- Semantic Faithfulness: Only syntactic correctness (compile@k) is measured; no thorough unit-test–based semantic evaluation is performed (pass@k).
- Optimization Confound: Disparity in binary optimization between Dart and Swift is a confounding factor in transfer experiments.
- Human Evaluation: Idiomaticity claims are not formally substantiated (single reviewer, lacking inter-rater calibration).
- Reproducibility: Some hyperparameter choices not strictly documented.
Implications and Future Directions
- Practical Decompilation: Small models enable performant, compute-efficient decompilation for modern high-level languages, crucial for reverse engineering, vulnerability analysis, and software archaeology.
- Scalable Training: Data augmentation strategies must account for scale-dependent transfer/interference effects when combining multiple programming languages.
- New Evaluation Protocols: Full semantic unit tests (pass@k) and matched binary optimizations are necessary for unequivocal model comparison.
- Expansion to Other Architectures: Generalization to ARM and RISC-V and mapping effects of various compilation flags warrant further study.
Conclusion
This work establishes that domain-specialized small LLMs (4B) are competitive with foundation models over two orders of magnitude larger for Dart decompilation from optimized binaries. Critically, effectiveness of cross-lingual augmentation hinges on sufficient model capacity and aligned optimization strategies; otherwise, interference outweighs transfer. These findings have direct implications for building practical, efficient decompilers for contemporary software ecosystems and highlight the necessity for nuanced evaluation and tailoring of codal LLMs for emerging languages and use-cases.